Сценарии администрирования
Администрирование продукта СУБД Pangolin (Pangolin) (далее – Pangolin) осуществляется средствами, которые описаны в этом разделе.
Реализация АРМ администратора
Для администрирования системы используется утилита psql. Эта утилита представляет собой терминальный клиент для передачи запросов к СУБД и отображения результатов.
psql [параметр...] [имя_бд [имя_пользователя]]
Примечание:
Решение по обеспечению безопасности АРМ администратора должно исходить из окружения конечной АС.
Генерация сертификатов
Для включения SSL между компонентами кластера необходимо подготовить сертификаты.
Подготовка сертификатов не выполняется инсталлятором Pangolin. Ожидается, что на хосте уже есть сертификаты, которые будут переданы на вход инсталлятору. Инсталлятор сам разместит их в нужных директориях и выдаст права для служебных пользователей (например, etcd).
-
Серверный сертификат (необходимо создать для каждого хоста в кластере):
-
Сгенерируйте ключ:
openssl genrsa -out server.key 2048 -
Создайте файл конфигурации для создания запроса на подпись сертификата
vim server.conf:[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[ v3_req ]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[ ssl_client ]
extendedKeyUsage = clientAuth, serverAuth
basicConstraints = CA:FALSE
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
subjectAltName = @alt_names
[ v3_ca ]
basicConstraints = CA:TRUE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
authorityKeyIdentifier=keyid:always,issuer
[alt_names]
DNS.1 = <host> ## hostname with domain
IP.1 = <IP-адрес> ## host ip address -
Экспортируйте файл конфигурации:
CONFIG=`echo $PWD/server.conf` -
Создайте запрос на подпись сертификата. В
CNнеобходимо указать полныйhostname:openssl req -new -key server.key -out server.csr -subj "/CN=<host>" -config ${CONFIG}
-
-
Клиентский сертификат:
-
Сгенерируйте ключ:
openssl genrsa -out postgres.key 2048 -
Создайте файл конфигурации для создания запроса на подпись сертификата
vim client.conf:[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[ v3_req ]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
[ ssl_client ]
extendedKeyUsage = clientAuth
basicConstraints = CA:FALSE
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
[ v3_ca ]
basicConstraints = CA:TRUE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
authorityKeyIdentifier=keyid:always,issuer -
Экспортируйте файл конфигурации:
CONFIG=`echo $PWD/client.conf` -
Создайте запрос на подпись сертификата. В
CNнеобходимо указать имя клиента/компонента (postgres, patroni, patronietcd, pgbouncer):openssl req -new -key postgres.key -out postgres.csr -subj "/CN=postgres" -config ${CONFIG}
Примечание:
При создании клиентских сертификатов, в поле
subjectAltNameможно указать IP-адрес или(и) DNS-имя машины (список машин), на которой(ых) будет использоваться сертификат. Также в этом поле можно указать адрес подсети. -
Сгенерированные запросы на подпись сертификатов (файлы в формате *.csr) необходимо подписать удостоверяющем центре.
Полученные сертификаты необходимо перевести в формат PEM (например, командой openssl x509 -inform DER -outform PEM -in ./certificate.cer -out ./certificate.crt), расположить в одинаковых директориях на каждом хосте и выдать права - 600 для ключей и 644 для сертификатов, владелец — УЗ ОС postgres.
Наименование сертификатов, с которыми будет работать инсталлятор:
| Назначение | Наименование сертификата | Наименование ключа |
|---|---|---|
| Сертификат сервера | server.crt | server.key |
| Сертификат пользователя postgres | postgres.crt | postgres.key |
| Сертификат пользователя Pangolin Pooler | pgbouncer.crt | pgbouncer.key |
| Сертификат пользователя patronietcd | patronietcd.crt | patronietcd.key |
| Сертификат пользователя patroni | patroni.crt | patroni.key |
Поскольку в Pangolin можно указать только один корневой сертификат, а в нашем случае их два (один — УЦ непосредственно выпустивший сертификат, второй — УЦ выпустивший сертификат для УЦ и имеющий признак CA), необходимо объединить сертификаты корневого и промежуточного УЦ в один:
cat root.crt intermediate.crt > rootCA.crt
Все корневые сертификаты необходимо скопировать в папку /etc/pki/ca-trust/source/anchors и выполнить команду обновления хранилища доверенных корневых сертификатов:
sudo update-ca-trust
Настройка компонентов
Внимание!
В процессе работы инструмента развертывания производится валидация сертификатов на их соответствие требованиям. После работы инструмента развертывания валидация сертификатов находится на стороне владельца стенда.
Произведите настройку компонентов на использование сертификатов (задача инструмента развертывания):
-
В файле
postgres.conf(для стендов в конфигурации standalone-postgresql-pgbouncer). В данном случае необходимо указать путь к подписанным сертификатам для сервера БД:ssl = 'on'
ssl_cert_file = '/home/postgres/ca/server.crt'
ssl_key_file = '/home/postgres/ca/server.key'
ssl_ca_file = '/home/postgres/ca/rootCA.crt'
ssl_crl_file = 'путь к файлу со списком отозванных сертификатов' -
В
pangolin-pooler.iniдобавьте секцию TLS-настроек. Между Pangolin Pooler и СУБД Pangolin настраивается обязательное SSL-соединение, между Pangolin Pooler и клиентом — по требованию клиента. В обоих случаях минимальная версия TLS 1.2 (Cipher suites (TLS 1.2): ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384).# TLS settings
server_tls_protocols = secure
server_tls_ciphers = secure
server_tls_sslmode = verify-full
server_tls_ca_file = /home/postgres/ca/rootCA.crt
server_tls_cert_file = /home/postgres/ca/pgbouncer.crt
server_tls_key_file = /home/postgres/ca/pgbouncer.key
client_tls_protocols = secure
client_tls_ciphers = secure
client_tls_sslmode = prefer
client_tls_ca_file = /home/postgres/ca/rootCA.crt
client_tls_cert_file = /home/postgres/ca/server.crt
client_tls_key_file = /home/postgres/ca/server.key -
В
etcd.confзначенияhttpпереведите вhttpsи добавьте секцию настроекTLS. Аутентификация в БД etcd происходит по паролю, так же необходимо указать сертификат пользователя.ETCD_NAME="<hostname>"
ETCD_LISTEN_CLIENT_URLS="https://<IP-адрес>:2379"
ETCD_ADVERTISE_CLIENT_URLS="<hostname>:<порт>"
ETCD_LISTEN_PEER_URLS="https://<IP-адрес>:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="<hostname>:<порт>"
ETCD_INITIAL_CLUSTER_TOKEN="test"
ETCD_INITIAL_CLUSTER="<hostname>:<порт>,<hostname>:<порт>,<hostname>:<порт>"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ENABLE_V2="false"
# TLS settings
ETCD_CIPHER_SUITES="TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"
ETCD_TRUSTED_CA_FILE="/home/postgres/ca/rootCA.crt"
ETCD_CERT_FILE="/home/postgres/ca/server.crt"
ETCD_KEY_FILE="/home/postgres/ca/server.key"
ETCD_PEER_TRUSTED_CA_FILE="/home/postgres/ca/rootCA.crt"
ETCD_PEER_CERT_FILE="/home/postgres/ca/server.crt"
ETCD_PEER_KEY_FILE="/home/postgres/ca/server.key"
ETCD_PEER_CLIENT_CERT_AUTH="true"
ETCD_PEER_CRL_FILE="путь к файлу со списком отозванных сертификатов" -
В файле конфигурации pangolin-manager
postgres.ymlвнесите изменения в секцииrestapi, etcd3, postgres, pg_hba.-
restapiдобавить параметрыverify_client, cafile, certfile, keyfile- пути до сертификатов. Параметрverify_client: optional- означает, что все запросы «управления»PUT, POST, PATCH, DELETEтребуют аутентификации по сертификатам. Параметрыallowlist: [] allowlist_include_members: true- означают, что доступ к запросам «управления» есть только у членов кластера и хостов, которые перечислены вallowlist. ЗапросыGET(только получение сведений о кластере) будут возвращаться без аутентификации.restapi:
listen: <IP-адрес>:8008
connect_address: <hostname>:<порт>
allowlist: []
allowlist_include_members: true
verify_client: optional
cafile: /home/postgres/ca/rootCA.crt
certfile: /home/postgres/ca/server.crt
keyfile: /home/postgres/ca/server.key
authentication:
username: patroniyml
password: <пароль> -
В секции
etcdдобавьте параметрыprotocol, cacert, cert, key. Соединение с etcd будет осуществляться по протоколу HTTPS.etcd:
hosts: <hostname>:<порт>,<hostname>:<порт>,<hostname>:<порт>
protocol: https
cacert: /home/postgres/ca/rootCA.crt
cert: /home/postgres/ca/patronietcd.crt
key: /home/postgres/ca/patronietcd.key
username: patronietcd
password: <пароль>
-
-
В секции postgres в подразделе аутентификации пользователя patroni добавьте параметры
sslmode, sslkey, sslcert, sslrootcertи в разделеparametersукажите путь к серверному сертификату. Параметрsslmodeустанавливается в значениеverify-caиз-за особенностей локального подключения.postgresql:
listen: <IP-адрес>:5433
bin_dir: /usr/pgsql-se-05/bin
connect_address: <hostname>:<порт>
data_dir: /pgdata/0{major_version}/data/
create_replica_methods:
- basebackup
basebackup:
format: plain
wal-method: fetch
authentication:
replication:
username: patroni
database: replication
sslmode: verify-ca
sslkey: /home/postgres/ca/patroni.key
sslcert: /home/postgres/ca/patroni.crt
sslrootcert: /home/postgres/ca/rootCA.crt
sslcrl: "путь к файлу со списком отозванных сертификатов"
superuser:
username: patroni
sslmode: verify-ca
sslkey: /home/postgres/ca/patroni.key
sslcert: /home/postgres/ca/patroni.crt
sslrootcert: /home/postgres/ca/rootCA.crt
sslcrl: "путь к файлу со списком отозванных сертификатов"
ssl: 'on'
ssl_cert_file: /home/postgres/ca/server.crt
ssl_key_file: /home/postgres/ca/server.key
ssl_ca_file: /home/postgres/ca/rootCA.crt
ssl_crl_file: "путь к файлу со списком отозванных сертификатов" -
В секции pg_hba смените метод подключения для УЗ patroni с host на hostssl:
hostssl all patroni <IP-адрес>/32 scram-sha-256
hostssl all patroni <IP-адрес>/32 scram-sha-256
hostssl replication patroni <IP-адрес>/32 scram-sha-256
hostssl replication patroni <IP-адрес>/32 scram-sha-256 -
Если какой-либо сертификат был просрочен или отозван, необходимо выпустить новый, согласно инструкции описанной в разделе «Генерация сертификатов», и, в случае изменения наименования сертификата, произвести настройку компонента, где данный сертификат был задействован. В случае сохранения имени сертификата, необходимо перезапустить сервисы компонентов после замены файлов сертификатов.
Использование сертификатов PKCS#12 в кластере Pangolin
В версиях Pangolin до 5.3.0 сертификаты и закрытые ключи, используемые для установки TLS/SSL соединений, хранились в кластере Pangolin в формате, не предусматривающем предъявление секрета для доступа к сертификату и/или закрытому ключу. В версии Pangolin, начиная с 5.3.0, в целях повышения уровня информационной безопасности вводится авторизация для использования сертификатов и закрытых ключей на промышленных стендах.
При использовании оригинального libpq поддержка PKCS#12 недоступна, так как не гарантируется работоспособность сторонних решений.
Сертификаты и закрытые ключи, используемые в версии Pangolin 5.2.1, приведены в таблице ниже и используются для установления TLS-соединения между компонентами кластера Pangolin:
| Клиентские сертификат и ключ Pangolin Pooler для подключения к серверу СУБД Pangolin | Назначение сертификатов и закрытых ключей |
|---|---|
| server.crt / server.key | Серверный сертификат СУБД Pangolin для установления клиентских подключений Серверный сертификат Pangolin Manager. для установления клиентских подключений (REST API) Клиентский и серверный сертификат для взаимодействия между экземплярами etcd Серверный сертификат Pangolin Pooler для установления клиентских подключений |
| pgbouncer.crt / pgbouncer.key | Клиентский сертификат Pangolin Pooler для подключения к серверу СУБД Pangolin |
| patroni.crt / patroni.key | Клиентский сертификат Pangolin Manager для подключения к серверу СУБД Pangolin |
| patronietcd.crt / patronietcd.key | Клиентский сертификат Pangolin Manager для подключения к серверу etcd |
| client.crt / client.key | Клиентский сертификат пользователя postgres |
| root.crt | Корневой сертификат УЦ |
С версии Pangolin 5.3.0 данные сертификаты и закрытые ключи, за исключением root.crt и patronietcd.crt/patronietcd.key, хранятся в файловой системе в засекреченных контейнерах PKCS#12, а парольные фразы для их расшифровки - в засекреченном виде. Ключ для засекречивания/рассекречивания парольных фраз генерируется на основе параметров сервера, поэтому файлы с парольными фразами не переносимы между узлами кластера Pangolin.
Примечание:
Следующая ключевая информация хранится в файловой системе в PEM-формате:
- Сертификаты и закрытые ключи etcd (
etcd.crt/etcd.key,patronietcd.crt/patronietcd.key), так как этот компонент не поддерживается командой разработки Pangolin.- Корневой сертификат, которым подписаны сертификаты etcd (может не совпадать с сертификатом, подписавшим сертификаты компонентов Pangolin, Pangolin Pooler и Pangolin Manager).
- Корневой сертификат
root.crt, которым подписаны сертификаты компонентов Pangolin, Pangolin Pooler и Pangolin Manager.
Для компонентов кластера введены настроечные параметры для установки пути до конфигурационного файла, включающего путь к контейнеру PKCS#12 и парольную фразу в засекреченном виде:
-
в конфигурационном файле pangolin-manager
postgresql.ymlпараметрpkcs12_config_pathв секциях:-
restapi:pkcs12_config_path: example.p12.cfg;
-
postgresql:authentication:replication/superuser/rewind:pkcs12_config_path: example.p12.cfg;
-
postgresql:parameters:serverssl.pkcs12_config_path: example.p12.cfg;
-
-
в конфигурационном файле СУБД Pangolin
postgresql.confпараметрserverssl.pkcs12_config_path; -
в конфигурационном файле Pangolin Pooler
pangolin-pooler.iniпараметрыclient_tls_pkcs12_config_pathиserver_tls_pkcs12_config_path; -
в строке подключения
psql:pkcs12_config_path(переменная окруженияPKCS12_CONFIG_PATH);pkcs12_passphrase(переменная окруженияPKCS12_PASSPHRASE) - используется для предоставления парольной фразы без ручного ввода в случае, если в файле.p12.cfgотсутствует поле passphrase. Парольная фраза может быть как в открытом, так и в засекреченном виде. Парольная фраза засекречивается утилитойpg_auth_password.
Формат конфигурационного файла .p12.cfg:
{
"pkcs12": "", // Путь к контейнеру PKCS#12
"passphrase": "" // Парольная фраза, засекреченная ключом на параметрах сервера, либо в открытом виде
}
Для валидации сертификатов компонентов, выполняющих подключение, по умолчанию используется полная цепочка сертификатов в контейнере PKCS#12, если в конфигурационных файлах не прописаны прежние параметры для установки цепочки доверенных сертификатов:
-
в конфигурационном файле Pangolin Manager
postgresql.ymlв секциях:-
restapi:cafile: /path/to/CAfile.pem;capath: /path/to/CAdir(параметр введен в версии 5.3.0);
-
postgresql:authentication:replication/superuser/rewind:sslrootcert: /path/to/CAfile.pem;sslrootpath: /path/to/CAdir(параметр введен в версии 5.3.0);
-
postgresql:parameters:ssl_ca_file: /path/to/CAfile.pem;ssl_ca_path: /path/to/CAdir(параметр введен в версии 5.3.0);
-
-
в конфигурационном файле СУБД Pangolin
postgresql.conf:ssl_ca_file = '/path/to/CAfile.pem';ssl_ca_path = '/path/to/CAdir'(параметр введен в версии 5.3.0);
-
в конфигурационном файле Pangolin Pooler
pangolin-pooler.ini:client_tls_ca_file = /path/to/CAfile.pem;server_tls_ca_file = /path/to/CAfile.pem;client_tls_ca_path = /path/to/CAdir(параметр введен в версии 5.3.0);server_tls_ca_path = /path/to/CAdir(параметр введен в версии 5.3.0);
-
в строке подключения
psql:sslrootcert = /path/to/CAfile.pem(переменная окруженияPGSSLROOTCERT);sslrootpath = /path/to/CAdir(переменная окруженияPGSSLROOTPATH(параметр введен в версии 5.3.0)).
Если один из этих параметров указан, то он будет использоваться для инициализации цепочки доверенных сертификатов для проверки сертификатов: со стороны сервера - клиентского сертификата, со стороны клиента - серверного сертификата. В дополнение к приведенным вариантам поиска доверенных сертификатов добавлен поиск среди доверенных сертификатов операционной системы. Настроечный параметр для этого не требуется.
Примечание:
Клиентские компоненты кластера (
psql) используют полную цепочку сертификатов в контейнере PKCS#12 для валидации сертификатов, если в строке подключения параметрsslmodeустановлен вverify-caилиverify-full.
Порядок поиска доверенных сертификатов:
- если не используются параметры, указывающие на файл, либо директорию с сертификатами: сначала в полной цепочке сертификатов из контейнера PKCS#12, затем в директории ОС, указанной по умолчанию;
- если используются параметры, указывающие на файл и/или директорию с сертификатами: сначала в файле, содержащем один или несколько доверенных сертификатов, затем в директории, если установлена, и, если в них не удалось найти нужный сертификат, то - в директории ОС, указанной по умолчанию.
Возможность конфигурирования сертификатов через PEM-файлы сохранена.
Реализация интерфейса получения контейнера PKCS#12 и парольной фразы к нему выполнена в виде плагинов (подключаемых модулей). В директории установки Pangolin созданы символические ссылки на плагины:
/usr/pangolin-{version}/lib/libpkcs12_exporter_plugin_link.so -> plugins/libpkcs12_exporter_plugin.so
/usr/pangolin-{version}/lib/libpkcs12_passphrase_plugin_link.so -> plugins/libpkcs12_passphrase_plugin.so
Для контроля сроков действия сертификатов и проверки подписи локальным корневым сертификатом в контейнерах PKCS#12 предоставляется утилита pkcs12_cert_info. По умолчанию поиск корневого сертификата также ведется в системных директориях по умолчанию. Утилита принимает на вход аргументы: путь к конфигурационному файлу со стратегией получения контейнера PCKS#12 и парольной фразы --pkcs12_config_path (-p), параметр включения проверки подписи --verify (-v), опционально путь к корневому сертификату --CAfile (-f), опционально путь к директории с корневым сертификатом --CApath (-d), опциональный параметр отключения поиска в директориях по умолчанию --no-CApath (-n).
Утилита pkcs12_cert_info доступна только для редакций Enterprise и Enterprise для ERP-систем.
Справка по использованию утилиты:
$ pkcs12_cert_info -h
Usage:
pkcs12_cert_info <option>...
Options:
--help [-h] This help
--pkcs12_config_path [-p] Path to config file with info how to get PKCS#12 file
--verify [-v] Check that PKCS#12 certificate trusted by anchor
--CAfile [-f] Path to root/intermediate certificate file
--CApath [-d] Path to root/intermediate certificate directory
--no-CApath [-n] Do not use the default directory of trusted certificates.
Pangolin product version information:
--product_version prints product name and version
--product_build_info prints product build number, date and hash
--product_component_hash prints component hash string
Вывод утилиты включает статус наличия закрытого ключа в контейнере, сроки действия сертификата и атрибуты, идентифицирующие сертификат (имя издателя и общее имя сертификата), а также сроки действия цепочки доверенных сертификатов. При введенном параметре проверки подписи выводится результат проверки, а также путь до использованного корневого сертификата.
Пример запуска утилиты:
$ pkcs12_cert_info -p /pg_ssl/server.p12.cfg
Certificate:
Issuer: CN=Pangolin_intermediate_CA
Validity
Not Before: Nov 8 10:52:13 2022 GMT
Not After : Nov 5 10:52:13 2032 GMT
Subject: CN=srv-0-154
Private key exists
Certificate chain:
Certificate #1:
Issuer: CN=Pangolin_CA
Validity
Not Before: Nov 8 10:52:13 2022 GMT
Not After : Nov 5 10:52:13 2032 GMT
Subject: CN=Pangolin_intermediate_CA
Certificate #2:
Issuer: CN=Pangolin_CA
Validity
Not Before: Nov 8 10:52:12 2022 GMT
Not After : Nov 5 10:52:12 2032 GMT
Subject: CN=Pangolin_CA
Использование сертификатов в локально хранящихся контейнерах PKCS#12 настраивается путем установки следующих параметров в конфигурационных файлах компонентов кластера:
- в конфигурационном файле Pangolin Manager
postgresql.ymlпараметрpkcs12_config_pathв секциях:restapi;pkcs12_config_path: example.p12.cfg;
postgresql:authentication:replication/superuser/rewind;pkcs12_config_path: example.p12.cfg;
postgresql:parameters;serverssl.pkcs12_config_path: example.p12.cfg;
- в конфигурационном файле СУБД Pangolin
postgresql.confпараметрserverssl.pkcs12_config_path; - в конфигурационном файле Pangolin Pooler
pangolin-pooler.iniпараметрыclient_tls_pkcs12_config_pathиserver_tls_pkcs12_config_path.
Изменение данных параметров не требует перезапуска компонентов кластера, достаточно выполнить перечитывание конфигурационных файлов.
Если для подключения к СУБД Pangolin требуется предоставить сертификат, и кластер настроен с использованием контейнеров PKCS#12, хранящихся в файловой системе, то в строке подключения psql необходимо указать параметр pkcs12_config_path с путем до конфигурационного файла .p12.cfg, содержащего путь к контейнеру PKCS#12 и парольную фразу в засекреченном виде.
Примеры запуска утилиты psql:
# В файле /pg_ssl/client.p12.cfg установлена парольная фраза.
$ psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full pkcs12_config_path=/pg_ssl/client.p12.cfg"
# В файле /pg_ssl/client.p12.cfg установлена парольная фраза. Путь к /pg_ssl/client.p12.cfg указан через переменную окружения.
$ PKCS12_CONFIG_PATH=/pg_ssl/client.p12.cfg psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full"
# В файле /pg_ssl/client.p12.cfg парольная фраза не установлена. Парольная фраза передается в строке подключения в засекреченном виде.
$ psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full pkcs12_config_path=/pg_ssl/client.p12.cfg pkcs12_passphrase=$enc$+tsiUlhEuNw4ASyvN6ta0A==$sys$mKb2BejR/MLUBzZQ2PaFs+zXGHDRljMWqX46w0CMmDWtjPDzwbxwNSfDAmVTT3Wu"
# В файле /pg_ssl/client.p12.cfg парольная фраза не установлена. Парольная фраза передается через переменную окружения в засекреченном виде.
$ PKCS12_PASSPHRASE='$enc$+tsiUlhEuNw4ASyvN6ta0A==$sys$mKb2BejR/MLUBzZQ2PaFs+zXGHDRljMWqX46w0CMmDWtjPDzwbxwNSfDAmVTT3Wu' psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full pkcs12_config_path=/pg_ssl/client.p12.cfg"
# В файле /pg_ssl/client.p12.cfg парольная фраза не установлена. Требуется ручной ввод парольной фразы.
$ psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full pkcs12_config_path=/pg_ssl/client.p12.cfg"
Enter passphrase for PKCS#12 file:
***
Внимание!
В режиме защищенного конфигурирования (
secure_config = on) управление параметром СУБД Pangolinserverssl.pkcs12_config_pathвыполняется на стороне хранилища секретов.
Если для валидации сертификатов не подходит полная цепочка сертификатов в контейнере PKCS#12, предоставляется возможность использования существующих параметров для установки путей к файлам с полными цепочками доверенных сертификатов или введенных в текущей работе новых параметров для установки директории с доверенными сертификатами:
- в конфигурационном файле Pangolin Manager.
postgresql.ymlв секциях:restapi;cafile: /path/to/CAfile.pem;capath: /path/to/CAdir;
postgresql:authentication:replication/superuser/rewind;sslrootcert: /path/to/CAfile.pem;sslrootpath: /path/to/CAdir;
postgresql:parameters;ssl_ca_file: /path/to/CAfile.pem;ssl_ca_path: /path/to/CAdir;
- в конфигурационном файле СУБД Pangolin
postgresql.conf:ssl_ca_file = '/path/to/CAfile.pem';ssl_ca_path = '/path/to/CAdir';
- в конфигурационном файле Pangolin Pooler
pangolin-pooler.ini:client_tls_ca_file = /path/to/CAfile.pem;server_tls_ca_file = /path/to/CAfile.pem;client_tls_ca_path = /path/to/CAdir;server_tls_ca_path = /path/to/CAdir;
- в строке подключения
psql:sslrootcert = /path/to/CAfile.pem(переменная окруженияPGSSLROOTCERT);sslrootpath = /path/to/CAdir(переменная окруженияPGSSLROOTPATH).
Поиск доверенных сертификатов также выполняется среди доверенных сертификатов операционной системы. Настроечный параметр для этого не требуется.
Пример подготовки директории с доверенными сертификатами:
# Добавление корневого сертификата в директорию с доверенными сертификатами
cp /path/to/panglolin.crt /pg_ssl/root_dir
c_rehash /pg_ssl/root_dir
Пример управления доверенными сертификатами операционной системы CentOS 7.9:
# Добавление корневого сертификата с именем Pangolin_CA в хранилище доверенных сертификатов ОС
sudo cp /path/to/panglolin.crt /etc/pki/ca-trust/source/anchors/
sudo update-ca-trust extract
trust list|grep Pangolin_CA
# Удаление корневого сертификата с именем Pangolin_CA из хранилища доверенных сертификатов ОС
sudo rm /etc/pki/ca-trust/source/anchors/panglolin.crt
sudo update-ca-trust extract
trust list|grep Pangolin_CA
Для контроля сроков действия сертификатов в контейнерах PKCS#12 предоставляется утилита pkcs12_cert_info. Утилита принимает на вход один аргумент: путь к конфигурационному файлу со стратегией получения контейнера PCKS#12 и парольной фразы. Вывод утилиты включает статус наличия закрытого ключа в контейнере, сроки действия сертификата и атрибуты, идентифицирующие сертификат (имя издателя и общее имя сертификата), а также сроки действия полной цепочки сертификатов.
В пользовательском конфигурационном файле инсталлятора введены следующие параметры:
-
Контейнер PKCS#12, помимо сертификата и закрытого ключа, может содержать полную цепочку сертификатов, включая корневой, которыми подписан сертификат. Для упрощения настройки доверенных SSL/TLS сертификатов в кластере предоставляется возможность использовать цепочку сертификатов из контейнера в качестве доверенных, установив параметр pkcs12_use_ca_chain_from_container в true.
# Флаг определяет, использовать ли полную цепочку сертификатов в контейнере PKCS#12 в качестве доверенной.
# Если флаг true, то использовать полную цепочку доверенных сертификатов в контейнере, если есть, в качестве доверенной, иначе - false.
pkcs12_use_ca_chain_from_container: true -
Если вариант с использованием полной цепочки сертификатов из контейнера PKCS#12 не подходит для настройки доверенных SSL/TLS сертификатов, предоставляется возможность установки доверенных сертификатов через следующие параметры:
pg_certs_pwd:
root_ca_file: "{{ '' | default('/pg_ssl/root.crt', true) }}" # Использовать PEM файл, который может содержать один или несколько доверенных сертификатов
root_ca_path: "{{ '' | default('/pg_ssl/root_dir', true) }}" # Использовать подготовленную директорию с доверенными сертификатами -
Параметры для поддержки использования сертификатов и закрытых ключей из контейнеров PKCS#12, расположенных в файловой системе:
# Активация получения контейнера PKCS#12 и парольной фразы к нему из файловой системы.
# Если флаг true, то устанавливаются плагины libpkcs12_passphrase_plugin.so и libpkcs12_exporter_plugin.so.
# Если флаг false, то используется прежний подход для получения ключевой информации: из файлов в PEM формате. Плагин не устанавливается.
pkcs12_plugin_enable: true
pg_certs_pwd:
# Установка параметра p12_path обязательна при активации флага pkcs12_plugin_enable.
server_p12:
p12_path: "{{ '' | default('/home/postgres/ssl/server.p12', true) }}" # Путь в файловой системе к контейнеру PKCS#12 с серверной ключевой парой и цепочкой доверенных сертификатов.
p12_pass: "{{ '' | default('', true) }}" # Парольная фраза для доступа к контейнеру PKCS#12 (server.p12), засекреченная средствами Ansible Vault (в ходе установки парольная фраза рассекречивается и сохраняется в файл по пути p12_config_path (см. ниже) в засекреченном виде на ключе, сгенерированном на параметрах сервера). Параметр обязателен в случае установки параметра p12_path.
p12_config_path: "{{ '' | default('/home/postgres/ssl/server.p12.cfg', true) }}" # Путь к файлу в JSON-формате, содержащему параметр ("passphrase") для получения парольной фразы для доступа к контейнеру PKCS#12, засекреченную на ключе, сгенерированном на параметрах сервера, и параметр ("pkcs12") для получения контейнера PKCS#12. Параметр обязателен при установке флага pkcs12_plugin_enable в true.
postgres_p12:
p12_path: "{{ '' | default('/home/postgres/ssl/client.p12', true) }}" # Путь в файловой системе к контейнеру PKCS#12 с клиентской ключевой парой пользователя postgres и цепочкой доверенных сертификатов
p12_pass: "{{ '' | default('', true) }}"
p12_config_path: "{{ '' | default('/home/postgres/ssl/client.p12.cfg', true) }}"
pgbouncer_p12:
p12_secman_integration: true
p12_path: "{{ '' | default('/home/postgres/ssl/pgbouncer.p12', true) }}" # Путь в файловой системе к контейнеру PKCS#12 с клиентской ключевой парой Pangolin Pooler и цепочкой доверенных сертификатов для подключения к СУБД Pangolin
p12_pass: "{{ '' | default('', true) }}"
p12_config_path: "{{ '' | default('/home/postgres/ssl/pgbouncer.p12.cfg', true) }}"
patroni_p12:
p12_path: "{{ '' | default('/home/postgres/ssl/patroni.p12', true) }}" # Путь в файловой системе к контейнеру PKCS#12 с клиентской ключевой парой и цепочкой доверенных сертификатов для подключения Pangolin Manager к СУБД Pangolin
p12_pass: "{{ '' | default('', true) }}"
p12_config_path: "{{ '' | default('/home/postgres/ssl/patroni.p12.cfg', true) }}"
etcd_cert: "{{ '' | default('/home/postgres/ssl/etcd.crt', true) }}" # Путь к сертификату для взаимодействия экземпляров ETCD. Может быть подписан сертификатом, отличным от сертификата, подписавшего сертификаты компонентов Pangolin, Pangolin Pooler, Pangolin Manager. Тогда потребуется указать путь к корневому сертификату в параметре etcd_root_ca.
etcd_key: "{{ '' | default('/home/postgres/ssl/etcd.key', true) }}" # Путь к приватному ключу для взаимодействия экземпляров ETCD
etcd_root_ca: "{{ '' | default('/home/postgres/ssl/root_etcd.crt', true) }}" # Корневой сертификат для проверки действительности сертификатов ETCDПримечания к ключам словаря
pg_certs_pwd:-
p12_path- путь в файловой системе к контейнеру PKCS#12 с ключевой парой и цепочкой доверенных сертификатов. -
p12_pass- парольная фраза для доступа к контейнеру PKCS#12, засекреченная средствами Ansible Vault. В ходе установки парольная фраза рассекречивается и сохраняется в файл по путиp12_config_pathв засекреченном виде на ключе, сгенерированном на параметрах сервера. -
p12_config_path- путь к файлу в JSON-формате.p12.cfg, содержащему поле "passphrase" с парольной фразой для доступа к контейнеру PKCS#12 и полеpkcs12с путем до контейнера PKCS#12. Файл формируется инсталлятором: в полеpkcs12прописывается путь к контейнеру PKCS#12 (из параметраp12_path), в полеpassphraseпомещается парольная фраза перекодированная ключом, сгенерированном на основе параметров сервера (из параметраp12_pass). Формат файла:{
"pkcs12": "", // Путь к контейнеру PKCS#12
"passphrase": "" // Парольная фраза, засекреченная ключом на параметрах сервера, либо в открытом виде
} -
etcd_root_ca- путь к корневому сертификату ETCD. Параметр является обязательным при настройке SSL между узлами etcd.
-
-
Параметр для выбора способа хранения парольной фразы в конфигурационном файле
.p12.cfg, путь к которому указывается в параметреp12_config_path: в засекреченном или в открытом виде.# Флаг, определяющий способ хранения парольной фразы к контейнеру PKCS#12.
# Если флаг true, то парольная фраза засекречивается ключом, генерируемым на основе параметров сервера, иначе - парольная фраза в открытом виде.
pkcs12_encrypt_passphrase: true
Отключение функциональности
Отключение функциональности выполняется переконфигурированием кластера на использование сертификатов в PEM-формате без перезапуска кластера. Достаточно выполнить перечитывание конфигурационных файлов.
Управление сертификатами для Pangolin с Secret Management System
В целях повышения уровня информационной безопасности новая функциональность обеспечивает хранение и использование контейнеров PKCS#12 и парольных фраз к ним в хранилище секретов и сертификатов Secret Management System (SecMan) и их ротацию на промышленных стендах.
В Pangolin появляется несколько новых конфигурационных файлов. Эти файлы используются следующими компонентами кластера: СУБД Pangolin, Pangolin Pooler и Pangolin Manager. Каждый компонент использует свой конфигурационный файл. Данные, указанные в файлах, используются для генерации контейнеров PKCS#12, содержащих сертификат и частный ключ. Контейнер создается и хранится в SecMan и возвращается компоненту кластера по запросу.
Описание файла:
{
"pkcs12": {
"name": "", // Имя роли
"common_name": "", // CN для сертификата
"email": "", // Почтовый адрес владельца сертификата
"alt_names": "", // Альтернативные имена субъектов в списке, разделенном запятыми. Это могут быть имена хостов или адреса электронной почты
"ip_sans": "", // Альтернативные имена субъекта IP в списке с разделителями-запятыми. Действителен только в том случае, если роль разрешает IP SAN (по умолчанию)
"other_sans": "", // Настраиваемые SAN со строкой OID/UTF8
"exclude_cn_from_sans": "" // Параметр, включающий/выключающий возможность исключить common_name из DNS или электронной почты SAN
}
}
Примеры файлов для компонентов кластера:
-
Pangolin:
{
"pkcs12": {
"name": "server",
"common_name": "server",
"email": "test@test.ru",
"alt_names": "",
"ip_sans": "",
"other_sans": "",
"exclude_cn_from_sans": ""
}
} -
Pangolin Pooler:
{
"pkcs12": {
"name": "pgbouncer",
"common_name": "pgbouncer",
"email": "test@test.ru",
"alt_names": "",
"ip_sans": "",
"other_sans": "",
"exclude_cn_from_sans": ""
}
} -
Pangolin Manager:
{
"pkcs12": {
"name": "patroni",
"common_name": "patroni",
"email": "test@test.ru",
"alt_names": "",
"ip_sans": "",
"other_sans": "",
"exclude_cn_from_sans": ""
}
}
Для того, чтобы использовать новые конфигурационные файлы, пути к ним нужно прописать в основных конфигурационных файлах:
-
В случае кластера. В файле конфигурации Pangolin Manager
postgresql.ymlв параметреpkcs12_config_pathв секцияхrestapi,postgresql/authentication/replication,postgresql/authentication/superuserиpostgresql/authentication/rewind, а также в параметреpkcs12_config_pathв секцииpostgresql/parameters:restapi:
pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата
postgresql:
authentication:
replication:
pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата
postgresql:
authentication:
superuser:
pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата
postgresql:
authentication:
rewind:
pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата
postgresql:
parameters:
serverssl.pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата -
В случае standalone конфигурации. В файле конфигурации СУБД Pangolin
postgresql.conf(для случая конфигурации standalone) в параметреserverssl.pkcs12_config_path:serverssl.pkcs12_config_path = "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификатаВнимание!При включенной защите параметров конфигурационный параметр
serverssl.pkcs12_config_pathдолжен быть под защитой, а его значение должно устанавливаться только через SecMan. -
В файле конфигурации Pangolin Pooler
pangolin-pooler.iniв параметреclient_tls_pkcs12_config_pathиserver_tls_pkcs12_config_path:client_tls_pkcs12_config_path = "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата
server_tls_pkcs12_config_path = "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата
Ротация сертификатов, получаемых из SecMan
Ротация сертификатов, используемых компонентами кластера, осуществляется агентом, который:
- контролирует срок действия сертификатов, полученных из SecMan;
- обновляет сертификаты на SecMan при приближении конца их срока действия;
- контролирует внешнее изменение сертификатов, обновление на SecMan, а также отзыв сертификата;
- запускает процесс обновления сертификатов на кластере.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Агент pangolin-certs-rotate
Агент представляет собой исполняемый файл pangolin-certs-rotate, который настраивается для работы с конкретным хранилищем сертификатов через систему плагинов. Расположен в директории /opt/pangolin-common/bin/ и запускается отдельной службой pangolin-certs-rotate.service до запуска служб postgresql.service, pangolin-pooler.service и pangolin-manager.service.
Период проверки сертификатов и их обновления настраивается в конфигурационном файле агента. Первая проверка происходит на его старте. Следующий запуск агента может произойти до окончания заданного промежутка времени, если интервал между датой истечения и датой выпуска одного из сертификатов достигает 80% внутри текущего периода. Таким образом, агент будет запущен в этот момент времени, и следующий период будет отсчитываться уже от этой точки. Если в процессе работы агента произошла ошибка, то его следующий запуск произойдет через заданный в конфигурации период ожидания.
На схеме ниже приведены этапы работы агента:
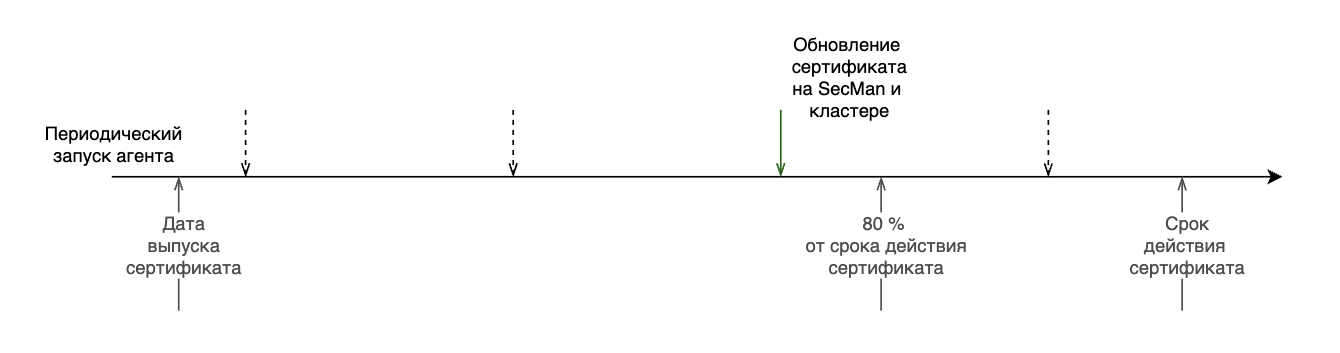
Если обновление сертификата на SecMan произошло без участия агента, то кластер до следующего запуска агента будет работать со старым сертификатом (в том числе, если сертификат отозван):
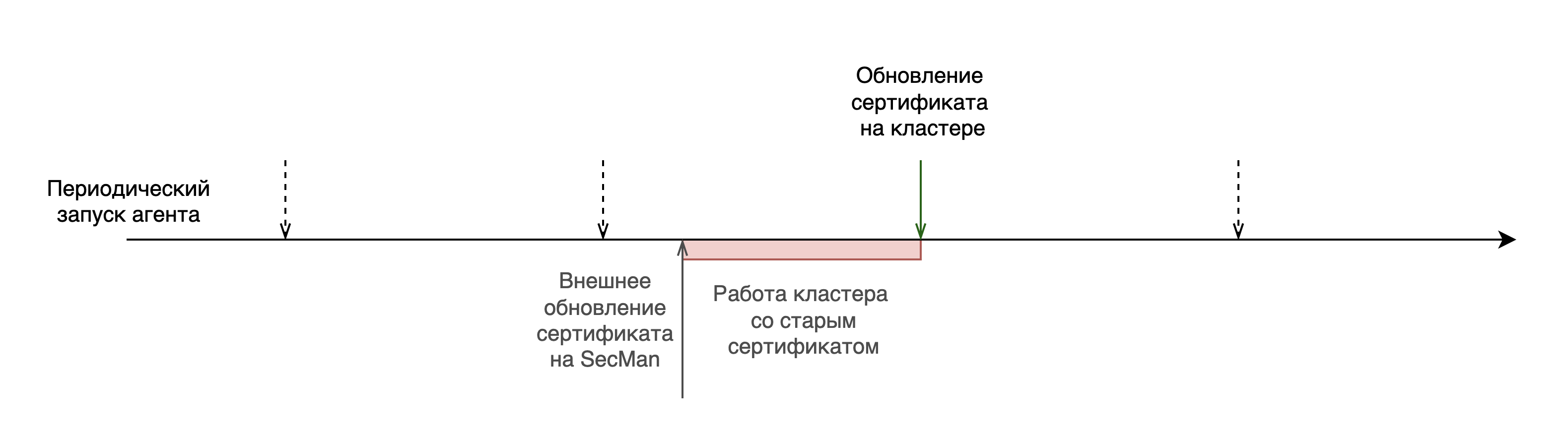
Для взаимодействия с SecMan применяется плагин remote_secman_pki_plugin, который использует протокол http/https, а также параметры подключения кластера. Параметры хранятся в засекреченном хранилище /etc/pangolin-security-utilities/enc_connection_settings_cert.cfg. Для рассекречивания файла агент использует плагин кодирования.
Процесс инсталляции агента
Настройка работы агента происходит на этапе установки кластера Pangolin (при автоматизированном способе установки):
При ручной установке требуется установить rpm/deb-пакет компонента, при помощи пакетного менеджера, и проделать действия по инициализации - вручную.

Для включения агента ротации сертификатов в конфигурационном файле инсталлятора custom_file_template.yml требуется добавить параметр enable в yaml-словарь pangolin-certs-rotate. Все параметры агента сохраняются в конфигурационном файле, который тот использует при инициализации:
-
путь к конфигурационному файлу агента задается при помощи параметра
agent_config, который находится вpangolin-certs-rotate. По умолчанию используется конфигурационный файл/etc/pangolin-certs-rotate/pangolin-certs-rotate.yml; -
путь к директории для лог-файлов задается с помощью параметра
log_directoryв yaml-словареpangolin-certs-rotate. По умолчанию используется путь/var/log/pangolin-certs-rotate; -
имя лог-файла задается параметром
log_filenameв yaml-словареpangolin-certs-rotate. По умолчанию используется имя pangolin-certs-rotate; -
уровень логирования задается параметром
log_levelв yaml-словареpangolin-certs-rotate. Возможны уровни:debug | info | warning | error | fatal. По умолчанию используется уровеньinfo; -
методы записи лога задаются параметром
log_destinationв yaml-словареpangolin-certs-rotate. Возможные методы:console, fileпри любой комбинации методов. По умолчанию используется методconsole; -
включить/отключить функцию ротации сертификатов можно с помощью параметра
enable_updateв словареpangolin-certs-rotate:certs. По умолчанию функция включена; -
период проверки сертификатов настраивается при помощи параметра
poll_period_in_min, который находится в словареpangolin-certs-rotate:certsи задается в минутах. По умолчанию период работы будет равен 60 минутам; -
время ожидания повторного запуска агента в случае ошибки устанавливается в параметре
retry_interval_in_sec, который находится в словареpangolin-certs-rotate:certsи задается в секундах. По умолчанию тайм-аут будет равен 30 секундам; -
количество повторных проверок в случае ошибки задается параметром
retry_attempts_num, который находится в словареpangolin-certs-rotate:certs. По умолчанию настроена одна попытка; -
список сертификатов, за сроком действия которых «следит» агент, определяются группами
locations, которые находятся в словареpangolin-certs-rotate:certs:watch. В каждой группе задается:-
в словаре
pathsмножество конфигурационных файлов сертификатов*.p12.cfg; -
в словаре
on_updateмножество зависимых от сертификатов команд, необходимых для обновления компонентов кластера.Внимание!Были реализованы только следующие команды:
sudo systemctl reload postgresql
sudo systemctl reload pangolin-manager
sudo systemctl reload pangolin-pooler
-
Формат конфигурационного файла инсталлятора для агента ротации:
pg-certs-rotate-agent:
# Флаг определяет, запускается ли агент ротации.
# Если флаг true, то агент будет запущен, иначе - false.
enable: true
# Путь к конфигурационному файлу агента в YAML-формате
agent_config: "{{ '' | default('/etc/pangolin-certs-rotate/pangolin-certs-rotate.yml', true) }}"
# Путь к директории для лог-файлов
log_directory: "{{ '' | default('/var/log/pangolin-certs-rotate', true) }}"
# Имя лог-файла
log_filename: "{{ '' | default('pangolin-certs-rotate', true) }}"
# Уровень логирования
log_level: "{{ '' | default('info', true) }}"
# Методы записи лога
log_destination: "{{ '' | default('console', true) }}"
certs:
# Включить/выключить автоматическое обновление сертификатов
enable_update: "{{ '' | default(true, true) }}"
# Период проверки валидности сертификатов [мин]
poll_period_in_min: "{{ '' | default(60, true) }}"
# Тайм-аут на повторный запуск в случае ошибки [c]
retry_interval_in_sec: "{{ '' | default(30, true) }}"
# Количество попыток после неудачи
retry_attempts_num: "{{ '' | default(1, true) }}"
# Множество обновляемых сертификатов
watch:
- locations:
# Множество файлов конфигураций сертификатов
paths:
- path/to/cert/configuration/1_1
- path/to/cert/configuration/1_N
# Множество команд, которые требуется выполнить после обновления хотя бы одного из сертификатов
on_update:
- update command 1_1
- update command 1_N
# Множество файлов конфигураций
- locations:
# Множество обновляемых сертификатов
paths:
- path/to/cert/configuration/M_1
- path/to/cert/configuration/M_N
# Множество команд, которые требуется выполнить после обновления хотя бы одного из сертификатов
on_update:
- update command M_1
- update command M_N
Для каждого сертификата существует конфигурационный файл *.p12.cfg. Если кластер получает сертификат из SecMan, то в словаре pkcs12 будут описаны параметры доступа к сертификату на SecMan:
{
"pkcs12": {
"name": "", // Имя роли
"common_name": "", // CN для сертификата
"email": "", // Почтовый адрес владельца сертификата
"alt_names": "", // Альтернативные имена субъектов в списке, разделенном запятыми. Это могут быть имена хостов или адреса электронной почты
"ip_sans": "", // Альтернативные имена субъекта IP в списке с разделителями-запятыми. Действителен только в том случае, если роль разрешает IP SAN (по умолчанию)
"other_sans": "", // Настраиваемые SAN со строкой OID/UTF8
"exclude_cn_from_sans": "" // Параметр, включающий/выключающий возможность исключить common_name из DNS или электронной почты SAN
}
}
Если кластер использует локальный сертификат, то в словаре pkcs12 будет указан путь к локальному сертификату. Чтобы агент ротации мог обновить файл локального сертификата, необходимо в конфигурационном файле *.p12.cfg добавить словарь secman с описанием параметров доступа к сертификату на SecMan:
{
"secman": {
"name": "", // Имя роли
"common_name": "", // CN для сертификата
"email": "", // Почтовый адрес владельца сертификата
"alt_names": "", // Альтернативные имена субъектов в списке, разделенном запятыми. Это могут быть имена хостов или адреса электронной почты
"ip_sans": "", // Альтернативные имена субъекта IP в списке с разделителями-запятыми. Действителен только в том случае, если роль разрешает IP SAN (по умолчанию)
"other_sans": "", // Настраиваемые SAN со строкой OID/UTF8
"exclude_cn_from_sans": "" // Параметр, включающий/выключающий возможность исключить common_name из DNS или электронной почты SAN
}
}
Настройка параметров запущенного агента
Примечание:
В случае кластерной конфигурации агент запускается на каждом из его узлов. Далее описывается настройка агента для standalone-конфигурации или при запуске на одном узле.
Чтобы изменить параметры запущенного агента, требуется обновить конфигурационный файл агента, который был указан в процессе инсталляции, и перезагрузить параметры службы pangolin-certs-rotate.service:
На первом шаге необходимо заполнить конфигурационный файл агента в формате YAML:
log:
directory: PATH/TO/LOG/DIRECTORY
filename: LOG_FILE_NAME
level: debug | info | warning | error | fatal
destination: console, file
certs:
enable_update: bool
poll_period_in_min: unsigned integer
retry_interval_in_sec: unsigned integer
retry_attempts_num: unsigned integer
watch:
- locations:
paths:
- PATH/TO/CERT/CONFIGURATION/1
- PATH/TO/CERT/CONFIGURATION/N
on_update:
- bash command 1
- bash command N
- locations:
paths:
- PATH/TO/CERT/CONFIGURATION/1
- PATH/TO/CERT/CONFIGURATION/M
on_update:
- bash command 1
- bash command M
Чтобы включить или отключить ротацию сертификатов, требуется установить значение ключа enable_update, который находится в yaml-словаре certs, в значение true или false соответственно.
Для изменения периода работы агента нужно задать новое значение ключа poll_period_in_min (в минутах), который тоже находится в словаре certs.
Для изменения времени ожидания с целью перезапуска агента (в случае ошибки) нужно задать новое значение ключа retry_interval_in_sec (в секундах). Ключ расположен в словаре certs.
Чтобы изменить количество повторных попыток в случае ошибки, нужно задать новое значение ключа retry_attempts_num, который находится в yaml-словаре certs.
Список сертификатов для обработки агентом задается в виде групп, определенных через ключ locations. Для каждой группы должна быть определена команда обновления сертификатов на кластере. Если один из сертификатов группы устаревает, обновляется на SecMan или появляется в списке отозванных, то выполняется команда, указанная по ключу on_update.
Далее приведен пример конфигурационного файла агента ротации сертификатов для конфигурации standalone-patroni-etcd-pgbouncer без контроля отозванных сертификатов:
certs:
enable_update: true
poll_period_in_min: 1440
retry_interval_in_sec: 60
retry_attempts_num: 1
watch:
- locations:
paths:
- "/home/postgres/ssl/server.p12.cfg"
- "/home/postgres/ssl/patroni.p12.cfg"
on_update:
- sudo systemctl reload pangolin-manager
- locations:
paths:
- "/home/postgres/ssl/server.p12.cfg"
- "/home/postgres/ssl/pgbouncer.p12.cfg"
on_update:
- sudo systemctl reload pangolin-pooler
При изменении имени конфигурационного файла агента требуется обновить параметры службы pangolin-certs-rotate.service. Имя файла указывается в качестве аргумента исполняемого файла /opt/pangolin-certs-rotate/bin/pangolin-certs-rotate:
ExecStart=/opt/pangolin-common/bin/pangolin-certs-rotate --config=/etc/pangolin-certs-rotate/pangolin-certs-rotate.yml
Для применения настроек необходимо перезагрузить службу:
sudo systemctl restart pg-certs-rotate_agent.service
Процесс обновления сертификатов на SecMan
При успешном подключении к SecMan, агент запрашивает каждый контролируемый сертификат отдельно, используя метод read. Метод fetch не используется, чтобы исключить автоматический перевыпуск сертификатов без их последующего обновления на кластере. Если интервал между датой истечения и датой выпуска сертификата достигает 80% внутри следующего периода (или если сертификат попал в список отозванных), то агент, используя метод generate, запрашивает его перевыпуск. Если в процессе обновления сертификата произошла ошибка, то следующая попытка откладывается на другую итерацию работы агента через период ожидания, определенный в конфигурационном файле.
Примечание:
Контроль за попаданием сертификатов в список отозванных реализуется в сервисе обновления CRL. Сервис ротации сертификатов сообщает сервису обновления CRL серийные номера используемых на кластере сертификатов. Если сервис обновления CRL находит сертификаты в списке отозванных, то сообщает об этом сервису ротации сертификатов, после чего запускается процесс их обновления на SecMan.
Процесс обновления сертификатов на кластере
При успешном обновлении на SecMan хотя бы одного сертификата из списка (или если обновление сертификатов на SecMan произошло без участия агента) агент запускает процесс обновления сертификатов на кластере. Для этой проверки он сохраняет серийные номера сертификатов, которые периодически сравнивает с полученными от SecMan.
Процесс обновления сертификатов на кластере состоит в перезагрузке параметров узла кластера или сервера конфигурации standalone с помощью команды, указанной в конфигурационном файле.
Внимание!
Агент не контролирует ошибки, которые могут произойти в процессе обновления сертификатов на кластере.
Отключению функциональности
Отключение производится путем удаления описанных выше конфигурационных параметров для соответствующих компонентов.
Поддержка CRL в компонентах кластера Pangolin
CRL представляет собой список сертификатов, которые УЦ пометил как отозванные (при этом сертификаты с истекшим сроком действия не вносятся в этот список). Каждая запись в списке включает идентификатор отозванного сертификата и дату отзыва. Дополнительная информация включает в себя ограничение по времени, если отзыв применяется в течение определенного периода времени, а также причину отзыва.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Начиная с версии 5.4.0, использование файлов CRL поддерживается всеми компонентами кластера, а автоматическое обновление неактуальных файлов CRL доступно как часть функциональности агента ротации сертификатов pangolin-certs-rotate.
Настройка CRL
Для поддержки CRL имеются следующие параметры в конфигурационных файлах компонентов:
-
postgresql.conf(Pangolin):-
ssl_crl_file- путь к файлу CRL, по которому выполняется проверка статуса клиентских сертификатов; -
ssl_crl_dir- путь к директории с файлами CRL, по которым выполняется проверка аннулирования клиентских сертификатов.
Примечание:
При включенной защите параметров
ssl_crl_fileиssl_crl_dirинициализируются значениями из защищенного хранилища секретов. -
-
Клиентские утилиты, использующие библиотеку
libpq(psql):sslcrl(переменная окруженияPGSSLCRL) - путь к файлу CRL, по которому выполняется проверка статуса серверных сертификатов;sslcrldir(переменная окруженияPGSSLCRLDIR) - путь к директории с файлами CRL, по которым выполняется проверка статуса серверных сертификатов.
-
postgres.yml(Pangolin Manager):- в секции restapi:
crlfile- путь к файлу CRL;crlpath- путь к директории с файлами CRL, по которым выполняется проверка аннулирования клиентских сертификатов;
- в секции
postgresql/authentication/(replication/rewind/superuser):sslcrldir- путь к директории с файлами CRL, по которым выполняется проверка аннулирования серверного сертификата Pangolin;
- в секции
postgresql/parameters:sslcrldir- путь к каталогу с файлами CRL, по которым выполняется проверка аннулирования клиентских сертификатов;
- в секции restapi:
-
pangolin-pooler.ini(Pangolin Pooler):client_tls_crl_file- путь к файлу CRL;client_tls_crl_path- путь к директории с файлами CRL, по которым выполняется проверка аннулирования клиентских сертификатов;server_tls_crl_file- путь к файлу CRL;server_tls_crl_path- путь к директории с файлами CRL, по которым выполняется проверка аннулирования серверного сертификата Pangolin.
В параметрах конфигурации, приведенных выше, должны использоваться пути к существующим файлам CRL, иначе при включенном TLS/SSL запуск компонента завершится ошибкой.
Примечание:
Для использования директории c файлами CRL необходимо для каждого из файлов создать в этой директории символические ссылки, названные по хеш-значению от содержимого соответствующего файла CRL. Хеш-значения рассчитываются утилитой
c_rehash.Пример вызова утилиты:
c_rehash /pg_ssl/crlЗа подробностями обратитесь к документации OpenSSL.
Для обеспечения автоматического обновления файлов CRL расширяется функциональность агента ротации сертификатов pangolin-certs-rotate.
Запуск агента выполняется до запуска служб postgresql.service (для конфигурации standalone), pangolin-manager.service (для кластерной конфигурации) и pangolin-pooler.service, чтобы для каждого из компонентов выгрузить файлы CRL из CDP (CRL Distribution Point - точка распространения CRL). Компоненты кластера не запустятся, если файлы CRL прописаны в конфигурационных файлах, но отсутствуют на файловой системе. После выполнения первого цикла выгрузки CRL агент нотифицирует systemd о готовности в случае успешной выгрузки всех файлов CRL, иначе переводит статус службы в failed. Время цикла выгрузки CRL ограничено за счет установки времени ожидания в 30 сек на каждый запрос к CDP.
Примечание:
Агент не удаляет файлы CRL из файловой системы, только заменяет их на новые, поэтому исчезновение файлов CRL в процессе работы компонентов является результатом ручного вмешательства. Для восстановления удаленных файлов CRL перезапустите службу агента ротации и обновления CRL.
Исполняемый файл агента принимает в качестве аргумента командной строки путь к конфигурационному файлу агента pg_certs_rotate.yml, который расположен в директории /etc/postgres и включает следующие параметры:
- в секции log:
directory- путь к директории для лог-файлов (обязательный параметр при выводе лога в файл);filename- имя лог-файла (по умолчаниюpangolin-certs-rotate.log);level- (trace|debug|info|warning|error) - уровень логирования (по умолчаниюinfo);destination- методы записи лога (комбинируются через запятую):console- в стандартный поток вывода или ошибок (в случае запуска под управлением службы - в системный журнал). Значение по умолчанию;file- в файл.
- в секции crl:
enable_update(true|false) - включить/выключить автоматическое обновление CRL (по умолчаниюfalse);poll_period_in_min- интервал времени, определяющий период проверки наличия обновленных CRL файлов (задается как целое неотрицательное число в минутах; по умолчанию 60 минут; 0 для отключения периодической проверки CRL). Опрос CDP должен выполняться не реже данного периода;retry_interval_on_expire_in_sec- интервал повторных попыток выгрузки CRL, для которых дата публикации или дата окончания срока действия уже наступили (задается как целое положительное число в секундах, по умолчанию 30 секунд);retry_interval_on_failure_in_sec- интервал времени, через который выполняются повторные попытки выгрузки CRL после неудачи (задается как целое положительное число в секундах, по умолчанию 30 секунд);retry_attempts_num_on_failure- количество попыток выгрузки CRL по списку URI для данного пути расположения файла CRL после неудачи (по умолчанию 1 попытка);crl_file_perm- права доступа, устанавливаемые на выгружаемые файлы CRL (задается в восьмеричном формате, по умолчанию 0644).
- в секции watch:
locations- секция включает списки путей до файлов, обновление которых отслеживается (path), а также куда выгружаются новые CRL из CDP (uri):path- путь к файлу CRL;uri- массив URI для выгрузки CRL (основной и резервные);
on_update- список выполняемых команд, если файл CRL изменился (перечитывание конфигурации компонентами кластера).
Далее приведен формат конфигурационного файла агента ротации сертификатов и обновления CRL:
log:
directory: /pgerrorlogs/05/pangolin-certs-rotate
filename: pangolin-certs-rotate.log
level: info
destination: console,file
crl:
enable_update: false
poll_period_in_min: 60
retry_interval_on_expire_in_sec: 30
retry_interval_on_failure_in_sec: 30
retry_attempts_num_on_failure: 1
crl_file_perm: 0644
watch:
- locations:
- path: CRLPATH_1
uri:
- URI_1
- URI_N
- path: CRLPATH_N
uri:
- URI_1
- URI_N
on_update:
- sudo systemctl reload postgresql
- locations:
- path: CRLPATH_1
uri:
- URI_1
- URI_N
- path: CRLPATH_N
uri:
- URI_1
- URI_N
on_update:
- sudo systemctl reload pangolin-manager
- locations:
- path: CRLPATH_1
uri:
- URI_1
- URI_N
- path: CRLPATH_N
uri:
- URI_1
- URI_N
on_update:
- sudo systemctl reload pangolin-pooler
Справка по аргументам командной строки агента:
pangolin-certs-rotate --help
Allowed options:
-h [ --help ] produce this help message
-p [ --pid-file ] arg (=/var/run/pangolin-certs-rotate/pangolin-certs-rotate.pid)
path to agent's PID file
-c [ --config ] arg (=/etc/pangolin-certs-rotate/pangolin-certs-rotate.yml)
path to agent's configuration file
-d [ --dry-run ] check config file format and exit
Агент поддерживает режим пробного запуска с ключом --dry-run. В этом режиме проверяется корректность конфигурационного файла с последующим завершением выполнения. Результат проверки определяется кодом возврата: 0 - конфигурационный файл валидный, иначе 1. Информация об ошибке выводится в лог.
На старте агент сохраняет PID своего процесса в файл (по умолчанию /var/run/pangolin-certs-rotate/pangolin-certs-rotate.pid). Файл с PID процесса используется для предотвращения запуска еще одного экземпляра агента и в команде на ротацию лог-файла. Ротация лог-файлов агента выполняется с помощью утилиты logrotate. Файл конфигурации для logrotate расположен в /etc/logrotate.d/pangolin-certs-rotate и имеет следующее содержимое:
/pgerrorlogs/05/pangolin-certs-rotate/pangolin-certs-rotate.log {
rotate 10
dateext
daily
missingok
notifempty
compress
create 0640 postgres postgres
sharedscripts
postrotate
[ ! -f /var/run/pangolin-certs-rotate/pangolin-certs-rotate.pid ] || /bin/kill -USR1 `cat /var/run/pangolin-certs-rotate/pangolin-certs-rotate.pid 2> /dev/null` 2>/dev/null
endscript
}
Права доступа к директории с логами /pgerrorlogs/05/pangolin-certs-rotate:
drwxr-x--- 2 postgres postgres
Если включена автоматическая проверка обновления CRL (crl:enable_update), агент в установленное время подключается к первой доступной CDP по HTTP (crl:watch:locations:uri), выгружает файл CRL и сохраняет его в PEM-формате по пути, определенному в параметре crl:watch:locations:path (если файл CRL еще ни разу не выгружался или изменился в точке распространения).
Выгруженный файл CRL с истекшим сроком действия не сохраняется в файловой системе и не удаляется из нее.
Внимание!
Агент не проверяет подпись выгруженного файла CRL. Данную проверку выполняют компоненты кластера, для которых файл CRL предназначен.
Агент создает символическую ссылку на выгруженный файл CRL. Символическая ссылка именуется хеш-значением, рассчитанным по содержимому файла CRL. Если файл CRL до выгрузки нового уже существовал, то символическая ссылка на старый файл удаляется, чтобы не засорять файловую систему, поскольку хеш-значения от старого и нового файлов CRL будут отличаться. Символическая ссылка требуется, чтобы иметь возможность указывать директорию с файлами CRL в конфигурационных файлах компонентов кластера, так как OpenSSL выполняет поиск CRL по хеш-значению.
Если выгруженный файл CRL не является истекшим и не содержит серийные номера сертификатов, находящихся под контролем сервиса ротации сертификатов, агент выполнит команды перечитывания конфигурации соответствующих компонентов (crl:watch:locations:on_update). Если же файл CRL содержит серийные номера таких сертификатов, то соответствующие сертификаты будут перевыпущены сервисом ротации, а команды перечитывания конфигурации выполнятся после процедуры перевыпуска сертификатов.
Внимание!
Агент не контролирует ошибки, которые могут произойти в процессе перечитывания конфигурации компонентами кластера.
Для защиты файлов CRL от их перезаписи агентом в процедуре инициализации SSL контекста в компонентах кластера применяется блокировка на базе flock(). В процессе работы создается временный файл /tmp/.crl.lock. Агент удерживает для него эксклюзивную блокировку на время записи выгруженных CRL-файлов, тогда как компоненты кластера (на старте или при перечитывании параметров) используют для него разделяемую блокировку. Таким образом, компоненты кластера могут одновременно, не мешая друг другу, загружать файлы CRL, блокируясь только при обновлении файлов CRL агентом.
Для каждого файла CRL проверка обновления выполняется:
- при запуске агента;
- с периодичностью, определенной в параметре
crl:poll_period_in_min, если значение параметра больше 0; - в момент следующей публикации CRL (дата в поле CRL файла
NextCRLPublish) и через каждый интервал времени, определяемый параметромcrl:retry_interval_on_expire_in_sec(если после наступления даты публикации CRL еще не выпущен); - в момент истечения срока действия CRL (дата в поле CRL файла
NextUpdate) и через каждый интервал времени, определяемый параметромcrl:retry_interval_on_expire_in_sec, если после истечения срока действия CRL еще не выпущен; - спустя интервал времени, задаваемый параметром
crl:retry_interval_on_failure_in_sec, после неудачной выгрузки; - по требованию путем перезапуска службы агента (на его старте):
sudo systemctl restart pangolin-certs-rotate.service
-
при выполнении команды reload и изменении конфигурационного файла агента:
- изменился список URI;
- добавлена новая команда в
crl:watch:locations:on_update; - добавлен новый путь к файлу CRL.
sudo systemctl reload pangolin-certs-rotate.service
Примечание:
Дата следующей проверки обновления для каждого файла CRL рассчитывается индивидуально.
Процесс инсталляции
Пути к файлу CRL и директории, содержащей файлы CRL, задаются в конфигурационном файле инсталлятора и одинаковы для всех компонентов кластера. Ниже приведен формат его полей для настройки путей к файлам CRL:
pg_certs_pwd:
crl_file: "{{ '' | default('/pg_ssl/crl/root.crl', true) }}" # Путь к CRL файлу
crl_path: "{{ '' | default('/pg_ssl/crl', true) }}" # Путь к директории с файлами CRL
Для формирования конфигурационного файла агента и обновления CRL в конфигурационном файле инсталлятора необходимо добавить следующие параметры:
pangolin-certs-rotate:
enable: true # Настроить и запустить службу агента (не учитывается при обновлении агента, только при первичном развертывании)
agent_config: /etc/pangolin-certs-rotate/pangolin-certs-rotate.yml # Путь к конфигурационному файлу агента в формате YAML
update_agent_config: false # Обновить файл конфигурации агента (учитывается только при обновлении, значение по умолчанию - False)
log:
directory: /pgerrorlogs/05/pangolin-certs-rotate # Путь к директории для лог-файлов
filename: pangolin-certs-rotate.log # Имя лог-файла
level: info # Уровень логирования
destination: console,file # Методы записи лога
crl:
enable_update: false # Включить/выключить автоматическое обновление CRL
poll_period_in_min: 60 # Период проверки наличия обновленных CRL файлов
retry_interval_on_expire_in_sec: 30 # Тайм-аут для повторной попытки выгрузки CRL после наступления даты публикации CRL или окончания срока действия
retry_interval_on_failure_in_sec: 30 # Тайм-аут для повторной попытки выгрузки CRL после неудачи
retry_attempts_num_on_failure: 1 # Количество попыток выгрузки CRL по списку URI для данного пути расположения файла CRL после неудачи
crl_file_perm: 0644 # Права доступа, устанавливаемые на выгружаемые файлы CRL
watch:
- locations:
- path: path/to/crlfile_1 # Путь к обновляемому файлу CRL
uri:
- URI_1 # Основная точка распространения CRL
- URI_N # Резервная точка распространения CRL
- path: path/to/crlfile_N # Путь к обновляемому файлу CRL
uri:
- URI_1 # Основная точка распространения CRL
- URI_N # Резервная точка распространения CRL
on_update:
- sudo systemctl reload postgresql # Список выполняемых команд, если файл CRL изменился
Примечание:
Установка файлов агента на узел СУБД производится инсталлятором автоматически.
Обновление pangolin-certs-rotate осуществляется по одному из двух сценариев:
-
если агент был ранее установлен в обновляемой версии СУБД Pangolin (например, при переходе с версии СУБД Pangolin 5.4.0 на более высокую):
-
в зависимости от значения параметра
update_agent_config, который определяется в конфигурационном файле инсталлятора, автоматически настраивается файл конфигурации агента. По умолчанию значение параметра -False, в этом случае конфигурационный файл агента не заменяется версией конфигурации из файла инсталлятора. При необходимости ее обновления инсталлятором, параметр нужно установить в значениеTrue; -
в зависимости от состояния службы агента (
active/inactive) по окончании обновления версии СУБД служба агента будет либо запущена, либо нет. Проверить статус службы можно следующим способом:sudo systemctl status pangolin-certs-rotate | grep ActiveРезультат будет иметь следующий вид:
Active: active (running) since Tue 2023-05-23 15:59:02 MSK; 13s agoили
Active: inactive (dead)
-
-
если агент не был установлен в обновляемой версии СУБД Pangolin (например, при переходе с версии СУБД Pangolin 5.2.0):
- файл конфигурации агента создается и настраивается в соответствии с конфигурационным файлом инсталлятора (для незаполненных полей берутся значения по умолчанию);
- запуск службы агента в данном случае не производится.
Примечание:
В рамках механизма обновления версии СУБД скрипт-разведчик проверяет корректность заполнения файла конфигурации
pangolin-certs-rotate.
В файл /etc/sudoers вручную добавляются следующие команды, разрешенные пользователю postgres для выполнения без запроса пароля:
/bin/journalctl -f -u pangolin-certs-rotate
/usr/bin/systemctl start pangolin-certs-rotate
/usr/bin/systemctl stop pangolin-certs-rotate
/usr/bin/systemctl restart pangolin-certs-rotate
/usr/bin/systemctl reload pangolin-certs-rotate
/usr/bin/systemctl status pangolin-certs-rotate
/usr/bin/systemctl reload pangolin-manager
/usr/bin/systemctl reload postgres
В файл конфигурации службы pangolin-manager.service необходимо добавить команду reload:
ExecReload=/bin/kill -HUP $MAINPID
Мониторинг блокировок
Для оперативного мониторинга заблокированных объектов предусмотрен отдельный инструмент psql_lockmon.
Механизм отслеживания блокировок представляет собой набор представлений, позволяющий проводить оперативный мониторинг блокировок в разрезе:
- заблокированных объектов;
- типов блокировок;
- параметров сессии, которая заблокировала объект (при наличии прав);
- длительности сессий, запросов, ожидания блокировок, смены статуса (при наличии прав);
- текста последнего запроса в сессии (при наличии прав);
- дерева блокировок, при наличии очереди заблокированных объектов.
Поставка механизма отслеживания блокировок производится в виде расширения psql_lockmon.
Предусмотрена автоматизация развертывания решения на уровне специализированного сценария (custom.yml). Решение по умолчанию устанавливается в БД пользователя и в шаблонную БД.
Параметры управления легкими блокировками
Параметры позволяют управлять легкими блокировками (LWLock) на высоконагруженных системах для повышения производительности в следующих сценариях нагрузки:
- редкие пишущие запросы и чрезмерно частые читающие запросы;
- запросы с большим числом таблиц: партиционированные таблицы, таблицы с большим числом индексов, объединение таблиц с помощью оператора JOIN;
- запросы, сопровождающиеся частым обращением к буферному кешу для чтения страниц из файловой системы, записи страниц в файловую систему, вытеснения страниц из буферного кеша.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Включение функциональности
Задание параметров осуществляется в конфигурационных файлах СУБД Pangolin (postgres.conf для standalone, postgres.yml для cluster), или в командной строке при запуске сервера. Список GUC-параметров управления легкими блокировками:
lwlock_shared_limit;fastpath_num_locks(deprecated);log2_num_lock_partitions;log2_num_buf_partitions;log2_fastpath_num_groups.
Примечание:
Параметр
fastpath_num_locksпродолжает существовать для обратной совместимости, но, начиная с версии СУБД Pangolin 7.1.0, он больше не влияет на поведение системы.После изменения параметра
lwlock_shared_limit, для применения значения, достаточно выполнить процесс перечитывания параметров СУБД Pangolin (reload). Изменениеlog2_num_lock_partitionsиlog2_num_buf_partitions,log2_fastpath_num_groupsтребует обязательного перезапуска сервера СУБД Pangolin (restart).
GUC-параметр lwlock_shared_limit
В СУБД Pangolin для работы с разделяемыми структурами данных, например с хеш-таблицей, используются легкие блокировки (LWLock). Имеются два режима: исключительный (для изменения данных, exclusive) и разделяемый (только для чтения, shared). Разделяемый режим позволяет одновременно многим процессам читать одни и те же данные, если в этот момент нет процессов, изменяющих эти данные. Как только пишущий процесс взял exclusive-блокировку, читающие процессы выстраиваются за ним в очередь. Если к моменту попытки получения exclusive-блокировки, удерживается shared-блокировка, то другие читающие процессы проходят вне очереди, продлевая время ожидания блокировки пишущих процессов.
Эта особенность очереди может привести к отказу в обслуживании при большом числе параллельно выполняющихся читающих запросов и редких пишущих. Пишущий процесс может надолго, если не вечно, зависнуть на захвате в исключительном режиме одной из легких блокировок транша LWLock:BufferMapping. Транш LWLock:BufferMapping состоит из 128 отдельных легких блокировок, каждая из которых защищает свою часть хеш-таблицы, позволяющей найти буфер в кеше по номеру блока в файловой системе. Интенсивная read-only нагрузка вытесняет из очереди пишущие процессы, которым требуется добавить в хеш-таблицу новый блок.
Для решения данной проблемы введен новый GUC-параметр lwlock_shared_limit. Параметр определяет количество последовательно запрашиваемых shared-блокировок, по достижении которого включается «честный» режим. В этом режиме запросы shared-блокировок становятся в очередь, а не получают блокировку немедленно, что позволяет избежать подавления exclusive-блокировок. Когда очередь доходит до exclusive-блокировки, процесс, владеющий этой блокировкой, отключает «честный» режим. При небольших значениях этого параметра exclusive-блокировки будут получаться гораздо быстрее, но могут возникнуть значительные издержки. С увеличением этого значения снижаются издержки, но уменьшается и ускорение. Имеет смысл использовать, если увеличение log2_num_lock_partitions не улучшает ситуации.
Диапазон значений: от 0 до 16383.
Значение по умолчанию: 0 («честный» режим отключен).
Рекомендуемое значение на высокой нагрузке: очень зависит от профиля нагрузки (в большинстве случаев можно использовать значение по умолчанию, в определенных ситуациях можно поднять до 10-20).
GUC-параметр log2_num_lock_partitions
При планировании и выполнении запросов устанавливаются тяжелые блокировки на объекты БД, участвующие в запросе, а по завершении транзакции эти блокировки снимаются. Информация о тяжелых блокировках хранится в хеш-таблице, расположенной в общей памяти сервера. Хеш-таблица менеджера блокировок поделена на 16 частей, доступ к каждой из которых защищен своей легкой блокировкой (транш LWLock:LockManager). На современных многоядерных системах с высокой степенью параллельности и большой нагрузкой 16 частей может оказаться недостаточно, если в запросе участвует более 16 объектов БД. В этом случае неизбежны коллизии: хеши, вычисленные по идентификаторам разных объектов БД, ссылаются на одну и ту же часть таблицы, что, в свою очередь, приводит к большой конкуренции за легкую блокировку, отвечающую за доступ к этой части хеш-таблицы. Поскольку захват блокировки осуществляется в исключительном режиме, коллизии хешей повышают вероятность ожидания процессов на событии LWLock:LockManager.
Для снижения влияния коллизий введен новый GUC-параметр log2_num_lock_partitions. Параметр позволяет настроить число частей, на которые будет поделена общая таблица блокировок, и, соответственно, количество легких блокировок в транше LWLock:LockManager. Значение параметра представляет степень, в которую нужно возвести число 2 (2^log2_num_lock_partitions), для получения фактического количества частей хеш-таблицы.
Увеличение количества секций относительно значения по умолчанию снижает конкуренцию при доступе к секциям структуры и может быть использовано при решении проблем с ожиданиями на LWLock:LockManager.
Диапазон значений: от 4 (16 частей) до 8 (256 частей)
Значение по умолчанию: 4 (16 частей).
Рекомендуемое значение на высокой нагрузке: 7.
GUC-параметр log2_num_buf_partitions
В СУБД Pangolin страницы отношений хранятся в буферном кеше. Он располагается в общей памяти сервера и доступен всем процессам. Когда менеджеру буферов требуется прочитать страницу, он сначала пытается найти ее в буферном кеше. Для быстрого поиска нужного буфера используется хеш-таблица Shared Buffer Lookup Table, хранящая номера буферов.
Для увеличения гранулярности хеш-таблица поделена на 128 частей (бакетов/корзин), доступ к каждой из которых защищается своей отдельной легкой блокировкой.
Эти легкие блокировки объединены в транш блокировок LWLock::BufferMapping для данной хеш-таблицы. Перед обращением к хеш-таблице процесс должен захватить легкую блокировку, на которую выпал ключ хеширования: идентификатор файла отношения, тип слоя и номер страницы внутри файла этого слоя. Блокировка захватывается в двух режимах: в разделяемом режиме - для чтения и в исключительном - для изменений.
В большинстве сценариев обращения к хеш-таблице происходят очень активно, поэтому эта блокировка становится "узким местом". На современных многоядерных системах число бакетов 128 оказывается недостаточным из-за высокой конкуренции за доступ к отдельному бакету.
Для решения описанной проблемы используйте GUC-параметр log2_num_buf_partitions для установки числа бакетов хеш-таблицы и, соответственно, количества легких блокировок в транше LWLock:BufferMapping. Увеличение значения параметра при интенсивной нагрузке позволит снизить вероятность ожидания процессов на событии LWLock:BufferMapping за счет увеличения гранулярности блокировок. Значение параметра представляет степень, в которую нужно возвести число 2, для получения фактического количества частей хеш-таблицы.
Диапазон значений: от 7 (128 частей) до 16 (65536 частей)
Значение по умолчанию: 7 (128 частей).
Рекомендуемое значение на высокой нагрузке: 10-12.
GUC-параметр log2_fastpath_num_groups
Для снижения нагрузки на разделяемую хеш-таблицу менеджера блокировок (LWLock:LockManager) применяется подход, называемый fast-path locking (блокировка объекта БД по быстрому пути). Fast-path-блокировка объекта БД возможна при выполнении следующих условий:
- блокировка захватывается на отношение (таблица, индекс, представление и пр.);
- запрашиваются менее конфликтующие режимы тяжелой блокировки, допускающие одновременное изменение данных в таблице (не конфликтуют между собой):
AccessShareLock,RowShareLock,RowExclusiveLock; - отсутствуют транзакции, заблокировавшие таблицу в более конфликтующем режиме:
ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock; - текущей транзакцией используется менее 16 слотов с информацией о блокировках отношений.
Каждая транзакция может использовать fast-path-блокировку только для 16 тяжелых блокировок отношений. Все дополнительные блокировки должны использовать разделяемую хеш-таблицу менеджера блокировок. Информация о менее конфликтующих блокировках, полученных по fast-path, хранится в разделяемой памяти, но конкуренция за этот участок возникает не так часто, как за хеш-таблицу менеджера блокировок. Обычно доступ к этой области памяти осуществляет только процесс, выполняющий запрос, поэтому можно рассматривать этот участок, как локальный для процесса. Исключением является случай, когда в одной транзакции уже взята менее конфликтующая блокировка на объект, а в другой захватывается более конфликтующая блокировка на тот же объект. Процесс с более конфликтующей блокировкой будет переносить информацию о менее конфликтующей блокировке другого процесса в общую хеш-таблицу менеджера блокировок, а для этого ему потребуется заблокировать доступ к памяти с fast-path-блокировками другого процесса. В сценариях нагрузки, когда более конфликтующие блокировки на объекты берутся достаточно редко, за счет использования fast-path-блокировок можно получить значительный прирост производительности.
Для снижения частоты использования разделяемой хеш-таблицы менеджера блокировок (LWLock:LockManager) введен новый GUC-параметр log2_fastpath_num_groups. Параметр определяет число разделов хеш-таблицы fast-path-блокировок, каждый из которых имеет 16 слотов для хранения информации о fast-path-блокировках на объекты БД. Значение параметра представляет степень, в которую нужно возвести число 2 (2^log2_fastpath_num_groups), для получения фактического количества групп хеш-таблицы fast-path-блокировок.
При значении log2_fastpath_num_groups = -1, количество групп fast-path-блокировок вычисляется автоматически, исходя из количества max_locks_per_transaction. В таком случае, количество групп fast-path-блокировок будет равно той степени двойки, которая при умножении на 16 будет меньше или равна max_locks_per_transaction. Например, при max_locks_per_transaction = 128, количество групп fast-path-блокировок будет равно 8 (8 * 16 = 128). При max_locks_per_transaction = 100, количество групп fast-path-блокировок будет равно 4 (4 * 16 = 64).
Диапазон значений: от -1 до 10.
Значение по умолчанию – 0.
Рекомендуемое значение на высокой нагрузке: -1.
Отключение функциональности
Отключение производится путем установки параметров в значение по умолчанию:
lwlock_shared_limit = 0;log2_num_lock_partitions = 4;log2_num_buf_partitions = 7;log2_fastpath_num_groups = 0.
Маскирование запросов
В СУБД Pangolin для обеспечения защиты персональных данных и конфиденциальных сведений при выполнении SQL-запросов реализована функциональность маскирования запросов. Модель функционирования СУБД строится на выполнении запросов со стороны аутентифицированных и авторизованных пользователей.
Подробнее о функциональности в разделе «Маскирование запросов».
Автоматическое завершение неактивных соединений
Соединения, остающиеся неактивными определенное время, подлежат принудительному завершению. Для завершения таких соединений используется фоновый процесс «idle sessions terminator», осуществляющий мониторинг и завершение бездействующих клиентских сеансов. Этот процесс запускается при старте сервера Pangolin и завершается вместе с остановкой сервера.
Процесс регулируется двумя параметрами:
check_idle_time_delay- интервал мониторинга в миллисекундах;backend_idle_alive_time- допустимое время бездействия в секундах.
Если хотя бы один из этих параметров равен нулю, неактивные соединения завершаться не будут.
Оптимизация таблиц
В процессе работы с Pangolin возникает table bloat — ситуация, при которой данные таблиц будут храниться неэффективно. Они фрагментируются, что приводит к ухудшению производительности и нерациональному использованию места на диске.
Примеры ситуаций, при которых может возникать фрагментация:
- непредвиденный скачок запросов
UPDATEи/илиDELETE, сильно отличающийся от обычного профиля нагрузки; - наличие долгих транзакций, препятствующих удалению старых версий записей (
VACUUMне может удалить запись, если есть хотя бы одна незакрытая транзакция старше записи, удалившей или изменившей эту запись); - наличие незавершенных PREPARED-транзакций;
- наличие открытых слотов репликации. Это может произойти из-за сильной задержки между лидером и репликой либо в случае недоступности реплики;
- фрагментация может накапливаться естественным образом, если в таблице есть типы данных переменной длины. Это приводит к образованию кусков удаленных данных такого размера, которые сложно будет перезаписать.
Механизм работы с данными в PostgreSQL
При первом наполнении таблицы данные добавляются последовательно и равномерно занимают блоки. Пример наполнения записями таблицы bloated_table:
CREATE TABLE bloated_table(id integer, data integer);
INSERT INTO bloated_table SELECT i, random() FROM generate_series(1, 1000000) AS g(i);
Посмотреть статистику по таблице можно с помощью запроса к pg_stat_user_tables командой ANALYZE:
ANALYZE bloated_table;
SELECT n_tup_ins, n_tup_upd, n_tup_del, n_live_tup, n_dead_tup FROM pg_stat_user_tables WHERE relname = 'bloated_table';
n_tup_ins | n_tup_upd | n_tup_del | n_live_tup | n_dead_tup
-----------+-----------+-----------+------------+------------
1000000 | 0 | 0 | 1000000 | 0
Полученные результаты:
n_tup_ins,n_tup_upd,n_tup_del— количество вставок, изменений, удалений строк таблицы;n_live_tup— актуальные записи;n_dead_tup— «мертвые» записи, помеченные на удаление.
Команда pg_size_pretty покажет объем таблицы на диске:
SELECT pg_size_pretty(pg_table_size('bloated_table'));
pg_size_pretty
----------------
35 MB
Симуляция фрагментации методом удаления каждой второй строки:
DELETE FROM bloated_table WHERE (id % 2) = 0;
Статистика таблицы после фрагментации:
n_tup_ins | n_tup_upd | n_tup_del | n_live_tup | n_dead_tup
-----------+-----------+-----------+------------+------------
1000000 | 0 | 500000 | 500000 | 500000
pg_size_pretty
----------------
35 MB
Теперь 500 000 записей считаются «мертвыми» (dead) и могут быть удалены сборщиком мусора (VACUUM). При штатной работе это сделает auto vacuum, а для таблицы из примера очистка запущена вручную:
VACUUM bloated_table;
...
n_tup_ins | n_tup_upd | n_tup_del | n_live_tup | n_dead_tup
-----------+-----------+-----------+------------+------------
1000000 | 0 | 500000 | 500000 | 0
pg_size_pretty
----------------
35 MB
«Мертвых» записей больше нет, но размер таблицы не изменился. VACUUM не возвращает место на диске кроме случаев, когда удаляет последний блок с данными. Свободное место будет переиспользовано Pangolin для новых записей.
Примечание:
Обновление существующих записей также может привести к фрагментации:
UPDATEиDELETEне изменяют значение текущей строки (tuple), а создают ее новую версию.
Анализ фрагментации таблиц
В PostgreSQL есть расширение pgstattuple, позволяющее анализировать состояние таблиц. Оно устанавливается вместе с Pangolin по умолчанию.
Пример использования:
test=> SELECT * FROM pgstattuple('bloated_table');
-[ RECORD 1 ]------+-------
table_len | 458752
tuple_count | 1470
tuple_len | 438896
tuple_percent | 95.67
dead_tuple_count | 11
dead_tuple_len | 3157
dead_tuple_percent | 0.69
free_space | 8932
free_percent | 1.95
Значение строк вывода:
free_percent— процент свободных записей. Чем он выше, тем больше фрагментирована таблица. Нормальными считаются значения не более 20%;table_len— физическая длина отношения в байтах;tuple_count— количество «живых» записей;tuple_len— общая длина «живых» записей в байтах;tuple_percent— процент «живых» записей;dead_tuple_count— количество «мертвых» записей;dead_tuple_len— общая длина «мертвых» записей в байтах;dead_tuple_percent— процент «мертвых» записей;free_space— общий объем свободного пространства в байтах.
Примечание:
Рекомендуется периодически проверять активные и перенесшие всплеск нагрузки таблицы.
Стандартные утилиты PostgreSQL
Вернуть освобожденное после VACUUM место на диске можно стандартными средствами PostgreSQL:
-
VACUUM FULLполностью пересоберет таблицу, освободив все неиспользуемые строки:VACUUM FULL bloated_table;
...
pg_size_pretty
----------------
17 MB -
CLUSTERвыполнит все операцииVACUUM FULLи упорядочит строки по индексу, уменьшая количество обращений к диску на некоторых запросах:CLUSTER bloated_table USING <index_name>;
Использовать VACUUM FULL и CLUSTER на БД под нагрузкой не рекомендуется. Эти команды работают медленно и полностью блокируют обрабатываемую таблицу. Для решения table bloat без прибегания к блокировке в состав Pangolin входит утилита по реорганизации данных pg_repack.
Расширение pg_repack
Инструмент для реорганизации таблиц без эксклюзивной блокировки. Позволяет реорганизовать таблицы и индексы к ним и переносить их в другое табличное пространство.
Функциональность:
- реорганизация таблиц без блокировки, в отличие от стандартных средств PostgreSQL
VACUUM FULLиCLUSTER. Производительность сравнима сCLUSTER; - удаление пустот в таблицах и индексах;
- восстановление физического порядка кластеризованных индексов.
Более подробно c информацией о расширении pg_repack можно ознакомиться в одноименном разделе расширения pg_repack документа «Описание расширений продукта СУБД Pangolin».
При включенном прозрачном защитном преобразовании данных (TDE) использовать расширение pg_repack запрещено.
Расширение pg_squeeze
Расширение предназначено для оптимизации хранения данных в таблицах и индексах методом переупаковки данных в новый объект.
Предусмотрен обмен данными между расширением и администратором СУБД только через следующие объекты:
| Объект | Тип | Назначение |
|---|---|---|
| squeeze.tables | таблица | Регистрация автоматически обслуживаемых таблиц, по одной записи на таблицу |
| squeeze.log | таблица | Журнал переупаковок, заполняется по записи на каждую успешно переупакованную таблицу |
| squeeze.errors | таблица | Журнал ошибок, заполняется ошибками переупаковки |
| squeeze.start_worker(); | функция | Запустить фоновую обработку |
| squeeze.stop_worker(); | функция | Остановить фоновую обработку |
| squeeze.squeeze_table(); | функция | Переупаковать таблицу вручную |
Проверка расширения
Для проверки подключения расширения необходимо:
-
Убедиться, что установлены следующие параметры сервера:
wal_level: logical
max_replication_slots = 1 # или добавить 1 к существующему значению
shared_preload_libraries = 'pg_squeeze' # или добавить библиотеку к существующим -
Проверить наличие схемы
squeeze, а также подключение под ТУЗsqueeze_tuz. -
Перезапустить узлы для применения.
Использование модуля
Процессы работы с расширением, такие как:
- Включение автоматической обработки;
- Настройка существующей базы;
- Регистрация таблицы;
- Отмена регистрации;
- Ручная переупаковка таблицы.
Более подробно c примерами использования, информацией о параметрах функции squeeze.squeeze_table и полями таблицы squeeze.tables можно ознакомиться в одноименном разделе расширения pg_squeeze документа «Описание расширений продукта СУБД Pangolin».
Мониторинг метрик репликации
Рекомендуется обеспечить на стороне инфраструктуры мониторинг стандартной логической репликации. Как минимум, необходимо отслеживать следующие метрики:
SELECT slot_name,
pg_wal_lsn_diff(restart_lsn, pg_current_wal_lsn()) process_lag_bytes,
pg_wal_lsn_diff(confirmed_flush_lsn, pg_current_wal_lsn()) apply_lag_bytes
FROM pg_replication_slots WHERE slot_type='logical';
Для найденных slot_name можно построить графики process_lag_bytes и apply_lag_bytes с триггерами, например, 256 МБ/1 ГБ warning/critical.
В списке рекомендованных метрик для Pangolin эти метрики объединены под именем pgse_replication_slots_retained_bytes_active. Подробнее о событиях мониторинга смотрите в разделе «Мониторинг». В разделе репликация той же таблицы доступны запросы и правила для более подробного отслеживания процесса. А на странице мониторинг статуса репликации можно узнать смысл этой информации и познакомиться с примерным решением в виде панели отчетов для Grafana.
Можно использовать для мониторинга любое решение на выбор. Чтобы узнать подробнее об использовании Grafana для мониторинга параметров Pangolin и сборе метрик смотрите документ «Установка и настройка дополнительных компонентов системы, не входящих в состав дистрибутива Pangolin», раздел «Мониторинг с помощью Grafana» (документ доступен в личном кабинете).
Чтобы исправить ситуацию по сигналам на эти метрики, если слот репликации относится к pg_squeeze, следует прервать переупаковку. Возможно, для этого придется самостоятельно удалить процесс ручной переупаковки или фоновый процесс-переупаковщик, после чего можно будет удалить не используемый слот. Далее операцию ручной переупаковки придется повторить. В случае фонового процесса, он будет запланирован на следующий интервал автоматически.
Стандартная метрика для отслеживания свободного пространства на дисковом томе, который хранит WAL, также должна быть включена.
Аудит действий, выполняемых расширением
Для того чтобы в логе сервера присутствовали записи аудита с маркером AUDIT:, интегрированное решение pgaudit должно быть корректно настроено. Расширение pg_squeeze самостоятельно регистрирует два события:
- факт вызова функции переупаковки
squeeze.squeeze_table(), вне зависимости от способа вызова функции - в ручном или автоматическом режиме. Данное событие соответствует классу событий аудитаMISC. - факт переноса таблицы и/или индекса в другое табличное пространство, выполняемого в рамках функции по переупаковке таблицы. Данное событие соответствует классу событий аудита
DDL.
Настройка аудита для регистрации этих действий заключается в добавлении MISC и DDL в переменную pgaudit.log в соответствии с ролевой моделью, то есть:
- при ручном способе переупаковки эти классы аудита должны быть установлены для пользователя, выполняющего вызов переупаковщика;
- при автоматизированной переупаковке - для пользователя, от которого запущен процесс, запускающий переупаковку по расписанию (
squeeze.worker_role- если запуск рабочего процесса осуществляется на старте сервера или тот пользователь, который запустил процесс вручную).
Например:
ALTER ROLE db_admin SET pgaudit.log='ddl, role, connection, misc_set, misc';
First_db=# \drds db_admin
List of settings
Role | Database | Settings
----------+----------+-------------------------------------------------------
db_admin | | pgaudit.log=ddl, role, connection, misc_set, misc
(1 row)
Для аудита событий добавления/изменения/модификации расписания автоматизированного переупаковщика необходимо настроить аудит над объектом squeeze.tables. С инструкцией можно ознакомиться в документации pgaudit. Ниже приведен пример настройки:
CREATE ROLE squeeze_auditor;
GRANT INSERT, UPDATE, DELETE, TRUNCATE ON squeeze.tables TO squeeze_auditor;
\dp+ squeeze.tables
ALTER ROLE db_admin set pgaudit.role=squeeze_auditor;
\drds db_admin
List of settings
Role | Database | Settings
----------+----------+-------------------------------------------------------
db_admin | | pgaudit.log=ddl, role, connection, misc_set, function+
| | pgaudit.role=squeeze_auditor
(1 row)
Также в параметр log_line_prefix может быть добавлен тип процесса - %b. Это позволит различать в логе записи о ручной и автоматизированной переупаковке.
Аналитика производительности Pangolin
Для сбора данных в Pangolin создается дочерний процесс, в цикле которого происходит периодический опрос статистики активности и блокировок.
Для последующего анализа собранной статистики можно сформировать отчет с указанием временного диапазона. Отчет сохраняется в формате HTML. Описание и примеры разделов отчета представлены в отдельном документе «Описание структуры отчетов СУБД Pangolin» (документ доступен в личном кабинете).
Инструмент для оперативного анализа текущей активности СУБД доступен только для редакций Enterprise и Enterprise для ERP-систем.
Конфигурационные параметры
Примечание:
Для применения внесенных изменений настроечных параметров необходимо выполнить перезагрузку.
При изменении пути к папке хранения файлов необходимо содержимое старой папки перенести в новую.
Настройка параметров для аналитики производительности осуществляется в файле postgresql.conf:
-
performance_insights.enable— включает/выключает функциональность (значение по умолчанию —false); -
performance_insights.sampling_enable— включает/выключает сбор данных (значение по умолчанию —true). После изменения настроек параметра требуется выполнить одно из предложенных действий:- перезагрузка;
- вызов команды
SELECT pg_reload_conf();; - отправить сигнал SIGHUB;
-
performance_insights.sampling_period— задает периодичность сбора данных в миллисекундах (значение по умолчанию —1s). Минимальное значениеmin - 100ms, значениеmax— не ограничено; -
performance_insights.num_samples_in_ram— количество итераций сбора данных активности текущих сессий, хранящихся в оперативной памяти (значение по умолчанию —900). Определяет время хранения данных активности текущих сессий в оперативной памяти. Время определяется количеством сборов данных (performance_insights.num_samples_in_ram), умноженным на периодичность сбора данных (performance_insights.sampling_period). Таким образом, время хранения данных активности текущих сессий по умолчанию (900 * 1s) —> 900 секунд (или 15 минут), при этом:minзначение – 0;maxзначение – не ограничено (2147483647);
При значении 0 данные, собираемые performance_insights.num_samples_in_ram (Activity и Lock), будут записываться сразу на диск, без промежуточного сохранения в общей памяти. Это подразумевает частичный отказ от использования shared memory для хранения snapshots.
-
performance_insights.num_samples_in_files— количество итераций сбора данных активности текущих сессий, хранящихся в файлах (на диске) (значение по умолчанию —86400). Определяет время хранения данных активности текущих сессий в файлах (на диске). Время определяется количеством сборов данных (performance_insights.num_samples_in_files) умноженное на периодичность сбора данных (performance_insights.sampling_period). Таким образом, время хранения данных активности текущих сессий по умолчанию (86400 * 1s) —> 86400 секунд (или 1 сутки), при этом:minзначение - 1;maxзначение — не ограничено (2147483647);
-
performance_insights.directory— путь к папке, в которую сохраняются файлы с полученными данными (значение по умолчанию${PGDATA}/pg_perf_insights);Внимание!Рекомендуется задать директорию хранения, находящуюся за пределами директории с данными СУБД (PGDATA).
В противном случае возможна потеря статистики при реиницилизации кластера.
-
performance_insights.masking— включает/выключает маскирование параметров запроса, параметров соединения и имени пользователя (значение по умолчанию — true). Параметрperformance_insights.maskingрекомендуется поместить под защиту.Внимание!Возникновение предупреждения формата
Invalid PL/PgSQL expression passed to masker, masking limited to input string onlyозначает, что исходный запрос превышал ограничение по длине (тег окончания блока запроса не найден), но был замаскирован. -
performance_insights.file_format– формат файла, используемый для хранения данных:0- формат по умолчанию (1 минута в файле, старый формат, формат Default);1-gzip(сжатие, хранение диапазоном секунд);2-zstd(сжатие, хранение диапазоном секунд);3- формат с диапазоном секунд (без сжатия);
-
performance_insights.packed_block_size– размер распакованного блока данных, хранимых в одном файле. Значение по умолчанию -25MB, допустимые значения5MB - 256MB. -
performance_insights.size_samples_in_files– максимальный размер папки с данными.0- значение по умолчанию (означает, размер без ограничений). Диапазон0 - 2147483647MB(только для форматов1-3). При значении0файлы форматов (file_format)1,2,3не будут удаляться автоматически, ограничений на общий размер нет. -
performance_insights.compression_level– уровень сжатия для алгоритмов хранения со сжатием.9- максимальное (значение по умолчанию).0- минимальное (не рекомендуется). Для форматов0,3игнорируется. Чем больше значение сжатия — тем сильнее нагрузка на CPU.
Функции
Для работы с данными по аналитике производительности Pangolin применяются следующие функции:
pg_stat_get_activity_history— возвращает набор записей с данными об активности сессий в определенный момент времени;pg_stat_get_activity_and_lock_status_history— возвращает данные активности текущих сессий вместе с данными блокировок (если они имеются) и затраченными ресурсами (CPU, IO);pg_stat_get_activity_history_last— возвращает набор записей с данными об активности сессий в последний период обновления истории;pg_lock_status_history— возвращает набор записей с информацией о блокировках в определенный момент времени;pg_stat_activity_history_reset— функция для управления сохраненными данными, которая полностью очищает историю;pg_stat_activity_and_lock_status_history_report— формирует отчет из собранных данных.
Примечание:
По умолчанию функции по аналитике производительности может вызвать суперпользователь или пользователь, у которого есть привилегии групповой роли
pg_read_all_perfinsight.
Описание функций (входные параметры / возвращаемые значения) и примеры использования представлены в отдельном документе «Список PL/SQL функций продукта» раздел «Аналитика производительности Pangolin» (документ доступен в личном кабинете).
Оптимизация структуры хранения данных Performance Insights
В версии 6.5.0 реализована доработка оптимизации структуры хранения данных.
В данных Performance Insights наблюдаются дублирования:
-
Избыточные строковые данные, занимающие много места, а также повторяющиеся данные по процессам, находящимся в одном и том же состоянии продолжительное время.
Проблема: если таблица уже удалена, объект
oidбудет недоступен. Решение: использованиеpg_profileдля предотвращения потери информации. -
Чрезмерное количество файлов при хранении данных с высокой частотой выборки:
- Если активный пользователь сохраняет данные за месяц с интервалом в 1 секунду, возникает огромное количество файлов, что делает их открытие затруднительным.
- Это приводит к избыточности хранения данных и увеличению времени обработки.
Цели доработки:
- Уменьшить дублирование при хранении данных.
- Сократить количество файлов для обеспечения возможности их открытия.
Возможности при использовании доработки оптимизации:
- Пользователь может управлять схемой хранения данных на диске, используя диапазоны и сжатие в форматах
gzipиzstdдля уменьшения количества файлов. - Возможно ограничение объема хранимых данных: при превышении заданного объема самые старые файлы автоматически удаляются.
- Пользователь может выбирать формат сохранения новых файлов, при этом старые файлы остаются доступными независимо от текущего формата.
- Для архивируемых форматов (
gzip,zstd) предусмотрена возможность внешней распаковки (gunzip,unzstd) для восстановления поврежденных архивов.
Описание решения
Для управления настройками введены или изменены следующие параметры конфигурации (postgresql.conf) в разделе performance_insights. Изменения параметров применяются только после перезапуска сервера.
| Параметр | Назначение | Значения | Пример |
|---|---|---|---|
num_samples_in_files | Количество сэмплов в файле на диске | Значение по умолчанию — 86400. Только для формата по умолчанию ( file_format=0) | |
file_format | Формат файла, используемый для хранения данных | 0 - формат по умолчанию (1 минута в файле, старый формат, формат Default); 1 - gzip (сжатие, хранение диапазоном секунд); 2 - zstd (сжатие, хранение диапазоном секунд); 3 - формат с диапазоном секунд (без сжатия) | 13208870 792532267_792532343.gz 792532267_792532343.zst 792532267_792532343 |
packed_block_size | Размер распакованного блока данных, хранимых в одном файле | Значение по умолчанию - 25MB, допустимые значения 5MB - 256MB. При достижении указанного размера распакованным блоком данных, произойдет переключение файлов: закрытый файл будет переименован в соответствии с требованиями (в названии указывается диапазон секунд). | |
compression_level | Уровень сжатия для алгоритмов хранения со сжатием | 9 - максимальное (значение по умолчанию); 0 - минимальное (не рекомендуется). Для форматов 0, 3 игнорируется. Чем больше значение сжатия — тем сильнее нагрузка на CPU | |
size_samples_in_files | Максимальный размер папки с данными | 0 - значение по умолчанию (означает, размер без ограничений). Диапазон 0 - 2147483647MB (только для форматов 1-3). При значении 0 файлы форматов (file_format) 1, 2, 3 не будут удаляться автоматически, ограничений на общий размер нет |
Очистка файлов
Для разных форматов определены разные методы очистки, которые применяются к соответствующим файлам на постоянной основе, вне зависимости от указанного file_format.
-
Формат 0 (Default):
Для
file_format = 0(Default) происходит очистка по времени исходя из заданных параметров хранения (performance_insights.sampling_period,performance_insights.num_samples_in_ram,performance_insights.num_samples_in_files). Интервал, за который хранятся файлы формата 0 (Default) вычисляется следующим образом:sampling_period * (num_samples_in_ram + num_samples_in_files).Пример:
sampling_period = ‘100ms’
num_samples_in_ram = 300
num_samples_in_files = 10000Тогда
interval = 0.1s * (300 + 10000) = 1030s- допустимый к хранению интервал. Файл не будет удален до тех пор, пока полностью не выйдет за данный диапазон хранения[current_time - interval, current_time]. -
Форматы 1, 2 и 3 (
gzip,zstd, без сжатия с диапазоном секунд):Для новых форматов (1, 2 и 3) очистка происходит исходя из занимаемого ими объема (
size_samples_in_files). При этом рассматриваются размеры только файлов новых форматов (1, 2 и 3). Файлы формата 0 (Default) не учитываются при вычислении суммарного занимаемого размера.
При смене форматов очистка продолжает происходить для всех форматов. Однако, если при использовании формата 0, не происходит добавление файлов форматов 1, 2 и 3 - их очистка не будет запускаться (пока не изменится параметр size_samples_in_files), поскольку их общий объем остается прежним.
Логика работы буфер файла
В рамках работы форматов 1 и 2 (gzip, zstd) создаются два файла: databuffer.* и *_xxx, которые содержат последние вытесненные из памяти данные. Пример (в случае формата gzip): databuffer.gz и 792532267_xxx.
Файл *_xxx содержит распакованные данные, вытесненные из памяти, тогда как databuffer.* содержит те же данные, но в сжатом виде. Поскольку файл databuffer.* невозможно правильно прочитать до тех пор, пока он не закрыт, для корректной работы программы сохраняется его несжатая версия. Постоянное наличие файла databuffer.* в процессе работы, а не только в момент переключения файлов / завершения работы, связано с длительностью процесса сжатия файла «с нуля», которая могла бы превысить допустимое время завершения.
Ориентиром для переключения файла служит именно размер *_xxx (размер распакованного блока данных, хранимых в одном файле - packed_block_size). При работе с форматами 1, 2 при переключении файлов или завершении работы происходит переименование файла databuffer.* в итоговый файл с диапазоном секунд и расширением.
При работе с форматом 3 (без сжатия, формат с диапазоном секунд) присутствует только файл *_xxx и он будет переименован при переключении файлов / завершении работы.
Формула преобразования имени файла в unix epoch time
Формула преобразования имени файла в unix epoch time:
unix_time = time + (POSTGRES_EPOCH_JDATE - UNIX_EPOCH_JDATE) * SECS_PER_DAY = time + 946684800
unix_time будет посчитан для часового пояса GMT+0000. Для перевода в GMT+0300 (Мск) необходимо к unix_time прибавить 10800 (3 часа).
Однако при выводе данных пользователю (например, при чтении истории performance_insights с помощью запроса SELECT * FROM pg_stat_get_activity_history(NULL,NULL,NULL)), в таблице будет указано время, скорректированное на часовой пояс указанный в postgresql.conf.
Резервное копирование
Независимо от способа создания резервной копии (pg_basebackup / pg_probackup), содержимое папки $PGDATA/pg_perf_insights не будет включаться в бэкап. Наличие файлов разных форматов (zst / gz) на это поведение влияния не оказывает.
Только каталог pg_perf_insights исключается из резервного копирования, значение переменной performance_insights.directory в данном случае не учитывается.
Логирование
-
В рамках процесса performance insights:
При автоматическом удалении файлов формата 0, так и 1, 2 и 3 не выводятся дополнительные сообщения в лог. Как и в предыдущей версии performance insights для этого требуется уровень логирования минимум
DEBUG1, что приведет к выводу большого объема дополнительной информации в процессе работы.При потенциально некорректной настройке, например, отсутствии прав на запись в директорию, в логи будет попадать информация о невозможности записать данные в конкретный файл
*_xxx(для 1, 2 и 3 форматов), но лишь один раз. При этом нужно учитывать, что диапазон в названии новых форматов файлов задается в секундах, соответственно за минуту таких логов может быть 60 штук (на каждую секунду при соответствующей нагрузке).Для формата 0 (Default) поведение аналогичное, однако названия файлов этого формата задаются в минутах, поэтому такой лог будет появляться не чаще, чем раз в минуту.
-
В рамках получения данных в консоли:
При работе с файлами, содержащими некорректные данные (например, в которых не совпадает сохраненный размеров данных с реальным или значение в
headerотличается от ожидаемого), могут выводитьсяWARNINGсообщения c информацией о конкретных проблемах, возникших в ходе обработки данного файла. При этом данные будут прочитаны до момента непосредственной проблемы и лишь в момент появления ошибок будет произведен переход к чтению следующего файла.Информация о невозможности открытия файла по различным причинам относится к этой же категории.
Сценарии работы
Возможные сценарии работы выглядят следующим образом:
-
Для сохранения совместимости со старой структурой устанавливается значение
file_format = 0(используется по умолчанию), структура хранения аналогична старой${PGDATA}/pg_perf_insights. -
Для обеспечения максимального сжатия необходимо установить следующие значения параметров:
file_format = 2 # сжатие в zstd
compression_level = 9 # максимальное сжатие
packed_block_size = 256MB # минимальное количество файлов, высокая компрессияПри значении
performance_insights.sampling_period >= 1sобеспечивается минимальное влияние на производительность сервера. -
Для снижения нагрузки на сервер доступно изменение параметра
compression_level.Важно!
Значение
compression_level = 0может привести к увеличению файлов из-за хранения заголовков сжатия.
Обработка ошибок
При обнаружении дефектного сжатого файла:
- Логируется ошибка, проблемный фрагмент пропускается.
- Некоторые дефекты могут приводить к остановке чтения, включая последующие файлы.
- Имя проблемного файла фиксируется в логах.
Для восстановления поврежденных архивов:
- Рекомендовано использовать внешние утилиты (
gunzip,unzstd) для усечения архивов. - Архивы с данными могут быть перепакованы внешними средствами, но это не гарантируется для всех возможных настроек утилит.
Управление объемом данных
Параметр size_samples_in_files используется для очистки наиболее старых данных при сохранении новых. Фактический объем хранимых данных может быть превышен в двух случаях:
-
При работе с активным сохраняемым диапазоном который больше, чем разрешенный размер хранения.
Пример:
size_samples_in_files=20MB
packed_block_size=256MBФактическое место на диске моет составлять 276MB (
256+20). -
При активной работе с сохраняемым диапазоном. В таком случае, общий объем составит:
size_samples_in_files+packed_block_size(packed_block_size- зависит от коэффициента сжатия).
Получение диагностической информации об узле СУБД
Утилита формирования диагностического отчета предназначена для упрощения и ускорения сбора информации о состоянии и настройках стенда Pangolin. Информация собирается посредством запуска утилиты и передачи в нее определенных параметров сбора и формирует на выходе набор файлов, упакованный в tar.gz архив. Некоторые компоненты отчета требуют повышенных привилегий или доступов к каталогам.
Примечание:
После автоматизированной установки Pangolin утилита доступна в каталоге
/opt/pangolin-diagnostic-tool/bin/. Для установки вручную воспользуйтесь пакетным менеджером и поставляемым компонентом в виде rpm/deb-пакета. Есть возможность скопировать каталог в любое другое доступное пользователю место. Утилита представляет собой скомпилированный бинарный файл и набор.soбиблиотек. Утилита не требует выполнения дополнительных действий для работоспособности и установки дополнительных модулей.
Файловый состав утилиты следующий:
diag— основной файл, который является точкой входа и используется для запуска сбора статистики. Утилита осуществляет сбор аргументов, вывод справки и последовательный запуск модулей сбора информации. После окончания работы утилиты осуществляется архивирование отчета, вывод сообщения о завершении работы и пути до сформированного отчета;utils/common.so— модуль общих переиспользуемых функций (печать в общий лог, создание каталогов, синтаксический анализ текста в csv и т.д.);utils/vars.so— модуль глобальных переменных;utils/sql.so— модуль SQL-скриптов для работы с БД;utils/linux_info.so— модуль сбора информации об ОС;utils/linux_stat.so— модуль сбора статистики использования ОС;utils/logs_collect.so— модуль сбора лог-файлов;utils/config.so— модуль сбора конфигурационных файлов.
Использование
Для запуска утилиты необходимо перейти в каталог diagnostic_tool с исполняемым файлом утилиты и ее библиотеками. Затем произвести запуск утилиты. Примеры:
./diag
./diag --help
./diag --host 127.0.0.1 --port 5433 --user psimax --database first_db --pgbuser pgbouncer --logs --log_lines_count 10
Утилита поддерживает следующие параметры:
$ ./diag --help
usage: diag [-h] [-H HOST] [-p PORT] [-U USER] [-d DATABASE]
[--pgbuser PGBUSER] [--logs] [--pgdata PGDATA]
[--log_lines_count LOG_LINES_COUNT] [--version]
This is the Pangolin or PostgreSQL Diagnostics Collection Script. Some parts
of script need superuser or root privileges, if the privileges are
insufficientsome information cannot be collected.
optional arguments:
-h, --help show this help message and exit
-H HOST, --host HOST database server host or socket directory (default:
127.0.0.1)
-p PORT, --port PORT database server port (default: 5433)
-U USER, --user USER database user name (default: postgres)
-d DATABASE, --database DATABASE
database name (default: postgres)
--pgbuser PGBUSER Pangolin Pooler user name
--logs collect log files
--pgdata PGDATA pgdata dir path
--log_lines_count LOG_LINES_COUNT
count last lines of log for collecting (default: 300)
--version show program's version number and exit
Описание параметров:
-
-U USER,--user USERПараметр username для подключения к СУБД Pangolin.
Значение по умолчанию:
postgres. -
-p PORT,--port PORTПараметр port для подключения к СУБД Pangolin.
Значение по умолчанию:
5433. -
-h,--helpВыводит справку по использованию утилиты.
-
-H HOST,--host HOSTПараметр host для подключения к СУБД Pangolin.
Значение по умолчанию:
127.0.0.1. -
-d DATABASE, `--database DATABASEПараметр database для подключения к СУБД Pangolin.
Значение по умолчанию:
postgres. -
--pgdata PGDATAПараметр, определяющий путь к
$PGDATA. Если не задан — будет произведена попытка поиска данного каталога в переменных окружения и запущенных процессах Pangolin.Значение по умолчанию отсутствует.
-
--pgbuser PGBUSERПараметр username для подключения к виртуальной БД Pangolin Pooler для сбора статистики использования Pangolin Pooler.
Значение по умолчанию отсутствует.
-
--logsПараметр, включающий сбор лог-файлов. По умолчанию лог-файлы не собираются.
-
--log_lines_count LOG_LINES_COUNTПараметр, определяющий, сколько последних строк лог-файлов сохранить в отчет. Параметр введен для ограничения размера итогового отчета, количество строк должно быть достаточным для анализа и не слишком большим для экономии размера, как правило, достаточно 300-700 последних строк.
Значение по умолчанию:
300. -
--versionВыводит версию утилиты и завершает работу.
В случае, если переданные параметры --user или --pgbuser отличаются от значений по умолчанию, утилита запросит пароль для данных пользователей. В ответ на запрос утилиты введите соответствующий пароль (пароль при вводе не отображается).
После того, как утилита отработала, она выдаст сообщение о том, где сохранена диагностическая информация. Отчет формируется в каталоге с утилитой из префикса pgse_diag_out_ и временной метки запуска утилиты YYYYMMDD_HHmmSS, где YYYY — год, MM — месяц, DD — день, HH — часы, mm — минуты, SS — секунды. Сформированный архив с отчетом можно скопировать с удаленного хоста, например, с помощью scp:
scp postgres@{IP-адрес}:/home/postgres/diagnostic_tool/pgse_diag_out_20220607_145935.tar.gz .
Чтобы проверить содержимое архива его нужно распаковать:
tar -xvf ./pgse_diag_out_20220607_145935.tar.gz
Внимание!
Перед отправкой отчета нужно убедиться в отсутствии недопустимой к передаче информации, а именно:
- непараметризованных запросов или значений параметров в секции
collect hot statements statфайлаdiag.log;- непараметризованных запросов или значений параметров в секции
collect slow statements statфайлаdiag.log;- непараметризованных запросов или значений параметров в файле
csv/dbms/hot_statements.csv;- непараметризованных запросов или значений параметров в файле
csv/dbms/slow_statements.csv;- логинов/паролей, а также иной чувствительной информации в секции
collect running servicesфайлаdiag.log(в колонкеCOMMANDстрока запуска процесса);- логинов/паролей, а также иной чувствительной информации в файле
csv/psaux.csv(в колонкеCOMMANDстрока запуска процесса);- логинов/паролей(в том числе хешей паролей) в конфигурационном файле
config/pg_hba.conf;- логинов/паролей(в том числе хешей паролей) в конфигурационном файле
config/postgresql.yml(конфигурационный файл Pangolin Manager, проверить в том числе секциюpg_hba);- непараметризованных запросов и значений параметров в файле
logs/postgresql-XXXXXXXX.log, гдеXXXXXXXXкомбинация из даты и порядкового номера лог-файла.
Отчетность по нагрузке Pangolin
Генерация отчетов для детального анализа истории активности СУБД доступна только для редакций Enterprise и Enterprise для ERP-систем.
Отчетность по нагрузке в Pangolin реализована с помощью расширения pg_profile. Для расширения pg_profile в БД создается набор таблиц под историческое хранилище. Это хранилище будет накапливать статистические выборки с кластера postgres. Выборки собираются вызовом функции take_sample(). Для сбора статистики по расписанию можно использовать cron или расширение pg_cron.
Периодические выборки могут помочь найти источники интенсивной нагрузки в прошлом. Например, стало известно о деградации производительности, которая была несколько часов назад. Для решения подобных проблем можно построить отчет между двумя выборками, охватывающими период проблемы с производительностью, чтобы увидеть профиль нагрузки БД. Это поможет узнать точное время возникновения проблемы с производительностью. Для этого рекомендуется использовать инструмент мониторинга (например, Zabbix).
Выборку можно сохранить непосредственно перед запуском любой бизнес-задачи (блока транзакций) и после того, как она будет выполнена.
Когда сохраняется выборка, вызывается функция pg_stat_statements_reset() как гарантия того, что отчеты не будут потеряны из-за достижения параметра pg_stat_statements.max. Отчет будет содержать раздел, информирующий о том, что количество собранной статистики в любой выборке достигнет 90% от параметра pg_stat_statements.max.
При установке расширения автоматически создается локальный сервер. Это сервер для кластера, где установлено расширение pg_profile.
Для подключения к БД используется расширение db_link.
О работе функций для получения отчетности читайте в документе «Список PL/SQL функций продукта», раздел «Отчетность по нагрузке Pangolin» (документ доступен в личном кабинете).
Установка pg_profile и pg_stat_kcache
Установка всех расширений и их первоначальная настройка производится инсталлятором.
- Расширению
pg_profileтребуются расширенияplpgsql,dblink. - Расширению
pg_stat_kcacheтребуетсяpg_stat_statements(устанавливается по умолчанию на всех серверах). Такжеpg_stat_statementsдолжен быть указан в параметреshared_preload_librariesраньше.
Параметры установщика
| Параметр | Значение по умолчанию | Описание |
|---|---|---|
pg_profile.is_enable | true | Установка базы с установленным расширением pg_profile и настроенным в pg_cron заданием на сборку статистики |
pg_profile.topn | 20 | Количество основных объектов (statements, relations и т.д.), которые должны быть представлены в каждой отсортированной таблице отчета. Параметр влияет на размер выборки - чем больше объектов требуется отобразить в отчете, тем больше объектов нужно сохранить в выборке |
pg_profile.max_sample_age | 7 | Срок хранения выборок в днях |
pg_profile.track_sample_timings | off | Когда этот параметр включен, pg_profile будет отслеживать точное время сбора выборок |
pg_profile.stats_periods | 0,30 * * * * | Строка в стиле crontab для настройки периодов сбора статистики, по умолчанию: раз в полчаса, каждый час в 0 и 30 минут |
pg_stat_track_activities | on | Отслеживание выполняемых серверным процессом команд |
pg_stat_track_counts | on | Контроль, собирается ли статистика о доступе к таблицам и индексам |
pg_stat_track_io_timing | on | Отслеживание времени чтения и записи блоков |
pg_stat_track_functions | off | Отслеживание использования пользовательских функций |
pg_stat_statements_track | top | Контроль учитываемых модулем операторов |
pg_stat_statements_max | 5000 | Максимальное количество операторов, отслеживаемых модулем (то есть максимальное количество строк в представлении pg_stat_statements) |
pg_stat_kcache.is_enabled | true | Установка базы с установленным расширением pg_kcache |
relnblocks_enable | on | Включение механизма подсчета (pg_profile автоматом подхватит значение из этого механизма, а не из pg_class). Изменение требует перезагрузки: в случае значения off память под кеш при старте выделена не будет |
relnblocks_hash_max_size | 1000000 | Максимальное количество отношений (имеющих физические файлы на диске) в базе. В случае превышения заданного значения новое отношение создать будет нельзя. Нужно помнить, что к этим отношениям относятся таблица, индекс, генератор последовательности, таблица хранения сверхбольших атрибутов, материализованное представление. Необходимо внимательно отнестись к этому параметру и установить значение «с запасом» |
relnblocks_hash_init_size | 1024 | Параметр определяет количество отношений в базе (имеющих физические файлы на диске), на которые будет предаллоцирован кеш. кеш-таблица для отслеживания размеров объектов будет размещена одним выровненным куском памяти, и поиск по ней будет быстрее |
Установка в ручном режиме
Описание установки расширений находится всоответствующих разделах документа «Описание расширений продукта СУБД Pangolin».
Сбор статистики с кластеров
Расширение pg_profile, установленное на один кластер, может собирать также статистику с других кластеров, именуемых servers (далее — серверы).
Для этого:
- при помощи функции
create_server()создайте необходимые серверы, указав имя и строку подключения. Подробнее о функции читайте в документе «Список PL/SQL функций продукта», раздел «Отчетность по нагрузке Pangolin» (документ доступен в личном кабинете); - убедитесь, что подключение может быть установлено ко всем БД всех серверов.
После этих действий можно собирать, например, статистику с пассивного узла кластера СУБД (Standby) подключаясь к ней с активного узла кластера СУБД (Active).
Настройка параметров
Задать параметры настроек можно в файле postgresql.conf (указаны значения по умолчанию):
track_activities = on— мониторинг текущих команд для каждого процесса вpg_stat_activity;track_counts = on— мониторинг текущих команд для каждого процесса вpg_stat_all_tables;track_io_timing = on— мониторинг времени чтения/записи блоков вpg_stat_statements,pg_stat_kcache;track_functions = none— включает подсчет вызовов функций и времени их выполнения. Значениеplвключает отслеживание только функций на процедурном языке, аall— также функций на языкахSQLиCдля представленияpg_stat_user_functions;track_activity_query_size = 1024— задает число байт, которое будет зарезервировано для отслеживания выполняемой в данный момент команды в каждом активном сеансе вpg_stat_statements.
Параметры pg_profile
pg_profile.topn = 20— количество основных объектов (statements, relations и т.д.), которые должны быть представлены в каждой отсортированной таблице отчета. Этот параметр влияет на размер выборки — чем больше объектов необходимо отобразить в отчете, тем больше объектов нужно сохранить в выборке;pg_profile.max_sample_age = 7— срок хранения выборок в днях. Выборки, возраст которых равенpg_profile.max_sample_ageдней и более, будут автоматически удалены при следующем вызовеtake_sample();pg_profile.track_sample_timings = off— когда этот параметр включен, расширениеpg_profileбудет отслеживать точное время сбора выборок;pg_profile.query_length = 20000— ограничение размера запросов, применяется только к тем запросам, которые выполнялись во время сбора статистики. Не применяется к запросам изpg_stat_statements.
Параметры pg_stat_statements (влияют на pg_stat_kcache)
pg_stat_statements.max = 5000(из установщика) — максимальное количество различных запросов, по которым хранится статистика. Если этот параметр будет недостаточно большим — расширениеpg_profileбудет выдавать предупреждения (в случае, если кеш при сборе статистики заполнен на 80%);pg_stat_statements.track = 'top'— типы запросов (top/nested) по которым хранится статистика:top,all,none;pg_stat_statements.track_utility = 'on'— при значении параметраoff, статистика будет храниться только для запросов SELECT, INSERT, UPDATE и DELETE;pg_stat_statements.track_planning = 'off'— сохранять отдельно статистику этапа планирования;pg_stat_statements.save = 'on'— сохранять статистику в файл, в случае штатной перезагрузки сервера.
Параметры pg_stat_kcache
pg_stat_kcache.linuz_hz = -1— установить частоту аппаратных прерываний (тиков CPU ) для компенсации ошибок выборки. Для данного расширения можно явно указать, какой параметр задан в системе (параметр CONFIG_HZ ядра linux). По умолчанию установлено значение-1— это означает, что расширение попытается автоматически рассчитать эту частоту при старте.
Параметры подсчета точных размеров отношений (указаны значения по умолчанию)
-
relnblocks_enable = 'on'— включение механизма подсчета (pg_profileавтоматом подхватит значение из этого механизма, а не изpg_class); -
relnblocks_hash_max_size = 1000000— максимальное количество отношений (имеющих физические файлы на диске) в базе. В случае переполнения этого числа новое отношение нельзя будет создать.Внимание!Необходимо внимательно отнестись к параметру
relnblocks_hash_max_sizeи взять достаточный запас, так как к этим отношениям относятся:- таблица;
- индекс;
- генератор последовательности;
- таблица хранения сверхбольших атрибутов;
- материализованное представление.
-
relnblocks_hash_init_size = 1024— количество отношений (имеющих физические файлы на диске) в базе, на которые будет предварительно выделен кеш.В этом случае хеш-таблица для отслеживания размеров объектов будет размещена одним выровненным куском памяти, и поиск по ней будет быстрее.
Использование pg_profile
Подробное описание расширения в документе «Описание расширений продукта СУБД Pangolin», раздел «pg_profile», подраздел «Использование модуля».
Отслеживание времени изменения объекта СУБД
В целях повышения удобства сопровождения СУБД, при выявлении причин снижения ее производительности, вызванного выполнением DDL-операций над объектами БД, предоставляется инструмент в виде двух представлений psql_dba_objects и psql_all_objects.
Данный инструмент доступен только для редакций Enterprise и Enterprise для ERP-систем.
Данные представления используются для отслеживания даты/времени последней модификации объектов СУБД psql_dba_objects и psql_all_objects.
Пример выполнения запроса представления psql_dba_objects:
select * from pg_catalog.psql_dba_objects;
-[ RECORD 1 ]-+------------------------------
oid | 16384
name | t1
namespace | 2200
type | table
owner | postgres
ispredef | f
created | 2022-05-31 12:58:20.765479+03
last_ddl_time | 2022-05-31 12:58:20.765479+03
deleted |
Пример выполнения запроса представления psql_all_objects:
select * from pg_catalog.psql_all_objects;
-[ RECORD 1 ]-+------------------------------
oid | 16384
name | t1
namespace | 2200
type | table
owner | postgres
ispredef | f
created | 2022-05-31 12:58:20.765479+03
last_ddl_time | 2022-05-31 12:58:20.765479+03
deleted |
Примечание:
Обновление поля
last_ddl_timeосуществляется в обработчиках DDL-команд, изменяющих логическую структуру объекта, а так жеGRANT/REVOKE. В обработчиках остальных DDL-команд, не модифицирующих логическую структуру объекта, значение поля не меняется. К таким DDL-командам относятся:
REINDEX;CLUSTER;TRUNCATE;VACUUM;VACUUM FULL;REFRESH MATERIALIZED VIEW [CONCURRENTLY].
Для очистки записей о датах изменения удаленных объектов используется функция purge_object_mod_dates([start_time timestamptz, end_time timestamptz]) → void.
Функция принимает на вход начало и конец интервала времени, в пределах которого требуется очистить записи объектов, даты удаления которых попадают в этот интервал. Входные аргументы могут быть опущены, тогда функция удалит записи о всех удаленных объектах за все время существования БД.
В качестве неопределенной границы интервала времени может использоваться значение NULL. Вызов упрощенной вариации функции без аргументов purge_object_mod_dates() равнозначен вызову purge_object_mod_dates(NULL, NULL) и purge_object_mod_dates('-infinity', 'infinity').
Пример использования функции purge_object_mod_dates():
select purge_object_mod_dates('2022-06-08 09:24:51'::timestamptz, '2022-06-08 10:24:51'::timestamptz);
select purge_object_mod_dates('-infinity', '2022-06-08 10:24:51'::timestamptz);
select purge_object_mod_dates('2022-06-08 09:24:51'::timestamptz, 'infinity');
select purge_object_mod_dates('-infinity', 'infinity');
select purge_object_mod_dates(NULL, '2022-06-08 10:24:51'::timestamptz);
select purge_object_mod_dates('2022-06-08 09:24:51'::timestamptz, NULL);
select purge_object_mod_dates(NULL, NULL);
select purge_object_mod_dates();
select purge_object_mod_dates(now() - interval '1 day', now());
Для сохранения информации о датах изменения удаленных объектов, в течение некоторого интервала времени, введен параметр object_modification_date_keep_interval. В пределах этого интервала времени функции очистки запрещено удалять записи с датами изменения удаленных объектов, которые входят в этот интервал. Интервал отсчитывается от момента выполнения функции очистки psql_purge_object_mod_dates(). Параметр принимает неотрицательные значения типа interval. Если указан нулевой интервал (0), то ограничения на выполнение функции очистки не накладываются. Значение по умолчанию - 1 week (1 неделя). Для изменения параметра необходим перезапуск сервера Pangolin.
Внимание!
Может потребоваться увеличить параметр
max_worker_processes, чтобы это число включало дополнительные рабочие процессы, обновляющие даты создания и модификации объектов в новой БД после ее создания.
Отключению функциональности
Для включения/отключения функциональности предназначен конфигурационный параметр enable_monitor_object_modification_date (в файле postgresql.conf). Значение параметра по умолчанию - on. Для изменения параметра необходим перезапуск сервера Pangolin.
Управление планами запросов
Для возможности ручной оптимизации планов запросов в Pangolin используются расширения pg_outline, pg_hint_plan и pg_store_plans.
Расширения pg_store_plans, pg_outline и pg_hint_plan входят в состав СУБД Pangolin. Эти расширения, в совокупности, предоставляют возможность фиксации и подмены планов запросов для оптимизации работы планировщика запросов.
Расширение pg_hint_plan
Расширение pg_hint_plan управляет планом выполнения с помощью фраз-подсказок (hint), записываемых в виде простых описаний в SQL-комментариях особого вида.
Функциональные возможности:
-
подсказки (hint) планировщику запросов для управления планами выполнения запросов, в части:
- методов сканирования таблиц;
- методов соединения таблиц;
- порядка соединения;
- корректировки числа строк результата соединения;
- настройки параллельности обработки таблиц;
- установки значений параметров конфигурации на время планирования запроса;
-
управление планами подготовленных запросов (prepared statements) через заданные в тексте этих запросов подсказок (hint);
-
управление планами запросов в составе PL/pgSQL-блока через подсказки (hint), заданные в тексте запросов в PL/pgSQL-блоках;
-
дополнение запросов подсказками «на лету» на этапе планирования запроса на уровне всей СУБД в составе СУБД Pangolin. Это позволяет выполнять:
-
компенсационную корректировку запросов на основе заполняемой таблицы подсказок, которая устанавливает соответствие текста дополняемого запроса и имени приложения (опционально);
-
компенсационную корректировку для:
- запросов с динамическими параметрами (подсказкой плейсхолдеров, вместо конкретных значений);
- подготовленных запросов;
-
-
управление (через настроечные параметры) на уровне сессии пользователя или всей СУБД в составе СУБД Pangolin:
- активностью расширения;
- использованием функциональности дополнения подсказками через таблицу подсказок;
- уровнем логирования, с которым в лог будут писаться сообщения об ошибках разбора подсказок;
- детализацией записей отладочной информации расширения;
- уровнем логирования, с которым в лог будут писаться сообщения с отладочной информацией.
С настройкой расширения и его объектами можно ознакомиться в одноименном разделе расширения pg_hint_plan документа «Описание расширений продукта СУБД Pangolin».
Использование подсказок
Использование подсказок описано в документе «Описание расширений продукта СУБД Pangolin», раздел «pg_hint_plab», подраздел «Использование подсказок».
Расширение pg_outline
Расширение pg_outline предназначено для изменения плана выполнения запросов.
Функциональные возможности:
- управление (добавить, заменить, удалить, включить, выключить) правилами подмены (фиксациями подсказок
pg_hint_plan) планов запросов; - возврат информации о созданных правилах подмены планов запросов;
- возврат идентификатора запроса (
queryId) для текста запроса (queryText).
С настройкой расширения и его объектами можно ознакомиться в одноименном разделе расширения pg_outline документа «Описание расширений продукта СУБД Pangolin».
Расширение pg_store_plans
Расширение pg_store_plans предназначено для накапливания статистики по планам выполнения всех SQL-запросов, выполняемых в БД.
С настройкой расширения и его объектами можно ознакомиться в одноименном разделе расширения pg_store_plans документа «Описание расширений продукта СУБД Pangolin».
Восстановление работоспособности узла кластера при смене параметров сервера
В состав Pangolin включена утилита pangolin-auth-reencrypt, которая используется для восстановления работоспособности узла кластера при смене параметров сервера.
После автоматизированной установки СУБД Pangolin утилита доступна в каталоге /opt/pangolin-auth-reencrypt/bin/pangolin-auth-reencrypt.
Утилита запускается в двух режимах:
- автоматический — запуск настраивается при установке Pangolin;
- ручной — вызов бинарного файла утилиты с указанием требуемых параметров и предварительной настройкой утилиты.
Автоматический запуск утилиты (службой systemd)
Установщик Pangolin создает новую службу/службы systemd (зависит от конфигурации кластера) для запуска и отслеживания состояния демона утилиты.
В автоматическом режиме утилита в процессе работы создает файл enc_params.cfg + '.' + 'имя_пользователя' в каталоге /etc/postgres. Файл создается с правами -rw-rw-r-- владельцем, от имени которого был запущен демон. Содержимое файла засекречено. Утилита используется для хранения текущих параметров сервера. Изменение параметров сервера детектируется на основе данного файла.
Служба/службы запускаются при старте ОС и запускают демонов утилиты перекодирования, которые периодически (с периодом 5 секунд) проверяют параметры оборудования и, если они поменялись, обновляют файлы с засекреченной информацией. В зависимости от конфигурации кластера файлы могут принадлежать:
- пользователю — Администратору СУБД (
postgres). В данном случае запускается один демон утилиты от имени пользователяpostgres; - или пользователям — Администратору СУБД (
postgres) и Администратору безопасности (kmadmin_pg). В этом случае запускаются два демона: от имени пользователяpostgresи от имени пользователяkmadmin_pg.
Список файлов для разных пользователей определяется конфигурацией утилиты (тег «owner», см. ниже «Конфигурационный файл утилиты»).
Для управления демоном утилиты служба создает каталог /var/run/pangolin_reencrypt/, где демон создает файл pangolin_reencrypt_<имя_пользователя_запустившего_утилиту>, содержащий идентификатор процесса pid. Отсутствие каталога не приводит к завершению работы утилиты с ошибкой, но будет выведено предупреждение в журнал: Create pid file failed.
Ручная установка утилиты
Установите пакет компонента pangolin-auth-reencrypt:
- SberLinux, РЕД ОС, CentOS
- Astra Linux
- Альт СП
sudo dnf install pangolin-auth-reencrypt-{product_version}-{OS}.x86_64.rpm
sudo apt install pangolin-auth-reencrypt-{product_version}_amd64.deb
sudo apt-get install pangolin-auth-reencrypt-{product_version}-{OS}.x86_64.rpm
Пример заполненной команды:
cd distributive
sudo dnf install -y utilities/pangolin-auth-reencrypt-6.5.2-sberlinux9.x86_64.rpm
Ручной запуск утилиты
Для запуска утилиты в ручном режиме требуется:
-
подготовить конфигурационный файл утилиты;
-
запустить бинарный файл утилиты с требуемыми параметрами (см. ниже «Параметры запуска утилиты»):
/etc/postgres/pangolin-auth-reencrypt [OPTION]
При ручном запуске утилита также создает файл enc_params.cfg + '.' + 'имя_пользователя' с правами -rw-rw-r-- в каталоге /etc/postgres. Владельцем файла в данном случае будет пользователь, от имени которого была запущена утилита. Если у пользователя нет прав на создание файла в каталоге /etc/postgres, работа утилиты будет завершена с ошибкой.
Ручной запуск утилиты перекодирования на кластере
На версиях кластера от 4.4.0 (где внедрено засекречивание файлов с параметрами подключения) возможна ручная установка утилиты, для этого:
-
Расположите исполняемый файл утилиты в каталоге
/opt/pangolin-auth-reencrypt/bin/pangolin-auth-reencrypt(владелец:root, группа: root, права:-rwxr-xr-x). Исполняемый файл утилиты располагается в дистрибутиве по путиpangolin-auth-reencrypt/opt/pangolin-common/bin/pangolin-auth-reencrypt. -
Расположите файл конфигурации утилиты
/etc/pangolin-auth-reencrypt/enc_util.cfg(владелец:root, группа:root, права:rw-r--r–). Зависит от конфигурации кластера (см. ниже «Шаблон конфигурации утилиты перекодирования). -
Создайте службу-шаблон с запуском демона в systemd (см. ниже «Шаблон спецификации службы для утилиты перекодирования»):
- имя службы
pangolin_reencrypt@.service; - служба запускается от пользователя переданного с помощью параметра (пример:
pangolin_reencrypt@postgres.service); - служба должна создавать каталог
/var/run/pangolin_reencryptдляpidфайла(ов). Владелецpostgres, группаkmadmin\_pg,g+rw; - служба должна запускать утилиту перекодирования паролей
/opt/pangolin-auth-reencrypt/bin/pangolin-auth-reencrypt; - служба должна автоматически запускаться при каждой загрузке Linux и в случае сбоев (
Restart=on-failure);
- имя службы
-
Обновите службы systemd (
sudo systemctl daemon-reload). -
Запустите новую службу/службы (в зависимости от конфигурации кластера) и установите принудительный запуск при каждой загрузке ОС (
sudo systemctl enable --now pangolin_reencrypt.service).
Шаблон конфигурации утилиты перекодирования
{
"files" :
[
### файл 1: включается, если на кластере активирован tde или admin_protection
{
"name" : "{{ KMS_CONFIG }}",
"owner" : "kmadmin_pg",
"domain" : "kms"
},
### файл 2: включается на всех конфигурациях
{
"name" : "{{ pg_encrypt_cfg }}",
"owner" : "postgres",
"domain" : "postgres"
},
### файл 3: включается для конфигураций с Pangolin Manager
{
"name" : "/etc/pangolin-manager/postgres.yml",
"owner" : "postgres",
"secrets" :
[
{
"type" : "tag",
"name" : "restapi/authentication/password",
"domain" : "postgres"
},
{
"type" : "tag",
"name" : "etcd/password",
"domain" : "postgres"
},
{
"type" : "text",
"name" : "ldapbindpasswd",
"domain" : "postgres"
}
]
}
### файл 4: включается для конфигураций без Pangolin Manager
{
"name" : "pg_hba.conf",
"owner" : "postgres",
"secrets" :
[
{
"type" : "text",
"name" : "ldapbindpasswd",
"domain" : "postgres"
}
]
}
]
}
Примечание:
###— начало комментария, необходимо удалить перед записью конфигурации на диск. Если условие в комментарии не выполняется, то вместе с комментарием нужно удалить описание файла, следующее за ним.
Шаблон спецификации службы для утилиты перекодирования
[Unit]
Description=Runners Pangolin reencrypt service (%i)
After=syslog.target network.target
[Service]
Type=forking
User=%i
Group=%i
Environment="PGDATA=<path>/data"
Environment="PG_PLUGINS_PATH=<path>/lib"
PermissionsStartOnly=true
ExecStartPre=/bin/mkdir -p /var/run/pangolin_reencrypt
ExecStartPre=/bin/chown postgres:kmadmin_pg /var/run/pangolin_reencrypt
ExecStartPre=/bin/chmod g+rw /var/run/pangolin_reencrypt
ExecStartPost=/bin/sleep 1
ExecStart=/opt/pangolin-auth-reencrypt/bin/pangolin-auth-reencrypt -l2 -d
PIDFile=/var/run/pangolin_reencrypt/pangolin_reencrypt_%i.pid
Restart=on-failure
[Install]
WantedBy=multi-user.target
Примечание:
<path>— домашняя директория Pangolin
Конфигурационный файл утилиты
Установщик Pangolin создает конфигурационный файл утилиты enc_util.cfg, который расположен в каталоге /etc/postgres. Файл создается с правами -rw-r--r-- и владельцем root:root. Вносить изменения в файл может только привилегированный пользователь.
Конфигурационный файл хранится в формате JSON. Файлы с засекреченными параметрами подключения к БД задаются ключом files.
Для каждого файла указывается:
-
имя, через ключ
name. Если указано неполное имя файла, то поиск файла происходит в каталоге, определенном через переменную окруженияPGDATA; -
владелец файла, через ключ
owner. Утилита проверяет пользователя, который ее запустил: если в конфигурации утилиты для файла указан другой владелец, то утилита пропускает этот файл; -
домен кодирования, через ключ
domain. В случае, если файл засекречивается полностью, то кроме имени и владельца требуется указать домен через ключdomain, для которого производится засекречивание. Когда требуется засекретить отдельные пароли в файлах, то с помощью ключаsecretsуказывается массив с описанием метода поиска пароля в файле. Метод поиска задается с помощью ключей:-
type— указывает тип поиска; -
name— указывает идентификатор пароля.Примечание:
Если в
typeустановлено значение«tag»— файл разбирается по форматуyml. Поиск пароля происходит по тегам, указанным в полеnameв порядке записи (теги разделены символом'/').Если в
typeустановлено значение«text», то поиск пароля в файле происходит по строкеname=<искомый_пароль>.
-
Для файла или отдельного пароля в файле можно указать булевый признак опциональности через ключ opt. Если признак задан и равен true, то отсутствие файла на диске или отсутствие пароля внутри файла не приводит к ошибкам в работе утилиты. Если признак не задан или задан и равен false, то отсутствие файла или отстутствие пароля внутри файла приведет к ошибкам в работе утилиты, при условии что утилита запущена без параметра -f (см. Параметры запуска утилиты).
Пример конфигурационного файла утилиты для конфигурации без Pangolin Manager, но с tde:
{
"files" :
[
{
"name" : "/etc/pangolin-security-utilities/enc_connection_settings.cfg",
"owner" : "kmadmin_pg",
"domain" : "kms",
"opt" : true
},
{
"name" : "/etc/pangolin-auth-encryption/enc_utils_auth_settings.cfg",
"owner" : "postgres",
"domain" : "postgres"
},
{
"name" : "pg_hba.conf",
"owner" : "postgres",
"secrets" :
[
{
"type" : "text",
"name" : "ldapbindpasswd",
"domain" : "postgres"
}
]
}
]
}
Параметры запуска утилиты
-
-c --conf— необязательный параметр. Задает файл конфигурации утилиты, который требуется проверить на наличие ошибок. Утилита проверит файл на наличие ошибок и завершит работу с кодом 0, если конфигурация не содержит ошибок, и 1, если указанный файл невалиден.Параметр может быть комбинирован с параметром
-l, при этом будет выведено диагностическое сообщение о результате проверки конфигурации. Рекомендуется проверить конфигурационный файл на наличие ошибок в процессе обновления файла/etc/pangolin-auth-reencrypt/enc_util.cfg, который используется утилитой при перекодировании.Если задан параметр
-c, то параметры-f -r -sбудут проигнорированы. -
-l --log— необязательный параметр. Включает лог утилиты. Совместим со всеми остальными параметрами. -
-L --log-dir- необязательный параметр. Задает каталог, в котором будут храниться файлы логов. Совместим со всеми параметрами.Примечание:
Ключ работает только совместно с ключом -l.
Если каталог не существует, он будет создан.
Логирование будет производиться в файл.
Поддерживает ротацию логов.
-
-m --max-log-files- необязательный параметр. Ограничивает количество хранимых логов. Совместим со всеми параметрами.Примечание:
Если значение равно 0, отключает автоматическое удаление логов.
Значение по умолчанию - 100.
-
-n --log-name- необязательный параметр. Задает шаблон имени файла лога. Совместим со всеми параметрами.Примечание:
Значение по умолчанию - pangolin-auth-reencrypt-%Y-%m-%d_%H-%M-%S-%f, где %f — дополнительный параметр, определяющий текущее значение микросекунд.
-
-z --max-log-size- необязательный параметр. Устанавливает максимальный размер лог-файла в килобайтах перед его ротацией. Совместим со всеми параметрами.Примечание:
Значение по умолчанию — 100МБ.
Минимальное допустимое значение: 50 КБ, при значении менее 50 КБ запуск утилиты завершится ошибкой.
Реальный размер файла может быть немного больше заданного, так как утилита проверяет размер файла каждые 200 строк и дотирует после того, как файл превысит заданное.
-
-f --force— необязательный параметр. Запускает утилиту в режиме игнорирования ошибок. Совместим со всеми параметрами.Если указан параметр
-c, параметр-fучитываться не будет. -
-r, --roll— необязательный параметр. Запускает утилиту в режиме отката операции перекодирования. Может задавать файл, для которого требуется применить процесс отката. Если файл не задан, то процесс отката перекодирования применяется ко всем файлам, указанным в конфигурации утилиты. Совместим со всеми параметрами.Если указан параметр
-c, параметр-rучитываться не будет. -
-s, --stable— необязательный параметр. Учитывается только в режиме перекодирования. Запрещает обновление/создание файла с параметрами оборудования. Используется при запуске утилиты для файлов с засекреченной информацией, принадлежащих разным пользователям.Примечание:
Параметр
-s, --stableнеобходимо указывать при первых запусках утилиты. Порядок вызовов утилиты имеет значение, поскольку при последнем вызове (без параметра-s) будет создан файл с параметрами оборудования, принадлежащий пользователю на момент вызова. -
-e, --enc— необязательный параметр. Задает отдельный файл для перекодирования, который должен быть описан в конфигурации утилиты. Если этот параметр задан — перекодирование осуществляется только для данного файла, остальные файлы из конфигурации не перекодируются. -
-d, --daemon— необязательный параметр. Запускает утилиту в виде службы Linux (демона) для непрерывного отслеживания изменения параметров оборудования сервера (проверка изменения происходит с периодом 5 секунд). -
-p, --pid-file— необязательный параметр. Позволяет указать путь к PID-файлу, отличный от значения по умолчанию:/var/run/pangolin_reencrypt/pangolin_reencrypt__%i.pid.Примечание:
Если файл не существует, он будет создан.
Флаг работает только совместно с флагом -d/—daemon, при отсутствии ключа -d/—daemon утилита не запускается.
Примечание:
Ключи
-d,-c(проверка конфигурации),-e(перекодирование отдельного файла),-r(откат операции перекодирования) несовместимы: если используются два и более ключа, то утилита не запускается.
Управление службой утилиты
Управлять утилитой pangolin-auth-reencrypt, запущенной в виде службы, можно с помощью следующих сигналов Linux:
- SIGTERM - отправка запроса на завершение работы;
- SIGUSR1 - отправка запроса на внеочередную проверку параметров оборудования;
- SIGRTMIN - отправка запроса на проверку параметров (формируется таймером с периодом 5 секунд).
Режим игнорирования ошибок
По умолчанию утилита останавливает свою работу, если в процессе перекодирования/отката перекодирования одного из файлов возникла ошибка. При возникновении ошибки в процессе перекодирования все файлы возвращаются в исходное состояние, выводится сообщение об ошибке и возвращается соответствующий код. Откат перекодирования в случае отсутствия резервной копии одного из файлов завершается с ошибкой, все файлы остаются в исходном состоянии.
В режиме игнорирования ошибок возникновение ошибки в процессе перекодирования/отката перекодирования файлов не приводит к остановке работы утилиты, последовательно предпринимаются попытки перекодировать/восстановить все файлы, указанные в файле конфигурации.
Режим отката операции перекодирования
Перед началом процесса перекодирования утилита создает резервные копии файла с параметрами оборудования и файлов с зсекреченными параметрами подключения к БД. Резервная копия создается в том же каталоге, где и исходный файл. Имя резервной копии файла формируется по принципу: .имя_оригинала_с_расширением.bak (пример для файла enc_params.cfg: .enc_params.cfg.bak).
В режиме отката операции перекодирования утилита возвращает файлы в исходное состояние на основании резервных копий.
Код завершения работы утилиты
В случае успеха утилита возвращает ноль. Если работа утилиты завершилась с ошибкой — утилита возвращает код ошибки:
- 0 — операция перекодирования, откат операции перекодирования завершились с успехом (файл конфигурации не содержит ошибок для параметра
-c); - 1 — ошибка в файле конфигурации утилиты;
- 2 — работа завершена с ошибкой (подробности указаны в логе).
Отключение функциональности утилиты
Для отключения функциональности:
-
Остановите службу/службы systemd Linux, запускающие демон утилиты.
Для службы, запущенной от имени пользователя
kmadmin_pg:sudo systemctl stop pangolin_reencrypt@kmadmin_pgДля службы, запущенной от имени пользователя
postgres:sudo systemctl stop pangolin_reencrypt@postgres -
Переведите состояние служб в
disable.Для службы, запущенной от имени пользователя
kmadmin_pg:sudo systemctl disable --now pangolin_reencrypt@kmadmin_pgДля службы, запущенной от имени пользователя
postgres:sudo systemctl disable --now pangolin_reencrypt@postgresЕсли демон утилиты запущен вручную, то требуется отправить процессу демона сигнал
SIGTERM, для этого:-
Определите идентификаторы процессов демона:
ps aux | grep -i pangolin-auth-reencrypt -
Для всех найденных процессов демона отправьте сигнал:
kill -SIGTERM <pid>
<pid>— найденный идентификатор процесса демона. -
Лог утилиты
Утилита формирует лог в стандартный поток вывода Linux. Журнал (log) содержит информацию о процессе работы утилиты. Журнал (log) утилиты может быть перенаправлен в файл средствами ОС. Включение журналирования задается параметром -l или --log. По умолчанию утилита выводит сообщения только в случае ошибок.
В режиме работы демона записи (log) переводятся в системный журнал Linux syslog. В этом режиме дополнительно в записи журнала поступает информация о результате инициализации демона. В случае успешного запуска демона утилиты в логе появится строка Reencrypt daemon was started for <имя_пользователя_запустившего_утилиту>.
В утилите предусмотрена возможность задать уровни логирования:
- уровень 1 (
-l1или--log=1) — показывать только ошибки; - уровень 2 (
-l2или--log=2) — показывать записи (log) по перекодированию данных и ошибки; - уровень 3 (
-l3или--log=3) — показывать лог по проверке параметров оборудования, перекодированию данных и ошибки.
По умолчанию (без указания уровня: -l или --log) используется 3 уровень логирования.
Примечание:
Для режима демона рекомендуется запускать утилиту с уровнем лога не выше 2, чтобы в системный журнал попадали только ключевые моменты работы.
Примеры:
-
Ошибка в конфигурационном файле:
2022-06-06 17:33:52.870752130 [18572] ERROR: Configuration file content (json) error: /etc/pangolin-auth-reencrypt/enc_util.cfg
2022-06-06 17:33:52.870818918 [18572] LOG: Load configuration /etc/pangolin-auth-reencrypt/enc_util.cfg FAIL -
Запуск утилиты первый раз:
2022-06-06 17:29:33.914889769 [18200] LOG: Load configuration /etc/pangolin-auth-reencrypt/enc_util.cfg ok
2022-06-06 17:29:33.916778674 [18200] LOG: Start saving current encrypting params
2022-06-06 17:29:33.923238749 [18200] LOG: Saving current encrypting params ok -
Повторный запуск утилиты при неизменных параметрах сервера:
2022-06-06 17:29:46.226502410 [18264] LOG: Load configuration /etc/pangolin-auth-reencrypt/enc_util.cfg ok
2022-06-06 17:29:46.228432243 [18264] LOG: Check encrypting params in file
2022-06-06 17:29:46.234465754 [18264] LOG: Encrypting params in file are equal to the current
Синхронизация запуска утилиты и сервера базы данных
Для корректного запуска сервера базы данных необходимо удостовериться, что утилита перекодирования отработала успешно в случае изменения каких-либо параметров сервера. Для этого в конфигурационном файле postgresql.conf необходимо сконфигурировать два параметра:
reencrypt.monitored_files— путь к файлам<имя_пользователя_запустившего_утилиту>.done, которые утилита перекодирования создает при своей работе после удачного перекодирования;reencrypt.wait_timeout— тайм-аут в секундах, в течение которого база данных будет ожидать появления файлов<имя_пользователя_запустившего_утилиту>.done, создаваемых утилитой перекодирования.
Пример конфигурации:
reencrypt.monitored_files = '/opt/pangolin-auth-reencrypt/pg-sync-data/postgres.done,/opt/pangolin-auth-reencrypt/pg-sync-data/kmadmin_pg.done'
reencrypt.wait_timeout = 30
В случае обнаружения сервером баз данных сконфигурированных <имя_пользователя_запустившего_утилиту>.done файлов или по истечении времени тайм-аута запуск сервера будет продолжен.
Функциональность FOREIGN DATA WRAPPER для БД Oracle
Расширение oracle_fdw — это внешняя оболочка данных, которая позволяет получать доступ к таблицам и представлениям базы данных Oracle через сторонние таблицы. Когда клиент СУБД Pangolin обращается к внешней таблице, расширение oracle_fdw обращается к соответствующим данным во внешней базе данных Oracle через библиотеку интерфейса вызовов Oracle (OCI) на сервере PostgreSQL в СУБД Pangolin. Это расширение PostgreSQL предоставляет доступ к базам данных Oracle из СУБД Pangolin, включая отображение условий WHERE и требуемых столбцов, а также всестороннюю поддержку EXPLAIN.
Для обработки и проверки создаваемого расширения oracle_fdw используются функции oracle_fdw_handler и oracle_fdw_validator. Описание всех функций расширения в разделе «Функциональность FOREIGN DATA WRAPPER для БД Oracle» документа «Список PL/SQL функций продукта» (документ доступен в личном кабинете).
Расширение появилось в СУБД Pangolin в версии 4.5.0.
Примечание:
Внутреннее устройство описано в подразделе «Расширение oracle_fdw» данного документа.
Расширение oracle_fdw
Расширение oracle_fdw — это внешняя оболочка данных, которая позволяет получать доступ к таблицам и представлениям баз данных Oracle через сторонние таблицы из СУБД Pangolin, включая отображение условий WHERE и требуемых столбцов, а также всестороннюю поддержку EXPLAIN.
Расширение oracle_fdw устанавливает значение параметра postgres в параметр MODULE в сессии Oracle и pid backend-процесса в параметр ACTION. Это позволяет идентифицировать сессию Oracle и делает возможной ее трассировку с помощью DBMS_MONITOR, SERV_MOD_ACT_TRACE_ENABLE.
Расширение oracle_fdw использует предварительную выборку результатов Oracle, чтобы избежать ненужных обходов между клиентом и сервером. Количество строк предварительной выборки можно настроить с помощью опции таблицы prefetch, по умолчанию оно равно 200.
В Oracle при планировании запросов функция EXPLAIN PLAN помещает планы выполнения запросов в таблицу PLAN_TABLE. Вместо того, чтобы использовать PLAN_TABLE для формирования плана запроса Oracle (что потребовало бы создания такой таблицы в базе данных Oracle), oracle_fdw использует планы выполнения, хранящиеся в кеше библиотеки. Для этого явно описывается запрос Oracle, что заставляет Oracle анализировать запрос. Сложность заключается в том, чтобы найти SQL_ID и CHILD_NUMBER запроса в V$SQL, потому что столбец SQL_TEXT содержит только первые 1000 байт запроса. Поэтому oracle_fdw добавляет комментарий, содержащий MD5-хеш текста запроса, к самому запросу. Данный способ используется для поиска в V$SQL. Фактический план выполнения или информация о затратах извлекаются из V$SQL_PLAN.
Расширение oracle_fdw использует уровень изоляции транзакций SERIALIZABLE на стороне Oracle, что соответствует REPEATABLE READ в Postgresql. Это необходимо, поскольку один запрос PostgreSQL может привести к нескольким запросам в Oracle (например, во время вложенного JOIN), и результаты должны быть согласованными.
Транзакция Oracle фиксируется непосредственно перед фиксацией локальной транзакции, так что завершенная транзакция PostgreSQL гарантирует завершение транзакции Oracle. Однако существует небольшая вероятность того, что транзакция PostgreSQL не сможет завершиться, даже если транзакция Oracle зафиксирована. Этого нельзя избежать без использования двухфазных транзакций и менеджера транзакций, что выходит за рамки того, что может разумно предоставить внешняя обертка данных.
Подготовленные запросы, передаваемые в Oracle, не поддерживаются по той же причине.
Установка и настройка
Описание установки расширения находится в одноименном разделе расширения oracle_fdw документа «Описание расширений продукта СУБД Pangolin».
Порядок установки переменной LD_LIBRARY_PATH в окружении Pangolin Manager
При работе экземпляра под управлением Pangolin Manager игнорируется переменная окружения LD_LIBRARY_PATH, инициализированная в .bash_profile в домашней директории пользователя postgres. Это происходит потому, что в systemd unit жестко прописано новое значение этой переменной.
Для того чтобы переменная применилась, ее необходимо вносить непосредственно в systemd unit Pangolin Manager, расположение которого можно узнать командой:
systemctl status pangolin-manager.service
По умолчанию он расположен в каталоге /usr/lib/systemd/system/pangolin-manager.service.
Порядок действий:
-
Пользователем с правами
sudoоткройте на редактирование файлpangolin-manager.service. -
Если в качестве
Environmentуже задана переменнаяPG_LD_LIBRARY_PATH, добавьте в нее существующий путь к библиотекам Oracle Client, например,/usr/lib/oracle/19.18/client64/lib. В результате строка будет выглядеть примерно так:Environment="PG_LD_LIBRARY_PATH=/usr/pangolin-5.5.0/lib:/usr/lib/oracle/19.18/client64/lib" -
Если переменная
PG_LD_LIBRARY_PATHотсутствует, добавьте строку сLD_LIBRARY_PATHили приведите ее к виду:Environment="LD_LIBRARY_PATH=/usr/pangolin-5.5.0/lib:/usr/lib/oracle/19.18/client64/lib" -
Обновите конфигурацию
systemd:sudo systemctl daemon-reload -
Остановите сервис pangolin-manager:
sudo systemctl stop pangolin-manager -
Запустите сервис pangolin-manager:
sudo systemctl start pangolin-manager
После запуска сервиса переменная будет определена на уровне службы Pangolin Manager.
Параметры
Параметры оболочки внешних данных (FOREIGN DATA WRAPPER)
Внимание!
Рекомендуем всегда создавать новую оболочку внешних данных (
SQL CREATE FOREIGN DATA WRAPPER), если необходимо, чтобы параметры были постоянными. При изменении обертки внешних данныхoracle_fdw, созданной по умолчанию, любые изменения будут потеряны при сбросе или восстановлении.
Для расширения oracle_fdw используется необязательный параметр nls_lang.
Когда клиент СУБД Pangolin обращается к внешней таблице базы данных Oracle, oracle_fdw обращается к соответствующим данным во внешней базе данных Oracle через библиотеку интерфейса вызовов Oracle (OCI) на сервере СУБД Pangolin.
Чтобы получить доступ к библиотеке OCI из oracle_fdw, установите переменную окружения NLS_LANG для Oracle в параметр nls_lang. Параметр NLS_LANG находится в форме language_territory.charset (например, AMERICAN_AMERICA.AL32UTF8). Этот параметр должен соответствовать кодировке базы данных. Если это значение не задано, расширение oracle_fdw автоматически определит правильную кодировку либо выдаст предупреждение, если определить кодировку не удалось.
Параметры сервера - источника внешних данных (foreign server options)
Ниже перечислены параметры для работы с внешним сервером (foreign server):
-
dbserver(обязательный параметр) – строка подключения к сторонней БД Oracle может быть в любой из форм, поддерживаемых Oracle.Например:
CREATE SERVER ora_test FOREIGN DATA WRAPPER oracle_fdw
OPTIONS (dbserver 'host_ora:1521/EPXDB01');
CREATE SERVERгде:
host_ora:1521– имя:номер порта сервера Oracle;EPXDB01– имя сервера базы данных.
Для локальных подключений в значение параметра
dbserverустановите пустую строку (протоколBEQUEATH). -
isolation_level(необязательно) – уровень изоляции транзакций используемый в БД Oracle. Допустимые значенияserializable(по умолчанию),read_committedилиread_only.Примечание:
Обратите внимание, что таблица Oracle может быть запрошена более одного раза во время одной транзакции СУБД Pangolin (например, во время объединения (
JOIN) таблиц). Чтобы убедиться, что не может возникнуть несоответствий, вызванных конкурентными транзакциями, уровень изоляции транзакций должен гарантировать стабильность чтения. Это возможно только с помощью уровней изоляции OracleSERIALIZABLEилиREAD ONLY.Реализация наиболее строгого уровня изоляции
SERIALIZABLEв Oracle довольно нестабильна и вызывает ошибки сериализации ORA-08177 в неожиданных ситуациях, например, вставки в таблицу. ИспользованиеREAD COMMITTEDпозволяет обойти эту проблему, но существует риск возникновения несоответствий. В случае его использования рекомендуем узнать, может ли внешнее сканирование выполняться более одного раза. Для этого нужно проверить планы выполнения запросов (EXPLAIN). -
nchar(boolean, необязательно, значение по умолчаниюoff):- Установка этого параметра в значение
onпозволяет выбрать более дорогостоящее преобразование символов на стороне Oracle. Это необходимо, если используется однобайтовый набор символов базы данных Oracle, но при этом присутствуют столбцыNCHARилиNVARCHAR2, содержащие символы, которые не могут быть представлены в наборе символов базы данных. - Установка
ncharвonоказывает заметное влияние на производительность и вызывает ошибки ORA-01461 с операторамиUPDATE, которые устанавливают строки более 2000 байт (или 16383, еслиMAX_STRING_SIZE = EXTENDED). Эта ошибка, по-видимому, является ошибкой Oracle.
- Установка этого параметра в значение
Параметры прав доступа (USER MAPPING)
user(обязательно). Имя пользователя Oracle для подключения.password(необязательно). Пароль пользователя Oracle для подключения. В СУБД Pangolin возможно использование засекреченного хранилища паролей (утилитаpg_auth_config). Если пароль не задан в параметреpassword, он будет взят из хранилища паролей по соответствию имени хоста, порта и имени БД из строки подключения, указанной в используемомforeign server.
Параметры внешней таблицы (FOREIGN TABLE)
-
table(обязательно):Имя таблицы Oracle. Должно быть написано точно так же, как оно было сохранено в системном каталоге Oracle. Как правило, имя содержит только символы в верхнем регистре.
Чтобы определить внешнюю таблицу на основе произвольного запроса Oracle, установите этот параметр для запроса, заключенного в круглые скобки, например:
OPTIONS (table '(SELECT col FROM tab WHERE val = ''string'')')Параметр
schemaв данном случае указывать не нужно.Инструкции
INSERT,UPDATEиDELETEбудут работать со сторонней таблицей, основанной на таких запросах, если необходимо избежать этого (или путаницы с сообщениями об ошибках Oracle для более сложных запросов), используйте опциюreadonly. -
dblink(необязательно):Oracle database link, через который доступна таблица. Должно быть написано точно так же, как оно было сохранено в системном каталоге Oracle. Как правило, оно содержит только символы в верхнем регистре. -
schema(необязательно):Схема с таблицей (или владелец). Полезно для доступа к таблицам, которые не принадлежат подключающемуся пользователю Oracle. Название схемы должно быть написано точно так же, как оно было сохранено в системном каталоге Oracle. Как правило, оно содержит только символы в верхнем регистре.
-
max_long(необязательно, значение по умолчанию «32767»):Максимальный размер полей с типом
LONG,LONG RAWиXMLTYPEв таблице Oracle. Возможными значениями являются целые числа от 1 до 1073741823 (максимальный размерbyteaв PostgreSQL). Этот объем памяти будет выделен как минимум дважды, поэтому большие значения будут занимать много памяти. Еслиmax_longменьше размера самого большого из полученных значений, будет получена ошибкаORA-01406: fetched column value was truncated. -
readonly(необязательно, значение по умолчанию«false»):Операции
INSERT,UPDATEиDELETEдоступны только для таблиц, где данный параметр не равенyes/on/true. -
sample_percent(необязательно, значение по умолчанию «100»):Данный параметр влияет только на выполнение операции
ANALYZEи может пригодиться для выполненияANALYZEочень больших таблиц за разумное время. Значение должно быть в диапазоне от 0,000001 до 100, оно определяет процент блоков таблицы Oracle, которые будут выбраны случайным образом для вычисления статистики таблицы базы данных Pangolin. Это достигается с помощью выраженияSAMPLE BLOCK(x)в Oracle. ПостроениеANALYZEзавершится с ошибкойORA-00933для таблиц, определенных с помощью запросов Oracle, и может завершиться с ошибкойORA-01446для таблиц, определенных со сложными представлениями (view) Oracle. -
prefetch(необязательно, значение по умолчанию «200»):Задает количество строк, которые будут извлечены с помощью одного кругового перехода между СУБД Pangolin и Oracle во время сканирования внешней таблицы. Реализовано с помощью предварительной выборки строк Oracle. Значение должно находиться в диапазоне от 0 до 10240, где нулевое значение отключает предварительную выборку. По умолчанию строки выбираются порциями по 200 штук. Высокие значения могут повысить производительность, но будут использовать больше памяти сервера СУБД Pangolin.
Примечание:
Если запрос Oracle включает столбец
BLOB,CLOBилиBFILE, предварительная выборка строк не будет работать (ограничения Oracle). Как следствие, запросы к таким столбцам во внешней таблице будут выполняться долго при извлечении большого количества строк.
Параметры полей
-
key(необязательно, значение по умолчанию«false»):Если значение равно
yes/on/true, соответствующее поле в таблице Oracle является первичным ключом. Чтобы работали операцииUPDATEиDELETE, установите этот параметр для всех столбцов, относящихся к первичному ключу таблицы. -
strip_zeros(необязательно, значение по умолчанию"false"):Если значение равно
yes/on/true,ASCII 0символы будут удалены из строки перед передачей. Такие символы допустимы в Oracle, но не в PostgreSQL, поэтому они вызовут ошибку при чтенииoracle_fdw. Данная опция актуальна только для типовcharacter, character varyingиtext.
Использование расширения oracle_fdw
Привилегии Oracle
Учетная запись в Oracle должна иметь привилегию CREATE SESSION и права на чтение таблиц или представлений в запросе.
Для выполнения EXPLAIN VERBOSE пользователь также должен обладать привилегией SELECT на представлениях V$SQL и V$SQL_PLAN.
Подключение к внешней БД
Расширение oracle_fdw кеширует соединения Oracle, поскольку создание сеанса Oracle для каждого отдельного запроса обходится дорого. Все соединения автоматически закрываются по окончании сеанса со стороны СУБД Pangolin.
Функция oracle_close_connections() может быть использована для закрытия кешированных соединений Oracle. Это может быть полезно для длительных сеансов, которые не обращаются к внешним таблицам постоянно и хотят избежать блокировки ресурсов, необходимых для открытых подключений к Oracle. Нельзя вызвать эту функцию внутри транзакции, которая модифицирует данные в Oracle.
Поля и столбцы внешних таблиц
При определении внешней таблицы, столбцы таблицы базы данных Oracle сопоставляются столбцам СУБД Pangolin в порядке, в котором они указаны.
Расширение oracle_fdw будет включать в запрос Oracle только те столбцы, которые действительно необходимы для запроса СУБД Pangolin.
Таблица СУБД Pangolin может содержать больше или меньше столбцов, чем таблица базы данных Oracle. Если в ней больше столбцов, и эти столбцы используются, появится предупреждение и будут возвращены значения NULL.
Если необходимо выполнить операцию UPDATE или DELETE, убедитесь, что параметр key установлен для всех столбцов, принадлежащих первичному ключу таблицы. Невыполнение этого требования приведет к ошибкам.
Типы данных
Необходимо определить столбцы таблиц СУБД Pаngolin с типами данных, которые может преобразовать oracle_fdw (см. таблицу преобразования ниже). Это ограничение применяется только в том случае, если столбец действительно используется, поэтому можно определять «фиктивные» столбцы для непереводимых типов данных до тех пор, пока к ним не будет получен доступ (этот трюк работает только с SELECT, а не при изменении внешних данных). Если значение из Oracle превышает размер столбца СУБД Pаngolin (например, длину столбца varchar или максимальное целочисленное значение), будет выведено сообщение об ошибке во время выполнения.
Данные преобразования типов автоматически выполняются расширением oracle_fdw:
| Oracle type | Possible PostgreSQL types |
|---|---|
| CHAR | char, varchar, text |
| NCHAR | char, varchar, text |
| VARCHAR | char, varchar, text |
| VARCHAR2 | char, varchar, text, json |
| NVARCHAR2 | char, varchar, text |
| CLOB | char, varchar, text, json |
| LONG | char, varchar, text |
| RAW | uuid, bytea |
| BLOB | bytea |
| BFILE | bytea (read-only) |
| LONG RAW | bytea |
| NUMBER | numeric, float4, float8, char, varchar, text |
| NUMBER(n,m) with m<=0 | numeric, float4, float8, int2, int4, int8, boolean, char, varchar, text |
| FLOAT | numeric, float4, float8, char, varchar, text |
| BINARY_FLOAT | numeric, float4, float8, char, varchar, text |
| BINARY_DOUBLE | numeric, float4, float8, char, varchar, text |
| DATE | date, timestamp, timestamptz, char, varchar, text |
| TIMESTAMP | date, timestamp, timestamptz, char, varchar, text |
| TIMESTAMP WITH TIME ZONE | date, timestamp, timestamptz, char, varchar, text |
| TIMESTAMP WITH LOCAL TIME ZONE | date, timestamp, timestamptz, char, varchar, text |
| INTERVAL YEAR TO MONTH | interval, char, varchar, text |
| INTERVAL DAY TO SECOND | interval, char, varchar, text |
| XMLTYPE | xml, char, varchar, text |
| MDSYS.SDO_GEOMETRY | geometry (see "PostGIS support" below) |
Если тип NUMBER привести к boolean, тогда "0" превратится в "false", все остальное в "true".
Вставка или обновление XMLTYPE работает только со значениями, которые не превышают максимальную длину типа данных VARCHAR2 (4000 или 32767, в зависимости от параметра MAX_STRING_SIZE).
Тип данных NCLOB в настоящее время не поддерживается, поскольку Oracle не может автоматически преобразовать его в кодировку клиента.
Если нужны преобразования, отличающиеся от вышеуказанных, определите соответствующее представление (view) в Oracle или Pangolin.
Инструкции WHERE и ORDER BY
СУБД Pаngolin будет использовать все применимые части предложения WHERE в качестве фильтра для проверки. Запрос Oracle, который создает oracle_fdw, будет содержать предложение WHERE, соответствующее этим критериям фильтрации, всякий раз, когда такое условие может быть безопасно переведено в Oracle SQL. Эта функция, также известная как выдвижение предложений WHERE, может значительно сократить количество строк, извлекаемых из Oracle, и может позволить оптимизатору Oracle выбрать подходящий план доступа к требуемым таблицам.
Аналогично, предложения ORDER BY будут перенесены в Oracle там, где это возможно. Обратите внимание, что ORDER BY, сортирующее по символьной строке, будет пропущено, поскольку нет гарантий, что порядок сортировки в СУБД Pаngolin и Oracle будет одинаковым.
Для использования попробуйте писать простые условия для внешней таблицы. Выберите типы данных столбцов СУБД Pаngolin, соответствующие типам Oracle, поскольку в противном случае условия не могут быть переведены.
Выражения now(), transaction_timestamp(), current_timestamp, current_date и localtimestamp будут переведены правильно.
В выводе EXPLAIN будет показан используемый запрос Oracle, чтобы была возможность увидеть, какие условия были переведены в Oracle и как.
Объединения (JOIN) между внешними таблицами
Начиная с версии PostgreSQL 9.6 расширение oracle_fdw может передавать инструкцию join на сервер Oracle, то есть join между двумя внешними таблицами приведет к одному запросу Oracle, который выполняет join на стороне Oracle.
Необходимые условия:
- обе таблицы должны относиться к одному внешнему серверу Oracle;
JOINмежду 3 и более таблицами не произойдет;JOINдолжен использоваться в выраженииSELECT;oracle_fdwдолжен быть способен выполнить всеJOINи условияWHERE;- перекрестный
JOINбез условий не будет выполнен; - если выполнен
JOIN,ORDER BYвыполнен не будет.
Важно, чтобы статистика для обеих внешних таблиц была собрана с помощью ANALYZE для определения наилучшей стратегии объединения.
Изменение внешних данных
Расширение oracle_fdw поддерживает операции INSERT, UPDATE и DELETE на внешних таблицах. Данные операции доступны по умолчанию (также и в БД, обновленной с ранних версий PostgreSQL) и могут быть отключены опцией readonly на внешней таблице.
Чтобы операции UPDATE и DELETE работали, столбцы, относящиеся к первичному ключу в таблице Oracle, должны иметь установленную опцию key. Значения данных столбцов используются для идентификации строк внешней таблицы, поэтому убедитесь, что опция установлена на ВСЕХ столбцах, относящихся к первичному ключу.
Если во время вставки один из столбцов внешней таблицы пропущен, этому столбцу присваивается значение, определенное в предложении DEFAULT для внешней таблицы СУБД Pangolin (или NULL, если предложение DEFAULT отсутствует). Предложения DEFAULT в соответствующих столбцах Oracle не используются. Если внешняя таблица СУБД Pangolin не включает все столбцы таблицы Oracle, для столбцов, не включенных в определение внешней таблицы, будут использоваться предложения DEFAULT в Oracle.
Директива RETURNING в операцих INSERT, UPDATE или DELETE поддерживается, кроме столбцов Oracle с типами данных LONG или LONG RAW (сам Oracle не поддерживает данные типы данных в RETURNING).
Триггеры для внешних таблиц поддерживаются, начиная с версии PostgreSQL 9.4. Триггеры, определенные с использованием AFTER и FOR EACH ROW, требуют, чтобы во внешней таблице не было столбцов с типом данных Oracle LONG или LONG RAW. Это происходит потому, что такие триггеры используют предложение RETURN, упомянутое выше.
Во время изменения внешних данных производительность может снижаться, особенно когда затрагивается много строк, потому что (так работают внешние обертки данных) каждая строка должна обрабатываться индивидуально.
Транзакции пересылаются в Oracle, поэтому BEGIN, COMMIT, ROLLBACK и SAVEPOINT работают должным образом. Подготовленные запросы, относящиеся к Oracle, не поддерживаются.
Поскольку oracle_fdw по умолчанию использует сериализованные транзакции, возможно, что запросы на изменение данных приведут к сбою сериализации:
ORA-08177: can't serialize access for this transaction
Это может произойти, если несколько транзакций одновременно изменяют таблицу и вероятность этого возрастает на длинных транзакциях. Такие ошибки могут быть идентифицированы по статусу SQLSTATE(40001). Приложение, использующее oracle_fdw, должно повторить транзакции, которые завершаются с этой ошибкой.
По возможности используйте другие уровни изоляции транзакций (READ COMMITTED или READ ONLY), чтобы избежать данной ошибки.
Планы запросов (EXPLAIN)
Команда EXPLAIN в СУБД Pаngolin покажет запрос, который фактически отправлен в Oracle. EXPLAIN VERBOSE покажет план выполнения Oracle (но это не будет работать с версиями Oracle 9i и ниже).
Сбор статистики (ANALYZE)
Можно использовать ANALYZE для сбора статистики внешней таблицы. oracle_fdw поддерживает такую возможность.
Без статистики СУБД Pаngolin не может оценить количество строк для запросов по внешней таблице, что может привести к выбору неправильных планов выполнения. СУБД Pаngolin не будет автоматически собирать статистику для внешних таблиц с помощью демона AUTOVACUUM, как это делается для обычных таблиц, поэтому особенно важно запускать ANALYZE для внешних таблиц после создания и всякий раз, когда внешняя таблица значительно изменилась.
Примечание
Для внешней таблицы Oracle выполнение
ANALYZEприведет к полному последовательному сканированию таблицы. Для того, чтобы ускорить процесс, можно использовать параметр таблицыsample_percent.
Поддержка геоданных PostGIS
Информация представлена в разделе «Особенности миграции с Oracle» документа «Администрирование функциональностей».
Импорт определения сторонних таблиц (IMPORT FOREIGN SCHEMA)
Расширение oracle_fdw имеет функцию, которая позволяет массово создавать сторонние таблицы. Можно создать внешнюю таблицу, используя CREATE FOREIGN TABLE. При этом необходимо определить каждый столбец в соответствии с его определением на стороне БД Oracle. Это достаточно трудоемко, если количество таблиц велико.
С помощью IMPORT FOREIGN SCHEMA есть возможность создавать сторонние таблицы для каждой из таблиц, определенных в импортированной схеме, с возможностью импорта только некоторых из этих таблиц.
Примечание
Предложение DEFAULT не импортируется, поэтому его необходимо добавить отдельно к столбцам позже.
В дополнение к документации по IMPORT FOREIGN SCHEMA, учитывайте следующее:
-
IMPORT FOREIGN SCHEMAсоздаст внешние таблицы для всех объектов, найденных вALL_TAB_COLUMNS, включая таблицы, представления и материализованные представления, но не синонимы. -
Поддерживаемые параметры для
IMPORT FOREIGN SCHEMA: -
case– управляет регистром имен таблиц и столбцов при импорте; Возможные значения:keep: оставить имена такими как в Oracle, как правило в верхнем регистре.lower: преобразовать имена всех таблиц и столбцов в нижний регистр.smart: преобразовать только имена, записанные полностью в верхнем регистре в Oracle (значение по умолчанию).
-
collation: порядок сортировки, используемый при преобразовании регистра при выборе значенияlowerилиsmartдля параметраcase. По умолчанию используется порядок сортировки используемый в БД. Поддерживаются только значения, которые есть в схемеpg_catalog. Доступные параметры сортировки указаны в таблицеpg_collation, значенияcollname. -
dblink:dblinkна базу данных Oracle, через которую осуществляется доступ к схеме. Имя должно быть написано точно так же, как оно было сохранено в системном каталоге Oracle. Как правило, оно содержит только символы в верхнем регистре. -
readonly: устанавливает опциюreadonlyдля всех импортируемых таблиц(см. описание опций таблиц). -
max_long: устанавливает опциюmax_longдля всех импортируемых таблиц (см. описание опций таблиц). -
sample_percent: устанавливает опциюsample_percentдля всех импортируемых таблиц (см. описание опций таблиц). -
prefetch: устанавливает опциюprefetchдля всех импортируемых таблиц (см. описание опций таблиц). -
Имя схемы должно быть написано точно так же, как оно сохранено в системном каталоге Oracle. Как правило, имя содержит только символы в верхнем регистре. Поскольку PostgreSQL переводит имена в нижний регистр перед обработкой, необходимо обернуть имя схемы двойными кавычками (например,
"SCOTT"). -
Имена таблиц в выражениях, использующих
LIMIT TOилиEXCEPT, должны быть написаны так, как они будут отображаться в PostgreSQL после преобразования регистра (см. параметрcase).
Обратите внимание, что IMPORT FOREIGN SCHEMA не работает с СУБД Oracle версии 8i и ниже.
Пример использования
Ниже приведен простейший пример использования расширения oracle_fdw. Более детальная информация описана в разделах «Параметры» и «Использование расширения oracle_fdw». Пример предполагает, что работа ведется под пользователем ОС postgres и он может подключиться к БД Oracle:
sqlplus orauser/orapwd@//dbserver.mydomain.com:1521/ORADB
Проверка подключения к БД необходима, чтобы убедиться, что Oracle клиент и окружение настроены корректно и все работает правильно. Кроме этого необходимо, чтобы расширение oracle_fdw присутствовало в инсталляции Pangolin (убедитесь, что версия Pangolin используется не ниже 4.5.0).
Предположим, что необходимо получить доступ к таблице Oracle, которая имеет вид:
SQL> DESCRIBE oratab
Name Null? Type
------------------------------- -------- ------------
ID NOT NULL NUMBER(5)
TEXT VARCHAR2(30)
FLOATING NOT NULL NUMBER(7,2)
Для этого:
-
Сконфигурируйте
oracle_fdwпод администратором СУБД Pangolin:CREATE EXTENSION oracle_fdw;
CREATE SERVER oradb FOREIGN DATA WRAPPER oracle_fdw
OPTIONS (dbserver '//dbserver.mydomain.com:1521/ORADB'); -
Выдайте права на использование стороннего сервера пользователю:
GRANT USAGE ON FOREIGN SERVER oradb TO pguser; -
Подключитесь к БД пользователем
pguserи выполните:CREATE USER MAPPING FOR pguser SERVER oradb OPTIONS (user 'orauser'); -
Пароль пользователя Oracle должен быть сохранен в засекреченном хранилище паролей, утилита
pg_auth_config; -
Создайте внешнюю таблицу:
CREATE FOREIGN TABLE oratab (
id integer OPTIONS (key 'true') NOT NULL,
text character varying(30),
floating double precision NOT NULL
) SERVER oradb OPTIONS (schema 'ORAUSER', table 'ORATAB');
Теперь можно обращаться к данной таблице, как к обычной таблице PostgreSQL в СУБД Pangolin.
Функциональность FOREIGN DATA WRAPPER для БД MSSQL
Обертка внешних данных (PostgreSQL foreign data wrapper) может подключаться к базам данных, использующим протокол табличного потока данных (TDS), таким как базы данных Sybase и Microsoft SQL server. Обертки внешних данных позволяют работать с таблицами из внешних БД как с собственными.
Для этой обертки требуется библиотека, реализующая интерфейс DB-Library, например FreeTDS.
Обертка работает с версиями PostgreSQL старше 9.2.
Установка
Расширение появилось в дистрибутиве Pangolin, начиная с версии 4.4.0. Для его использования версия Pangolin должна быть не ниже, в противном случае требуется обновить СУБД.
Для корректной работы расширения в системе должен быть установлен драйвер freetds версии не ниже 1.1.20 (необходимо включить репозиторий EPEL в /etc/yum.repos.d/mirror.repo):
sudo yum install freetds
Расширение доработано под использование pg_auth_config. Необходимо добавить параметры подключения к БД MSSQL и пароль при помощи утилиты:
pg_auth_config add --host <ip_address_mssql> --port <mssql_port> --user <mssql_user> --database <mssql_database>
После того как все подготовительные действия выполнены, создайте и настройте расширение в БД:
--Создать расширение в схеме ext
set role db_admin;
create extension tds_fdw schema ext;
--Дать права на использование расширения роли as_admin
GRANT USAGE ON FOREIGN DATA WRAPPER tds_fdw TO as_admin;
Использование
Права на создание внешних таблиц и подключений должны быть у роли as_admin, для этого данной роли при создании расширения выдается право USAGE на foreign data wrapper. Далее роль as_admin самостоятельно создает user mapping, foreign server и foreign tables. Доступы к сторонним таблицам разграничиваются на стороне стороннего сервера, хранящего эти объекты (в данном случае БД MSSQL), поэтому пользователь, добавленный в user mapping должен иметь минимально необходимый для работы набор привилегий в соответствии с утвержденной ролевой моделью MSSQL. Для работы приложения роль as_admin может выдать право USAGE на foreign server для роли as_TUZ.
Foreign server
Возможные параметры foreign server:
servername(обязательный, значение по умолчанию:127.0.0.1) – имя сервера, IP-адрес или fqdn внешнего сервера. Это может быть имя источника данных (DSN), указанное в файлеfreetds.conf(см. FreeTDS name lookup). Можно передать в этой опции список серверов, разделенных запятой, где серверы будут последовательно перебираться до первого успешного подключения. Это используется для автоматического fail-over на второй сервер;port(необязательный) – порт стороннего сервера. Параметр опциональный, может быть указан здесь или в файлеfreetds.conf(при условии, чтоservernameэто DSN);database(необязательный) – внешняя база данных для подключения;dbuse(необязательный, значение по умолчанию:0) – данная опция говоритtds_fdwподключаться напрямую к БД, если параметрdbuse = 0. Еслиdbuseне равен0,tds_fdwбудет подключаться к БД по умолчанию, после чего выберет БД вызовом функцииdbuse()из библиотеки DB-Library;language(необязательный) – язык, используемый в сообщениях, и локаль, применяемая для форматирования дат. FreeTDS по умолчанию используетus_englishна многих системах. Язык можно задать в файлеfreetds.conf.character_set(необязательный) – клиентский набор символов, используемый для подключения, если нужно устанавливать его по какой-то причине. Для протокола TDS версии 7.0+, подключение использует UCS-2, данный параметр не нужно менять в большинстве случаев. См. Localization and TDS 7.0;tds_version(необязательный) – версия протокола TDS используемого для данного сервера. См. Choosing a TDS protocol version и History of TDS Versions;msg_handler(необязательный, значение по умолчанию:blackhole) – функция обработчика сообщений TDS. Может бытьnoticeилиblackhole. При значенииnotice, сообщения от TDS будут переданы в сообщения PostgreSQL. При значенииblackholeсообщения TDS будут игнорироваться;fdw_startup_cost(необязательный) – стоимость представления накладных расходов на использование FDW. Используется при планировании запросов;fdw_tuple_cost(необязательный) – стоимость представления накладных расходов на выборку строк с сервера. Используется при планировании запросов.
Некоторые параметры внешней таблицы, допустимые в определении сервера, могут также быть установлены на уровне сервера:
use_remote_estimate;row_estimate_method.
Пример:
CREATE SERVER mssql_svr
FOREIGN DATA WRAPPER tds_fdw
OPTIONS (servername '127.0.0.1', port '1433', database 'tds_fdw_test', tds_version '7.1');
Foreign table
Допустимые параметры foreign table:
-
query(обязательный, если не указан параметрtable_name) – не может быть указан одновременно с параметромtable_name. Строка запроса, формирующая внешнюю таблицу; -
schema_name(необязательный) – имя схемы, содержащей внешнюю таблицу. Имя схемы может быть так же включено вtable_name; -
table_name(обязательный, если не указан параметрquery) – имя внешней таблицы. Сокращенный вариант –table. Не может быть указан одновременно с параметромquery; -
match_column_names(необязательный) – определяет, следует ли сопоставлять локальные столбцы с удаленными столбцами путем сравнения их имен или использовать порядок их отображения в результирующем наборе; -
use_remote_estimate(необязательный) – параметр, определяющий оценивается ли размер таблицы при выполнении операции на удаленном сервере (как определеноrow_estimate_method), или в соответствии сlocal_tuple_estimateиспользуется локальная оценка; -
local_tuple_estimate(необязательный) – локально установленная оценка количества кортежей, которая используется, когда параметрuse_remote_estimateвыключен; -
row_estimate_method(необязательный, значение по умолчанию:execute). Может принимать одно из следующих значений:execute– выполнить запрос на удаленном сервере и получить актуальное количество строк в запросе;showplan_all– получить расчетное количество строк с использованием MS SQL ServerSET SHOWPLAN_ALL.
Допустимые параметры столбцов в foreign table:
column_name(необязательный) – имя столбца на удаленном сервере. Если этот параметр не задан, предполагается, что удаленное имя столбца совпадает с локальным именем столбца. Если дляmatch_column_namesдля таблицы установлено значение0, то имена столбцов не используются, и этот параметр игнорируется.
Пример с использованием table_name:
CREATE FOREIGN TABLE mssql_table (
id integer,
data varchar)
SERVER mssql_svr
OPTIONS (table_name 'dbo.mytable', row_estimate_method 'showplan_all');
С использованием schema_name и table_name:
CREATE FOREIGN TABLE mssql_table (
id integer,
data varchar)
SERVER mssql_svr
OPTIONS (schema_name 'dbo', table_name 'mytable', row_estimate_method 'showplan_all');
С использованием query:
CREATE FOREIGN TABLE mssql_table (
id integer,
data varchar)
SERVER mssql_svr
OPTIONS (query 'SELECT * FROM dbo.mytable', row_estimate_method 'showplan_all');
С использованием column_name:
CREATE FOREIGN TABLE mssql_table (
id integer,
col2 varchar OPTIONS (column_name 'data'))
SERVER mssql_svr
OPTIONS (schema_name 'dbo', table_name 'mytable', row_estimate_method 'showplan_all');
User mapping
Допустимые параметры:
username(обязательный) – логин пользователя на внешнем сервере;password(необязательный) – пароль пользователя на внешнем сервере. Если не указан, будет взят по параметрам сервера из foreign server вpg_auth_config.
Пример:
CREATE USER MAPPING FOR postgres
SERVER mssql_svr
OPTIONS (username 'sa', password '');
Foreign schema
Допустимые параметры:
import_default(необязательный, значение по умолчанию:false) – определяет, включаются ли значенияDEFAULTдля столбцов в определения внешних таблиц;import_not_null(необязательный, значение по умолчанию:true) – определяет, включать ли ограничения столбцаNOT NULLв определения внешних таблиц.
Пример:
IMPORT FOREIGN SCHEMA dbo
EXCEPT (mssql_table)
FROM SERVER mssql_svr
INTO public
OPTIONS (import_default 'true');
Параметры
Допустимые параметры
tds_fdw.show_before_row_memory_stats- выводит статистику контекста памяти в лог PostgreSQL перед извлечением каждой строки;tds_fdw.show_after_row_memory_stats- выводит статистику контекста памяти в лог PostgreSQL после извлечения каждой строки;tds_fdw.show_finished_memory_stats- выводит статистику контекста памяти в лог PostgreSQL после завершения транзакции.
Установка параметров
Для установки параметра используйте команду SET:
postgres=# SET tds_fdw.show_finished_memory_stats=1;
SET
EXPLAIN
EXPLAIN (VERBOSE) – показывает запрос, сформированный в удаленной системе.
Примечание:
В случае работы с данными в Unicode при получении от MS SQL Server ошибки следующего вида:
NOTICE: DB-Library notice: Msg #: 4004, Msg state: 1, Msg: Unicode data in a Unicode-only collation or ntext data cannot be sent to clients using DB-Library (such as ISQL) or ODBC version 3.7 or earlier., Server: PILLIUM\SQLEXPRESS, Process: , Line: 1, Level: 16
ERROR: DB-Library error: DB #: 4004, DB Msg: General SQL Server error: Check messages from the SQL Server, OS #: -1, OS Msg: (null), Level: 16Можно вручную установить параметр
tds versionв файлеfreetds.confв значение 7.0 или выше. См. The freetds.conf File и Choosing a TDS protocol version.
Примечание:
Хотя многие новые версии протокола TDS будут использовать только USC-2 для взаимодействия с сервером, FreeTDS конвертирует UCS-2 в набор символов, выбранных пользователем. Для установки набора, можно задать параметр
client charsetв файлеfreetds.conf. См. The freetds.conf File и Localization and TDS 7.0.Предусмотрено шифрование соединения с MSSQL Server. Данная возможность предоставляется драйвером FreeTDS, поэтому ее необходимо сконфигурировать в файле
freetds.conf. См. The freetds.conf File.
Расширение TimescaleDB
TimescaleDB – это база данных временных рядов с открытым исходным кодом, оптимизированная для быстрой работы с данными и обработки сложных запросов.
TimescaleDB работает на полноценном SQL и, соответственно, проста в использовании, как традиционная реляционная база данных, но масштабируется так, как раньше могла только NoSQL.
Примечание:
API TimescaleDB по управлению гипертаблицами приведен в документе «Список PL/SQL функций продукта», раздел «TimescaleDB. Управление гипертаблицами» (документ доступен в личном кабинете).
При выборе между реляционным подходом и NoSQL приходится идти на компромиссы, тогда как TimescaleDB предлагает преимущества обоих подходов:
-
Простота использования:
- Предоставляется полноценный интерфейс SQL для всех элементов, изначально поддерживаемых PostgreSQL (включая вторичные индексы, вложенные запросы, объединения, оконные функции, а также агрегатные функции, не основанные на времени).
- Возможно подключение к любому клиенту, который работает с PostgreSQL, никаких изменений не требуется.
- Учитываются ориентированные на время особенности, предоставляются функции API и средства оптимизации.
- Осуществляется поддержка политик хранения данных.
-
Масштабируемость:
- Данные прозрачно сегментируются по пространству и времени для масштабирования в высоту (один узел) и в ширину (в разработке).
- Запись данных производится на высокой скорости (включая пакетные коммиты, индексы в памяти, транзакционную поддержку, поддержку наполнения исторических данных).
- Осуществляется подбор оптимального размера блоков (двумерных разделов данных), который на отдельных узлах обеспечивает быструю запись и обработку даже больших объемов данных.
- Производится распараллеливание операций между блоками и серверами.
-
Надежность:
- Решение разработано в качестве расширения на базе PostgreSQL.
- Гибкие настройки управления (совместимость с существующей экосистемой и инструментарием PostgreSQL).
Более подробно c преимуществами и архитектурой расширения можно ознакомиться в одноименном разделе расширения TimescaleDB документа «Описание расширений продукта СУБД Pangolin».
Официальная документация поставляемого модуля: https://docs.timescale.com/
Индекс RUM
Индексный метод доступа RUM является одним из инструментов оптимизации доступа к данным. RUM основан на GIN-подобном индексном методе и, кроме того, включает дополнительную методику оценки релевантности результата поиска («дистанцией»).
Функциональность поставляется в качестве расширения в составе продукта, не требует специальных шагов по настройке со стороны сотрудников сопровождения. Активация расширения не требует изменения параметров конфигурации БД.
Установка расширения производится в выбранной БД следующим способом:
SET ROLE db_admin;
CREATE EXTENSION IF NOT EXISTS rum WITH SCHEMA ext;
RESET ROLE;
RUM имеет качественное преимущество в возможности ранжирования результатов поиска по «дистанции»/«схожести». При этом «дистанция»/«схожесть» имеют другой алгоритм обработки, чем существующие функции ts_rank, ts_rank_cd.
Для незначительного уменьшения размера индекса можно использовать классы операторов hash, если не предполагается префиксного поиска.
RUM имеет количественное преимущество перед существующими индексными методами только при соблюдении следующих условий:
- Запрос SQL должен иметь условие поиска по дистанции. В случае FTS -
tsqueryдолжен использовать оператор дистанции«<=>»,«<2>»,«<3>»и тому подобные. - Запрос SQL, содержащий условие поиска по дистанции, должен оперировать термами низкой или средней селективности (при возможности их оценки).
В иных случаях предпочтительнее использовать другие индексы.
Отключение функциональности
Отключение расширения влечет за собой удаление всех ранее созданных индексов RUM, дальнейшую невозможность использовать классы операторов, операторы и функции, добавленные расширением. Отключение функциональности требует прав db_admin.
Удаление расширения производится следующим способом:
SET ROLE db_admin;
DROP EXTENSION IF EXISTS rum CASCADE;
RESET ROLE;
Пересоздание хоста арбитра
Полностью утерян хост арбитра. Необходимо восстановить только сбойный хост, а не весь кластер целиком. Для восстановления потребуется полностью новая виртуальная машина.
Процедура инициализации
Для наглядности приведенных ниже действий и их последовательности в описываемой процедуре приводятся примеры команд. Допускается выполнение данных действий какими-либо другими средствами или командами, более удобными с точки зрения пользователя.
Обозначение параметров
В примерах команд далее используются параметры для обозначения имен хостов вместо действительных значений:
-
узел мастера:
\{{ master_host }}и\{{ master_ip }}; -
узел реплики:
\{{ replica_host }}и\{{ replica_ip }}; -
узел арбитра:
\{{ arbiter_host }}и\{{ arbiter_ip }}; -
узел арбитра в сокращенной форме, используемый в etcd-командах:
\{{ arbiter_etcd_host }}; -
суперпользователь:
\{{ USER }}; -
директория с сертификатами обозначается параметром:
\{{ pg_ssl }}.Например,
pg_sslилиhome/postgres/sslИмя директории с сертификатами следует выбрать так же, как на мастере.
Примечание:
В случае необходимости конфигурации дополнительных компонентов, таких как RSYSLOG или SRC, следует обращаться к соответствующим материалам.
Подготовительные действия
Для выполнения процедуры предполагается наличие новой виртуальной машины, на которой будет производиться инсталляция. Параметры виртуальной машины должны соответствовать сохранившимся хостам кластера Pangolin. Процедура может быть использована для различных версий Pangolin: 4.x.x - 6.x.x. Однако, следует учитывать тот факт, что примеры команд и набор необходимых действий приводятся для версий Pangolin 5.1.0-5.2.0 и операционной системы Red Hat Enterprise Linux Server release 7.9. В других версиях могут отличаться имена файлов, директорий, набор компонентов, особенности конфигурации, влияющие на выбор того или иного формата команд, и др.
Настройка репозиториев yum
Действие выполняется на арбитре.
Для настройки репозиториев yum перенесите содержимое с аналогичных файлов на узле мастера или скопируйте сами файлы на узел арбитра и дайте такие же права:
sudo su - {{ USER }}
sudo vi /etc/yum.repos.d/D10.repo
sudo vi /etc/yum.repos.d/mirror.repo
sudo vi /etc/yum.repos.d/redhat.repo
Установка пакетов
Действие выполняется на арбитре.
Для дальнейшей работы требуется установить ряд необходимых пакетов.
Заполните вспомогательный файл prereq.txt:
sudo su - {{ USER }}
vi /home/{{ USER }}/prereq.txt
Файл prereq.txt должен содержать следующий список пакетов:
openssl
rsync
sshpass
python3-pip
python36
python36-devel
python36-virtualenv
rsyslog
postgresql-libs
Выполните установку пакетов как в следующем примере:
sudo su - {{ USER }}
sudo yum install $(cat /home/{{ USER }}/prereq.txt)
Создание пользователя postgres
Действие выполняется на арбитре.
Создайте пользователя postgres, если он отсутствует на узле арбитра:
sudo su - {{ USER }}
sudo useradd -m -G postgres postgres
Заполните /home/postgres/.bash_profile:
- перенесите содержимое с мастера;
- удалите все записи после строки
PATH=$PATH:$HOME/.local/bin:$HOME/bin; - добавьте следующие записи в конец полученного файла:
export PATH
export CLNAME=clustername
export CLNAME=KSG
sudo su - {{ USER }}
sudo vi /home/postgres/.bash_profile
sudo chown postgres:postgres /home/postgres/.bash_profile
sudo chmod 700 /home/postgres/.bash_profile
Генерация сертификатов
Перенесите root-сертификат с узла мастера на арбитр и сгенерируйте серверный сертификат на арбитре для того, чтобы все сертификаты кластера были подписаны одним root-сертификатом.
Создание директории с сертификатами
Действие выполняется на арбитре.
Создайте директорию с сертификатами на хосте арбитра:
sudo su - {{ USER }}
sudo rm -rf /{{ pg_ssl }}/
sudo mkdir -p /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/
sudo chmod 0755 /{{ pg_ssl }}/
Копирование root во временную директорию на мастере
Действие выполняется на мастере.
Скопируйте root во временную директорию на мастере:
sudo su - {{ USER }}
mkdir /tmp/{{ pg_ssl }}
sudo cp /{{ pg_ssl }}/root.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/root.crt /tmp/{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.crt
Перенос сертификатов на арбитр
Действие выполняется на арбитре.
Перенесите сертификаты на арбитр:
sudo su - {{ USER }}
sudo scp -r {{ USER }}@{{ master_ip }}:/tmp/{{ pg_ssl }}/* /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/root.key
sudo chown postgres:postgres /{{ pg_ssl }}/root.crt
sudo chmod 644 /{{ pg_ssl }}/root.crt
sudo chmod 600 /{{ pg_ssl }}/root.key
Удаление временной директории на мастере
Действие выполняется на мастере.
Удалите временную директорию на мастере:
sudo su - {{ USER }}
rm -rf /tmp/{{ pg_ssl }}
Генерация серверного сертификата
Действие выполняется на арбитре.
Заполните конфигурационный файл server.cnf подставьте актуальное имя хоста и IP-адрес в разделе [alt_names]:
sudo su - {{ USER }}
vi /{{ pg_ssl }}/server.cnf
Содержимое файла server.cnf:
[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[ssl_client]
extendedKeyUsage = clientAuth, serverAuth
basicConstraints = CA:FALSE
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
subjectAltName = @alt_names
[v3_ca]
basicConstraints = CA:TRUE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
authorityKeyIdentifier=keyid:always,issuer
[alt_names]
DNS = {{ arbiter_host }}
IP = {{ arbiter_ip }}
Сгенерируйте серверный сертификат, подписывая его с помощью root:
sudo su - {{ USER }}
openssl req -new -nodes -text -out /{{ pg_ssl }}/server.csr -keyout /{{ pg_ssl }}/server.key -config /{{ pg_ssl }}/server.cnf -subj "/CN={{ arbiter_host }}"
openssl x509 -req -in /{{ pg_ssl }}/server.csr -text -days 365 -CA /{{ pg_ssl }}/root.crt -CAkey /{{ pg_ssl }}/root.key -CAcreateserial -extfile /{{ pg_ssl }}/server.cnf -extensions ssl_client -out /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.key
sudo chmod 644 /{{ pg_ssl }}/server.crt
sudo chmod 600 /{{ pg_ssl }}/server.key
sudo cp /{{ pg_ssl }}/root.crt /etc/pki/ca-trust/source/anchors/ && sudo update-ca-trust
Настройка прав sudo
Действие выполняется на арбитре.
Добавьте общие правила в /etc/sudoers (специфичные только для хоста арбитра):
sudo su - {{ USER }}
sudo visudo --file /etc/sudoers
Содержимое sudoers, необходимое для хоста арбитра
postgres ALL=(ALL) NOPASSWD: /usr/bin/systemctl daemon-reload, /usr/bin/systemctl stop etcd, /usr/bin/systemctl start etcd, /usr/bin/systemctl restart etcd, /usr/bin/systemctl status etcd, /usr/bin/systemctl status etcd -l, /usr/bin/systemctl status etcd --no-pager --full, /usr/bin/systemctl enable etcd, /usr/bin/systemctl disable etcd, /bin/journalctl -u etcd
Перевод Pangolin Manager в режим паузы
Действие выполняется на мастере.
Переведите Pangolin Manager в режим паузы:
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml pause
Установка etcd
Предварительная очистка
Действие выполняется на арбитре.
Опционально можно выполнить очистку хоста от предыдущих инсталляций, если это необходимо. Если виртуальная машина новая, то выполнять данное действие нет необходимости.
sudo su - {{ USER }}
sudo systemctl stop etcd
sudo yum remove etcd -y
sudo rm -rf /var/lib/etcd
sudo rm -rf /etc/etcd
sudo rm /etc/systemd/system/etcd.service
sudo rm /usr/lib/systemd/system/etcd.service
Конфигурирование файла службы
Действие выполняется на арбитре.
Заполните файл службы. Информацию перенесите из аналогичного файла на узле мастере.
sudo su - {{ USER }}
sudo vi /usr/lib/systemd/system/etcd.service
sudo chown postgres:postgres /usr/lib/systemd/system/etcd.service
sudo chmod 640 /usr/lib/systemd/system/etcd.service
Установка etcd
Действие выполняется на арбитре.
Выполните установку etcd. Версия etcd должна совпадать с версией, установленной на мастере.
sudo su - {{ USER }}
sudo yum install etcd-3.3.11
Конфигурирование etcd
Действие выполняется на арбитре.
Заполните конфигурационный файл etcd. Содержимое файла перенесите с узла мастера и откорректируйте значения следующих параметров для работы на хосте арбитра:
- ETCD_NAME
- ETCD_ADVERTISE_CLIENT_URLS
- ETCD_INITIAL_ADVERTISE_PEER_URLS
sudo su - {{ USER }}
sudo mkdir -p /etc/etcd
sudo chown postgres:postgres /etc/etcd
sudo chmod 700 /etc/etcd
sudo vi /etc/etcd/etcd.conf
sudo chown postgres:postgres /etc/etcd/etcd.conf
sudo chmod 700 /etc/etcd/etcd.conf
Создание рабочей директории
Действие выполняется на арбитре.
Создайте рабочую директорию etcd:
sudo mkdir -p /var/lib/etcd
sudo chown postgres:postgres /var/lib/etcd
sudo chmod 700 /var/lib/etcd
Настройка .bash_profile пользователя postgres
Действие выполняется на арбитре.
Найдите в файле .bash_profile на хосте мастера 4 строки с префиксом: alias members, alias elist, alias elog, alias health и добавьте их в конец аналогичного файла на арбитре. Откорректируйте имена хостов и IP-адреса на значения, соответствующие хосту арбитра:
sudo su - {{ USER }}
sudo vi /home/postgres/.bash_profile
Процедура 1. Мягкий способ без замены всех узлов
Внимание:
Процедура 1 применяется в следующих случаях:
- в etcd не включена аутентификация (до версии Pangolin v.5.x.x);
- известен пароль etcd-пользователя root.
В противном случае переходим к Процедуре 2 (см. подраздел «Процедура 2. Способ с полной заменой всех узлов»), где производится полная замена всех узлов.
В соответствии с Процедурой 1 потерянный узел кластера удаляется и взамен него добавляется новый. Остановка всего кластера etcd не выполняется. При этом все настройки кластера, включая аутентификационные (если они есть), перенесутся на новый узел etcd. Таким образом, Процедура 1 предлагает более «мягкий» вариант конфигурирования кластера etcd после потери одного из узлов.
Особенности использования Процедуры 1 на реплике:
Процедура 1 может также использоваться для пересоздания утерянного узла реплики (не арбитра, как в данной статье).
В этом случае на реплике формируется новый (взамен утраченного) конфигурационный файл (Pangolin Manager) postgres.yml, в который вносится пароль служебного пользователя patronietcd, с помощью которого Pangolin Manager подключается к etcd. Пароль этого пользователя записывается в etcd при настройке в нем аутентификации и все еще продолжает храниться на уцелевших узлах etcd.
Однако, если в postgres.yml на мастере этот пароль хранится в засекреченном виде, а сам пароль неизвестен, то нельзя взять пароль из postgres.yml на мастере и записать его в аналогичный файл на реплике. Это связано с тем, что засереченные пароли привязаны к конкретному хосту (там, где производилось засекречивание). Рассекретить пароль нельзя. Поэтому в этом случае дополнительно потребуется сгенерировать новый пароль и заново описать пользователей в etcd (см. подраздел «Процедура 2. Способ с полной заменой всех узлов», подраздел «Настройка аутентификации в etcd»).
Если же помнить пароли пользователей, их засекреченные версии (каждого хоста) или иметь резервную копию файла postgresql.yml утерянного хоста реплики, то при работе с репликой достаточно выполнить только Процедуру 1. Дополнительные действия из подраздела «Настройка аутентификации в etcd» (см. подраздел «Процедура 2. Способ с полной заменой всех узлов») не требуются.
Дополнительная возможность
Существует еще одна альтернатива удалению и добавлению узла etcd-кластера. Это использование команды Pangolin Manager: pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml remove. В этом случае удаляется вся DCS-информация о кластере, включая все узлы. Аутентификационные настройки etcd (и пользователи) сохраняются. Однако в этом случае также встает вопрос необходимости генерации нового пароля patronietcd, если засекреченный ранее на реплике вариант неизвестен.
Первоначальная оценка состояния кластера
Действие выполняется на мастере.
Выполните оценку состояния кластера:
sudo su - postgres
etcdctl cluster-health
Анализ состояния кластера:
Когда все узлы кластера функционируют и аутентификация не включена - можно наблюдать следующий результат:
$ etcdctl cluster-health
member {хеш} is healthy: got healthy result from http://{{ replica_host }}:{Порт}
member {хеш} is healthy: got healthy result from http://{{ arbiter_host }}:{Порт}
member {хеш} is healthy: got healthy result from http://{{ master_host }}:{Порт}
cluster is healthy
Когда узел арбитра не функционирует и аутентификация включена - можно наблюдать следующий результат команды проверки состояния кластера (описание параметра {{ root_pass }} можно найти в подразделе «Настройка аутентификации в etcd» (см. подраздел «Процедура 2. Способ с полной заменой всех узлов»):
$ ETCDCTL_API=3 etcdctl --endpoints={{ master_host }},{{ replica_host }}:2379,{{ arbiter_host }}:{Порт} --cert=/{{ pg_ssl }}/client.crt --key=/{{ pg_ssl }}/client.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' endpoint health
{{ master_host }}:{Порт} is healthy: successfully committed proposal: took = 1.22267ms
{{ replica_host }}:{Порт} is healthy: successfully committed proposal: took = 1.477113ms
{{ arbiter_host }}:{Порт} is unhealthy: failed to connect: rpc error: code = Unavailable desc = grpc: the connection is unavailable
Error: unhealthy cluster
Идентификаторы узлов в случае, когда аутентификация включена, можно получить при помощи следующей команды:
$ ETCDCTL_API=3 etcdctl --endpoints={{ master_host }} --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key member list -w table
+------------------+---------+--------------------+-----------------------------------+-----------------------------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS |
+------------------+---------+--------------------+-----------------------------------+-----------------------------------+
| {ID} | started | {{ master_host }} | https://{{ master_host }}:{Порт} | https://{{ master_host }}:{Порт} |
| {ID} | started | {{ replica_host }} | https://{{ replica_host }}:{Порт} | https://{{ replica_host }}:{Порт} |
| {ID} | started | {{ arbiter_host }} | https://{{ arbiter_host }}:{Порт} | https://{{ arbiter_host }}:{Порт} |
+------------------+---------+--------------------+-----------------------------------+-----------------------------------+
Ошибки, получаемые во время анализа:
Результат (ошибочный) ниже можно наблюдать, если в etcd включена аутентификация, но в команде не указан пользователь root и его пароль. По нему можно оценить, что наблюдаются неявные признаки того, включена или нет аутентификация в etcd. Если пароль неизвестен, см. Процедуру 2 (см. подраздел «Процедура 2. Способ с полной заменой всех узлов»).
Данный результат приведен для примера - на практике могут быть получены и другие варианты:
$ etcdctl cluster-health
cluster may be unhealthy: failed to list members
Error: client: etcd cluster is unavailable or misconfigured; error #0: net/http: HTTP/1.x transport connection broken: malformed HTTP response "\x15\x03\x01\x00\x02\x02"
; error #1: dial tcp {IP-адрес}:{Порт}: connect: connection refused
error #0: net/http: HTTP/1.x transport connection broken: malformed HTTP response "\x15\x03\x01\x00\x02\x02"
error #1: dial tcp {IP-адрес}:{Порт}: connect: connection refused
Удаление потерянного хоста арбитра
Действие выполняется на мастере.
Удалите из кластера хост арбитра, как в следующем примере. Если он существовал ранее и был утерян - информация о нем будет отображаться в результате команды cluster-health или member list.
В данном примере узел относится к узлу арбитра ('{{ arbiter_host }}') и аутентификация не включена:
sudo su - postgres
$ etcdctl member remove {хеш}
Removed member {хеш} from cluster
В данном примере приведен вариант команды и результат в случае, когда аутентификация включена:
sudo su - postgres
$ ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:{Порт},{{ replica_host }}:{Порт},{{ arbiter_host }}:{Порт} --cert=/{{ pg_ssl }}/client.crt --key=/{{ pg_ssl }}/client.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' member remove {хеш}
Member {хеш} removed from cluster {хеш}
Добавление нового хоста арбитра
Действие выполняется на мастере.
Добавьте новый узел кластера etcd. В команде указывается хост арбитра и порт.
В данном примере приводится вариант команды и результат, когда аутентификация не включена:
sudo su - postgres
$ etcdctl member add {{ arbiter_etcd_host }} https://{{ arbiter_host }}:{Порт}
Added member named {{ arbiter_etcd_host }} with ID {ID} to cluster
В данном примере приводится результат команды и результат, когда аутентификация включена:
sudo su - postgres
$ ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:{Порт},{{ replica_host }}:{Порт},{{ arbiter_host }}:{Порт} --cert=/{{ pg_ssl }}/client.crt --key=/{{ pg_ssl }}/client.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' member add {{ arbiter_etcd_host }} --peer-urls=https://{{ arbiter_host }}:{Порт}
Member {хеш} added to cluster {хеш}
...
Корректировка настроек etcd перед стартом
Действие выполняется на арбитре.
В конфигурационном файле на узле арбитра установите параметр ETCD_INITIAL_CLUSTER_STATE в значение "existing":
Внимание:
Старт etcd на хосте арбитра без параметра
ETCD_INITIAL_CLUSTER_STATE="existing"не будет успешным.
sudo su - {{ USER }}
sudo vi /etc/etcd/etcd.conf
Старт etcd на хосте арбитра
Действие выполняется на арбитре.
Запустите службу etcd на узле арбитра:
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start etcd
sudo systemctl status etcd
sudo etcdctl cluster-health
Корректировка настроек etcd после старта
Действие выполняется на арбитре.
В конфигурационном файле на узле арбитра установите параметр ETCD_INITIAL_CLUSTER_STATE в значение "new". Затем произведите рестарт службы:
sudo su - {{ USER }}
sudo vi /etc/etcd/etcd.conf
sudo systemctl restart etcd
Процедура 2. Способ с полной заменой всех узлов
Внимание:
Процедура 2 выполняется, если не были выполнены шаги Процедуры 1 (см. подраздел «Процедура 1. Мягкий способ без замены всех узлов»), то есть в случае, когда в etcd включена аутентификация и неизвестен etcd-пароль
root.Пункт 2.8.3 может выполняться независимо от выбора Процедуры в случае, если возникает необходимость переописать в etcd параметры аутентификации.
Пересоздание рабочих директорий
Действие выполняется на всех узлах.
Остановите службу etcd:
sudo su - {{ USER }}
sudo systemctl stop etcd
Пересоздайте рабочие директории etcd на каждом узле (они будут заполнены впоследствии автоматически во время первого старта):
sudo su - {{ USER }}
sudo rm -rf /var/lib/etcd
sudo mkdir -p /var/lib/etcd
sudo chown postgres:postgres /var/lib/etcd
sudo chmod 700 /var/lib/etcd
Старт etcd-кластера
Действие выполняется на всех узлах.
Запустите службу etcd:
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start etcd
Настройка аутентификации в etcd
Действие выполняется на мастере.
Опишите пользователей в etcd и включите аутентификацию:
Примечание:
Пользователь
rootявляется техническим и используется только во время данного конфигурирования. Его возможно запомнить и использовать в дальнейшем, но по умолчанию он не используется после инсталляции.Пароль можно сгенерировать с помощью команды:
openssl rand -base64 24.В примере в качестве пароля
rootиспользован параметр: {{ root_pass }}.Пароль пользователя
patronietcdможно сгенерировать с помощью команды:openssl rand -base64 24.В примере в качестве пароля
patronietcdиспользован параметр: {{ patronietcd_pass }}.Затем пароль надо засекретить (на хосте мастера и реплики), чтобы впоследствии поместить в
postgres.yml. Команда, используемая для засекречивания, запрашивает пароль и выдает его засекреченный вид:/opt/pangolin-auth-password/bin/pg_auth_password enc -t.
sudo su - postgres
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' role add patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt role grant-permission patroni readwrite --prefix=true /service/
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user grant-role patronietcd patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role add patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt role grant patroni -path '/service/*' -readwrite
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' user grant patronietcd -roles patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role revoke guest -path '/*' --readwrite
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key member list -w table
ETCDCTL_API=3 etcdctl --endpoints={{ replica_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user list
Корректировка паролей в Pangolin Manager
Действие выполняется на мастере и реплике.
Так как в пункте 2.8.3 поменялся пароль пользователя patronietcd, необходимо обновить его в конфигурационных файлах Pangolin Manager на мастере и реплике:
Внимание:
Пароль, засекреченный на мастере, должен быть указан в
postgres.ymlна мастере.Пароль, засекреченный на реплике, должен быть указан в
postgres.ymlна реплике.
Заполните новые пароли в postgres.yml:
sudo su - {{ USER }}
sudo vi /etc/pangolin-manager/postgres.yml
Актуализация настроек Pangolin Manager посредством рестарта
Действие выполняется на мастере и реплике.
Актуализируйте новые файлы postgres.yml, содержащие новые пароли patronietcd:
sudo su - core_dev
sudo systemctl restart pangolin-manager
Перевод Pangolin Manager в рабочий режим
Действие выполняется на мастере.
Выведите Pangolin Manager из режима паузы:
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml resume
Пересоздание хоста реплики с использованием средств автоматической инсталляции
Полностью утерян хост реплики. Необходимо восстановить только сбойный хост, а не весь кластер целиком. Для восстановления потребуется полностью новая виртуальная машина.
Процедура инициализации
Для наглядности приведенных ниже действий и их последовательности в описываемой процедуре приводятся примеры команд. Допускается выполнение данных действий какими-либо другими средствами или командами, более удобными с точки зрения пользователя.
Обозначение параметров
В примерах команд далее используются параметры для обозначения имен хостов вместо действительных значений:
-
узел мастера: {{ master_host }} и {{ master_ip }};
-
узел реплики: {{ replica_host }} и {{ replica_ip }};
-
узел арбитра: {{ arbiter_host }} и {{ arbiter_ip }};
-
суперпользователь: {{ USER }}.
Например
core_dev; -
директория с сертификатами: {{ pg_ssl }}.
Например,
pg_sslилиhome/postgres/ssl. Имя директории с сертификатами следует выбрать так же, как на мастере.
Примечание:
В случае необходимости конфигурации дополнительных компонентов, таких как RSYSLOG или SRC, следует обращаться к соответствующим материалам.
Подготовительные действия
Для выполнения процедуры предполагается наличие новой виртуальной машины, на которой будет производиться инсталляция. Параметры виртуальной машины должны соответствовать сохранившимся хостам кластера Pangolin. Процедура может быть использована для различных версий Pangolin: 4.x.x - 6.x.x. Однако, следует учитывать тот факт, что примеры команд и набор необходимых действий приводятся для версий Pangolin 5.1.0-5.2.0 и операционной системы Red Hat Enterprise Linux Server release 7.9. В других версиях могут отличаться имена файлов, директорий, набор компонентов, особенности конфигурации, влияющие на выбор того или иного формата команд, и др.
Перевод Pangolin Manager в режим паузы
Действие выполняется на мастере.
Переведите Pangolin Manager в режим паузы:
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml pause
Установка Pangolin
Действие выполняется на реплике.
Произведите установку Pangolin с помощью автоматических средств (например, Ansible или Jenkins). При установке выберите конфигурацию standalone, соответствующую целевому кластеру и содержащую такой же перечень компонентов Pangolin. Например, вместо cluster-patroni-etcd-pgbouncer следует выбрать standalone-patroni-etcd-pgbouncer. В процессе дальнейшей инициализации данный standalone-узел, установленный автоматически, будет включен в кластер.
Останов служб
Действие выполняется на реплике.
Остановите службы на реплике:
sudo su - {{ USER }}
sudo systemctl stop pangolin-pooler
sudo systemctl stop pangolin-manager
sudo systemctl stop etcd
Генерация сертификатов
В данном разделе выполняется генерация серверного сертификата и перенос клиентских сертификатов с мастера для того, чтобы все сертификаты кластера были подписаны одним root-сертификатом.
Очистка директории с сертификатами
Действие выполняется на реплике.
Удалите все сертификаты на реплике:
sudo su - {{ USER }}
sudo rm -rf /{{ pg_ssl }}/*
Копирование сертификатов во временную директорию на мастере
Действие выполняется на мастере.
Скопируйте root и клиентские сертификаты во временную директорию на мастере:
sudo su - {{ USER }}
mkdir /tmp/{{ pg_ssl }}
sudo cp /{{ pg_ssl }}/root.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/root.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/client.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/client.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/etcd.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/etcd.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patroni.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patroni.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patronietcd.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patronietcd.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/pgbouncer.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/pgbouncer.key /tmp/{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/client.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/client.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/etcd.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/etcd.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patroni.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patroni.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patronietcd.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patronietcd.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/pgbouncer.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/pgbouncer.key
Перенос сертификатов на реплику
Действие выполняется на реплике.
Перенесите сертификаты с мастера на реплику:
sudo su - {{ USER }}
sudo scp -r {{ USER }}@{{ master_ip }}:/tmp/{{ pg_ssl }}/* /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/root.key
sudo chown postgres:postgres /{{ pg_ssl }}/root.crt
sudo chown postgres:postgres /{{ pg_ssl }}/client.crt
sudo chown postgres:postgres /{{ pg_ssl }}/client.key
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/etcd.crt
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/etcd.key
sudo chown postgres:postgres /{{ pg_ssl }}/patroni.crt
sudo chown postgres:postgres /{{ pg_ssl }}/patroni.key
sudo chown postgres:postgres /{{ pg_ssl }}/patronietcd.crt
sudo chown postgres:postgres /{{ pg_ssl }}/patronietcd.key
sudo chown postgres:postgres /{{ pg_ssl }}/pgbouncer.crt
sudo chown postgres:postgres /{{ pg_ssl }}/pgbouncer.key
sudo chmod 644 /{{ pg_ssl }}/root.crt
sudo chmod 600 /{{ pg_ssl }}/root.key
sudo chmod 644 /{{ pg_ssl }}/client.crt
sudo chmod 600 /{{ pg_ssl }}/client.key
sudo chmod 644 /{{ pg_ssl }}/etcd.crt
sudo chmod 600 /{{ pg_ssl }}/etcd.key
sudo chmod 644 /{{ pg_ssl }}/patroni.crt
sudo chmod 600 /{{ pg_ssl }}/patroni.key
sudo chmod 644 /{{ pg_ssl }}/patronietcd.crt
sudo chmod 600 /{{ pg_ssl }}/patronietcd.key
sudo chmod 644 /{{ pg_ssl }}/pgbouncer.crt
sudo chmod 600 /{{ pg_ssl }}/pgbouncer.key
Удаление временной директории на мастере
Действие выполняется на мастере.
Удалите временную директорию на мастере:
sudo su - {{ USER }}
rm -rf /tmp/{{ pg_ssl }}
Генерация серверного сертификата
Действие выполняется на реплике.
Заполните конфигурационный файл server.cnf, подставьте актуальное имя хоста и IP-адрес в разделе [alt_names]:
sudo su - {{ USER }}
vi /{{ pg_ssl }}/server.cnf
Содержимое файла server.cnf:
[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[ssl_client]
extendedKeyUsage = clientAuth, serverAuth
basicConstraints = CA:FALSE
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
subjectAltName = @alt_names
[v3_ca]
basicConstraints = CA:TRUE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
authorityKeyIdentifier=keyid:always,issuer
[alt_names]
DNS = {{ replica_host }}
IP = {{ replica_ip }}
Сгенерируйте серверный сертификат, подписывая его с помощью root:
sudo su - {{ USER }}
openssl req -new -nodes -text -out /{{ pg_ssl }}/server.csr -keyout /{{ pg_ssl }}/server.key -config /{{ pg_ssl }}/server.cnf -subj "/CN={{ replica_host }}"
openssl x509 -req -in /{{ pg_ssl }}/server.csr -text -days 365 -CA /{{ pg_ssl }}/root.crt -CAkey /{{ pg_ssl }}/root.key -CAcreateserial -extfile /{{ pg_ssl }}/server.cnf -extensions ssl_client -out /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.key
sudo chmod 644 /{{ pg_ssl }}/server.crt
sudo chmod 600 /{{ pg_ssl }}/server.key
sudo cp /{{ pg_ssl }}/root.crt /etc/pki/ca-trust/source/anchors/ && sudo update-ca-trust
Конфигурирование etcd
Корректировка конфигурационного файла
Действие выполняется на реплике.
Скорректируйте конфигурационный файл etcd. Значение ETCD_INITIAL_CLUSTER следует взять с мастера.
sudo su - {{ USER }}
sudo vi /etc/etcd/etcd.conf
Пересоздание рабочих директорий
Действие выполняется на всех хостах.
Примечание:
Если в etcd не включена аутентификация или известен пароль
root(внутренний пользователь etcd), можно удалить сбойный узел (member) из кластера etcd и добавить взамен него новый, не выключая весь кластер. В противном случае приходится пересоздавать узлы etcd полностью. Ниже приводится процедура полного пересоздания узлов etcd.Процедура включения в кластер отдельного узла описана в подразделе «Процедура 1. Мягкий способ без замены всех узлов».
Остановите службу etcd:
sudo su - {{ USER }}
sudo systemctl stop etcd
Пересоздайте рабочие директории etcd на каждом узле (они будут впоследствии заполнены автоматически во время первого старта):
sudo su - {{ USER }}
sudo rm -rf /var/lib/etcd
sudo mkdir -p /var/lib/etcd
sudo chown postgres:postgres /var/lib/etcd
sudo chmod 700 /var/lib/etcd
Старт etcd-кластера
Действие выполняется на всех хостах.
Запустите службу etcd:
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start etcd
Настройка аутентификации в etcd
Действие выполняется на мастере.
Опишите пользователей в etcd и включите аутентификацию:
Примечание:
Пользователь
rootявляется техническим и используется только во время данного конфигурирования. Его возможно запомнить и использовать в дальнейшем, но по умолчанию он не используется после инсталляции.Пароль можно сгенерировать с помощью команды:
openssl rand -base64 24.В примере в качестве пароля
rootиспользован параметр: {{ root_pass }}.Пароль пользователя
patronietcdможно сгенерировать с помощью команды:openssl rand -base64 24.В примере в качестве пароля
patronietcdиспользован параметр: {{ patronietcd_pass }}.Затем пароль надо засекретить (на хосте мастера и реплики), чтобы впоследствии поместить в
postgres.yml. Команда, используемая для засекречивания, запрашивает пароль и выдает его засекреченный вид:/opt/pangolin-auth-password/bin/pg_auth_password enc -t.В командах ниже можно использовать либо серверный, либо клиентский сертификат
postgres.
sudo su - postgres
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' role add patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt role grant-permission patroni readwrite --prefix=true /service/
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user grant-role patronietcd patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role add patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt role grant patroni -path '/service/*' -readwrite
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' user grant patronietcd -roles patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role revoke guest -path '/*' --readwrite
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key member list -w table
ETCDCTL_API=3 etcdctl --endpoints={{ replica_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user list
Конфигурирование Pangolin Managers
Настройка конфигурационных файлов
Действие выполняется на мастере и реплике.
Отредактируйте конфигурационные файлы Pangolin Manager на мастере и реплике, выполнив действия ниже:
sudo su - {{ USER }}
sudo vi /etc/pangolin-manager/postgres.yml
Выполните следующие действия:
- Обновите пароль
patronietcd, если он поменялся в пункте 2.4. - Обновите пароль
patroniyml- для этого сгенерируйте и засекретьте его так же, как и дляpatronietcd. - Убедитесь в корректности значения пароля для
ldapbindpasswdи если есть необходимость сгенерируйте, засекреьте и внесите его вpostgres.ymlв секциюpg_hba. - При необходимости произведите дополнительные изменения.
Внимание:
Пароль, засекреченный на мастере, должен быть указан в
postgres.ymlна мастере.Пароль, засекреченный на реплике, должен быть указан в
postgres.ymlна реплике.
Дополнительно на реплике выполните следующие действия:
- Измените название параметра
etcd.hostнаetcd.hosts, значение возьмите с мастера. - Добавьте параметры
bootstrap.synchronous_modeиbootstart.synchronous_mode_strictтак же, как на мастере. - Добавьте параметр
postgresql.callbacks.on_role_changeтак же, как на мастере. - Измените значение параметра
postgresql.parameters.installer.cluster_type, чтобы оно было таким же, как на мастере. - Приведите блок параметров
pg_hbaв соответствие с аналогичными параметрами на мастере (по умолчанию можно просто перенести все значения блока с мастера на реплику). - При необходимости можно также произвести другие изменения.
Конфигурирование PostgreSQL
Настройка директорий PostgreSQL
Действие выполняется на реплике.
Пересоздайте директории PostgreSQL. Имена директорий следует скорректировать, если текущие названия на мастере отличаются от используемых в примере имен.
sudo su - {{ USER }}
sudo rm -rf /pgerrorlogs/{version}/
sudo rm -rf /pgdata/{version}/data/
sudo rm -rf /pgarclogs/{version}/
sudo rm -rf /pgdata/{version}/tablespaces/
sudo mkdir -p /pgerrorlogs/{version}
sudo chown postgres:postgres /pgerrorlogs/{version}
sudo chmod 0700 /pgerrorlogs/{version}
sudo mkdir -p /pgdata/{version}/data
sudo chown postgres:postgres /pgdata/{version}/data
sudo chmod 0700 /pgdata/{version}/data
sudo mkdir -p /pgarclogs/{version}
sudo chown postgres:postgres /pgarclogs/{version}
sudo chmod 0700 /pgarclogs/{version}
sudo mkdir -p /pgdata/{version}/tablespaces
sudo chown postgres:postgres /pgdata/{version}/tablespaces
sudo chmod 0700 /pgdata/{version}/tablespaces
sudo mkdir -p /etc/postgres
sudo chown postgres:postgres /etc/postgres
sudo chmod 0700 /etc/postgres
Настройка прав sudo
Действие выполняется на реплике.
Скорректируйте содержимое /etc/sudoers - скопируйте содержимое с мастера или заполните в соответствии с конфигурацией:
sudo su - {{ USER }}
sudo visudo --file /etc/sudoers
Внимание:
Файл
/etc/sudoers- очень чувствительный элемент. В случае наличия в нем синтаксической ошибки можно потерять права sudo.Чтобы проверить корректную работу sudo, можно выполнить переключение на другого пользователя, например:
sudo su - postgres.
Одним из вариантов актуализации /etc/sudoers является перенос файла с мастера целиком. Пример выполнения:
-
копирование файла во временную директорию на мастере (выполняется на стороне мастера):
sudo su - {{ USER }}
sudo cp /etc/sudoers /tmp/
sudo chown {{ USER }}:{{ USER }} /tmp/sudoers -
копирование файла из временной директории мастера в целевую директорию на реплике (выполняется на стороне реплики):
sudo su - {{ USER }}
sudo scp {{ USER }}@{{ master_ip }}:/tmp/sudoers /tmp/
sudo chown root:root /tmp/sudoers
sudo cp /tmp/sudoers /etc/sudoers
sudo rm /tmp/sudoers -
удаление временного файла на мастере (выполняется на стороне мастера):
sudo rm /tmp/sudoers
Запуск реплики
Актуализация нового конфигурационного файла на мастере
Действие выполняется на мастере.
Актуализируйте новый файл postgres.yml и выведите Pangolin Manager из режима паузы:
sudo su - {{ USER }}
sudo systemctl restart pangolin-manager
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml resume
Старт Pangolin Manager на реплике и восстановление базы данных
Действие выполняется на реплике.
Запустите Pangolin Manager, который восстановит реплику в соответствии с bootstrap-логикой файла postgres.yml. В результате получится работающий кластер.
sudo su - {{ USER }}
sudo systemctl start pangolin-manager
Конфигурирование Pangolin Pooler
Примечание:
Данный блок является опциональным и необходим в случае наличия компонента Pangolin Pooler.
Корректировка конфигурационных файлов
Действие выполняется на реплике.
Скорректируйте конфигурационные файлы Pangolin Pooler, сравнивая их с аналогичными файлами на мастере:
sudo su - {{ USER }}
sudo vi /etc/pangolin-pooler/pangolin-pooler.ini
sudo vi /etc/pangolin-pooler/userlist.txt
sudo vi /etc/logrotate.d/pangolin-pooler
Запуск Pangolin Pooler
Действие выполняется на мастере и реплике.
Перезапустите службу Pangolin Pooler:
sudo su - {{ USER }}
systemctl restart pangolin-pooler
Пересоздание хоста реплики из дистрибутива
Полностью утерян хост реплики. Необходимо восстановить только сбойный хост, а не весь кластер целиком. Для восстановления потребуется полностью новая виртуальная машина.
Процедура инициализации
Для наглядности приведенных ниже действий и их последовательности в описываемой процедуре приводятся примеры команд. Допускается выполнение данных действий какими-либо другими средствами или командами, более удобными с точки зрения пользователя.
Обозначение параметров
В примерах команд далее используются параметры для обозначения имен хостов вместо действительных значений:
-
узел мастера: {{ master_host }} и {{ master_ip }};
-
узел реплики: {{ replica_host }} и {{ replica_ip }};
-
узел арбитра: {{ arbiter_host }} и {{ arbiter_ip }};
-
суперпользователь: {{ USER }}.
Например
core_dev; -
директория с сертификатами: {{ pg_ssl }}.
Например,
pg_sslилиhome/postgres/ssl. Имя директории с сертификатами следует выбрать так же, как на мастере; -
пользователь
nexus(репозиторий дистрибутивов): {{ nexus_login }}.
Примечание:
В случае необходимости конфигурации дополнительных компонентов, таких как RSYSLOG или SRC, следует обращаться к соответствующим материалам.
Подготовительные действия
Для выполнения процедуры предполагается наличие новой виртуальной машины, на которой будет производиться инсталляция. Параметры виртуальной машины должны соответствовать сохранившимся хостам кластера Pangolin. Процедура может быть использована для различных версий Pangolin: 4.x.x - 6.x.x. Однако следует учитывать тот факт, что примеры команд и набор необходимых действий приводятся для версий Pangolin 5.1.0-5.2.0 и операционной системы Red Hat Enterprise Linux Server release 7.9. В других версиях могут отличаться имена файлов, директорий, набор компонентов, особенности конфигурации, влияющие на выбор того или иного формата команд, и др.
Скачивание дистрибутива
Действие выполняется на реплике.
Скачайте дистрибутив. В качестве примера рассмотрим дистрибутив Pangolin 5.1.0. Версия дистрибутива должна совпадать с установленной на мастере версией.
sudo su - {{ USER }}
mkdir -p /tmp/pangolin_{version}
cd /tmp/pangolin_{version}
curl -O -u {{ nexus_login }} <URL>/Pangolin-D-{version}-40-distrib.tar.gz
tar -xvf /tmp/pangolin_{version}/Pangolin-D-{version}-40-distrib.tar.gz
Настройка репозиториев yum
Действие выполняется на реплике.
Настройте репозитории yum. Для этого перенесите содержимое с аналогичных файлов на узле мастера или скопируйте сами файлы на узел арбитра и дайте такие же права.
sudo su - {{ USER }}
sudo vi /etc/yum.repos.d/D10.repo
sudo vi /etc/yum.repos.d/mirror.repo
sudo vi /etc/yum.repos.d/redhat.repo
Установка пакетов
Действие выполняется на реплике.
Для дальнейшей работы требуется установить ряд необходимых пакетов.
Заполните вспомогательный файл prereq.txt:
sudo su - {{ USER }}
vi /home/{{ USER }}/prereq.txt
Файл prereq.txt должен содержать следующую информацию:
openssl
rsync
sshpass
python3-pip
python36
python36-devel
python36-virtualenv
rsyslog
postgresql-libs
Выполните установку пакетов как в следующем примере:
sudo su - {{ USER }}
sudo yum install $(cat /home/{{ USER }}/prereq.txt)
Создание пользователя postgres
Действие выполняется на реплике.
Создайте пользователя postgres, если он отсутствует на узле реплики:
sudo su - {{ USER }}
sudo useradd -m -G postgres postgres
Заполните /home/postgres/.bash_profile - перенесите содержимое с мастера и скорректируйте имена хостов и IP-адреса для работы на хосте реплики:
sudo su - {{ USER }}
sudo vi /home/postgres/.bash_profile
sudo chown postgres:postgres /home/postgres/.bash_profile
sudo chmod 700 /home/postgres/.bash_profile
Создание установочной директории PostgreSQL
Действие выполняется на реплике.
Создайте установочную директорию PostgreSQL. Имя директории следует выбрать таким же, как на мастере:
sudo su - {{ USER }}
sudo mkdir -p /usr/pgsql-se-{version}/
sudo chown postgres:postgres /usr/pgsql-se-{version}/
sudo chmod 0700 /usr/pgsql-se-{version}/
Создание виртуального окружения PostgreSQL
Действие выполняется на реплике.
Создайте виртуальное окружение PostgreSQL:
sudo su - postgres
virtualenv-3 /usr/pgsql-se-{version}/postgresql_venv --python=python3
Настройка вспомогательных файлов
Действие выполняется на реплике.
Заполните вспомогательные файлы: packlist.txt и requirements.txt:
sudo su - postgres
vi /home/postgres/packlist.txt
mkdir -p /home/postgres/installer_cache_dir/python_packages
vi /home/postgres/installer_cache_dir/python_packages/requirements.txt
Содержимое файла packlist.txt:
PyYAML==5.3.1
netaddr==0.7.19
psycopg2-binary==2.8.4
flake8==3.7.9
ruamel.yaml==0.16.12
argparse==1.4.0
requests==2.23.0
python-daemon==2.2.4
pexpect==4.8.0
cryptography==3.3.1
ansible-core==2.11.5
Содержимое файла requirements.txt (также можно найти в дистрибутиве: '/tmp/pangolin_510/installer/roles/checkup/files/requirements.txt):
urllib3==1.25.9
PyYAML==5.3.1
six==1.15.0
kazoo==2.8.0
psycopg2-binary==2.8.4
flake8==3.7.9
python-dateutil==2.8.1
boto==2.49.0
requests==2.23.0
python-etcd==0.4.5
click==7.1.2
prettytable==0.7.2
psutil==5.7.3
cdiff==1.0
python-daemon==2.2.4
setuptools-rust==1.1.1
Настройка виртуального окружения PostgreSQL
Действие выполняется на реплике.
Выполните установку необходимых в виртуальном окружении пакетов:
source /usr/pgsql-se-{version}/postgresql_venv/bin/activate
pip3 install --index-url=<URL> --trusted host=<host> --upgrade pip
pip3 install --index-url=<URL> -r /home/postgres/packlist.txt
pip download -r /home/postgres/installer_cache_dir/python_packages/requirements.txt --dest /home/postgres/installer_cache_dir/python_packages --only-binary :all
deactivate
Генерация сертификатов
В данном разделе выполняется генерация серверного сертификата и перенес клиентских сертификатов с мастера для того, чтобы все сертификаты кластера были подписаны одним root-сертификатом.
Создание директории для сертификатов
Действие выполняется на реплике.
Создайте директорию для сертификатов на реплике:
sudo su - {{ USER }}
sudo rm -rf /{{ pg_ssl }}/
sudo mkdir -p /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/
sudo chmod 0755 /{{ pg_ssl }}/
Копирование сертификатов во временную директорию на мастере
Действие выполняется на мастере.
Скопируйте root и клиентские сертификаты во временную директорию на мастере:
sudo su - {{ USER }}
mkdir /tmp/{{ pg_ssl }}
sudo cp /{{ pg_ssl }}/root.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/root.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/client.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/client.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/etcd.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/etcd.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patroni.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patroni.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patronietcd.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patronietcd.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/pgbouncer.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/pgbouncer.key /tmp/{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/client.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/client.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/etcd.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/etcd.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patroni.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patroni.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patronietcd.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patronietcd.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/pgbouncer.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/pgbouncer.key
Перенос сертификатов на реплику
Действие выполняется на реплике.
Перенесите сертификаты с мастера на реплику:
sudo su - {{ USER }}
sudo scp -r {{ USER }}@{{ master_ip }}:/tmp/{{ pg_ssl }}/* /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/root.key
sudo chown postgres:postgres /{{ pg_ssl }}/root.crt
sudo chown postgres:postgres /{{ pg_ssl }}/client.crt
sudo chown postgres:postgres /{{ pg_ssl }}/client.key
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/etcd.crt
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/etcd.key
sudo chown postgres:postgres /{{ pg_ssl }}/patroni.crt
sudo chown postgres:postgres /{{ pg_ssl }}/patroni.key
sudo chown postgres:postgres /{{ pg_ssl }}/patronietcd.crt
sudo chown postgres:postgres /{{ pg_ssl }}/patronietcd.key
sudo chown postgres:postgres /{{ pg_ssl }}/pgbouncer.crt
sudo chown postgres:postgres /{{ pg_ssl }}/pgbouncer.key
sudo chmod 644 /{{ pg_ssl }}/root.crt
sudo chmod 600 /{{ pg_ssl }}/root.key
sudo chmod 644 /{{ pg_ssl }}/client.crt
sudo chmod 600 /{{ pg_ssl }}/client.key
sudo chmod 644 /{{ pg_ssl }}/etcd.crt
sudo chmod 600 /{{ pg_ssl }}/etcd.key
sudo chmod 644 /{{ pg_ssl }}/patroni.crt
sudo chmod 600 /{{ pg_ssl }}/patroni.key
sudo chmod 644 /{{ pg_ssl }}/patronietcd.crt
sudo chmod 600 /{{ pg_ssl }}/patronietcd.key
sudo chmod 644 /{{ pg_ssl }}/pgbouncer.crt
sudo chmod 600 /{{ pg_ssl }}/pgbouncer.key
Удаление временной директории на мастере
Действие выполняется на мастере.
Удалите временную директорию на мастере:
sudo su - {{ USER }}
rm -rf /tmp/{{ pg_ssl }}
Генерация серверного сертификата
Действие выполняется на реплике.
Заполните конфигурационный файл server.cnf, подставьте актуальное имя хоста и IP-адрес в разделе [alt_names]:
sudo su - {{ USER }}
vi /{{ pg_ssl }}/server.cnf
Содержимое файла server.cnf:
[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[ssl_client]
extendedKeyUsage = clientAuth, serverAuth
basicConstraints = CA:FALSE
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
subjectAltName = @alt_names
[v3_ca]
basicConstraints = CA:TRUE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
authorityKeyIdentifier=keyid:always,issuer
[alt_names]
DNS = {{ replica_host }}
IP = {{ replica_ip }}
Сгенерируйте серверный сертификат, подписывая его с помощью root:
sudo su - {{ USER }}
openssl req -new -nodes -text -out /{{ pg_ssl }}/server.csr -keyout /{{ pg_ssl }}/server.key -config /{{ pg_ssl }}/server.cnf -subj "/CN={{ replica_host }}"
openssl x509 -req -in /{{ pg_ssl }}/server.csr -text -days 365 -CA /{{ pg_ssl }}/root.crt -CAkey /{{ pg_ssl }}/root.key -CAcreateserial -extfile /{{ pg_ssl }}/server.cnf -extensions ssl_client -out /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.key
sudo chmod 644 /{{ pg_ssl }}/server.crt
sudo chmod 600 /{{ pg_ssl }}/server.key
sudo cp /{{ pg_ssl }}/root.crt /etc/pki/ca-trust/source/anchors/ && sudo update-ca-trust
Перевод Pangolin Manager в режим паузы
Действие выполняется на мастере.
Переведите Pangolin Manager в режим паузы:
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml pause
Установка etcd
Очистка хоста от предыдущих инсталляций
Действие выполняется на реплике.
Опционально можно выполнить очистку хоста от предыдущих инсталляций, если это необходимо. Если виртуальная машина новая, то выполнять данное действие нет необходимости.
sudo su - {{ USER }}
sudo systemctl stop etcd
sudo yum remove etcd -y
sudo rm -rf /var/lib/etcd
sudo rm -rf /etc/etcd
sudo rm /etc/systemd/system/etcd.service
sudo rm /usr/lib/systemd/system/etcd.service
Конфигурирование файла службы
Действие выполняется на реплике.
Заполните файл службы. Информацию в него перенесите из аналогичного файла на мастере.
sudo su - {{ USER }}
sudo vi /usr/lib/systemd/system/etcd.service
sudo chown postgres:postgres /usr/lib/systemd/system/etcd.service
sudo chmod 640 /usr/lib/systemd/system/etcd.service
Установка etcd
Действие выполняется на реплике.
Выполните установку etcd. Версия должна быть такой же, как и на мастере.
sudo su - {{ USER }}
sudo yum install etcd-3.3.11
Конфигурирование etcd
Действие выполняется на реплике.
Заполните конфигурационный файл etcd. Содержимое файла перенесите с мастера и скорректируйте значения параметров:
- ETCD_NAME
- ETCD_ADVERTISE_CLIENT_URLS
- ETCD_INITIAL_ADVERTISE_PEER_URLS
sudo su - {{ USER }}
sudo mkdir -p /etc/etcd
sudo chown postgres:postgres /etc/etcd
sudo chmod 700 /etc/etcd
sudo vi /etc/etcd/etcd.conf
sudo chown postgres:postgres /etc/etcd/etcd.conf
sudo chmod 700 /etc/etcd/etcd.conf
Пересоздание рабочих директорий
Действие выполняется на всех узлах.
Примечание:
Если в etcd не включена аутентификация или известен пароль root (внутренний пользователь etcd), то можно удалить сбойный узел (member) из кластера etcd и добавить взамен него новый, не выключая весь кластер. В противном случае приходится пересоздавать все узлы etcd полностью. Ниже приводится процедура полного пересоздания узлов etcd.
Процедура включения в кластер отдельного узла описана в подразделе «Процедура 1. Мягкий способ без замены всех узлов».
Остановите службу etcd:
sudo su - {{ USER }}
sudo systemctl stop etcd
Пересоздайте рабочие директории etcd на каждом узле (впоследствии они будут заполнены автоматически во время первого старта):
sudo su - {{ USER }}
sudo rm -rf /var/lib/etcd
sudo mkdir -p /var/lib/etcd
sudo chown postgres:postgres /var/lib/etcd
sudo chmod 700 /var/lib/etcd
Старт etcd-кластера
Действие выполняется на всех узлах.
Запустите службу etcd:
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start etcd
Настройка аутентификации в etcd
Действие выполняется на мастере.
Опишите пользователей в etcd и включите аутентификацию:
Примечание:
Пользователь
rootявляется техническим и используется только во время данного конфигурирования. Его возможно запомнить и использовать в дальнейшем, но по умолчанию он не используется после инсталляции.Пароль можно сгенерировать с помощью команды:
openssl rand -base64 24.В примере в качестве пароля
rootиспользован параметр: {{ root_pass }}.Пароль пользователя
patronietcdможно сгенерировать с помощью команды:openssl rand -base64 24.В примере в качестве пароля
patronietcdиспользован параметр: {{ patronietcd_pass }}.Затем пароль надо засекретить (на хосте мастера и реплики), чтобы впоследствии поместить в
postgres.yml. Команда, используемая для засекречивания, запрашивает пароль и выдает его засекреченный вид:/opt/pangolin-auth-password/bin/pg_auth_password enc -t.В командах ниже можно использовать либо серверный, либо клиентский сертификат
postgres.
sudo su - postgres
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' role add patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt role grant-permission patroni readwrite --prefix=true /service/
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user grant-role patronietcd patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role add patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt role grant patroni -path '/service/*' -readwrite
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' user grant patronietcd -roles patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role revoke guest -path '/*' --readwrite
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key member list -w table
ETCDCTL_API=3 etcdctl --endpoints={{ replica_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user list
Установка Pangolin Manager
Установка пакета pangolin-manager
Действие выполняется на реплике.
sudo yum install pangolin-manager
Корректировка конфигурационного файла на мастере
Действие выполняется на мастере.
Отредактируйте конфигурационный файл Pangolin Manager на мастере, выполнив действия ниже:
sudo su - {{ USER }}
sudo vi /etc/pangolin-manager/postgres.yml
Выполните следующие действия:
- Обновите пароль
patronietcd, если он поменялся на шаге настройки аутентификации в etcd. - Обновите пароль
patroniyml- для этого сгенерируйте и засекретьте его так же, как и дляpatronietcd. - Убедитесь в корректности значения пароля для
ldapbindpasswdи при необходимости сгенерируйте, засекретьте и внесите его вpostgres.ymlв секциюpg_hba. - При необходимости можно произвести другие изменения.
Внимание:
Пароль, засекреченный на мастере, должен быть указан в
postgres.ymlна мастере.
Настройка конфигурационного файла на реплике
Внимание:
Приведенные ниже действия соответствуют версии Pangolin Manager 1.1.0. В других версиях функциональность может отличаться и, соответственно, могут потребоваться иные действия при работе с файлом
postgres.yml.
Действие выполняется на реплике.
Заполните конфигурационный файл на реплике - перенесите в него содержимое с аналогичного файла на мастере и отредактируйте, выполнив действия ниже:
sudo su - {{ USER }}
sudo mkdir -p /etc/pangolin-manager
sudo chown postgres:postgres /etc/pangolin-manager
sudo chmod 700 /etc/pangolin-manager
sudo vi /etc/pangolin-manager/postgres.yml
sudo chown postgres:postgres /etc/pangolin-manager/postgres.yml
sudo chmod 600 /etc/pangolin-manager/postgres.yml
Необходимо выполнить следующие действия:
- Обновите пароль
patronietcd, если он поменялся на шаге настройки аутентификации в etcd. - Обновите пароль
patroniyml- для этого сгенерируйте и засекретьте его так же, как и дляpatronietcd. - Убедитесь в корректности значения пароля для
ldapbindpasswdи при необходимости сгенерируйте, засекретьте и внесите его вpostgres.ymlв секциюpg_hba. - Скорректируйте значение параметра
name(во второй строке) - имя хоста мастера необходимо поменять на имя хоста реплики. - Скорректируйте значение параметра
restapi.connect_address- имя хоста мастера необходимо поменять на имя хоста реплики. - Скорректируйте значение параметра
postgresql.connect_address- имя хоста мастера необходимо поменять на имя хоста реплики. - При необходимости можно произвести другие изменения.
Внимание:
Пароль, засекреченный на реплике, должен быть указан в
postgres.ymlна реплике.
Настройка скрипта управления Pangolin Pooler
Действие выполняется на реплике.
Заполните скрипт управления службой Pangolin Pooler - содержимое перенесите из аналогичного файла на мастере:
sudo su - {{ USER }}
sudo vi /etc/pangolin-manager/reload_pangolin_pooler.sh
sudo chown postgres:postgres /etc/pangolin-manager/reload_pangolin_pooler.sh
sudo chmod 500 /etc/pangolin-manager/reload_pangolin_pooler.sh
Настройка службы Pangolin Manager
Действие выполняется на реплике.
Заполните скрипт управления службой Pangolin Manager - содержимое перенесите из аналогичного файла с мастера:
sudo su - {{ USER }}
sudo vi /usr/lib/systemd/system/pangolin-manager.service
sudo chown root:root /usr/lib/systemd/system/pangolin-manager.service
sudo chmod 640 /usr/lib/systemd/system/pangolin-manager.service
Копирование системных файлов
Действие выполняется на реплике.
Скопируйте файлы Pangolin Manager из дистрибутива в рабочие каталоги:
Примечание:
Pangolin Manager устанавливается из пакета pangolin-manager.
sudo yum install pangolin-manager
Установка PostgreSQL
Внимание:
Перечень выполняемых действий может варьироваться от версии к версии.
Создание директорий
Действие выполняется на реплике.
Cоздайте директории PostgreSQL с такими же именами, как на мастере. Если имена отличаются от используемых в примере, то команды следует скорректировать.
sudo su - {{ USER }}
sudo rm -rf /pgerrorlogs/{version}/
sudo rm -rf /pgdata/0{major_version}/data/
sudo rm -rf /pgarclogs/{version}/
sudo rm -rf /pgdata/{version}/tablespaces/
sudo mkdir -p /pgerrorlogs/{version}
sudo chown postgres:postgres /pgerrorlogs/{version}
sudo chmod 0700 /pgerrorlogs/{version}
sudo mkdir -p /pgdata/{version}/data
sudo chown postgres:postgres /pgdata/{version}/data
sudo chmod 0700 /pgdata/{version}/data
sudo mkdir -p /pgarclogs/{version}
sudo chown postgres:postgres /pgarclogs/{version}
sudo chmod 0700 /pgarclogs/{version}
sudo mkdir -p /pgdata/{version}/tablespaces
sudo chown postgres:postgres /pgdata/{version}/tablespaces
sudo chmod 0700 /pgdata/{version}/tablespaces
sudo mkdir -p /etc/postgres
sudo chown postgres:postgres /etc/postgres
sudo chmod 0700 /etc/postgres
Установка СУБД Pangolin
Действие выполняется на реплике.
Выполните установку СУБД Pangolin из дистрибутива. Начиная с Pangolin 5.1.0, инсталляция происходит в /usr/pgsql-se-{version} автоматически, в частности, создаются необходимые в дальнейшем директории.
Примечание:
Имя файла в дистрибутиве может отличаться от примера ниже в зависимости от версии. Имя рабочей директории Pangolin подразумевается в зависимости от устанавливаемой версии продукта и не является параметром при установке.
sudo su - {{ USER }}
sudo rpm -qa | grep pangolin
sudo rpm -ivh /tmp/pangolin_{version}/platform-v-pangolin-dbms-{version}-redhat7_9.x86_64.rpm
Настройка файла версии
Действие выполняется на реплике.
Скопируйте файл версии из дистрибутива или с мастера:
sudo su - {{ USER }}
sudo cp /tmp/pangolin_{version}/installer/files/version /usr/pgsql-se-{version}/share/version
sudo chown postgres:postgres /usr/pgsql-se-{version}/share/version
sudo chmod 0700 /usr/pgsql-se-{version}/share/version
Настройка прав директории bin
Действие выполняется на реплике.
Установите права на директорию usr/pgsql-se-{version}/postgresql_venv/bin/:
sudo su - {{ USER }}
sudo chown postgres:postgres /usr/pgsql-se-{version}/postgresql_venv/bin/
sudo chmod 0700 /usr/pgsql-se-{version}/postgresql_venv/bin/
Копирование утилит
Действие выполняется на реплике.
Скопируйте утилиты для работы БД и установите необходимые права:
sudo su - {{ USER }}
sudo mkdir -p /usr/pgsql-se-{version}/3rdparty
sudo chown postgres:postgres /usr/pgsql-se-{version}/3rdparty
sudo chmod 0700 /usr/pgsql-se-{version}/3rdparty
sudo cp -r /tmp/pangolin_{version}/3rdparty/pgrouting.tar.gz /usr/pgsql-se-{version}/3rdparty/
sudo cp -r /tmp/pangolin_{version}/3rdparty/postgis.tar.gz /usr/pgsql-se-{version}/3rdparty/
sudo chown -R postgres:postgres /usr/pgsql-se-{version}/3rdparty/pgrouting.tar.gz
sudo chown -R postgres:postgres /usr/pgsql-se-{version}/3rdparty/postgis.tar.gz
sudo chmod -R 0700 /usr/pgsql-se-{version}/3rdparty/pgrouting.tar.gz
sudo chmod -R 0700 /usr/pgsql-se-{version}/3rdparty/postgis.tar.gz
sudo su - postgres
cd /usr/pgsql-se-{version}/3rdparty
tar -xvf pgrouting.tar.gz
tar -xvf postgis.tar.gz
rm -rf pgrouting.tar.gz
rm -rf postgis.tar.gz
exit
sudo chown -R postgres:postgres /usr/pgsql-se-{version}/3rdparty/pgrouting
sudo chown -R postgres:postgres /usr/pgsql-se-{version}/3rdparty/postgis
sudo chmod -R 0700 /usr/pgsql-se-{version}/3rdparty/pgrouting
sudo chmod -R 0700 /usr/pgsql-se-{version}/3rdparty/postgis
Копирование дополнительных утилит и документации
Действие выполняется на реплике.
Скопируйте утилиту migration_tools, diagnostic_tool и каталог с документацией:
Внимание:
Утилита diagnostic_tools копируется в случае наличия в дистрибутиве.
sudo su - {{ USER }}
sudo mkdir -p /usr/pgsql-se-{version}/migration_tools
sudo chown postgres:postgres /usr/pgsql-se-{version}/migration_tools
sudo chmod 0700 /usr/pgsql-se-{version}/migration_tools
sudo cp -r /tmp/pangolin_{version}/migration_tools/db-data-comparator /usr/pgsql-se-{version}/migration_tools/
sudo cp -r /tmp/pangolin_{version}/migration_tools/ora2pg /usr/pgsql-se-{version}/migration_tools/
sudo cp -r /tmp/pangolin_{version}/migration_tools/pgloader /usr/pgsql-se-{version}/migration_tools/
sudo chown -R postgres:postgres /usr/pgsql-se-{version}/migration_tools/
sudo chmod 0700 /usr/pgsql-se-{version}/migration_tools/
sudo cp -r /tmp/pangolin_{version}/diagnostic_tool /usr/pgsql-se-{version}/
sudo chown -R postgres:postgres /usr/pgsql-se-{version}/diagnostic_tool
sudo chmod 0700 /usr/pgsql-se-{version}/diagnostic_tool
sudo cp -r /tmp/pangolin_{version}/documentation /usr/pgsql-se-{version}/
sudo chown -R postgres:postgres /usr/pgsql-se-{version}/documentation
sudo chmod 0700 /usr/pgsql-se-{version}/documentation
sudo cp /tmp/pangolin_{version}/readme.txt /usr/pgsql-se-{version}/
sudo cp /tmp/pangolin_{version}/releasenotes.json /usr/pgsql-se-{version}/
sudo chown postgres:postgres /usr/pgsql-se-{version}/readme.txt
sudo chmod 0700 /usr/pgsql-se-{version}/readme.txt
sudo chown postgres:postgres /usr/pgsql-se-{version}/releasenotes.json
sudo chmod 0700 /usr/pgsql-se-{version}/releasenotes.json
Копирование timescaledb
Действие выполняется на реплике.
Скопируйте timescaledb:
sudo su - {{ USER }}
sudo chown -R postgres:postgres /tmp/pangolin_{version}/timescaledb
sudo chmod -R 0700 /tmp/pangolin_{version}/timescaledb
sudo cp -rp /tmp/pangolin_{version}/timescaledb/usr/pgsql-se-{version}/lib/ /usr/pgsql-se-{version}/
sudo cp -rp /tmp/pangolin_{version}/timescaledb/usr/pgsql-se-{version}/share/extension/ /usr/pgsql-se-{version}/share/
Настройка crontab
Действие выполняется на реплике.
Заполните файл postgresql_clean_logs - содержимое перенесите с мастера. Затем настройте crontab - так же, как на мастере.
sudo su - {{ USER }}
sudo vi /usr/local/sbin/postgresql_clean_logs
sudo chown postgres:postgres /usr/local/sbin/postgresql_clean_logs
sudo chmod 0751 /usr/local/sbin/postgresql_clean_logs
crontab -e
Создание и настройка пользователя kmadmin_pg
Действие выполняется на реплике.
Создайте пользователя kmadmin_pg (если его нет) и задайте пароль {{ kmadmin_pg_pass }}. Содержимое файла .bashrc перенесите с мастера.
sudo su - {{ USER }}
sudo useradd -m -G kmadmin_pg kmadmin_pg
sudo printf '{{ kmadmin_pg_pass }}' | chpasswd --encrypted
sudo vim /home/kmadmin_pg/.bashrc
sudo chown kmadmin_pg:kmadmin_pg /opt/pangolin-security-utilities/bin/encrypt_params_file
sudo chmod 0700 /opt/pangolin-security-utilities/bin/encrypt_params_file
sudo chown kmadmin_pg:kmadmin_pg /opt/pangolin-security-utilities/bin/generate_encryption_key
sudo chmod 0700 /opt/pangolin-security-utilities/bin/generate_encryption_key
sudo chown kmadmin_pg:kmadmin_pg /opt/pangolin-security-utilities/bin/setup_kms_credentials
sudo chmod 0700 /opt/pangolin-security-utilities/bin/setup_kms_credentials
sudo chown root:kmadmin_pg /usr/pgsql-se-{version}/bin/initprotection
sudo chmod 0750 /usr/pgsql-se-{version}/bin/initprotection
sudo chown postgres:postgres /usr/pgsql-se-{version}/lib/libfe_elog.so
sudo chmod 0604 /usr/pgsql-se-{version}/lib/libfe_elog.so
sudo chown postgres:postgres /usr/pgsql-se-{version}/lib/plugins
sudo chmod 0704 /usr/pgsql-se-{version}/lib/plugins
sudo chown postgres:kmadmin_pg /etc/postgres
sudo chmod 0731 /etc/postgres
sudo chmod 0701 /usr/pgsql-se-{version}
sudo chmod 0701 /usr/pgsql-se-{version}/bin
sudo chmod 0705 /usr/pgsql-se-{version}/lib
sudo chmod 0705 /usr/pgsql-se-{version}/lib/plugins
Настройка прав sudo
Действие выполняется на реплике.
Скорректируйте содержимое /etc/sudoers - скопируйте содержимое с мастера и заполните в соответствии с конфигурацией:
sudo su - {{ USER }}
sudo visudo --file /etc/sudoers
Внимание:
Файл
/etc/sudoers- очень чувствительный элемент. В случае наличия в нем синтаксической ошибки можно потерять права sudo.Чтобы проверить корректную работу sudo, можно выполнить переключение на другого пользователя, например:
sudo su - postgres.
Одним из вариантов актуализации /etc/sudoers является перенос файла с мастера целиком. Пример выполнения:
-
копирование файла во временную директорию на мастере (выполняется на стороне мастера)
sudo su - {{ USER }}
sudo cp /etc/sudoers /tmp/
sudo chown {{ USER }}:{{ USER }} /tmp/sudoers -
копирование файла из временной директории мастера в целевую директорию на реплике (выполняется на стороне реплики)
sudo su - {{ USER }}
sudo scp {{ USER }}@{{ master_ip }}:/tmp/sudoers /tmp/
sudo chown root:root /tmp/sudoers
sudo cp /tmp/sudoers /etc/sudoers
sudo rm /tmp/sudoers -
удаление временного файла на мастере (выполняется на стороне мастера)
sudo rm /tmp/sudoers
Запуск реплики
Актуализация нового конфигурационного файла на мастере
Действие выполняется на мастере.
Актуализируйте новый файл postgres.yml и выведите Pangolin Manager из режима паузы:
sudo su - {{ USER }}
sudo systemctl restart pangolin-manager
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml resume
Старт Pangolin Manager на реплике и восстановление базы данных
Действие выполняется на реплике.
Запустите Pangolin Manager, который восстановит реплику в соответствии с bootstrap-логикой файла postgres.yml. В результате получится работающий кластер.
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start pangolin-manager
Конфигурирование Pangolin Pooler
Примечание:
Данный блок является опциональным и необходим в случае наличия компонента Pangolin Pooler.
Настройка файла службы Pangolin Pooler
Действие выполняется на реплике.
Заполните файл службы Pangolin Pooler. Содержимое файла перенесите с аналогичного файла на мастере.
sudo su - {{ USER }}
sudo vi /usr/lib/systemd/system/pangolin-pooler.service
sudo chown root:root /usr/lib/systemd/system/pangolin-pooler.service
sudo chmod 0644 /usr/lib/systemd/system/pangolin-pooler.service
Установка Pangolin Pooler
Действие выполняется на реплике.
Выполните установку компонента Pangolin Pooler:
sudo yum install pangolin-pooler-1.1.0-altlinux10.x86_64.rpm
Конфигурирование Pangolin Pooler
Действие выполняется на реплике.
Заполните файл pangolin-pooler.ini - содержимое перенесите с аналогичного файла на мастере и скорректируйте для хоста реплики:
sudo su - {{ USER }}
sudo mkdir -p /etc/pangolin-pooler
sudo chown postgres:postgres /etc/pangolin-pooler
sudo chmod 0700 /etc/pangolin-pooler
sudo vi /etc/pangolin-pooler/pangolin-pooler.ini
sudo chown postgres:postgres /etc/pangolin-pooler/pangolin-pooler.ini
sudo chmod 0600 /etc/pangolin-pooler/pangolin-pooler.ini
Конфигурирование userlist.txt
Действие выполняется на реплике.
Заполните файл userlist.txt - содержимое перенесите с аналогичного файла на мастере и скорректируйте для хоста реплики:
sudo su - {{ USER }}
sido vi /etc/pangolin-pooler/userlist.txt
sudo chown postgres:postgres /etc/pangolin-pooler/userlist.txt
sudo chmod 0600 /etc/pangolin-pooler/userlist.txt
Настройка ротации журналов
Действие выполняется на реплике.
Выполните конфигурирование ротации журналов. Содержимое файла pangolin-pooler перенесите из аналогичного файла на мастере.
sudo su - {{ USER }}
sudo vi /etc/logrotate.d/pangolin-pooler
sudo chown postgres:postgres /etc/logrotate.d/pangolin-pooler
sudo chmod 0644 /etc/logrotate.d/pangolin-pooler
Запуск Pangolin Pooler
Действие выполняется на мастере и реплике.
Перезапустите службу Pangolin Pooler:
sudo systemctl restart pangolin-pooler
Обеспечение аварийного завершения СУБД Pangolin при отключении СХД
Реализованная функциональность предназначена для определения отказа/отключения системы хранения данных (далее СХД) в кластере. При определении отказа/отключения системы хранения данных СУБД Pangolin аварийно завершается, а Pangolin Manager переключает лидера кластера.
Пути к каталогам для определения состояния СХД:
-
постоянные пути:
-
подкаталоги
PGDATA:global– подкаталог, содержащий общие таблицы кластера, такие какpg_database;pg_wal– подкаталог, содержащий файлы WAL;pg_commit_ts– подкаталог, содержащий данные о времени фиксации транзакций;pg_dynshmem– подкаталог, содержащий файлы, используемые подсистемой динамически разделяемой памяти;pg_notify– подкаталог, содержащий данные состояния прослушивания и уведомлений;pg_prep_stats– подкаталог для хранения файлов текстов запросов на подготовку для задачи «Поддержка prepared statements для транзакционного режима»;pg_serial– подкаталог, содержащий информацию о выполненных сериализуемых транзакциях;pg_snapshots– подкаталог, содержащий экспортированные снепшоты;pg_subtrans– подкаталог, содержащий данные о состоянии подтранзакций;pg_twophase– подкаталог, содержащий файлы состояний для подготовленных транзакций;pg_multixact– подкаталог, содержащий данные о состоянии мультитранзакций;base– подкаталог, содержащий подкаталоги для каждой базы данных;pg_pp_cache– password policy cache;pg_replslot– подкаталог, содержащий данные слота репликации;pg_stat– подкаталог, содержащий постоянные файлы для подсистемы статистики;pg_stat_tmp– подкаталог, содержащий временные файлы для подсистемы статистики;pg_xact– подкаталог, содержащий данные о состоянии транзакции;pg_logical– подкаталог, содержащий данные о состоянии для логического декодирования;pg_perf_insights– подкаталог, содержащий файлы с данными для задачи аналитики производительности;pg_auth– подкаталог используется задачей «Сквозная аутентификация»;
-
каталог
log_directory;
-
-
каталоги табличных пространств.
В СУБД Pangolin появляются новые параметры:
-
enable_filesystem_checker– определяет включение функциональности:True– функциональность включена,False– выключена (по умолчанию); -
disk_check_timeout– тайм-аут в секундах – периодичность проверки, имеет значение по умолчанию 5 секунд; -
disk_operation_timeout– тайм-аут в секундах – на ожидание завершения процесса записи/чтения, имеет значение по умолчанию 3 секунды; -
disk_retry_count– параметр определяет количество неудачных попыток файловых операций до аварийного переключения лидера кластера (failover), значение по умолчанию: 3; -
force_failover_timeout– параметр определяет период времени, в течение которого Pangolin гарантированно не запустится после отключения СХД, для того чтобы Pangolin Manager выполнил переключение лидера кластера. Значение рассчитывается по формуле:ttl + 2*loop_wait + 5где:
ttl- параметр Pangolin Manager, промежуток времени до запуска процесса автоматического перехода на другой ресурс; loop_wait - параметр Pangolin Manager, период опроса кластера.5- константа, используемая для того, чтобы значение параметраforce_failover_timeoutгарантированно было большеttl + 2*loop_wait. -
disk_check_tablespaces_count- определяет максимально возможное число табличных пространств, для которых может быть включена проверка, значение по умолчанию 128.
Отключение функциональности
Для отключения функциональности:
-
В файле конфигурации Pangolin Manager (
/etc/pangolin-manager/postgres.yaml) измените строку:enable_filesystem_checker:'True'На строку:
enable_filesystem_checker:'False' -
Выполните команды:
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml reload clustername
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml restart clusternameили
reload --force
restart --force
Резервирование подключений для ролей
Резервирование подключений для ролей доступно только для редакций Enterprise и Enterprise для ERP-систем.
В Pangolin реализована возможность резервирования количества доступных подключений для ролей, как индивидуально, так и по признаку вхождения в групповую роль. Это гарантирует пользователю наличие свободных подключений к БД в любое время.
Настроить резервирование соединения можно индивидуально или для группы ролей. При этом редактируются разные файлы:
- для конфигурации
standalone— файлpg_quota.conf. После редактирования файла требуется выполнить перезагрузку БД; - для конфигурации
cluster— настройка резервирования соединений осуществляется через файл/etc/pangolin-manager/postgresql.yml. После редактирования файла требуется выполнить перезагрузку БД и Pangolin Manager.
Пустые строки в файле pg_quota.conf игнорируются, как и любой текст комментария после значка #. Записи не продолжаются на следующей строке.
Записи начинаются с имени роли (role_name), за которой через пробел и/или tabs следует хотя бы одно поле в формате ключ=значение (поле reserved_connections).
В open source версии PostgreSQL отсутствует возможность резервирования подключений для пользователей, не являющихся superuser. Это приводит к проблеме - нет возможности получить соединение к БД, когда все свободные подключения к БД заняты и пользователь не superuser.
В СУБД Pangolin реализована возможность резервировать для ролей количество доступных подключений как индивидуально, так и по признаку вхождения в групповую роль. Это гарантирует пользователю наличие свободных подключений к БД в любое время.
В каждой БД создается файл pg_quota.conf. Файл содержит записи для ролей, требующих зарезервировать соединения.
Файл pg_quota.conf не синхронизируется с репликой средствами оркестратора Pangolin Manager. Файл pg_quota.conf содержится в копии БД, полученной pg_basebackup или pg_probackup.
Примечание:
Если записей несколько и квота есть для каждой роли, то берется квота первой записи для конкретной аутентифицирующейся роли.
Файл pg_quota.conf создается командой initdb при инициализации каталога с данными. Однако его можно разместить в любом другом месте, используя конфигурационный параметр quota_file. Файл pg_quota.conf считывается только при запуске системы.
Внимание!
Файл
pg_quota.confне считывается при получении сигнала SIGHUP, так как нет возможности перераспределить уже открытые соединения под новые квоты.
Редактировать файл могут администраторы БД. Файл не является обязательным. Если он не задан или отсутствует, используются лимиты для superuser (если роль superuser) и/или лимиты из общего пула — при этом работает стандартный механизм выдачи подключений.
Пример файла pg_quota.conf:
user reserved_connections=3
+db_admin reserved_connections=5
Примечание:
Файл не обязан содержать все роли, описанные в БД. Он может содержать только роли, для которых необходимо квотирование.
Для отключения функциональности требуется:
- для конфигурации
standalone— удалить файлpg_quota.confи перезапустить БД; - для конфигурации
cluster— удалить секциюpg_quotaв файле/etc/pangolin-manager/postgresql.ymlи выполнить перезагрузку БД и Pangolin Manager.
Поддержка функциональных пакетов Oracle для Pangolin (orafce)
Описание расширения
Расширение orafce представляет собой портирование части пакетов Oracle и функций по работе с данными. Использование этого расширения позволяет сократить время для миграции баз данных с Oracle на Pangolin.
Тем не менее, orafce принципиально не меняет модель работы с данными в Postgresql и не добавляет новых уровней поведения, не заложенных в модель Postgresql.
В частности:
- добавление «пакетов» Oracle не позволяет использовать переменные «пакета». Функциональный класс переменных отсутствует и не может быть портирован;
- портирована модель Oracle 10g1.
Добавление расширения
Выполните команду:
CREATE EXTENSION IF NOT EXISTS orafce;
Функциональность
Пакет dbms_alert
Пакет добавляет модель межсессионного взаимодействия.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Процедура | _signal | name::text, message::text | - | Internal |
| Триггер | deferred_signal | - | trigger | Internal |
| Процедура | register | name::text | - | Регистрация ipc c именем name |
| Процедура | remove | name::text | - | Удаление ipc с именем name |
| Процедура | removeall | - | - | Удаление всех ipc |
| Процедура | set_defaults | sensitivity::float8 | - | Определение sensitivity |
| Процедура | signal | event::text, _message::text | - | Регистрация сигнала для ipc event с сообщением _message |
| Функция | waitany | timeout::float8 | name::text, message::text, status::int | Ожидание сигналов в течение timeout сек |
| Функция | waitone | name::text, timeout::float8 | message::text, status::int | Ожидание сигнала в ipc name в течение timeout сек |
Пример использования:
| Сессия 1 | Сессия 2 | Сессия 3 | Комментарий |
|---|---|---|---|
| select dbms_alert.register('alert1'); | select dbms_alert.register('alert1'); | Регистрация очереди событий alert1 | |
| select * from dbms_alert.waitany(10); | select * from dbms_alert.waitany(10) | Ожидание событий в течение 10 секунд | |
| select dbms_alert.signal('alert1','Alert 1'); | Добавление события «Alert 1» в очереди alert1 |
Пакет dbms_assert
Пакет добавляет дополнительные проверки в целях защиты от SQL injection.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Функция | enquote_literal | str::varchar | ::varchar | Квотирование строки. Верификация двойного квотирования строки |
| Функция | enquote_name | str::varchar, [lowercase::bool] | ::varchar | Квотирование имени объекта sql. Опциональный параметр - приведение имени к нижнему регистру (ВНИМАНИЕ: поведение отличается от Oracle. В Oracle имя приводится к верхнему регистру) |
| Функция | noop | str::varchar | ::varchar | Функция-заглушка. Изменений не производится |
| Функция | qualified_sql_name | str::varchar | ::varchar | Проверка того, что входной параметр является правильным именем объекта sql |
| Функция | schema_name | str::varchar | ::varchar | Проверка существования в БД определенной схемы |
| Функция | simple_sql_name | str::varchar | ::varchar | Проверка применимости входного параметра для использования в качестве идентификатора sql |
| Функция | object_name | str::varchar | ::varchar | Проверка существования нефункционального объекта в БД с именем входного параметра |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| select dbms_assert.enquote_literal(E'O'Reilly'); | 'O''Reilly' |
| select dbms_assert.enquote_name(E'O'Reilly'); | "o'reilly" |
| select dbms_assert.enquote_name(E'O'Reilly',false); | "O'Reilly" |
| select dbms_assert.noop(E'O'Reilly'); | O'Reilly |
| select dbms_assert.qualified_sql_name(E'O'Reilly'); | ERROR: string is not qualified SQL name |
| select dbms_assert.qualified_sql_name(E'noop'); | noop |
| select dbms_assert.qualified_sql_name(E'noop1'); | noop1 |
| select dbms_assert.qualified_sql_name(E'1noop'); | 1noop |
| select dbms_assert.qualified_sql_name(E'noOP'); | noOP |
| select dbms_assert.schema_name(E'public'); | public |
| select dbms_assert.schema_name(E'noop'); | ERROR: invalid schema name |
| select dbms_assert.simple_sql_name(E'public'); | public |
| select dbms_assert.simple_sql_name(E'O'Reilly'); | ERROR: string is not simple SQL name |
| select dbms_assert.object_name(E'object_name'); | ERROR: invalid object name |
| select dbms_assert.object_name(E'information_schema'); | ERROR: invalid object name |
| select dbms_assert.object_name(E'pg_class'); | pg_class |
Пакет dbms_output
Пакет добавляет консольный вывод сообщений.
В Pangolin используется RAISE, однако поведение функций пакета отличается от принятого в Pangolin порядка выдачи сообщений тем, что функции пакета представляют собой очередь сообщений и могут быть прочитаны внутри сеанса.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Процедура | disable | - | - | Отключение вывода сообщений |
| Процедура | enable | [buffer_size::int] | - | Включение вывода сообщений. Опциональный параметр указывает размер буфера в байтах |
| Функция | get_line | - | line::text, status::int | Получение сообщений |
| Функция | get_lines | numlines::int | lines::text[],numlines::int | Получение блока последних сообщений |
| Процедура | new_line | - | - | Добавление нового пустого сообщения |
| Функция | put | a::text | - | Добавление нового сообщения (блок) |
| Функция | put_line | a::text | - | Добавление нового сообщения (строка) |
| Процедура | serveroutput | ::bool | - | Переключение вывода сообщений в консоль |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| select dbms_output.enable(); | |
| select dbms_output.put(E'One\nTwo'); | |
| select dbms_output.get_lines(2); | lines I numlines One+I1<br /> Two + I |
| select dbms_output.get_line(); | line I status I 1 |
| select dbms_output.put_line(E'One\nTwo'); | |
| select dbms_output.get_line(); | line I status One I 0 Two I |
| select dbms_output.serveroutput(true); | |
| select dbms_output.put(E'One\nTwo'); | |
| select dbms_output.get_line(); | line I status I 1 |
| select dbms_output.disable(); |
Пакет dbms_pipe
Пакет добавляет эмуляцию каналов Oracle. Реализация основана на использовании shared memory экземпляра:
- максимальное количество каналов - 50;
- длина канала определяется не в байтах, а в количестве элементов;
- возможна отправка сообщений без ожидания;
- возможна отправка пустых сообщений;
- тип timestamp для next_item_type = 13;
- Pangolin не поддерживает тип RAW. Используйте тип bytea.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Представление | db_pipes | - | name::varchar items::int4 size::int4 limit::int4 private::bool owner::varchar | Список каналов |
| Процедура | create_pipe | ::text, [::int4,[::bool]] | - | Создание канала. Передаваемые параметры: имя, размер, признак частного канала |
| Функция | next_item_type | - | ::int4 | Определение формата сообщения в канале: 0 - канал пуст; 9 - numeric/int4/int8; 11 - text; 12 - date; 13 - timestamptz; 23 - byte; 24 - record |
| Процедура | pack_message | ::bytea ::int4 ::int8 ::numeric ::text ::date ::timestamptz ::bytea ::record | - | Добавление сообщения в канал |
| Процедура | purge | ::text | - | Очистка канала. Параметр - имя канала |
| Функция | receive_message | ::text [::int4] | ::int4 | Прием сообщения. Копирование сообщения в локальный буфер. Параметры - имя канала, время ожидания в секундах, результат - код возврата: 0 - успех; 1 - тайм-аут; 2 - Ошибка: размер сообщения превышает размер буфера; 3 - Прерывание; ? - Недостаточно привилегий |
| Процедура | remove_pipe | ::text | - | Удаление канала. Параметр - имя канала |
| Процедура | reset_buffer | - | - | Очистка буфера |
| Функция | send_message | ::text[::int4 [::int4]] | ::int4 | Передача сообщения. Параметры: имя канала, тайм-аут в секундах, максимальный размер канала. Канал, созданный этой функцией, будет удален после передачи сообщения (в отличие от канала, созданного функцией create_pipe). Код возврата совпадает с кодами функции receive_message |
| Функция | unique_session_name | - | ::varchar | Возвращает уникальное имя сессии, в которой создан канал |
| Функция | unpack_message_bytea | - | ::bytea | Распаковка сообщения bytea |
| Функция | unpack_message_date | - | ::date | Распаковка сообщения date |
| Функция | unpack_message_number | - | ::numeric | Распаковка сообщения number |
| Функция | unpack_message_record | - | ::record | Распаковка сообщения record |
| Функция | unpack_message_timestamp | - | ::timestamptz | Распаковка сообщения timestamp |
| Функция | unpack_message_text | - | ::text | Распаковка сообщения text |
Пример использования:
| Сессия 1 | Сессия 2 | Комментарий |
|---|---|---|
| select dbms_pipe.create_pipe('pipe1',10,true); | Создание частного канала с именем pipe1 | |
| select * from dbms_pipe.db_pipes; | Список: name I items I size I limit I private I owner pipe1 I 0 I 0 I 10 I t I postgres | |
| select * from dbms_pipe.pack_message(timestamp 'epoch'+interval '2 days'); | ||
| select * from dbms_pipe.pack_message((date 'epoch'+interval '2 days')::date); | ||
| select * from dbms_pipe.pack_message(2::int4); | ||
| select * from dbms_pipe.pack_message(2::int8); | ||
| select * from dbms_pipe.pack_message(2::numeric); | ||
| select * from dbms_pipe.pack_message(2::text); | ||
| select * from dbms_pipe.send_message('pipe1',20,0); | Вывод кода возврата: 0 | |
| select dbms_pipe.receive_message('pipe1',1); | Вывод кода возврата: 0 | |
| select dbms_pipe.next_item_type(); | Вывод 13 (timestamp) | |
| select dbms_pipe.unpack_message_timestamp(); | Вывод 1970-01-03 00:00:00+03 (для временной зоны MSK) | |
| select dbms_pipe.next_item_type(); | Вывод 12 (date) | |
| select dbms_pipe.unpack_message_timestamp(); | ERROR: datatype mismatch | |
| select dbms_pipe.unpack_message_date(); | Вывод: 1970-01-03 | |
| select dbms_pipe.next_item_type(); | Вывод: 9 (number) | |
| select dbms_pipe.unpack_message_number(); | Вывод: 2 | |
| select dbms_pipe.next_item_type(); | Вывод 9 (number) | |
| select dbms_pipe.unpack_message_number(); | Вывод: 2 | |
| select dbms_pipe.next_item_type(); | Вывод 9 (number) | |
| select dbms_pipe.unpack_message_number(); | Вывод: 2 | |
| select dbms_pipe.next_item_type(); | Вывод 11 (text) | |
| select dbms_pipe.unpack_message_text(); | Вывод: 2 | |
| select dbms_pipe.next_item_type(); | Вывод: 0 (конец канала) | |
| select * from dbms_pipe.remove_pipe('pipe1'); |
Пакет dbms_random
Пакет добавляет генерацию псевдослучайных чисел Oracle.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Процедура | initialize | ::int4 | - | Инициализация генератора псевдослучайных чисел c заданным зерном (seed) |
| Функция | normal | - | ::float | Генерация числа в нормальном распределении |
| Функция | random | - | ::int4 | Генерация числа в полном диапазоне int4 (-231..231) |
| Процедура | seed | ::int4 | - | Передача зерна (seed) генератору |
| Процедура | seed | ::text | - | Передача зерна (seed) генератору |
| Функция | string | opt::text, len::int4 | text | Генерация случайной строки длиной len. Параметры: 'u','U' - UPPERCASE ALPHA 'l','L' - lowercase alpha 'a','A' - MiXeD AlPhA 'x','X', UPPERCASE ALPHANUMERIC 'p','P' - Anu printable characters |
| Процедура | terminate | - | - | Окончание работы пакета |
| Функция | value | [ low::float, high::float] | - | Генерация псевдослучайного номера из диапазона [low,high) |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| select dbms_random.initialize(ceil(random*1000)::int4); | - |
| select dbms_random.normal(); | 0.699305225607144 |
| select dbms_random.normal(); | -2.494277780294369 |
| select dbms_random.string('u',10); | VZXJBVROZM |
| select dbms_random.string('l',10); | snkzvijoaj |
| select dbms_random.string('a',15); | rntZKQhoQjoHfob |
| select dbms_random.string('x',10); | 530P36FNKE |
| select dbms_random.string('p',15); | .Vs4B='t#lZj@ww |
| select dbms_random.value(-10,10); | 3.7091398146003485 |
| select dbms_random.terminate(); | - |
Пакет dbms_utility
Пакет добавляет просмотр стека вызовов.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Функция | format_call_stack | [ ::text ] | text | Возвращает стек вызовов внутри блока pl/pgsql |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| do $$ declare res text; begin select dbms_utility.format_call_stack() into res; raise notice 'Call stack: %',res; end $$; | Call stack ---- PL/pgSQL Call Stack ----- object line object handle number name 0 0 function anonymous object 0 0 function anonymous object |
Пакет utl_file
Пакет добавляет операции с файловой системой.
В каждой сессии допускается до 10 открытых файловых дескрипторов. Длина строки ограничена 32Кб.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Таблица | utl_file_dir | dir::text dirname::text | - | Таблица псевдонимов |
| Домен | file_type | file_type::integer | - | Домен для хранения файлового дескриптора |
| Функция | fclose | file::utl_file.file_type | ::utl_file.file_type | Закрытие файлового дескриптора |
| Процедура | fclose_all | - | - | Закрытие всех открытых файловых дескрипторов |
| Процедура | fcopy | src_location::text src_filename::text dest_location::text dest_filename::text [ start_line::int4 ] [[ end_line::int4]] | - | Копирование файла. Передаваемые параметры: - исходный каталог - исходное имя файла - каталог назначения - имя файла назначения Опционально: - начальная строка - конечная строка |
| Процедура | fflush | file::utl_file.file_type | - | Сброс буфера на диск |
| Функция | fgetattr | location::text filename::text | fexist::boolean file_length::bigint block size::int4 | Получение атрибутов файла |
| Функция | fopen | location::text filename::text open_mode::text [ max_linesize::int4 ] [[ encoding::name ]] | ::utl_file.file_type | Открытие файлового дескриптора. Параметр open_mode стандартный('r','rw','a',...) |
| Процедура | fremove | location::text filename::text | - | Удаление файла |
| Процедура | frename | location::text filename::text [ dest_dir::text ] [ dest_file::text ] [[ overwrite::bool ]] | - | Переименование/перемещение файла |
| Функция | get_line | file::utl_file.file_type len::int4 | buffer::text | Получение строки из открытого файла |
| Функция | get_nextline | file::utl_file.file_type | buffer::text | Получение строки из открытого файла |
| Функция | is_open | file::utl_file.file_type | ::boolean | Проверка корректности файлового дескриптора |
| Функция | new_line | file::utl_file.file_type [ lines::int4] | ::boolean | Добавление новой строки в открытый файл |
| Функция | put | file::utl_file.file_type (buffer::text I buffer::anyelement ) | ::boolean | Добавление записи в файл |
| Функция | put_line | file::utl_file.file_type (buffer::text I buffer::anyelement ) [ autoflush::boolean ] | ::boolean | Добавление новой строки в открытый файл |
| Функция | putf | file::utl_file.file_type format::text [ arg1::text ] [[ arg2::text ]] [[[ arg3::text ]]] [[[[ arg4::text ]]]] [[[[[ arg5::text ]]]]] | ::boolean | Форматированный вывод в открытый файл |
| Функция | tmpdir | - | ::text | Вывод значения системной переменной $TEMP |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| INSERT INTO utl_file.utl_file_dir(dir,dirname) VALUES ('temp','/tmp') | |
| COPY (SELECT * FROM pg_settings) TO '/tmp/pg_settings.csv'; | |
| do $$ declare f utl_file.file_type; begin if (select fexists from utl_file.fgetattr('temp','pg_settings.csv')) then f := utl_file.fopen('temp', 'pg_settings.csv', 'r'); readl loop begin raise notice '%', utl_file.get_line(f); exception when no_data_found then exit readl; end; end loop; f := utl_file.fclose(f); end if; end; $$; | Содержимое файла /tmp/pg_settings.csv |
| SELECT utl_file.fremove('temp','pg_settings.csv'); | |
| SELECT utl_file.fclose_all(); |
Пакет plunit
Пакет добавляет функции проверок.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Процедура | assert_equals | expected::anyelement actual::anyelement [ message::varchar] | - | Проверка условия expected = actual |
| Процедура | assert_equals | expected::float8 actual::float8 range::float8 [ message::varchar] | - | Проверка условия expected=actual в пределах range |
| Процедура | assert_false | condition::bool [ message::varchar] | - | Проверка логического условия FALSE |
| Процедура | assert_true | condition::bool [ message::varchar] | - | Проверка логического условия TRUE |
| Процедура | assert_not_equals | expected::anyelement actual::anyelement [ message::varchar] | - | Проверка условия expected != actual |
| Процедура | assert_not_equals | expected::float8 actual::float8 range::float8 [ message::varchar] | - | Проверка условия expected != actual в пределах range |
| Продедура | assert_not_null | actual::anyelement [ message::varchar] | - | Проверка входного параметра на присутствие значения (NOT NULL) |
| Продедура | assert_null | actual::anyelement [ message::varchar] | - | Проверка входного параметра на отсутствие значения (IS NULL) |
| Продедура | fail | [ message::varchar] | - | Безусловный возврат с ошибкой |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| select plant.assert_equals(clock_timestamp(),current_timestamp,'Failed'); | ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_equals) |
| select plant.assert_equals(clock_timestamp()::date,current_timestamp::date,'Failed'); | - |
| select plant.assert_not_equals(clock_timestamp(),current_timestamp,'Failed'); | - |
| select plant.assert_not_equals(clock_timestamp()::date,current_timestamp::date,'Failed'); | ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_not_equals) |
| select plant.assert_false(clock_timestamp()::date=current_timestamp::date,'Failed'); | ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_false) |
| select plant.assert_true(clock_timestamp()=current_timestamp,'Failed'); | ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_true) |
| select plant.assert_not_null(clock_timestamp,'Failed'); | - |
| select plant.assert_null(clock_timestamp,'Failed'); | ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_null) |
| select plant.fail('Failed'); | ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_fail) |
Пакет plvchr
Пакет добавляет специфичные для Oracle функции для работы с текстом.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Функция | _is_kind | str::text,kind::int4 c::int4, kind::int4 | boolean | Базовая функция для is_% функций |
| Функция | char_name | c::text | varchar | Возвращает код символа в кодировке ASCII |
| Функция | first | str::text | varchar | Возвращает первый символ в строке |
| Функция | last | str::text | varchar | Возвращает последний символ в строке |
| Функция | nth | str::text, n::int4 | text | Возвращает n-ый символ в строке |
| Функция | quoted1 | str::text | varchar | Возвращает текст, заключенный в апострофы |
| Функция | quoted2 | str::text | varchar | Возвращает текст, заключенный в кавычки |
| Функция | stripped | str::text char_in::text | varchar | Удаляет символы подстроки char_in из str с учетом регистра символов |
| Функция | is_blank | str::text c::int4 | boolean | Проверяет значения параметра на заполненность |
| Функция | is_digit | str::text c::int4 | boolean | Проверяет значения параметра на цифровой формат |
| Функция | is_letter | str::text c::int4 | boolean | Проверяет значения параметра на текстовый формат |
| Функция | is_other | str::text c::int4 | boolean | Проверяет значения параметра на несоответствие ни цифровому, ни текстовому формату |
| Функция | is_quote | str::text c::int4 | boolean | Проверяет значения текстового параметра на квотирование (кавычки или апострофы) |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| select plvchr.char_name('Pangolin'); | P |
| select plvchr.first('Pangolin'); | P |
| select plvchr.last('Pangolin'); | n |
| select plvchr.nth('Pangolin',2); | a |
| select plvchr.nth('Pangolin',-2); | i |
| select plvchr.quoted1('Pangolin'); | 'Pangolin' |
| select plvchr.quoted2('Pangolin'); | "Pangolin" |
| select plvchr.quoted('Pangolin','Pango'); | li |
| select plvchr.quoted('Pangolin','pango'); | Pli |
| select plvchr.is_blank('Pangolin'); | false |
| select plvchr.is_digit('Pangolin'); | false |
| select plvchr.is_letter('Pangolin'); | true |
| select plvchr.is_other('Pangolin'); | false |
| select plvchr.is_quote('Pangolin'); | false |
| select plvchr.is_quote('''Pangolin"'); | true |
Пакет plvdate
Пакет добавляет специфичные для Oracle функции для работы с датами.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Функция | add_bizdays | ::date, ::int4 | date | Получение рабочей даты, спустя <n> рабочих дней от заданной |
| Функция | bizdays_between | ::date, ::date | int4 | Количество рабочих дней между двумя датами |
| Функция | days_inmonth | ::date | int4 | Количество дней в месяце |
| Процедура | default_holidays | ::text | - | Загрузка рабочего календаря. Принимаемые конфигурации: Czech German Austria Poland Slovakia Russia GB USA |
| Функция | include_start | [ ::boolean ] | boolean | Включение первой даты в расчет |
| Функция | noinclude_start | - | boolean | Исключение первой даты из расчета |
| Функция | isbizday | ::date | boolean | Является ли дата рабочим днем |
| Функция | isleapyear | ::date | boolean | Является ли год високосным |
| Функция | nearest_bizday | ::date | date | Ближайший рабочий день для даты |
| Функция | next_bizday | ::date | date | Следующий рабочий день |
| Функция | prev_bizday | ::date | date | Предыдущий рабочий день |
| Функция | set_nonbizday | ::date | boolean | Определение нерабочего дня. Возвращаемый параметр - рекурсия (каждый год) |
| Процедура | set_nonbizday | ::text ::date, ::boolean | - | Задать день недели как нерабочий Задать день как нерабочий. Второй параметр - рекурсия (каждый год) |
| Функция | unset_nonbizday | ::date | boolean | Определение рабочего дня. Возвращаемый параметр - рекурсия (каждый год) |
| Процедура | unset_nonbizday | ::text ::date, ::boolean | - | Задать день недели как рабочий Задать день как рабочий. Второй параметр - рекурсия (каждый год) |
| Функция | use_easter | - | boolean | Задать Пасху как нерабочий день. Возвращаемый параметр - рекурсия (каждый год) |
| Процедура | use_easter | ::boolean | - | Задать Пасху как нерабочий день |
| Функция | unuse_easter | - | boolean | Задать Пасху как рабочий день. Возвращаемый параметр - рекурсия (каждый год) |
| Процедура | unuse_easter | ::boolean | - | Задать Пасху как рабочий день |
| Функция | use_great_friday | - | boolean | Задать Страстную пятницу как нерабочий день. Возвращаемый параметр - рекурсия (каждый год) |
| Процедура | use_great_friday | ::boolean | - | Задать Страстную пятницу как нерабочий день |
| Функция | using_easter | - | boolean | Проверка, является ли Пасха рабочим днем |
| Функция | using_great_friday | - | boolean | Проверка, является ли Страстная пятница рабочим днем |
| Функция | version | - | cstring | Версия схемы |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| select plvdate.default_holidays('Russia'); | |
| select plvdate.isleapyear('2020-01-01'); | true |
| select plvdate.isleapyear('2021-01-01'); | false |
| select plvdate.isbizday('2021-03-08'); | false |
| select plvdate.isbizday('2021-02-22'); | true |
| select plvdate.add_bizdays('2021-02-22',15); | 2021-03-17 |
| select plvdate.bizdays_between('2021-04-30','2021-05-10'); | 6 |
| select plvdate.days_inmonth('2021-02-22'); | 28 |
| select plvdate.nearest_bizday('2021-02-22'); | 2021-02-24 |
| select plvdate.next_bizday('2021-02-22'); | 2021-02-24 |
| select plvdate.prev_bizday('2021-02-22'); | 2021-02-19 |
| select plvdate.set_nonbizday('2021-02-22',false); | |
| select plvdate.unset_nonbizday('2021-02-20',false); | ОШИБКА: 42704: nonbizday unregisteration error ПОДРОБНОСТИ: Nonbizday not found. |
| select plvdate.using_easter(); | false |
| select plvdate.using_greater_friday(); | false |
| select plvdate.version(); | PostgreSQL PLVdate, version 3.7, October 2018 |
Пакет plvlex
Пакет основан на оригинальном PL/Vision LEXical analysis и добавляет специфичные для Oracle функции для работы с лексемами.
Внимание!
Данный пакет основан на ключевых словах Postgresql и не является полностью совместимым с Oracle.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Функция | tokens | str::text, skip_spaces::boolean, qualified_names::boolean | SETOF record pos::integer token::text code::int4 class::text separator::text mod::text | Лексический анализатор. Возвращаемые параметры: - pos: позиция лексемы - token: лексема - code: для лексем, являющихся ключевыми словами и идентификаторами PG SE - ссылка на порядковый номер в классе; - class: класс лексемы - separator: разделитель mod: модификатор |
Пример использования. Сессия 1:
select * from plvlex.tokens('SELECT n.nspname AS schemaname, c.relname AS viewname, pg_get_userbyid(c.relowner) AS viewowner, pg_get_viewdef(c.oid) AS definition FROM pg_class c LEFT JOIN pg_namespace n ON n.oid = c.relnamespace WHERE c.relkind = ''v''::"char";',true,true)
Результат выполнения:
pos I token I code I class I separator I mod
0 I select I 613 I KEYWORD I I
7 I n.nspname I I IDENT I I I
17 I as I 292 I KEYWORD I I I
20 I schemaname I I IDENT I I I
30 I, I 44 I OTHERS I I self I
36 I c.relname I I IDENT I I I
46 I as I 292 I KEYWORD I I I
49 I viewname I I IDENT I I I
57 I, I 44 I OTHERS I I self I
63 I pg_get_userbyid I I IDENT I I I
78 I ( I 40 I OTHERS I I self I
79 I c.relowner I I IDENT I I I
89 I) I 41 I OTHERS I I self I
91 I as I 292 I KEYWORD I I I
94 I viewowner I I IDENT I I I
103 I, I 44 I OTHERS I I self I
109 I pg_get_viewdef I IIDENT I I I
123 I ( I 40 I OTHERS I I self I
124 I c.oid I I IDENT I I I
129 I ) I 41 I OTHERS I I self I
131 I as I 292 I KEYWORD I I I
134 I definition I I IDENT I I I
148 I from I 421 I KEYWORD I I I
153 I pg_class I I IDENT I I I
162 I c I I IDENT I I I
169 I left I 480 I KEYWORD I I I
174 I join I 470 I KEYWORD I I I
179 I pg_namespace I I IDENT I I I
192 I n I I IDENT I I I
194 I on I 533 I KEYWORD I I I
197 I n.oid I I IDENT I I I
203 I = I 61 I OTHERS I I self I
205 I c.relnamespace I I IDENT I I I
222 I where I 701 I KEYWORD I I I
228 I c.relkind I I IDENT I I I
238 I = I 61 I OTHERS I I self I
240 I v I I SCONST I I qs I
243 I v I 267 I OTHERS I I typecast I
245 I char I I IDENT I I dq I
251 I ; I 59 I OTHERS I I self I
Пакет plvstr
Пакет добавляет специфичные для Oracle функции для работы со строками и текстовыми данными.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Функция | betwn | str::text,start::int4,_end::int4[,inclusive:boolean] str::text,start::text,_end::text[,startnth::int4,endth::int4[,inclusive::boolean,gotoend::boolean]] | text | Производит поиск подстроки в пределах от start до _end символа |
| Функция | instr | str::text,patt::text[,start::int4[,nth::int4]] | int4 | Производит поиск позиции подстроки |
| Функция | is_prefix | str::int8,prefix::int8 str::int4,prefix::int4 str::text,prefix::text[,cs::boolean] | boolean | Производит проверку: начинается ли искомая строка с определенного префикса |
| Функция | left | str::text,n::int4 | varchar | Возвращает n символов с начала строки |
| Функция | right | str::text,n::int4 | varchar | Возвращает n символов с конца строки |
| Функция | lpart | str::text,div::text[,start::int4[,nth::int4[,allifnotfound::boolean]]] | text | Возвращает подстроку, находящуюся до строки поиска |
| Функция | rpart | str::text,div::text[,start::int4[,nth::int4[,allifnotfound::boolean]]] | text | Возвращает подстроку, находящуюся после первого символа строки поиска |
| Функция | lstrip | str::text,substr::text[,num::int4] | text | Усекает строку слева, если строка начинается с поисковой строки |
| Функция | rstrip | str::text,substr::text[,num::int4] | text | Усекает строку справа, если строка заканчивается на поисковую строку |
| Функция | rvrs | str::text,start::int4[,_end::int4] | text | Выставляет в обратном порядке символы в строке |
| Функция | substr | str::text,start::int4[,len::int4] | varchar | Возвращает подстроку, начиная с позиции start (и длиной len) |
| Функция | swap | str::text,replace::text[,start::int4,length::int4] | text | Производит поиск и замену подстроки replace в строке (начиная с позиции start, длиной length) |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| select plvstr.betwn('Pangolin','go','i') | goli |
| select plvstr.instr('Pangolin','go') | 4 |
| select plvstr.is_prefix('Pangolin','Pan') | true |
| select plvstr.is_prefix('Pangolin','pan') | false |
| select plvstr.left('Pangolin',5) | Pango |
| select plvstr.right('Pangolin',5) | golin |
| select plvstr.lpart('Pangolin','go') | Pan |
| select plvstr.rpart('Pangolin','go') | olin |
| select plvstr.lstrip('Pangolin','go') | Pangolin |
| select plvstr.lstrip('Pangolin','Pan') | golin |
| select plvstr.rstrip('Pangolin','lin') | Pango |
| select plvstr.rvrs('Pangolin') | nilgonaP |
| select plvstr.substr('Pangolin',5) | olin |
| select plvstr.swap('Pangolin','go') | gongolin |
Пакет plvsubst
Пакет добавляет специфичные для Oracle функции форматирования текста.
Объекты схемы:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Процедура | setsubst | [ str::text] | - | Задать маску поиска. Маска по умолчанию - '%s' |
| Функция | subst | - | text | Получить маску поиска |
| Функция | string | template_in::text[,vals_in::text[,delim_in::text[,substr-in::text]]] template_in::text[,values_in::text[][,subst::text]] | text | Применение форматирования по шаблону |
Пример использования:
| Сессия 1 | Результат выполнения |
|---|---|
| select plvsubst.string('%s codename %s','Postgresql,Pangolin'); | Postgresql codename Pangolin |
| select plvsubst.string('%s codename %s',ARRAY['Postgresql','Pangolin']); | Postgresql codename Pangolin |
| select plvsubst.subst(); | %s |
Изменения уровня базы данных
Новые обьекты:
| Тип | Имя | Входные переменные функции | Выходные переменные функции | Описание |
|---|---|---|---|---|
| Представление | dual | - | dummy::varchar | Специфичное для Oracle представление, необходимое для поддержки стандарта SQL |
| Тип | dummy | - | - | |
| Тип | varchar2 | - | - | Специфичный для Oracle тип текстовых данных (single-byte) |
| Тип | nvarchar2 | - | - | Специфичный для Oracle тип текстовых данных (multi-byte) |
Расширение btree_gin
С информацией о расширении btree_gist можно ознакомиться в одноименном разделе расширения btree_gist документа «Описание расширений продукта СУБД Pangolin».
Расширение btree_gist
С информацией о расширении btree_gist можно ознакомиться в одноименном разделе расширения btree_gist документа «Описание расширений продукта СУБД Pangolin».
Переход на поставку компонентов Pangolin в виде RPM-пакетов
Был реализован переход на использование пакетной установки для компонентов:
- Pangolin Pooler;
- Pangolin Manager;
- Pangolin Backup tools.
Подробнее о поставляемых rpm/deb-пакетах в разделе «Описание поставляемых rpm/deb-пакетов» документа «Руководство по установке».
Контроль потребления ресурсов БД (оперативная память и ЦП)
Функциональность реализована в виде расширения psql_resources_consumption_limits, позволяет ограничивать потребление ресурсов: оперативной памяти и CPU, с помощью процессов СУБД.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Внимание!
Процессы расширений ограничены в соответствии с установленными лимитами (включая задания
pg_cronи т.п.).
В Pangolin поддерживается:
- функциональность фиксированного задания ограничений ресурсов для процессов сессий СУБД;
- завершение с ошибкой сессии, превысившей ограничение на потребление ресурса, и всех ее подпроцессов;
- обнаружение превышения квоты на ресурсы асинхронно.
Примечание:
Управление ограничениями на уровне отдельной сессии не поддерживается.
Схема процесса
Процесс первоначальной настройки и изменения настройки квотирования ресурсов:
Включение функциональности на запущенном кластере Pangolin
Включение функциональности происходит при активации расширения psql_resources_consumption_limits. С процессом включения и отключения функциональности можно ознакомиться в документе «Описание расширений продукта СУБД Pangolin» разделе соответствующего расширения.
Настройка фиксированных ограничений
О параметрах предоставляемых для данной функциональности читайте в документе «Описание расширений продукта СУБД Pangolin» разделе расширения psql_resources_consumption_limits.
Примеры настройки параметров
Сценарий 1 – потребление ресурсов ограничено для выбранных ролей, для остальных ролей потребление ресурсов не ограничено:
- Задан нулевой параметр
mem_limit(илиcpu_limit) в конфигурации или с помощьюALTER SYSTEM SET(проверка для всех ролей отключена). - Заданы ненулевые параметры
mem_limit(илиcpu_limit) для выбранных ролей с помощьюALTER ROLE ... SET name=value;(проверка для отдельных ролей включена).
Сценарий 2 – потребление ресурсов не ограничено для выбранных ролей, для остальных ролей потребление ресурсов ограничено:
- Задан ненулевой параметр
mem_limit(илиcpu_limit) в конфигурации или с помощьюALTER SYSTEM SET(проверка для всех ролей включена). - Заданы нулевые параметры
mem_limit(илиcpu_limit) для выбранных ролей с помощьюALTER ROLE ... SET name=value;(проверка для отдельных ролей выключена).
Асинхронный поиск превышения лимитов
Контроль превышения лимитов реализуется в отдельном процессе.
Процесс запускается всегда, не зависимо от того, включен ли контроль за ресурсами или нет. Если контроль ни за одним ресурсов не включен, то процесс находится в ожидании. По SIGHUP процесс перечитывает конфигурационные параметры и, если контроль хотя бы за одним из ресурсов был включен, то процесс начинает периодическую проверку превышения лимитов.
Внимание!
Если контролируемый процесс превысит лимит внутри интервала контроля, но на момент проверки лимиты превышены не будут, то это превышение пройдет незамеченным для контролирующего процесса
Параллельное выполнение запросов
При порождении процессом сессии СУБД подпроцессов параллельного выполнения запросов или подпроцессов фонового выполнения (parallel worker или background worker) суммарное потребление ресурсов такой сессией и ее подпроцессами не может превысить заданное ограничение на сессию.
Потребление памяти одной сессией
Лимит учитывает только RSS-память процесса.
Значение RSS для процесса вычисляется по полю resident [количество страниц памяти RSS] внутри файла /proc/<pid>/statm. Чтобы перевести значение в байты resident умножается на sysconf(_SC_PAGESIZE) [Кб].
Считывается потребление резидентной памяти для каждого процесса сессии по pid, затем вычисляется суммарное потребление для сессии.
Потребление CPU одним процессом сессии
Потребление CPU процессом вычисляется по изменению полей utime, stime [clock ticks] внутри файла /proc/<pid>/stat со времени последнего измерения. Для этого на каждой итерации в памяти сохраняются поля utime, stime и время измерения, которые будут использоваться для вычисления процента потребления CPU на следующей итерации:
(((current utime + current stime) - (saved utime + saved stime)) / sysconf(_SC_CLK_TCK)) * 100 / (текущее время - время прошлого измерения)
Примечание:
sysconf(_SC_CLK_TCK) - функция, возвращающая количество тактов процессора в одной секунде.
Потребление CPU считывается для каждого процесса сессии по pid, затем вычисляется суммарное потребление для сессии.
Остановка процессов сессии
При превышении сессией установленных лимитов все ее процессы останавливаются сигналом SIGTERM.
Получение данных о потреблении ресурсов по процессам сессии
Данные о потреблении ресурсов процессами отображаются в новом представлении psql_resources_consumption_limits.consumption.
Права доступа pg_read_all_stats.
Представление содержит поля:
session_id– идентификатор сессии;proc_id– идентификатор процесса;role_id– идентификатор роли;rolname– имя роли;log_level– уровень лога для сообщений о превышении лимитов;mem_current– текущее потребление памяти процессом;mem_current_session– текущее потребление памяти сессией;mem_max– максимальное потребление памяти процессом за все время контроля;mem_max_session– максимальное потребление памяти сессией за все время контроля;mem_limit– заданное для сессии ограничение по памяти;mem_reaction– заданная для сессии реакция на превышение ограничения по памяти;cpu_current– текущее потребление CPU процессом;cpu_current_session– текущее потребление CPU сессией;cpu_max– максимальное потребление CPU процессом за все время контроля;cpu_max_session– максимальное потребление CPU сессией за все время контроля;cpu_limit– заданное для сессии ограничение по CPU;cpu_reaction– заданная для сессии реакция на превышение ограничения по CPU.
Контроль системных процессов
Контроль потребления ресурсов не производится для системных процессов Pangolin (в том числе для процессов потоковой и логической репликации).
Трассировка сессии
СУБД Pangolin предоставляет механизм трассировки (включения/выключения отладочной печати) с различными уровнями детализации. Суперпользователь может использовать этот механизм для любой сессии, в рамках которой действие не запрещено правилами защиты от действий привилегированного пользователя.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Трассировка записывается на сервере СУБД в файл, путь к которому указывается в значении параметра сервера, а имя либо формируется по умолчанию из PID серверного процесса и уникального идентификатора, либо задается перед включением трассировки параметром на уровне сессии.
Содержание файла трассировки:
- заголовок;
- строка-описание для каждого из запросов;
- строка-описание для каждой из фаз жизненного цикла запроса;
- переменные привязки;
-
- ожидания (по каждому из одиночных событий ожидания, в том числе блокировок);
- предварительный план по операциям (переносится в файл во время полного закрытия курсора успехом или ошибкой);
- реальный план выполнения по операциям (переносится в файл во время полного закрытия курсора успехом или ошибкой);
- ошибка при разборе или выполнении запроса;
- диагностика и стек вызовов для исключений PL/pgSQL.
По умолчанию файл трассировки имеет имя вида: <PID>_<YYYYMMDDHHMISS>, где PID - pid процесса сессии, YYYYMMDDHHMISS - временная метка начала формирования файла трассировки во временной зоне сервера СУБД (с точностью до секунд).
Файл трассировки параллельных процессов, порождаемых трассируемой сессией, имеет формат имени <SESSION_FILE_NAME>_parallel, где SESSION_FILE_NAME - имя файла родительской трассировки для данных процессов. Все трассировки параллельных процессов сохраняются в один файл, но в процессе их формирования для каждого из процессов будет создаваться свой файл с именем <SESSION_FILE_NAME>_<WORKER_PID>_<WORKER_YYYYMMDDHHMISS>, где SESSION_FILE_NAME - имя файла родительской трассировки, WORKER_PID - PID параллельного процесса, WORKER_YYYYMMDDHHMISS - временная метка начала формирования файла трассировки параллельного процесса во временной зоне сервера СУБД (с точностью до секунд).
Виды запросов, для которых фиксируется вышеуказанная информация:
- одинарные запросы;
PL/pgSQL-запросы;- многострочные запросы;
- динамические запросы, выполняемые через
PL/pgSQL; - подготовленные запросы, выполняемые через SQL-инструкции
PREPARE,EXECUTE,DECLARE CURSORиFETCH; - подготовленные запросы, выполняемые через расширенный протокол;
- запросы, выполняемые расширениями и триггерами через
SPI; - многострочные запросы с конструкциями
SAVEPOINTиCOMMIT/ROLLBACK TO SAVEPOINT; - иерархически организованные запросы (например, запросы, выполняемые функциями расширений в процессе выполнения запросов, или динамические запросы из
PL/pgSQL). Запросы организуются в иерархическую структуру, позволяющую определить их взаимное отношение.
Уровни трассировки
Поддерживаются следующие уровни трассировки, комбинируемые через логическое ИЛИ:
NONE - значение 0, отсутствие трассировки сессии;
BASE - значение 1, базовая трассировка;
BIND - значение 2, добавляет вывод переменных привязки;
LOCK - значение 4, добавляет вывод информации о блокировках, как LWLock, так и Lock;
RESOURCE - значение 8, добавляет вывод информации о потребляемых всеми операциями ресурсах.
Примечание:
Изменить уровень трассировки для сессии с уже установленным уровнем трассировки возможно только через остановку трассировки сессии (то есть установить уровень трассировки
NONE)с последующим включением трассировки уже с обновленным уровнем. Это необходимо для явного разделения файлов трассировки по уровням. При указании того же имени файла, которое использовалось ранее, будет возвращено сообщение об ошибке, так как файл уже существует.
Параметры настройки
| Имя параметра | Тип | Значение по умолчанию | Допустимые значения | Комментарий |
|---|---|---|---|---|
session_tracing_enable | bool | false | false/true | При включении параметра начинается накопление информации по текущему выполняемому запросу в т.ч. при отсутствии включенной для сессии трассировки). Это необходимо для ее последующего сброса при включении трассировки в середине выполнения запроса. При выключении исключается влияние функциональности на производительность |
session_tracing_default_level | integer | 0 | 0..15 | Уровень трассировки по умолчанию, работает в комбинации с параметром session_tracing_role. Комбинация уровней трассировки через логическое ИЛИ |
session_tracing_file_limit | integer | -1 | -1..2147483647 | Максимальный размер файлов трассировки (в кБ). При значении -1 ограничения нет. При достижении файлом трассировки заданного лимита трассировка соответствующей сессии прекращается с выводом в лог сообщения: Session tracing file for process <PID> going to exceed size limit: <текущий размер>/<лимит>. The session's tracing will be stopped |
session_tracing_default_path | string | NULL | Любое | Путь к директории по умолчанию для сохранения файлов трассировки. При значении NULL используется директория ${PGDATA}/tracing. Значение параметра не валидируется при задании, только при попытке использования для формирования файлов трассировки |
session_tracing_roles | string | " " | Любое | Список имен пользователей, через запятую, для сессий которых автоматически должна устанавливаться трассировка с уровнем session_tracing_default_level, при уровне 0 трассировка выключается |
Изменять приведенные выше параметры может только роль с правами суперпользователя. После внесения изменения требуется перезапуск СУБД.
Включение функциональности выполняется только через изменение параметра session_tracing_enable. Это обусловлено необходимостью выделения ресурсов общей памяти для обслуживания функциональности.
Внимание!
Включение функциональности трассировки сессий через установку настроечного параметра
session_tracing_enableв значениеonможет привести к снижению производительности запросов. Это связано с необходимостью предварительной подготовки и накопления трассировочной информации по выполняемым запросам при включении трассировки сессии в процесс их выполнения.
Функции API
start_session_tracing
Входные параметры:
pid;- уровень трассировки;
- имя файла трассировки (
NULLили пустая строка).
Выходной результат:
Успешное завершение / ошибка.
Возвращаемых значений нет.
Поведение функции:
Функция включает трассировку для сессии с указанным PID, уровнем трассировки, и, опционально, именем файла. Если имя файла будет задано как NULL или пустой строкой, то будет сгенерировано имя файла трассировки по умолчанию.
При успешном включении трассировки в лог будет выведено следующее сообщение:
"Process <PID> is signaled tracing to ON with level <уровень трассирвоки> for filename "<путь к файлу трассировки>""
При выключенной функции трассировки выводится ошибка:
"Session tracing isn't enabled"
При заданном уровне трассировки 0 выводится сообщение:
"Cannot start session tracing for process <PID> with level 0"
При попытке включения трассировки для сессии с уже включенной трассировкой будет получено сообщение:
"Session tracing for process <PID> already set"
При отсутствии процесса с указанным PID, в том числе, когда сессией управляет не суперпользователь (или владелец), будет получено сообщение вида:
"No process with PID <PID> for a session tracing"
stop_session_tracing
Входные параметры:
pid.
Выходной результат:
Успешное завершение / ошибка.
Возвращаемых значений нет.
Поведение функции:
Функция выключает трассировку для сессии с указанным PID.
При успешном выключении трассировки в лог выводится сообщение:
"Process <PID> is signaled tracing to OFF"
При выключенной функции трассировки будет получена следующая ошибка:
"Session tracing isn't enabled"
При попытке включения трассировки для сессии с уже включенной трассировкой будет получена ошибка:
"Session tracing for process <PID> not set"
При отсутствии процесса с указанным PID, в том числе когда сессией управляет не суперпользователь (или пользователь, не являющийся владельцем), будет получено сообщение вида:
"No process with PID <PID> for a session tracing"
Примечание:
Для обращения к функциям трассировки
start_session_tracingиstop_session_tracingпользователю необходимо иметь привилегии суперпользователя или иметь рольpg_tracing.Для включения и выключения трассировки через вызов функций
start_session_tracingиstop_session_tracingна процесс сессии требуется либо наличие привилегий суперпользователя, либо необходимо являться владельцем процесса (то есть быть тем пользователем, который запустил процесс), либо иметь рольpg_read_all_tracing.
psql_session_tracing
Входные параметры:
pid(может бытьNULL).
Выходной результат:
Набор записей с полями:
- pid;
- перечисление текстовых представлений для уровней трассировки (например,
BASE | BIND | LOCK | RESOURCE); - путь к файлу трассировки сессии.
Поведение функции:
Выводит список сессий с указанием их уровня трассировки и путей к файлам трассировки.
Выводятся только те сессии, для которых текущий пользователь имеет права на роль, запустившую сессию.
Пользователь с ролью pg_read_all_stats или суперпользователь видит все сессии.
При выключенной функции трассировки будет выведена ошибка:
"Session tracing isn't enabled"
Утилита генерации отчета trace_decode
Утилита размещается в директории ${PGHOME}/bin/ и имеет следующие ключи запуска:
| Ключ запуска | Значения | Комментарий |
|---|---|---|
| -h, --help | Без значений | Вывод подсказки по работе утилиты |
| -a | Без значений | Формирование агрегированного отчета |
| -f | TEXT или HTML | Ключ может быть не указан, в таком случае будет использоваться формат HTML |
| -p | Путь к файлу трассировки | Для корректного формирования отчета, при наличии соответствующего файла трассировки параллельных процессов сессии он должен размещаться в той же директории, что и файл трассировки сессии |
Отчет выводится в консоль. Для его вывода в файл необходимо перенаправить вывод stdout в файл с требуемым именем.
Структура отчета
Основные блоки не агрегированного HTML-отчета:
- Заголовок отчета c информацией о процессе (в том числе о
postmaster-процессе), временах запуска и версии продукта и СУБД. - Уровень трассировки.
- Значения всех GUC-переменных.
- Блоки выполнения запросов.
- Информация о незавершенном запросе (при его наличии).
- Информация о незавершенном ожидании поступления запроса (при его наличии).
- Суммарная информация о содержимом файла трассировки.
В агрегированном отчете каждый уникальный запрос указывается один раз. Блок запроса содержит обобщенную информацию о выполнении запроса и его потреблении ресурсов за все время трассировки. Сортировка запросов в агрегированном отчете выполняется в порядке убывания суммарной длительности выполнения запроса. При равной длительности - в порядке убывания количества выполнений запроса.
В не агрегированном отчете запросы указываются каждый раз, когда происходило их выполнение. Блок запроса содержит агрегированную информацию о выполнении запроса и о потреблении им ресурсов за одну команду. Сортировка запросов в не агрегированном отчете выполняется в порядке их выполнения.
Далее будет подробно рассмотрен состав каждого из блоков отчета.
Блок информации о запросе
Подблоки:
-
Заголовок запроса, включая
queryId, текст запроса, значения параметровsession_user,current_role,search_pathиcurrent_schema. Также содержит временные метки начала и окончания выполнения запроса. При наличии в файле трассировки незавершенных запросов поле времени окончания запроса будет содержать значениеNot finished. -
Ошибка выполнения запроса. Опциональный, присутствует только при наличии ошибки. Содержит текст сообщения об ошибке и ее код.
-
Общая статистика выполнения запроса. Содержит информацию по количеству успешных выполнений запроса, откатов и ошибок. Также содержит информацию по количеству фаз выполнения запроса:
- общее количество вызовов запроса извне;
- обработка;
- анализ;
- перезапись;
- планирование;
- кеширование плана;
- связывание переменных;
- выполнение.
-
Информация о шагах выполнения. Для каждого шага приводится статистика по длительности его выполнения, и, при уровне трассировки
RESOURCE- о потреблении ресурсов. В агрегированном отчете приводится информация о минимальных, максимальных и суммарных временах выполнения фазы запроса, и потребленных ресурсах (при уровне трассировкиRESOURCE). -
Информация о легковесных блокировках (
LWLock). Отображается при уровне трассировкиLOCKи наличии таких блокировок во время выполнения запроса. Содержит агрегированную информацию о легковесных блокировках в порядке убывания суммарной длительности их ожидания и их количества. При уровне трассировкиRESOURCEпомимо длительности, содержит информацию о минимальном, максимальном и суммарном потреблении ресурсов процессом при ожидании блокировки. -
Информация о блокировках (
Locks). Отображается при уровне трассировкиLOCKи наличии таких блокировок во время выполнения запроса. Содержит агрегированную информацию о блокировках в порядке убывания суммарной длительности их ожидания и количества. -
Информация о порожденных запросах - содержит список всех запросов, для которых выполнялась хотя бы одна фаза в ходе выполнения текущего запроса. Формат идентичен формату описываемого блока запроса. Такие запросы могут возникать в ходе работы расширений, PL/pgSQL блоков, триггеров.
-
Информация о выполнении запроса. Детально описывает этап выполнения плана запроса.
Блок информации о потреблении ресурсов
Раздел системных ресурсов включает в себя все показатели, которые выводятся только на уровне RESOURCE (кроме Duration):
Duration- длительность ожидания или операции (мс).Mem- память:ixrss- объем общей памяти;idrss- объем данных не в общей памяти;isrss- размер стека;minflt- ошибки программной страницы (soft page faults);majflt- ошибки страницы на диске (hard page faults).
IO- ввод/вывод:swap- не используется в Linux;inblock- количество операций ввода;outblock- количество операций вывода.
IPC- межпроцессные взаимодействия (не используются в Linux):msgsnd;msgrcv;nsignals.
CTX- переключения контекста:nvcsw- количество переключений контекста до истечения выделенного на процесс временного промежутка (например, при ожидании ресурса);nivcsw- количество переключений контекста по истечении процессного времени или количество переключений, осуществляемых процессом с более высоким приоритетом.
CPU- потребление CPU:user- в пользовательском режиме (мс);system- в режиме ядра (мс).
Раздел утилизации shared buffers:
shared buffer hits- число попаданий;shared disk blocks read- число прочитанных блоков;shared blocks dirtied- число измененных блоков;shared disk blocks written- число блоков, записанных изshared buffer;local buffer hits- число попаданий в локальный кеш блоков;local disk blocks read- число чтений локальных блоков;local blocks dirtied- число измененных локальных блоков;local disk blocks written- число записей локальных блоков;temp blocks read- число чтений временных блоков;temp blocks written- число записей временных блоков;time spent reading- время, потраченное на чтение блоков (мс);time spent writing- время, потраченное на запись блоков (мс).
Раздел утилизации WAL:
- Records produced - количество созданных WAL-записей;
- Full page images produced - количество
full page image-записей в WAL; - Size of WAL records produced - общий объем памяти созданных WAL-записей.
Блок информации о легковесных блокировках
Включает в себя подблок информации о последней легковесной блокировке (служит для определения длительности ожидания блокировки для незавершенного запроса):
Begin of latest lwlock- время начала ожидания;End of latest lwlock- время окончания ожидания;LWLock tranche Id- идентификатор потока, в состав которого входит блокировка (транш);LWLock tranche name- имя транша блокировки;LWLock mode- имя режима блокировки,LW_SHAREDилиLW_EXCLUSIVE.
Подблок, включающий в себе список всех легковесных блокировок в порядке убывания суммарной длительности ожидания:
LWLock tranche Id- идентификатор транша блокировки;LWLock tranche name- имя транша блокировки;LWLock mode- имя режима блокировки -LW_SHAREDилиLW_EXCLUSIVE;LWLock count- количество ожиданий блокировки;LWLock minimum resources- минимальные ресурсы ожидания блокировки, не включают информацию поshared buffersи WAL;LWLock maximum resources- максимальные ресурсы ожидания блокировки, не включают информацию поshared buffersи WAL;LWLock summary resources- суммарные ресурсы ожидания блокировки, не включают информацию поshared buffersи WAL.
Блок информации о блокировках
Включает в себя подблок информации о последней легковесной блокировке (служит для определения длительности ожидания блокировки для незавершенного запроса):
Begin of latest lock- время начала ожидания;End of latest lock- время окончания ожидания;Lock type name- имя типа блокировки (соответствуют типам PostgreSQL);Lock mode- имя режима блокировки (соответствуют типам PostgreSQL);- Описание объекта блокировки, в зависимости от типа (соответствуют типам PostgreSQL).
Подблок списка блокировок в порядке убывания суммарной длительности ожидания включает в себя информацию по каждой из блокировок:
Lock type name- имя типа блокировки (соответствуют типам PostgreSQL);Lock mode- имя режима блокировки (соответствуют типам PostgreSQL);Lock count- количество ожиданий блокировки;- Описание объекта блокировки, в зависимости от типа (соответствуют типам PostgreSQL).
Блок выполнений запроса
Включает в себя подблоки:
Query and environment- текст запроса, а также значения параметровsearch_path,current_schema,current_role,session_user.Error- сообщение об ошибке и код ошибки при ее возникновении в ходе выполнения плана запроса.Plan- план запроса. Может быть как предварительный, без детальной информации по шагам выполнения и их ресурсам (в случае незавершенного выполнения плана, то есть при длительном выполнении), так и окончательный, с детальной информацией по шагам выполнения и их ресурсам, в том числе при завершении с ошибкой.Common stats- статистика по количеству успешных, отмененных и завершенных с ошибкой выполнений.Binds- порядок, типы, флаги и значения связанных переменных. Только на уровне трассировкиBINDи при наличии связанных переменных. При включенномmasking_mode=fullна сервере все значения замаскированы.Resources- информация об утилизации ресурсов выполнения плана.LWLocks- информация о легковесных блокировках выполнения плана.Locks- информация о блокировках выполнения плана.Parallels- информация о параллельных процессах плана, включаяPIDпроцесса, блокировки и утилизацию ресурсов.
Блок информации об ожидании запроса
Заголовок включает поля:
- Times - количество ожиданий запросов;
- Last started - время последнего начала ожидания поступления запроса;
- Last finished - время последнего окончания ожидания поступления запроса (для незавершенных ожиданий будет отображаться
Not finished).
Также в блок включена информация об утилизированных ресурсах. Для агрегированного запроса - минимальных, максимальных и суммарных.
Блок сводной статистики
Подблок статистики ожиданий запросов включает:
- количество ожиданий запросов;
- дату и время начала первого ожидания;
- дату и время окончания последнего ожидания;
- минимальные, максимальные и суммарные потребления времени, а при уровне трассировки
RESOURCE- и ресурсов на ожидание запросов (включая статистику по утилизации буферов и WAL).
Подблок статистики по запросам включает:
- количество вызовов выполнения запросов;
- количество подтвержденных транзакций;
- количество отмененных транзакций;
- количество ошибок;
- минимальные, максимальные и суммарные потребления времени, а при уровне трассировки
RESOURCE- и ресурсов на выполнение запросов (включая статистику по утилизации буферов и WAL).
Также блок содержит информацию о порожденных параллельных процессах.
Очистка памяти
В ядре СУБД Pangolin реализована функция очистки памяти, осуществляющая перезапись высвобождаемого дискового пространства специальными последовательностями блоков. Функциональность обеспечивает исключение рисков утечки данных.
Описание функциональности
Очистка удаляемых файлов данных происходит для операций:
DROP TABLE(включая операции удаления временных таблиц);DROP MATERIALIZED VIEW;DROP TEMPORARY TABLE;DROP INDEX;TRUNCATE;DROP DATABASE;REINDEX;DROP SCHEMA;VACUUM FULL;ALTER TABLE ADD COLUMN;ALTER TABLE ALTER COLUMN TYPE.
Также очистка происходит при удалении содержимого WAL-файла.
Примечание:
При выполнении операции
BEGIN → DROP TABLE/INDEX/MATERIALIZED VIEW ... → ROLLBACKочистка файлов не производится.
Настройка функциональности
В СУБД Pangolin предусмотрено включение/отключение данной функциональности:
| Функциональность | Параметр | Возможные значения | Значение по умолчанию |
|---|---|---|---|
| Очистка удаляемых файлов данных | nonrestorable_deletion | on/off | off |
| Очистка удаляемых или высвобождаемых WAL-файлов | nonrestorable_wal_deletion | on/off | off |
Настройки хранятся в postgresql.conf. По умолчанию оба параметра отключены на уровне параметров ядра (имеют значение off). Если включена защита конфигурации, то настройки включения/выключения функциональности тоже находятся под защитой.
Контроль целостности конфигурации и объектов БД
Контроль целостности данных — это механизм, позволяющий контролировать целостность конфигурации системы управления базами данных, конфигураций баз данных, процедур (программного кода) системы управления базами данных, процедур (программного кода), хранимых в базах данных, в процессе запуска и функционирования. В случае нарушения целостности объектов контроля происходит разрыв всех текущих сессий, блокировка доступа всех пользователей (за исключением администратора СУБД) и информирование администратора СУБД о нарушении целостности объектов контроля.
Администратору СУБД доступен API, позволяющий:
- генерировать и принудительно обновлять контрольные суммы объектов контроля;
- проверять целостность объектов контроля;
- получать информацию о текущих инцидентах.
API представлено в виде SQL-интерфейса (функций, вшитых в ядро PostgreSQL).
Также реализована автоматическая проверка целостности по расписанию.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Описание алгоритма работы
Начало работы
При первом запуске СУБД создаются файлы для хранения подконтрольных объектов. Далее администратор СУБД при необходимости определяет набор защищаемых объектов и добавляет их в эти файлы средствами СУБД. При повторных запусках СУБД файлы не пересоздаются, а используются прежние файлы, но, в случае их удаления, они будут созданы вновь. Также при удалении файла во время работы СУБД администратор может их создать путем вызова функциональности добавления объектов под контроль (необходимо будет заново указать набор защищаемых объектов).
Защищаемые объекты
Защите могут подлежать файлы и системные каталоги (pg_proc). Для каждого объекта сохраняется контрольная сумма, посчитанная с использованием алгоритма SHA256. Сохраненные данные считаются эталонными. Администратор СУБД может изменять подконтрольные объекты и принудительно перегенерировать контрольные суммы объектов.
Постановка объектов под контроль
Добавление объектов под контроль осуществляется последовательно, по одному объекту. Вычисление контрольных сумм производится функциями ядра. Добавление файлов с вычислением их контрольных сумм производится в текущем соединении администратора, добавление каталогов — в дополнительно созданном bgworker. Если присутствовала ошибка в имени файла, базе данных или каталоге, добавление объекта под контроль не происходит, база данных не блокируется. В случае невозможности записи объекта в файл .json происходит блокировка СУБД.
Проверка целостности данных
Периодический контроль (от 1 минуты до 24 часов) и контроль по требованию администратора производится в отдельном процессе IntCheckLauncher. Данный процесс стартует при запуске СУБД, создает файлы для контролируемых объектов (в случае их отсутствия) и запускает первую проверку контроля целостности данных. Далее в процессе работы он запускает проверки с заданным в конфигурационном файле периодом и проверки по требованию администратора СУБД. Чтобы выполнить проверку, процесс IntCheckLauncher запускает последовательно процессы проверки контроля целостности данных (IntCheckWorker) для файлов и каталогов в каждой базе данных. Если процесс IntCheckWorker находит несовпадение контрольной суммы, не обнаруживает подконтрольный объект или не обнаруживает файл с подконтрольными объектами, то происходит блокировка СУБД. Если процесс IntCheckWorker по каким-то причинам не сообщает о завершении проверки, то происходит блокировка СУБД и принудительное завершение процесса через сигнал SIGTERM. Если после этого процесс все равно не завершается, то посылается сигнал SIGKILL с последующей перезагрузкой всех процессов СУБД. В случае запуска проверки администратором СУБД происходит отправка сигнала на IntCheckLauncher для запуска проверки целостности данных и ожидание ее результатов заданное время (время указано в конфигурационном файле). Если время ожидание заканчивается, а результат не получен, СУБД блокируется.
Разблокировка базы данных
В случае блокировки СУБД в shared memory выставляется флаг. Ее возможно разблокировать только повторной проверкой целостности данных. Повторная проверка может пройти успешно в случае устранения причины блокировки:
- добавлен под контроль проблемный объект с пересчетом контрольной суммы;
- восстановлен подконтрольный объект, если он был удален;
- полностью пересозданы JSON-файлы после их удаления и добавления новых объектов;
- перезапуск проверки, если это был системный сбой, связанный с временем ожидания
IntCheckWorkerиIntCheckLauncher.
Также в случае нарушения целостности контролируемых данных происходит запись сообщения причины блокировки в системный лог, запись сообщения в аудит и информирование администратора.
Примечание:
Если реплика заблокирована по несоответствию контрольных сумм, то работа мастера продолжается. При переключении реплика → мастер работа мастера продолжается, а реплика так и остается заблокированной.
Генерация контрольных сумм
Особенности:
- права на выполнение функции есть только у
superuser(отсутствуют права на функцию у ролиpublic). Но есть возможность делегировать права конкретному пользователю; - администратор СУБД всегда имеет доступ к функциям API;
- в случае защиты файлов требуется указывать абсолютный путь;
- в случае защиты файлов при расчете контрольной суммы учитывается и содержимое файла, и его атрибуты. Пример:
-rw-r--r-- postgres postgres.
Хранение конфигурационных файлов
Конфигурационные файлы с перечнем контролируемых объектов хранятся в каталоге /pgdata /{number_vers}/data/pg_integrity, путь к ним прописан в коде. Файлы должны быть доступны для изменения только средствами СУБД.
Контрольные суммы должны храниться в конфигурационных файлах см. раздел «Формат конфигурационных файлов».
Формат конфигурационных файлов
Конфигурационные файлы имеют формат JSON.
Каждая подструктура в файле конфигурации соответствует одному отслеживаемому объекту. Каждый тип объекта имеет свой конфигурационный файл: for_check_system.json для файлов и for_check_catalog.json для объектов БД. Файлы создаются при запуске и содержат пустую структуру и подпись. В файле содержится информация об объекте (путь) и контрольная сумма.
Формат файла конфигурации:
-
пустой файл:
{
"integrity" : null
} -
после постановки под контроль:
{
"integrity" : [
{
"hash" : "{хеш}",
"name" : "/home/postgres/file_test1.bin",
"type" : "file"
},
{
"hash" : "{хеш}",
"name" : "/home/postgres/file_test2.bin",
"type" : "file"
}
]
}
Функции API
Для работы с функциональностью предусмотрен ряд функций.
pg_integrity_check() — осуществляет полную проверку целостности.
Входные параметры: отсутствуют.
Возвращаемое значение: true/false.
Пример:
SELECT pg_integrity_check();
select pg_integrity_add_catalog(db_name, catalog_name) — подсчитывает контрольные суммы для объектов БД. Добавляет в файл конфигурации. Изменяет общую подпись файла конфигурации.
Входные параметры: db_name text (имя БД), catalog_name text (имя системного каталога).
Возвращаемое значение: true/false.
Пример:
SELECT pg_integrity_check('postgres','pg_catalog.pg_proc');
select pg_integrity_add_file(file) — подсчитывает контрольные суммы для объектов типа файл. Добавляет в файл конфигурации. Изменяет общую подпись файла конфигурации.
Входные параметры: file_check text (путь к файлу).
Возвращаемое значение: true/false.
Пример:
SELECT pg_integrity_add_file('/etc/pangolin-manager/postgres.yml');
Конфигурационные параметры
| Имя параметра | Допустимые значения | Установка параметра | Описание параметра |
|---|---|---|---|
integrity_check_delay | от 1 секунды до 24 часов | Требуется перезагрузка БД. В случае конфигурации K1 смена параметров возможна только через сервер KMS | Период проверки |
integrity_check_wait | от 1 секунды до 24 часов | Требуется перезагрузка БД. В случае конфигурации K1 смена параметров возможна только через сервер KMS | Время ожидания работы worker (если под контроль добавлен большой объем данных, то время на полную проверку ограничивается этим флагом) |
integrity_check_select_wait | от 1 секунды до 24 часов | Требуется перезагрузка БД. В случае конфигурации K1 смена параметров возможна только через сервер KMS | Период, который launcher ждет до завершения работы всех порожденных worker |
Контроль загрузки в адресное пространство СУБД расширений и библиотек
Функциональность предназначена для выявления и блокировки загрузки в адресное пространство системы управления базами данных программного обеспечения, не включенного в перечень (список) программного обеспечения, разрешенного для выполнения.
Список разрешенных для загрузки в адресное пространство СУБД расширений и библиотек хранится в конфигурационном файле, находящемся в каталоге /pgdata/<Номер версии>/data/pg_integrity. Конфигурационный файл может содержать хеш-сумму, рассчитанную для каждого разрешенного расширения и/или библиотеки. Формат файла и его создание описаны в разделе «Контроль целостности конфигурации и объектов БД» этого документа.
Включение функциональности
Для включения функциональности в postgresql.conf используются два конфигурационных параметра:
loading_control.check_allow_list— флаг включения проверки расширения или плагина в списке разрешенных. Значение по умолчанию —false. Параметр применяется после перезагрузки (командаrestart). При успешной проверке перезагрузка будет выполнена без ошибок, в ином случае будет выведено сообщение об ошибке и отработка ошибки.loading_control.check_hash— флаг включения проверки расширения или плагина и ее контрольной суммы. Значение по умолчанию —false. Параметр применяется после перезагрузки (командаrestart). При успешной проверке перезагрузка будет выполнена без ошибок, в ином случае будет выведено сообщение об ошибке и отработка ошибки. Флаг зависит от параметраloading_control.check_allow_listи имеет смысл только при включенном параметреloading_control.check_allow_list.
Первоначальная загрузка СУБД происходит со значениями равными false. Установка параметров в true происходит после создания списка разрешенных файлов.
Алгоритм работы
При загрузке расширений и библиотек в адресное пространство СУБД:
-
При включенном параметре
loading_control.check_allow_list:-
Открывается и читается файл со списком разрешенных файлов (в каталоге
/pgdata/<Номер версии>/data/pg_integrity). -
При отсутствии файла со списком разрешенных файлов или ошибках его чтения, в лог выводятся сообщения вида:
WARNING: Library "pg_outline.so" is not loaded, no integrity check file listЗагрузка расширения или плагина (библиотеки) не происходит.
Примечание:
При включенной защите параметров конфигурации, при запуске СУБД Pangolin для подключения к KMS и кодирования, используются плагины, на которые указывают символические ссылки
/usr/pangolin/lib/libconnector_plugin.soи/usr/pangolin/lib/libencryption_plugin.so. Если функциональность включена локально, то выполняется проверка этих плагинов и в случае ошибок проверки, СУБД Pangolin не сможет запуститься.В этом случае, для запуска Pangolin:
- Рекомендуется переустановить Pangolin.
- Выключите параметр
loading_control.check_allow_listи сгенерируйте файл со списком разрешенных файлов. - Включите параметр
loading_control.check_allow_list.
-
Производится поиск загружаемого файла в списке разрешенных файлов.
-
При отсутствии файла в списке разрешенных, в лог выводятся сообщения вида:
WARNING: Library "pg_outline.so" is not loaded, no file in listЗагрузка расширения или плагина (библиотеки) не происходит.
-
При наличии файла в списке разрешенных, и если параметр
loading_control.check_hashвыключен, проверка считается успешно пройденной.
-
-
При включенном параметре
loading_control.check_hash:-
Производится расчет хеш-суммы проверяемого файла.
-
Рассчитанная хеш-сумма сравнивается с хеш-суммой из списка разрешенных файлов.
-
Если хеш-суммы не совпадают, в лог выводятся сообщения вида:
WARNING: Library "pg_outline.so" is not loaded, file is damagedЗагрузка расширения или плагина (библиотеки) не происходит.
-
Если хеш-суммы совпадают, проверка считается успешно пройденной.
-
При ошибках выводятся сообщения в лог аудита в соответствии с решением описанным в разделе «Журналирование и аудит».
Обратная совместимость с компонентами, использующими OpenSSL 1.+
Для управления активацией устаревших алгоритмов шифрования в Pangolin DBMS, Pangolin Pooler и Pangolin Manager реализован конфигурационный параметр ssl_legacy_provider. Управление осуществляется путем подгрузки провайдера Legacy в OpenSSL 3.0.0+ (аналог Engine API в OpenSSL 1.+) при запуске компонента, чем обеспечивается обратная совместимость с компонентами, использующими OpenSSL 1.+. Значение параметра по умолчанию on. Изменение параметра требует перезапуска компонента.
В клиентскую часть Pangolin DBMS добавлена опция подключения ssllegacyprovider и переменная окружения PGSSLLEGACYPROVIDER. Значение опции по умолчанию 1. При запуске утилит pg_certs_rotate, pkcs12_cert_info и secret_storage_client провайдер Legacy подгружается автоматически. Для отключения подгрузки используйте аргумент --no-ssl-legacy-provider.
Рекомендации по настройке ОС Linux
Порядок выбора источников разрешения имен
Для избежания лишнего обращения к серверу DNS-имен, если запись есть в локальном файле, рекомендуется в файле /etc/nsswitch.conf указать сначала обращение к /etc/hosts, а затем к DNS:
cat /etc/nsswitch.conf | grep hosts
hosts: files dns
Это повысит производительность компонентов кластера, особенно в случае большой нагрузки на DNS-сервер.
Повышение производительности: SLRU, BufferMapping
SLRU cache settings
В СУБД Pangolin предусмотрены настройки размеров кеша SLRU с помощью новых GUCS для того, чтобы узлы с высоким уровнем параллелизма и большими диапазонами транзакции (multixacts/subtransactions) в работе одновременно могли выиграть от увеличения объема кеша. Принцип определяется:
- Разделением кеша на «банки» (терминология кеша CPU). Такие алгоритмы, как поиск в буфере удаления, влияют только на один конкретный банк. Это устраняет проблему, связанную с линейностью поиска определенного буфера во всем кеше (такой поиск занимает слишком много времени). В данном подходе нужно просматривать конкретный банк, размер которого невелик.
- Использованием каждого банка отдельного LWLock. Это позволяет повысить масштабируемость.
Особое внимание уделяется тому, чтобы алгоритмы, которые потенциально могут работать с несколькими банками, в редких случаях снимали блокировку с одного банка до получения доступа к следующему. Новые GUCS соответствуют названиям, введенным в представлении pg_stat_slru. Значения по умолчанию для этих параметров аналогичны предыдущим размерам каждого SLRU. commit_timestamp_buffers, subtransaction_buffers и subtransaction_buffers принимают значение 0, что соответствует размеру shared_buffers, разделенному на 512 (то есть 2 МБ на каждые 1 ГБ shared_buffers), с ограничением в 8 МБ. Ранее для загрузки требовалось 1 МБ, поэтому для сайтов с общим объемом памяти более 512 МБ общий объем используемой памяти увеличивается. Другие SLRU (multixact_member_buffers, multixact_offset_buffers, notify_buffers и serializable_buffers) имеют меньшие размеры и не поддерживают нулевое значение.
Примечание:
Параметры можно задать только в
postgresql.conf/postgres.ymlили в командной строке при запуске сервера.
BufferMapping
В СУБД Pangolin страницы отношений хранятся в буферном кеше. Он располагается в общей памяти сервера и доступен всем процессам. Когда менеджеру буферов требуется прочитать страницу, он сначала пытается найти ее в буферном кеше. Для быстрого поиска нужного буфера используется хеш-таблица "Shared Buffer Lookup Table", хранящая номера буферов.
Для увеличения гранулярности хеш-таблица поделена на 128 частей (бакетов/корзин), доступ к каждой из которых защищается своей отдельной легкой блокировкой. Эти легкие блокировки объединены в последовательность блокировок LWLock::BufferMapping для данной хеш-таблицы. Перед обращением к хеш-таблице процесс должен захватить легкую блокировку, на которую выпал ключ хеширования: идентификатор файла отношения, тип слоя и номер страницы внутри файла этого слоя. Блокировка захватывается в двух режимах: в разделяемом режиме - для чтения и в исключительном - для изменений.
В большинстве сценариев обращения к хеш-таблице происходят очень активно, поэтому эта блокировка становится узким местом. На современных многоядерных системах 128 пакетов оказывается недостаточным из-за высокой конкуренции за доступ к отдельному бакету.
В данной работе вводится новый GUC параметр log2_num_buf_partitions для установки числа бакетов хеш-таблицы и, соответственно, количества легких блокировок в группе LWLock:BufferMapping. Увеличение значения параметра при интенсивной нагрузке позволяет снизить вероятность ожидания процессов на событии LWLock:BufferMapping за счет увеличения гранулярности блокировок.
Значение параметра - это степень, в которую нужно возвести число 2, для получения фактического количества частей хеш-таблицы. Значение по умолчанию - 7 (128 частей).
Примечание:
Максимальное значение - 12 (4096 частей). Параметр можно задать только в
postgresql.conf/postgres.ymlили в командной строке при запуске сервера. Изменение параметра требует перезапуска сервера.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Образование spill-файлов при логической репликации. Влияние репликационных идентификаторов (REPLICA IDENTITY) на логическую репликацию
При работе логической репликации в случаях, когда транзакция содержит множество изменений, в директории pg_replslot для каждого слота логической репликации появляются файлы типа spill. В этом разделе описаны причины такого поведения PostgreSQL и влияние репликационных идентификаторов (REPLICA IDENTITY) на появление файлов типа spill и на логическую репликацию в целом.
PostgreSQL должен переупорядочивать изменения, чтобы они применялись в правильном порядке. Для этого процессы отправителя журнала транзакций (WAL sender) приступают к логическому декодированию и переупорядочивают изменения в памяти. Однако, если транзакция содержит множество изменений, это займет много памяти. Поэтому PostgreSQL записывает эти изменения на диск.
В более ранних версиях PostgreSQL данное поведение регламентировалось константой max_changes_in_memory (src/backend/replication/logical/reorderbuffer.c):
/*
* Maximum number of changes kept in memory, per transaction. After that, changes are spooled to disk.
*
* The current value should be sufficient to decode the entire transaction without hitting disk in OLTP workloads, while starting to spool to disk in other workloads reasonably fast.
*
* At some point in the future it probably makes sense to have a more elaborate resource management here, but it's not entirely clear what that would look like.
*/
static const Size max_changes_in_memory = 4096;
max_changes_in_memory = 4096 означает, что при добавлении/изменении/удалении в одной транзакции более, чем 4095 строк, PostgreSQL записывает эти изменения на диск в виде snap-файлов, что можно наблюдать в логах СУБД, выставив параметр log_min_messages = DEBUG2:
DEBUG: spill 4096 changes in XID 1084 to disk
Примечание:
В 12 версии ядра PostgreSQL расширение «snap» сменило название на «spill».
max_changes_in_memory = 4096 включает в себя именно 4096 изменений строк, а не 4096 инструкций SQL. Такое ограничение не практично, так как структура таблиц может очень сильно варьироваться и нагрузка при операциях над таблицами, которые содержат в себе TOAST, будет сильно отличаться от нагрузки при работе с таблицами, которые имеют более простую структуру.
В 13 версии PostgreSQL поведение в части записи изменений на диск при логической репликации было изменено. Появился параметр logical_decoding_work_mem, который задает объем памяти, выделяемой для логического декодирования, после превышения которого данные вытесняются на диск (src/backend/replication/logical/reorderbuffer.c):
/*
* Maximum number of changes kept in memory, per transaction. After that, changes are spooled to disk.
*
* The current value should be sufficient to decode the entire transaction without hitting disk in OLTP workloads, while starting to spool to disk in other workloads reasonably fast.
*
* At some point in the future it probably makes sense to have a more elaborate resource management here, but it's not entirely clear what that would look like.
*/
int logical_decoding_work_mem;
static const Size max_changes_in_memory = 4096; /* XXX for restore only */
Пример вытеснения данных на диск при работе логической репликации
Настройте логическую репликацию и выполните вставку данных (параметр logical_decoding_work_mem для тестовых целей выставлен в значение 5MB):
-- Публикующий сервер:
create table test(id int primary key);
create publication test_pub for table test;
-- Сервер подписчик:
create table test(id int primary key);
create subscription test_sub connection 'host=0.0.0.0 port=5433 user=postgres' publication test_pub;
-- Вставка данных:
insert into test select x from generate_series(1, 50000) as x;
В логах СУБД можно увидеть следующие сообщения (log_min_messages = DEBUG2):
DEBUG: spill 39719 changes in XID 1559 to disk
DEBUG: spill 10281 changes in XID 1559 to disk
В то же время в каталоге pg_replslot/test_sub появился файл:
xid-1559-lsn-2-22000000.spill
Репликационные идентификаторы (REPLICA IDENTITY) при логической репликации
Процесс логической репликации строится на идее репликационных идентификаторов. Они нужны при репликации команд UPDATE и DELETE для однозначной идентификации изменяемых или удаляемых строк.
По умолчанию в роли репликационных идентификаторов выступают Primary Key или уникальные NOT NULL индексы, в случае их отсутствия репликационные идентификаторы придется настраивать с нуля, в противном случае команды UPDATE или DELETE будут приводить к отмене транзакций на мастере.
Примечание:
REPLICA IDENTITY – эта форма изменяет информацию, которая записывается в журнал для идентификации обновленных или удаленных строк. В большинстве случаев старое значение каждого столбца записывается в журнал только в том случае, если оно отличается от нового значения; однако если старое значение хранится во внешнем журнале, оно записывается всегда, независимо от того, изменилось ли оно. Эта опция не имеет эффекта, за исключением случаев, когда используется логическая репликация.
Узнать текущее значение REPLICA IDENTITY для таблицы можно при помощи запроса:
SELECT CASE relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class
WHERE oid = 'test'::regclass;
REPLICA IDENTITY принимает следующие значения:
DEFAULT– записываются старые значения столбцов первичного ключа, если он есть. Это режим по умолчанию для несистемных таблиц.USING INDEX имя_индекса– записываются старые значения столбцов, составляющих заданный индекс, который должен быть уникальным, не частичным, не отложенным и включать только столбцы, помеченныеNOT NULL. Если этот индекс удален, поведение будет таким же, как в режимеNOTHING.FULL– записываются старые значения всех столбцов в строке.NOTHING– информация о старой строке не записывается. Это режим по умолчанию для системных таблиц.
Пример использования различных репликационных идентификаторов
Для демонстрации отличий репликационных идентификаторов в работе необходимо создать слот логической репликации с встроенным плагином test_decoding.
Встроенный плагин test_decoding в PostgreSQL предназначен для демонстрационных целей и тестирования механизмов логического декодирования.
Этот плагин позволяет увидеть, какие изменения записываются в журнал транзакций (WAL), и как они могут быть декодированы и прочитаны.
Однако test_decoding является лишь примером и не предоставляет функциональности для применения изменений на реплике.
Настройка логической репликации для демонстрации отличий REPLICA IDENTITY:
create table test (id int primary key, name text, a bigint, b int);
create publication test_pub for table test;
select pg_create_logical_replication_slot('test_sub', 'test_decoding');
-- Добавление в таблицу 5 строк, поле text попадет в toast таблицу
with gener as (select x, (select string_agg(chr(trunc(65 + random() * 26)::integer), '') from generate_series(1, 2000)), x + 1, x + 2 from generate_series(1, 5) as x) insert into test select * from gener;
При помощи функций pg_logical_slot_get_changes() и pg_current_wal_insert_lsn() посмотрите изменения в слоте после выполнения команды UPDATE при различных значениях REPLICA IDENTITY и на объем генерируемых WAL-файлов в байтах:
REPLICA IDENTITY = DEFAULT:
SELECT CASE relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class
WHERE oid = 'test'::regclass;
replica_identity
------------------
default
(1 row)
select pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
2/2C000130
(1 row)
update test set b = b + 10 where id = 1;
select pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
2/2C000200
(1 row)
------ Изменения в слоте ------
select pg_logical_slot_get_changes('test_sub', NULL, NULL);
pg_logical_slot_get_changes
-------------------------------------------------------------------------------------------------------------------------
(2/2C000130,1610,"BEGIN 1610")
(2/2C000168,1610,"table public.test: UPDATE: id[integer]:1 name[text]:unchanged-toast-datum a[bigint]:2 b[integer]:13")
(2/2C000200,1610,"COMMIT 1610")
(3 rows)
------ Размер журнальных записей ------
select '2/2C000200'::pg_lsn - '2/2C000130'::pg_lsn as bytes;
bytes
-------
208
(1 row)
------ Изменения в слоте при изменения PK ------
update test set id = id + 10 where id = 1;
select pg_logical_slot_get_changes('test_sub', NULL, NULL);
pg_logical_slot_get_changes
------------------------------------------------------------------------------------------------------------------------------------------------------------
(2/2D0003E0,1611,"BEGIN 1611")
(2/2D000418,1611,"table public.test: UPDATE: old-key: id[integer]:1 new-tuple: id[integer]:11 name[text]:unchanged-toast-datum a[bigint]:2 b[integer]:13")
(2/2D000590,1611,"COMMIT 1611")
(3 rows)
------ К изменениям добавилось старое значение PK
old-key: id[integer]:1
При REPLICA IDENTITY = DEFAULT записываются только старые значения столбцов первичного ключа, если он есть, для остальных полей старые значения не записываются.
REPLICA IDENTITY = FULL:
alter table test replica identity full;
select pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
2/2F000028
(1 row)
update test set b = b + 10 where id = 3;
select pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
2/2F0008E8
(1 row)
------ Изменения в слоте ------
select pg_logical_slot_get_changes('test_sub', NULL, NULL);
pg_logical_slot_get_changes
------------------------------------------------------------------------------------------------------------------------------------------------------------
(2/2F000028,1614,"BEGIN 1614")
(2/2F000060,1614,"table public.test: UPDATE: old-key: id[integer]:3 name[text]:'QNBMGJPDYFFIQBWSHGFLFRXZQPAOJCDNGTLRPFEPEGBYNOVTCMGELZTKBNGPOFDOMPNGYCJBLSGCHQUSFNNVOSWWJGPAATGGZCRKNVJPSNLZKCFVQFWHVFJDNKKDFRYZDOKRHQVVMRVMC
YHEDHPFMSXVSSESWWZOMHFZTPYBXOOMCJSLKXROKMAQLDCDHBYJVQBGHPVXIVCKTDAZEVDFVILFBQRZBHOBCXIORFIHGIVWKRRRGSSHZTZTBEAIXDSDFMYGYNLBZLMUQOSDTUWKJUGFZQZKUZPILYJGUZHRDCVKPMEOHVOSIPCHZJGRDRPTPMLGEXLRCWKZBUSBEQQCOJZYGFWNKHCXJYLIGBVMPJD
IXUNSQQESZNRTRDFIWNEJVMULQAFIUNIUAXDYFWFWJMGVPVCFORCLJZSDFOCEQOKLQHOQAKIOLLKKZMCAKTWPVPHIARAMXSBMGYNPDZVVRPUEIFRYTEKJZMRITXSUHMAWYIQWABUEORWIDUBPZCVTFLATFEGOIZJGGPAEYCOPQVXAHBSQGVNNPVUSUTIMHJNZJGRMKFFPBNDZSGDSTRZEEKJAJYGHW
SPSYJKMULJEONHGESYGWVWDNIKTOVJQXZPRHFJETRBMKBJADAEDUVMXSIFMKVADZZVVDRKMVQYJRETYANCNIZMFHRYABDAVXAHUVUTAESPZBHGCHIBSSKGOZNACNDNEDIFCUJPWZNDCOPTXAZBTXTLYDFEEUOOKBYMYWICCLGSDPCZFIFEGACYIYQOLIQADFLKUVOFBHYPKPGOQIMQAYCDOSVWVYHX
XMPHMMEXUOPFXOGDBWUDAFHXOIJJBXXQOCJJPAMIJKDLGQZDIPBISCYKCHATDPFFJPSHTJIGRZBBDCQJYIVUBXUUHUTCQFZMMRKLOIYKOFZLAAXCHFOJANOXAZBQDGSFABCNMVKHTTGKHHVLPOIMIDEWCDJOYUBOECISCCOSIWZHUTMVLFZFAHQEIFNRVSKDCIIVPSPAOLEDQIWUJSTIHACFHIGFTS
VICBJKMBTPLZTFIEBBJDEAVJCGRLBEYCSNGWUUIXEMVQDNOFHVXLXHSUCOECMCYRMHIRZSHZOIVEWTYMKLBOKPXJMEDMLJSDXUOHTIERBAGIBDKRJZRDSVURLUWDQSBORWAGQYKGAWAQPVWVSQSEXKXDOJLKVNYQJLQFUCRTTRQYFDECQTASVFINIPCRRGZXAQEPSQDXOEXHHERNQNXYUBLXDLSKDL
HMVDCSMVXGIFFKVPTBTXIJSGKJKGEZHEXBKORJXILUTNPVRREOTNTXYUMKACAIBYYLJLGTHWQAYCBJIHJXLFRRPOZFGTQHCZLDIWPVVBSXMJRHSLIHGMWJWHLPLNLWUZNQGLWBUHOIISDWPRAMVJHEJAHKOGSBIFJQIUUSPRMIXYRTJUPKUNROOYGDOSIUPLWABTNGCASOVBCIQWRLWSTRXPVUENFG
SRWYYSONCZRCFXQHYKKHSHEHDCXUFHUKAWTFHXUAIDEGKKXIELFLHABMJCAMOBUAQWZIVRVVEHXGFHDIOFWIHJNAIQXHCNMNVWDNCVDUXQFSYNDHZTVWNTGGGUATLABSOAMFZYHDCGCNKOOUSXZUPELZGYREBONHBBGEBQTOIIJFBWZUCFUPXBZMXJTCUQNXOTLKNXBQPWHVDHJEHHSUGPJURXZHNW
XNBGLAPNNUVYBDVCEQJGEFIVNCIEITBUGXHOZXHGHNRSYLIOXHVIQKQOBFGEGDMBWKITUFJGTZBRGWABJTIVFFBADKAUIENABHCHCUCJNHXSBZVCIQWYPIGFMCGCJQKURZZCKHYNQYVSMEIQUTHFLWOEJDJQWBXMZYKWCJAAPSEPXAWIUSUSWKMTZRHFIHQCSMWWLLUVFXJFZUBFWGOVPTYKWVAXOM
OLSEKGTQCDLJGGZTYZWVPYIXHMNYKNYHYUPJYTEDQKLIWLLJDDMADMJENLHMQATFKTSBWUGYYBWFBTZVLMH' a[bigint]:4 b[integer]:5 new-tuple: id[integer]:3 name[text]:unchanged-toast-datum a[bigint]:4 b[integer]:15")
(2/2F0008E8,1614,"COMMIT 1614")
------ Размер журнальных записей ------
select '2/2F0008E8'::pg_lsn - '2/2F000028'::pg_lsn as bytes;
bytes
-------
2240
(1 row)
При REPLICA IDENTITY = FULL записываются старые значения всех столбцов в строке, что существенно увеличивает нагрузку.
Вытеснение данных на диск при работе логической репликации в зависимости от репликационного идентификатора:
Из предыдущего примера видно, на сколько разрастается объем хранимых и передаваемых данных при REPLICA IDENTITY = FULL:
------ Размер журнальных записей при REPLICA IDENTITY = DEFAULT ------
select '2/2C000200'::pg_lsn - '2/2C000130'::pg_lsn as bytes;
bytes
-------
208
(1 row)
------ Размер журнальных записей при REPLICA IDENTITY = FULL ------
select '2/2F0008E8'::pg_lsn - '2/2F000028'::pg_lsn as bytes;
bytes
-------
2240
(1 row)
Пример вытеснения данных на диск при различных значениях REPLICA IDENTITY
Для демонстрации вытеснения данных на диск при различных значениях REPLICA IDENTITY настройте логическую репликацию:
-- Публикующий сервер:
create table test (id int primary key, name text, a bigint, b int);
create publication test_pub for table test;
-- Сервер подписчик:
create table test (id int primary key, name text, a bigint, b int);
create subscription test_sub connection 'host=0.0.0.0 port=5433 user=postgres' publication test_pub;
-- Вставка данных:
with gener as (select x, (select string_agg(chr(trunc(65 + random() * 26)::integer), '') from generate_series(1, 2000)), x + 1, x + 2 from generate_series(1, 5000) as x) insert into test select * from gener;
Выполните UPDATE всех 5000 строк при разных REPLICA IDENTITY.
REPLICA IDENTITY = DEFAULT:
update test set b = b + 10;
При значении REPLICA IDENTITY = DEFAULT в логах СУБД не появилось сообщений о вытеснении данных на диск.
REPLICA IDENTITY = FULL:
alter table test replica identity full;
update test set b = b + 10;
При значении REPLICA IDENTITY = FULL в логах СУБД наблюдаются вытеснения на диск:
DEBUG: spill 2349 changes in XID 1641 to disk
DEBUG: spill 2349 changes in XID 1641 to disk
DEBUG: spill 302 changes in XID 1641 to disk
Данный пример демонстрирует на сколько сильно значение REPLICA IDENTITY = FULL нагружает СУБД. Рекомендуется максимально воздержаться от данного значения.
SWIDTAG-файл
Технология SWID-тегов является стандартизированной (ISO, ГОСТ) и определяет формат и способы идентификации программного продукта в процессах учета цифровых активов от момента создания актива до развертывания в среде эксплуатации.
Согласно данной технологии, продукту присваивается уникальный идентификатор (тег), который позволяет единообразно и достоверно идентифицировать продукт и его владельца.
Теги используются учетными системами для того, чтобы получать информацию об используемом в организации ПО, определять его количество, проверять на соответствие лицензионному соглашению, устанавливать зависимости и т.д. Информация из тегов позволяет однозначно понять, кто является производителем и/или владельцем продукта для обращения при сбойных ситуациях или других вопросах, связанных с эксплуатацией продукта. Производитель продукта на основании информации из тега может убедиться, что речь идет действительно о принадлежащем ему продукте.
Теги поставляются в составе дистрибутива в виде SWIDTAG-файлов. SWIDTAG-файл имеет заданное содержимое с набором полей. Информация из файла в дистрибутиве должна быть перемещена в среду эксплуатации при развертывании продукта. Пример SWIDTAG-файла:
<?xml version="1.0" encoding="utf-8"?>
<software_identification_tag xmlns="http://standards.iso.org/iso/19770/-2/2009/schema.xsd" xmlns:ds="http://www.w3.org/2000/09/xmldsig#" xsi:schemaLocation="http://standards.iso.org/iso/19770/-2/2009/schema.xsd schema.xsd" id="AAAAA" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<entitlement_required_indicator>false</entitlement_required_indicator>
<product_title>Platform V Pangolin DB</product_title>
<product_version>
<name>6.4.0</name>
<numeric>
<major>6</major>
<minor>3</minor>
<build>1</build>
<review>0</review>
</numeric>
</product_version>
<software_creator>
<name>SberTech</name>
<regid>regid.2021-12.ru.sbertech</regid>
</software_creator>
<software_licensor>
<name>SberTech</name>
<regid>regid.2021-12.ru.sbertech</regid>
</software_licensor>
<software_id>
<unique_id>psq-6.4.0</unique_id>
<tag_creator_regid>regid.2021-12.ru.sbertech</tag_creator_regid>
</software_id>
<tag_creator>
<name>SberTech</name>
<regid>regid.2021-12.ru.sbertech</regid>
</tag_creator>
<dependency>
<software_id>
<unique_id>audit-libs@3.0</unique_id>
<tag_creator_regid>regid.-.audit-libs</tag_creator_regid>
</software_id>
<software_id>
<unique_id>cpio@2.12</unique_id>
<tag_creator_regid>regid.-.cpio</tag_creator_regid>
</software_id>
<software_id>
<unique_id>jsoncpp@1.8</unique_id>
<tag_creator_regid>regid.-.jsoncpp</tag_creator_regid>
</software_id>
<software_id>
<unique_id>keyutils-libs@1.5</unique_id>
<tag_creator_regid>regid.-.keyutils-libs</tag_creator_regid>
</software_id>
<software_id>
<unique_id>krb5-libs@1.18</unique_id>
<tag_creator_regid>regid.-.krb5-libs</tag_creator_regid>
</software_id>
<software_id>
<unique_id>libevent@2.1</unique_id>
<tag_creator_regid>regid.-.libevent</tag_creator_regid>
</software_id>
<software_id>
<unique_id>libgcrypt@1.8</unique_id>
<tag_creator_regid>regid.-.libgcrypt</tag_creator_regid>
</software_id>
<software_id>
<unique_id>libicu@60.3</unique_id>
<tag_creator_regid>regid.-.libicu</tag_creator_regid>
</software_id>
<software_id>
<unique_id>libyaml@0.1</unique_id>
<tag_creator_regid>regid.-.libyaml</tag_creator_regid>
</software_id>
<software_id>
<unique_id>logrotate@3.9</unique_id>
<tag_creator_regid>regid.-.logrotate</tag_creator_regid>
</software_id>
<software_id>
<unique_id>lz4@1.8</unique_id>
<tag_creator_regid>regid.-.lz4</tag_creator_regid>
</software_id>
<software_id>
<unique_id>openssl@1.1.1</unique_id>
<tag_creator_regid>regid.-.openssl</tag_creator_regid>
</software_id>
<software_id>
<unique_id>openssl-libs@1.1.1</unique_id>
<tag_creator_regid>regid.-.openssl-libs</tag_creator_regid>
</software_id>
<software_id>
<unique_id>pam@1.3</unique_id>
<tag_creator_regid>regid.-.pam</tag_creator_regid>
</software_id>
<software_id>
<unique_id>python3.9@3.9</unique_id>
<tag_creator_regid>regid.-.python3.9</tag_creator_regid>
</software_id>
<software_id>
<unique_id>tcl@8.6</unique_id>
<tag_creator_regid>regid.-.tcl</tag_creator_regid>
</software_id>
<software_id>
<unique_id>uuid@1.6</unique_id>
<tag_creator_regid>regid.-.uuid</tag_creator_regid>
</software_id>
<software_id>
<unique_id>xz-libs@5.2</unique_id>
<tag_creator_regid>regid.-.xz-libs</tag_creator_regid>
</software_id>
</dependency>
</software_identification_tag>
В ключ <product_version></product_version> записывается версия продукта, определяемая как два элемента - имя версии и числовая версия.
В ключ <name></name> записывается имя версии в формате major.minor.patch. Числовая версия записывается в соответствующие ключи: <major>major</major>, <minor>minor</minor>, <build>patch</build>.
В ключ <software_creator></software_creator> записывается идентификатор создателя программного обеспечения, выпустившего программный пакет.
В ключ <software_licensor></software_licensor> записывается идентификатор лицензиара программного обеспечения, владеющего авторскими правами на программный пакет.
В ключ <software_id></software_id> записывается информация, которую можно использовать для ссылки на конкретную версию конкретного продукта.
В ключ <unique_id></unique_id> записывается уникальный идентификатор программного обеспечения, который состоит из 3-х символьного кода продукта (из АС ПУ) <unique_id>psq-major.minor.patch</unique_id>.
В ключ <tag_creator></tag_creator> записывается идентификатор создателя идентификационного тега для программного обеспечения.
В ключ <dependency></dependency> записываются зависимости. Данный элемент предоставляется для того, чтобы разрешить программному обеспечению указывать, что для запуска ему необходимо другое программное обеспечение. Заполняются ключами <unique_id> и <tag_creator_regid> заключенных в ключе <software_id>. <unique_id> - уникальный идентификатор программного обеспечения, <tag_creator_regid> - идентификатор создателя тега.
SWIDTAG-файл продукта расположен на верхнем уровне в zip-пакете и имеет имя swidtag-distrib.swidtag (имя обусловлено форматом zip-пакета).
SWIDTAG-файл также формируется на каждый отдельный компонент.
Далее приведена таблица имен SWIDTAG-файлов компонентов и их расположение:
| Имя компонента | Имя SWIDTAG-файла | Расположение |
|---|---|---|
| pangolin-dbms | regid.2021-12.ru.sbertech_dbms-6.4.0.swidtag | /usr/pangolin-6.4/bin |
| pangolin-dbms-client | regid.2021-12.ru.sbertech_dbcl-6.4.0.swidtag | /usr/pangolin-dbms-client-6.4/bin |
| pangolin-dbms-libpq | regid.2021-12.ru.sbertech_dbli-6.4.0.swidtag | /usr/pangolin-dbms-libpq-6.4/share |
| pangolin-dbms-libpq-dev | regid.2021-12.ru.sbertech_dbld-6.4.0.swidtag | /usr/pangolin-dbms-libpq-dev-6.4/include |
| pangolin-manager | regid.2021-12.ru.sbertech_mngr-2.1.2.swidtag | /opt/pangolin-manager/bin |
| pangolin-pooler | regid.2021-12.ru.sbertech_polr-1.3.2.swidtag | /opt/pangolin-pooler/bin |
| pangolin-auth-reencrypt | regid.2021-12.ru.sbertech_arpt-6.4.0.swidtag | /opt/pangolin-auth-reencrypt/bin |
| pangolin-backup-tools | regid.2021-12.ru.sbertech_bpts-1.2.2.swidtag | /opt/pangolin-backup-tools/bin |
| pangolin-certs-rotate | regid.2021-12.ru.sbertech_crrt-6.4.0.swidtag | /opt/pangolin-certs-rotate/bin |
| pangolin-diagnostic-tool | regid.2021-12.ru.sbertech_dgns-6.4.0.swidtag | /opt/pangolin-diagnostic-tool/bin |
| pangolin-security-utilities | regid.2021-12.ru.sbertech_scrt-6.4.0.swidtag | /opt/pangolin-security-utilities/bin |
| pangolin-timescaledb | regid.2021-12.ru.sbertech_tmdb-2.14.2.swidtag | /usr/pangolin-6.4/share/extension |
| pangolin-ansible-venv-controller | regid.2021-12.ru.sbertech_vctr-2.14.2.swidtag | /opt/pangolin-ansible-venv-controller/bin |
| pangolin-ansible-venv-controlled | regid.2021-12.ru.sbertech_vctd-2.14.2.swidtag | /opt/pangolin-ansible-venv-controlled/bin |
Формат SWIDTAG-файла для компонента аналогичен SWIDTAG-файлу для продукта за исключением того, что добавлен ключ <component_of></component_of>, куда записывается уникальный идентификатор родительского продукта. Заполняются ключами <unique_id> и <tag_creator_regid>, заключенных в ключе <software_id>. <unique_id> - уникальный идентификатор создателя тега для родительского продукта, <tag_creator_regid> - идентификатор создателя тега.
Пример сформированного SWIDTAG-файла для компонента:
<?xml version="1.0" encoding="utf-8"?>
<software_identification_tag xmlns="http://standards.iso.org/iso/19770/-2/2009/schema.xsd" xmlns:ds="http://www.w3.org/2000/09/xmldsig#" xsi:schemaLocation="http://standards.iso.org/iso/19770/-2/2009/schema.xsd schema.xsd" id="AAAAA" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<entitlement_required_indicator>false</entitlement_required_indicator>
<product_title>Pangolin Manager</product_title>
<product_version>
<name>2.1.2</name>
<numeric>
<major>2</major>
<minor>1</minor>
<build>2</build>
<review>0</review>
</numeric>
</product_version>
<software_creator>
<name>SberTech</name>
<regid>regid.2021-12.ru.sbertech</regid>
</software_creator>
<software_licensor>
<name>SberTech</name>
<regid>regid.2021-12.ru.sbertech</regid>
</software_licensor>
<software_id>
<unique_id>mngr-2.1.2</unique_id>
<tag_creator_regid>regid.2021-12.ru.sbertech</tag_creator_regid>
</software_id>
<tag_creator>
<name>SberTech</name>
<regid>regid.2021-12.ru.sbertech</regid>
</tag_creator>
<!-- Родительский продукт PSQ версии 6.4.0 -->
<component_of>
<software_id>
<unique_id>psq-6.4.0</unique_id>
<tag_creator_regid>regid.2021-12.ru.sbertech</tag_creator_regid>
</software_id>
</component_of>
<!-- Платформенные зависимости -->
<dependency>
<software_id>
<unique_id>logrotate@3.9</unique_id>
<tag_creator_regid>regid.-.logrotate</tag_creator_regid>
</software_id>
<software_id>
<unique_id>python3.9@3.9</unique_id>
<tag_creator_regid>regid.-.python3.9</tag_creator_regid>
</software_id>
</dependency>
</software_identification_tag>
Примечание:
SWIDTAG-файлы располагаются в архиве
owned-distrib.zip. К файлам как для продукта, так и для компонентов разрешен только доступ на чтение (444).
SWIDTAG-файлы размещаются на серверах, куда производится установка продукта или компонента. SWIDTAG-файл продукта помещается в $PGHOME/share.
Механизм сбора информации о движении данных (Data Lineage)
Функциональность предназначена для сбора информации о движении данных внутри БД, реализована в виде расширения, загружаемого на старте сервера.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Потоком данных между объектами базы является выполнение запроса в БД, когда источником и приемником данных является объект базы. Это выполнение DML-запросов INSERT/UPDATE/MERGE/COPY FROM, а так же DDL-запросы, когда при определении объекта базы сразу происходит его наполнение: CREATE TABLE ... AS, SELECT INTO, CREATE MATERIALIZED VIEW.
Статистика по запросам содержащим потоки данных является консолидированной по всем запускам. При первом исполнение запроса определяются потоки данных и по каждому из них добавляется одна запись, при последующих запусках этого запроса обновляется лишь статистическая информация запроса.
На диаграмме ниже изображена последовательность выполнения процессов. Красным отмечены процессы, которые реализованы в продукте СУБД Pangolin, а синим - процессы, для которых необходимо предоставление прав, доступов, данных и настроек.
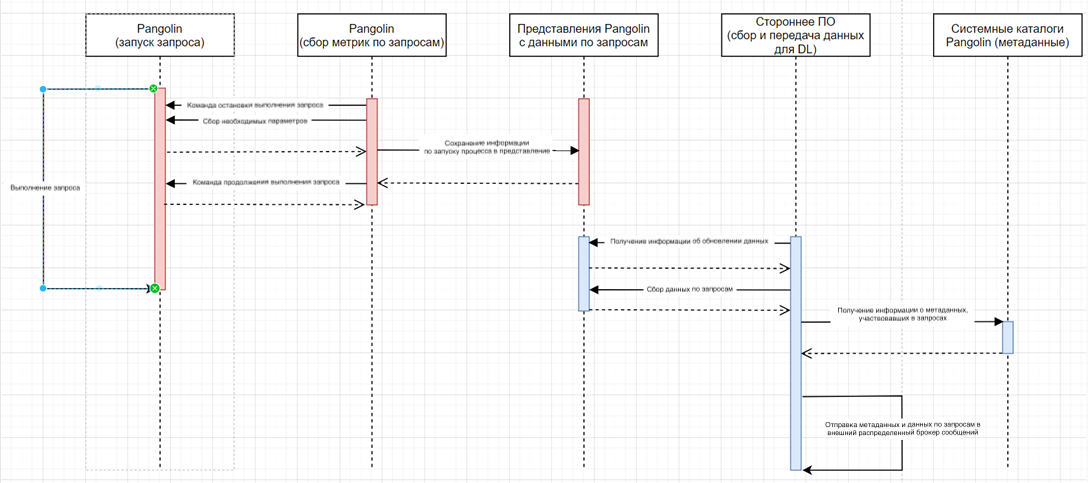
Сброс статистики (неконсистентный)
Для удаления всей статистики без учета консистентности сохранения данных, реализованы методы psql_data_lineage_reset и psql_data_lineage_clean. При их вызове будет удалена информация о статистике для всех БД и файлы с содержимым будут так же удалены с диска. Ниже в таблицах подробная информация о данных функциях.
Консистентное удаление данных
Для консистентного удаления данных, без потери записей от момента select до reset, реализована функциональность freeze.
При необходимости собрать статистику по Data Lineage пользователь может воспользоваться функциями psql_data_lineage_objects, psql_data_lineage_attributes и другими. Однако при этом возникает и необходимость эти данные (собранные) очистить. При выполнении обычной функции psql_data_lineage_reset возникает проблема связанная с неконсистентной обработкой потока данных, поскольку за время от последнего select до сброса состояние могло измениться.
Именно для решения данной проблемы введена функциональность freeze. При возникновении желания сохранить часть данных, пользователь вызывает функцию psql_data_lineage_freeze_data, которая замораживает все собранные на момент выполнения функции данные Data Lineage (создает локальную копию). После этого можно вызвать все необходимые функции, т.е. собрать желаемую статистику. Когда процесс сбора с сохранения закончен, пользователь вызывает функцию psql_data_lineage_reset_freezed. Тем самым очищая новые данные, которые продолжают поступать в shared memory, freeze на них не влияет. Такая очистка работает консистентно, поскольку учитывает новое и старое состояния счетчиков и записей.
Если после выполнения заморозки (psql_data_lineage_freeze_data) пользователь не смог собрать данные или принял решение не делать этого, можно вызвать psql_data_lineage_restore_freezed, которая очистит локальную копию. После этого все запросы снова будут идти в shared memory для получения данных.
Внимание!
После очистки с использованием freeze-функциональности записи в DL не удаляются полностью, у них обнуляются счетчики и они не показываются в запросах по получению данных. Такие zero-records используются для оптимизации времени, которое требуется на осуществление разбора дерева запроса (то есть zero-records выступают как некий кеш осуществленных до очистки запросов). При заполнении на 75% общей памяти в первую очередь будет произведена очистка именно zero-records. Таким образом при достижении 75% может требоваться больше времени для разбора уже очищенных, но ранее выполненных запросов.
На текущий момент нет механизма поддержки параллельного использования freeze-функциональности. Обеспечение осуществления вызовов данных функций только в одном процессе остается за пользователем.
Ограничение функциональности
В одной транзакции можно использовать не более 255 уникальных ID-запросов для DDL-запросов, которые имеют одинаковый инициализирующий запрос. Далее ID-запросы могут повторяться.
Включение и настройка функциональности
Процесс включения мониторинга DL:
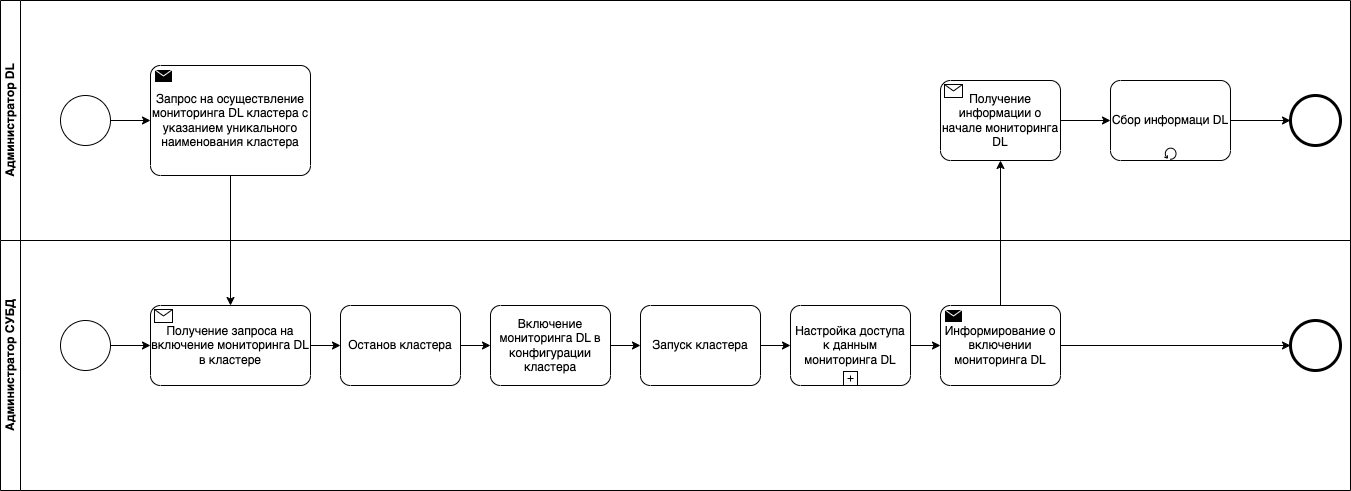
При загрузке расширения на старте СУБД выделяется общая память (shared memory) для обеспечения его работоспособности вне зависимости от того включена ли функциональность соответствующим параметром (psql_data_lineage.enable).
После включения функциональности сбор статистики осуществляется по всем существующим БД в сущности СУБД, если это не переопределено параметрами.
Включенная функциональность использует выделенную на старте общую память и в случае заполнения более 75% в лог СУБД, выводится предупреждение уровня WARNING о необходимости произвести очистку общей памяти (сначала происходит очистка zero-records). Функции и представления предоставляющие интерфейс выгрузки создаются при создании расширения командой CREATE EXTENSION psql_data_lineage и доступны в той БД в которой создано расширение, однако предоставляют всю накопленную статистику – по всем БД.
В рамках расширения задается параметр psql_data_lineage.max_records, отвечающий за максимальное количество записей о статистике уникальных запросов DL. При достижении указанных ограничений пользователь будет получать ошибку при попытке выполнения любого запроса, содержащего потоки данных.
Примечание:
Для оптимизации выгрузки данных DL рекомендуется создать отдельную обслуживающую БД в которой производится чтение данных DL в структуру обработки информации на усмотрение Администратора DL и дальнейшее использование этих данных для выгрузки администраторами DL. Данная рекомендация не является обязательной, и установка может быть выполнена в любую из существующих БД.
Для включения и настройки функциональности выполните шаги:
-
Добавьте к параметру
shared_preload_librariesзначениеpsql_data_lineage:ALTER SYSTEM SET shared_preload_libraries=' 'psql_data_lineage'; -
Выставьте параметр конфигурации
psql_data_lineage.enableв postgres в значениеon:ALTER SYSTEM SET psql_data_lineage.enable='on'; -
Перезагрузите СУБД.
-
Создайте расширение:
CREATE EXTENSION IF NOT EXISTS psql_data_lineage; -
Настройте список БД для которых будет собираться статистика. Для этого реализованы параметры
psql_data_lineage.exclude_databasesиpsql_data_lineage.include_databases. По умолчанию статистика собирается для всех БД, так как по умолчанию в значении пустая строка. Изменение любого из параметров требует перезагрузки СУБД.Примеры использования:
ALTER SYSTEM SET psql_data_lineage.exclude_databases='dl_1,dl_2,dl_3'– собирать статистику по всем существующим БД в сущности СУБД кромеdl_1,dl_2,dl_3;ALTER SYSTEM SET psql_data_lineage.include_databases='dl_3,dl_4,dl_5'– собирать статистику только в БДdl_3,dl_4,dl_5.
Указать
dl_3для обоих параметров можно, но в таком случае статистика будет собираться только в БДdl_4,dl_5. -
Перезагрузите СУБД, для применения параметров.
-
Настройте путь к месту сохранения файлов со статистикой:
-
Пример использования при сохранении данных вне
$PGDATA(рекомендовано):-
Создайте директорию в необходимом месте:
mkdir -p /opt/example_info/dl_stat_new -
Переопределите параметр
psql_data_lineage.stat_directory:ALTER SYSTEM SET psql_data_lineage.stat_directory='/opt/example_info/dl_stat_new' -
Перезагрузите СУБД для применения параметра. После применения параметра путь сохранения файлов статистики будет:
/opt/example_info/dl_stat_new.
-
-
Пример использования при сохранении в пределах
$PGDATA:-
Создайте директорию в
$PGDATA:mkdir -p $PGDATA/new_info/dl_stat_example -
Переопределить параметр
psql_data_lineage.stat_directory:ALTER SYSTEM SET psql_data_lineage.stat_directory='new_info/dl_stat_example' -
Перезагрузите СУБД для применения параметра. После применения параметра путь сохранения файлов статистики будет:
$PGDATA/new_info/dl_stat_example.
-
-
Параметры конфигурирования расширения
В рамках реализации функциональности были добавлены параметры:
| Параметр | Тип | Значение по умолчанию | Контекст | Описание |
|---|---|---|---|---|
psql_data_lineage.cluster_name | Строка | "" | postmaster | Суффикс, добавляемый к уникальным идентификаторам, может быть использован для обеспечения уникальности идентификаторов между различными экземплярами СУБД, при централизованном сборе DL |
psql_data_lineage.enable | Логическое значение | off | superuser | Включение функциональности по определению потоков данных и связанной статистической информации |
psql_data_lineage.max_records | Целое число | 5000 | postmaster | Максимальное количество записей о статистике уникальных запросов DL (определяется уникальным идентификатором запроса с учетом наименования объектов). Интервал допустимых значений: 1 .. INT_MAX/2 |
psql_data_lineage.exclude_databases | Строка | "" | postmaster | Исключенные БД, по ним статистика не ведется. Параметр psql_data_lineage.exclude_databases обладает большим приоритетом, чем psql_data_lineage.include_databases |
psql_data_lineage.include_databases | Строка | "" | postmaster | Включенные БД. Статистика будет собрана по этим базам данных. Если параметр не заполнен то будут собираться данные по всем таблицам (если переменная exclude_databases пуста) |
psql_data_lineage.stat_directory | Строка | "pg_stat/dl_stat" | postmaster | Параметр конфигурации расширения со значением по умолчанию $PGDATA/pg_stat/dl_stat указывает место в системе куда будут сохранятся данные, собранные расширением. Этот параметр можно задать либо как относительный путь ("pg_stat/dl_stat") в $PGDATA, либо как абсолютный путь к произвольному месту в системе |
Объекты, создаваемые расширением
| Наименование | Описание функции | Выходной парамет | Описание параметра |
|---|---|---|---|
psql_data_lineage_objects_meta | Метаданные об объектах, участвующих в данном потоке данных | process_id | Идентификатор запроса, обработанного Data Lineage (не совпадает с query_id, учитывает именования) {идентификатор запроса (совпадающий с названием создаваемого файла)} |
obj_oid | Идентификатор объекта в рамках СУБД на момент выполнения запроса | ||
qualified_name | Полное имя объекта в рамках данного потока данных {имя базы}.{имя схемы}.{имя объекта}@{суффикс кластера} | ||
name | Полное имя объекта в рамках Postgres {имя базы}.{имя схемы}.{имя объекта} | ||
db_oid | Идентификатор БД на момент выполнения запроса | ||
obj_type | Тип объекта * | ||
psql_data_lineage_attributes_meta | Метаданные об атрибутах объектов, участвующих в данном потоке данных | process_id | Идентификатор запроса, обработанного Data Lineage (не совпадает с query_id, учитывает именования) {идентификатор запроса} |
obj_oid | Идентификатор объекта в рамках СУБД на момент выполнения запроса | ||
qualified_name | Полное имя объекта в рамках данного потока данных {имя базы}.{имя схемы}.{имя объекта}.{имя атрибута}@{суффикс кластера} | ||
attr_no | Порядковый номер атрибута. Нумерация начинается с 1 | ||
name | Полное имя объекта {имя базы}.{имя схемы}.{имя объекта}.{имя атрибута} | ||
attr_type | Тип объекта * | ||
psql_data_lineage_objects | Определение потока данных включая источники/приемники запроса, а так же статистическую информацию о потоках | qualified_name | Идентификатор. Через этот идентификатор происходит связывание со всеми остальными предоставляемыми данными. Идентификатор формируется на основе идентификатора запроса расширенного метаинформацией. Номер потока разделяет потоки в рамках одного запроса. Такие потоки появляются в запросах MERGE, в запросах содержащих CTE с RETURNING, при наличии функции. {идентификатор запроса}/{номер потока}@{суффикс кластера} |
last_time | время начала последнего исполнения запроса | ||
input_type | Тип объекта источника * | ||
input_oid | Идентификатор объекта источника (пустой при const) | ||
output_type | Тип объекта приемника * | ||
output_oid | идентификатор объекта приемника | ||
query_plan | Текст последнего исполненного плана | ||
query_text | Генерализованный текст запроса | ||
first_time | Время начала первого исполнения запроса | ||
exec_duration | Длительность последнего исполнения запроса | ||
exec_count | Количество успешных исполнений запроса с начала сбора статистики | ||
count_row | Суммарное колличество строк обработанных запросом с начала сбора статистики | ||
query_id | Идентификатор запроса в рамках Postgres | ||
parent_process_id | Идентификатор запроса, обработанного Data Lineage (не совпадает с query_id, учитывает именования) Запросы могут иметь вложенный характер. Это поле позволяет отследить цепочку запросов вызывавших друг друга. Для порождающего запроса в качестве родительского указывается он сам {идентификатор запроса} | ||
process_id | Идентификатор запроса, обработанного Data Lineage (не совпадает с query_id, учитывает именования) {идентификатор запроса} | ||
psql_data_lineage_attributes | qualified_name | Идентификатор потока данных уровня атрибутов. {идентификатор запроса}/{номер потока}${номер атрибута источника}${идентификатор oid источника}${номер атрибута приемника}@{суффикс кластера} | |
input_type | Тип объекта источника * | ||
input_oid | Идентификатор объекта источника | ||
input_attno | Номер атрибута источника | ||
output_attno | Номер атрибута приемника | ||
query | Идентификатор потока для связи с данными из psql_data_lineage_object {идентификатор запроса}/{номер потока}@{суффикс кластера} | ||
psql_data_lineage_freeze_data | Позволяет создавать в процессе локальную копию собранных данных, по которым будут производится все операции по просмотру в данном процессе далее (до отмены/удаления) | Целое число | Количество замороженных записей |
psql_data_lineage_reset_freezed | Консистентно обновляет замороженные функцией psql_data_lineage_freeze_data данные. У старых объектов будет пересчитан exec_count и rowsCount, новые объекты присутствуют. (состояние после выполнения будет соответствовать тому, как если бы данные начали собираться в момент вызова psql_data_lineage_freeze_data) | Целое число | Количество обновленных записей |
psql_data_lineage_restore_freezed | При необходимости позволяет отменить заморозку, т.е. если после вызова psql_data_lineage_freeze_data не планируется сброс данных, вызов данной функции удалит локальную копию и позволит делать выборку данным в реальном времени | Логическое значение | Успех выполнения |
psql_data_lineage_reset | (неконсистентно) Очищает общую память от накопленных статистических данных, а так же удаляет файлы на диске хранящие статическую информацию о потоках данных | Логическое значение | Успех выполнения |
psql_data_lineage_clean(keep_interval TEXT) | (неконсистентно) Удаляет данные о потоках старше заданного keep_interval. Возвращает количество удаленных записей | Целое число | Количество удаленных записей |
* – все возможные типы отношений из pg_class (однако на практике индексы не участвуют в потоках данных, поэтому не могут попасть в качестве значения в это поле):
r– обычная таблица;i– индекс (index);S– последовательность (sequence);v– представление (view);m– материализованное представление (materialized view);c– составной тип (composite);t– таблица TOAST;f– сторонняя таблица (foreign).
Дополнительно введенные типы:
T– временная таблица;P– параметр;C– константа;F– функция.
Поставка сборки с отладочными пакетами
Примечание:
Начиная с версии 6.4.2, добавлена поддержка функциональности для семейства операционных систем Astra.
Для улучшения качества и скорости исследования инцидентов, возникших в промышленной среде, начиная с версии продукта 6.4.0 производится поставка отладочных символов. Отладочная информация отделяется от исполняемых/библиотечных объектов и сохраняется в отдельных файлах. Данные файлы поставляются отдельным пакетом (далее отладочным пакетом) с каждым компонентом решения, для которых их поставка предусмотрена.
Начиная с версии 6.4.0, в корневой каталог дистрибутива продукта добавлена директория debug, содержащая отладочные пакеты всех компонентов, для которых предусмотрена поставка. Скрипты автоматизации установки расширены дополнительными конфигурационными параметрами, позволяющие производить установку отладочных символов в момент установки решения.
Новые параметры скриптов автоматизации, сценарии обновления на версии 6.4.0 и выше, а также случаи, когда отладочные символы не были установлены сразу, будут рассмотрены далее.
Установка отладочного пакета не оказывает влияния на производительность решения. Принятие решения о моменте установки отладочной информации принимается пользователем.
Перечень компонентов решения для которых предусмотрена поставка отладочных символов:
- pangolin-pooler;
- pangolin-manager;
- pangolin-backup-tools;
- pangolin-dbms;
- pangolin-dbms-clent;
- pangolin-dbms-libpq;
- pangolin-certs-rotate;
- pangolin-security-utilities.
Установка отладочных пакетов позволяет:
- получать информативный стек вызовов (с адресами и именами функций);
- производить рассекречивание дампов памяти процесса (
core dump), в том числе сформированных автоматически до момента установки отладочных пакетов; - сократить срок расследования инцидентов.
Примечание:
Для корректного сбора информации в момент возникновения инцидента, необходимо произвести дополнительную настройку операционной системы (ОС) для автоматического формирования снимков памяти процесса (
core dump) в случае аварийного завершения процесса. Пример настройки ОС приведен в следующем разделе.Установка отладочной информации не влияет на процесс создания снимков памяти процесса (
core dump) и последующую информативность содержащих в них данных. Однако необходимо, чтобы в момент исследования дампов, отладочные символы были установлены (т.е. функциональность позволяет формировать информативный стек вызовов из дампов, сформированных до установки отладочной информации).
Настройка ОС для автоматического формирования core dump
С целью обеспечения автоматического формирования дампа памяти процесса (core dump) средствами операционной системы необходимо выполнить ее дополнительную настройку.
Как правило, выполнения ulimit -c unlimited перед запуском процесса достаточно для включения автоматического формирования снимков памяти (core dump) аварийно завершенного процесса. Однако также рекомендуется выполнить дополнительную настройку имен и путь расположения файлов, для чего перед запуском процесса дополнительно необходимо выполнить:
-
Добавить в файл
/etc/sysctl.confпараметры:kernel.core_uses_pid = 1
kernel.core_pattern = /tmp/core-%e-%s-%p-%t
fs.suid_dumpable = 2где
kernel.core_pattern- паттерн расположения и имени core-файла. В имени файла можно использовать следующие%-спецификаторы:%%- один % символ;%p- PID процесса для которого создан файл;%u- UID процесса для которого создан файл;%g- GID процесса для которого создан файл;%s- номер сигнала повлекшего создание файла;%t- время создание файла (количество секунд с 00:00 1 января 1970 года);%h- имя узла;%e- имя исполняемого файла.
-
Перезагрузить настройки в
/etc/sysctl.conf, выполнив команду:sudo sysctl -p
Установка отладочных пакетов
Существует несколько сценариев установки отладочных символов:
- При установке соответствующего флага в файле конфигурации скриптов автоматизации (для версий, начиная с 6.4.0). В таком случае установка отладочных символов компонента происходит автоматически в момент установки компонента.
Имена переменных для установки пакетов debuginfo (пакеты будут установлены в случае флагов в значении true) в custom_config_initial:
setup_debug_symbols:
pangolin_backup_tools: false # Install backup-tools-debuginfo package, contain debug symbols for origin backup-tools package
pangolin_dbms: false # Install dbms-debuginfo package, contain debug symbols for origin dbms-client package
pangolin_dbms_client: false # Install dbms-client-debuginfo package, contain debug symbols for origin dbms-client package
pangolin_manager: false # Install manager-debuginfo package, contain debug symbols for origin manager package
pangolin_pooler: false # Install pooler-debuginfo package, contain debug symbols for origin pooler package
pangolin_certs_rotate: false # Install certs-rotate-debuginfo package, contain debug symbols for origin certs-rotate package
pangolin_security_utilities: false # Install security-utilities-debuginfo package, contain debug symbols for origin security-utilities package
- В случае, когда отладочные символы не были установлены скриптами автоматизации в момент установки решения пользователь также производит их установку вручную путем запуска установки соответствующего отладочного пакета хранящегося в дистрибутиве продукта.
- Дополнительно доступен способ установки всех отладочных пакетов с помощью мета-пакета
pangolin-full-debuginfo. Подробнее в разделе «Мета-пакеты для процесса ручной пошаговой установки СУБД Pangolin».
Дистрибутив продукта доступен для скачивания из личного кабинета клиента.
Установка отладочных символов производится в стандартную директорию модуля, для которого они собраны, и размещается в одном каталоге с исполняемыми файлами/библиотеками. Отладочная информация собирается только для исполняемых файлов и библиотек.
Обновление отладочных пакетов
Существует несколько сценариев обновления отладочных символов:
-
Установку отладочных символов при обновлении с версий ниже 6.4.0 пользователь производит вручную (в т.ч. при выполнении обновления средствами скриптов автоматизации) путем запуска установки соответствующего отладочного пакета, хранящегося в дистрибутиве продукта.
-
При выполнении обновления средствами скриптов автоматизации, начиная с версии 6.4.0, обновление ранее установленных отладочных символов производится автоматически до версии, аналогичной устанавливаемым модулям, для которых они собраны. Обновление производится в том объеме, в котором отладочные символы были установлены ранее. При этом значения переменных словаря
setup_debug_symbols, установленных вcustom_config_initial, при обновлении игнорируются и вычисляются на основе ранее установленных пакетов. -
При выполнении ручного обновления, начиная с версии 6.4.0, отладочные символы должны быть удалены перед выполнением обновления модулей, для которых они собраны и установлены вручную.
Формирование стека вызова из core-файлов
При возникновении инцидента с генерацией снимка памяти процесса (core dupm) необходимо самостоятельно или с привлечением службы технической поддержи сформировать информативный стек вызовов в текстовом формате для его дальнейшего передачи разработчикам.
Под информативным стеком вызовов понимается стек с именами внутренних функций.
Пример неинформативного стека вызовов:
#0 0x00007fbc791d1b6f in ?? ()
#1 0x000000000080ef62 in ?? ()
#2 0x0000000000811070 in ?? ()
#3 0x000000000055cb93 in ?? ()
Пример максимально информативного стека вызовов:
#0 0x00007efe1d229b6f in select () from /lib64/libc.so.6
#1 0x0000000000811192 in ServerLoop ()
#2 0x0000000000813013 in PostmasterMain ()
#3 0x000000000055f0f3 in main ()
Примечание:
Отладочные пакеты компонентов решения не включают символы ряда используемых библиотек (не включенных в поставку), библиотек операционной системы (ОС), файлов ядра ОС и т.д.
При возникновении потребности в данных символах пользователь производит их поиск и установку самостоятельно.
Перед началом работ по получению стека вызовов из core-файла необходимо убедиться, что отладочные символы установлены.
Для формирования стека вызовов:
-
Запустите
gdbc передачей имени исполняемого файла (для которого сформирован core-файл) и имя core-файла. Пример:gdb /usr/pangolin-6.4/bin/postgres /tmp/core-postgres-6-1550075-1727167676 -
В интерактивном режиме
gdbвыполните команду для формирования трассы вызовов:(gdb) bt
Определение исполняемого файла для которого сформирован core-файл
Сore-файл содержит информацию об исполняемом файле, для которого он был сформирован. Для получения этой информации достаточно запустить gdb с передачей только core-файла. В момент загрузки файла gdb выведет информацию. Пример подобного вывода:
Core was generated by `/usr/pangolin-6.4/bin/postgres -D /pgdata/07/data'.
где /usr/pangolin-6.4/bin/postgres - имя исполняемого файла и путь к нему.
Наименование пакетов с отладочной информацией
Наименование пакетов, содержащих отладочную информация, совпадают с именами оригинальных пакетов и добавлением постфикса: -debuginfo. Например, оригинальный пакет: pangolin-dbms-6.3. Пакет с отладочной информацией: pangolin-dbms-6.3-debuginfo.
Наименование файлов, содержащих отладочную информацию
Наименование файлов, содержащих отладочные символы для исполняемых объектов, совпадают с именами файлов, для которых они собраны с добавлением суффикса: .debug. Пути расположения отладочных файлов полностью совпадают с путями расположения исполняемых файлов, для которых они были созданы.
Пример: отладочный файл для /usr/pangolin-6.4/bin/postgres будет назван /usr/pangolin-6.4/bin/postgres.debug.
Контроль целостности передачи WAL на реплику
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Для защиты от повреждения данных в случае неполадок оборудования СУБД Pangolin использует журнал предзаписи (WAL). Идея журналирования предварительной записи заключается в том, что прежде чем данные, измененные в результате выполнения транзакции, попадут на диск, в журнал предзаписи добавляется информация об этих изменениях, необходимая для восстановления результатов. Данные журнала используются не только для восстановления после сбоя, но и для работы репликации. Процесс WALSender читает зафиксированный на диске журнал предзаписи и отправляет WAL-записи на сервер-реплику, который находится в перманентном состоянии восстановления. На реплике полученные WAL-записи сохраняются на диск и проигрываются для применения к страницам с данными.
Для контроля целостности WAL-записи защищены CRC. Контрольная сумма при использовании WAL-записи проверяется в процессе восстановления данных (проигрывание WAL). Поздняя проверка CRC не позволяет восстановить запись, если данные WAL были повреждены при записи журнала на диск или при чтении перед отправкой. Наличие поврежденной записи журнала приводит к фатальной ошибке восстановления, что вызывает остановку репликации.
Процессы, влияющие на данные, перед фиксацией изменений помещают данные о выполнении в WAL-буфер, находящийся в разделяемой памяти. По мере заполнения циклического WAL-буфера данные сбрасываются на диск. Сброс осуществляется процессом, который добавляет новую запись или процессом WALWriter. Сброс на диск осуществляется не только по причине переполнения WAL-буфера, но и по таймеру. WALSender отправляет зафиксированные на диске WAL-записи для дальнейшего применения на реплике. Экземпляр реплики находится в состоянии постоянного восстановления - проигрывания WAL-записей с диска.
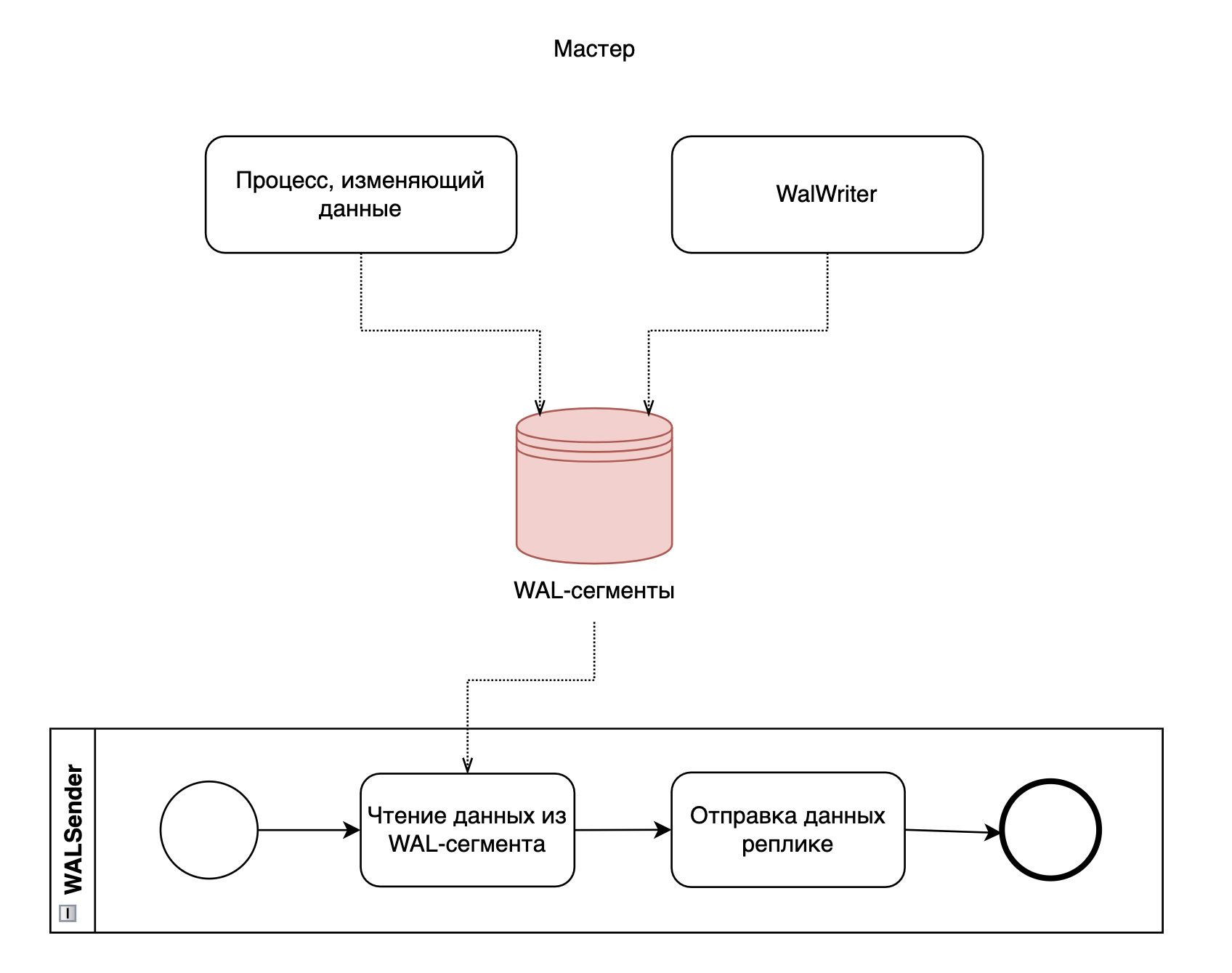
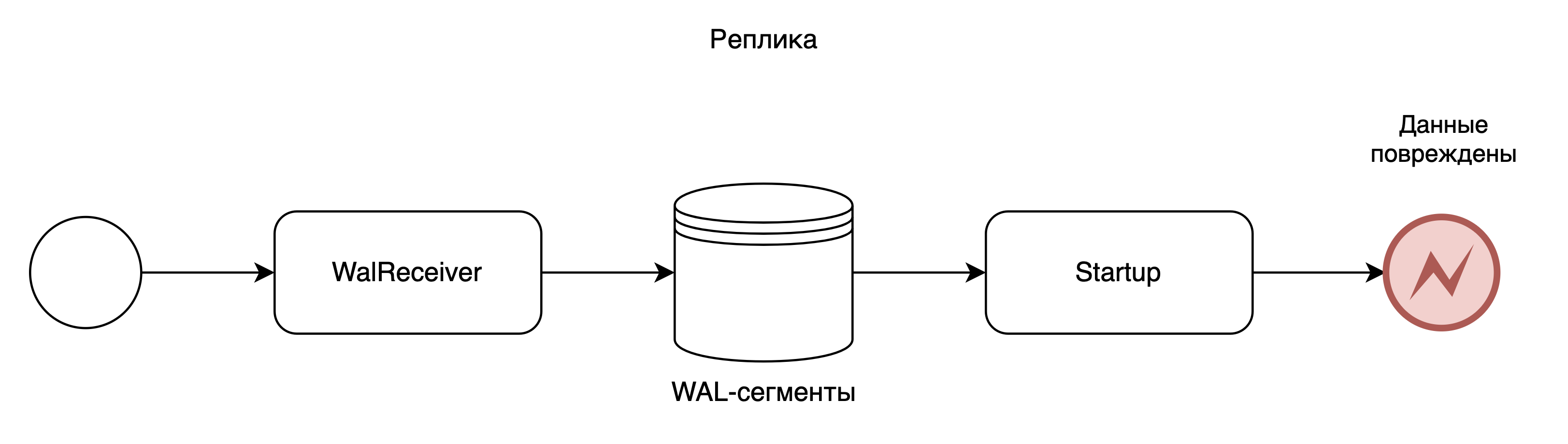
При записи или чтении с диска WAL-файл может быть поврежден, но в процессе отправки данных на реплику ошибка не будет определена, а проявится только на этапе применения WAL на реплике.
Внимание!
- Контроль целостности WAL происходит только при передаче данных на реплику и не используется в процессе восстановления данных после сбоя мастера.
- Восстановление поврежденных записей WAL происходит только на основном узле, при чтении данных с диска реплики контроль целостности не происходит.
Для сохранения резервной копии создается вспомогательный процесс WALRecoveryWriter, который получает блоки для записи копии WAL-сегмента и асинхронно записывает их в файл, аналогичный оригинальному WAL-сегменту с суффиксом backup в названии. Процесс WalSender перед отправкой проверяет данные, находящиеся в отправляемом сообщении. Если запись или заголовок блока повреждены, то происходит чтение поврежденной части из резервной копии журнала WAL-сегмента. Поврежденная часть заменяется резервной и происходит повторная проверка. Если не удалось восстановить поврежденные данные, то WAL-sender генерирует ошибку. То есть в случае повреждения WAL-данных ошибка будет происходить уже на мастере. При успехе попытки восстановления данные отправляются реплике.
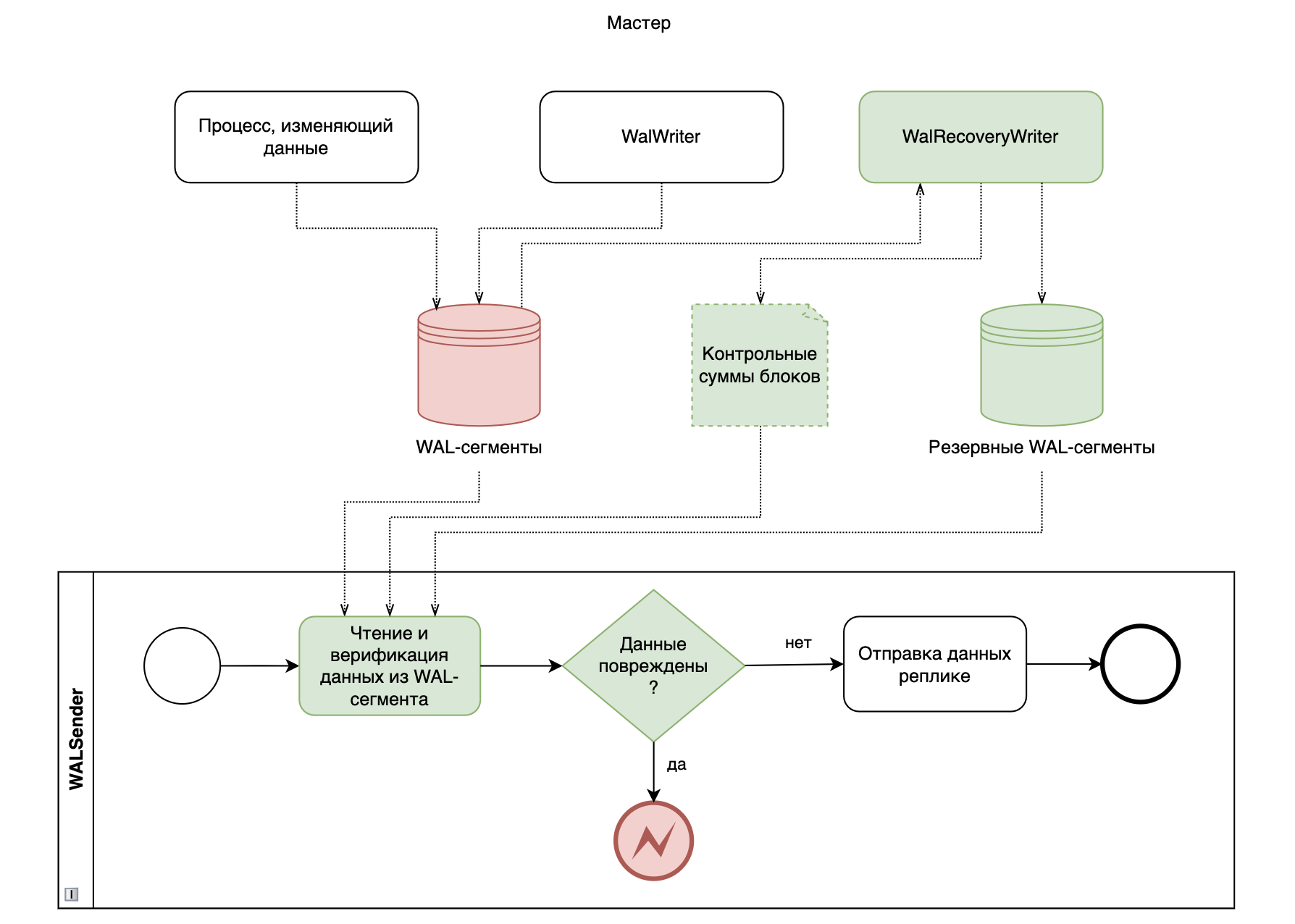
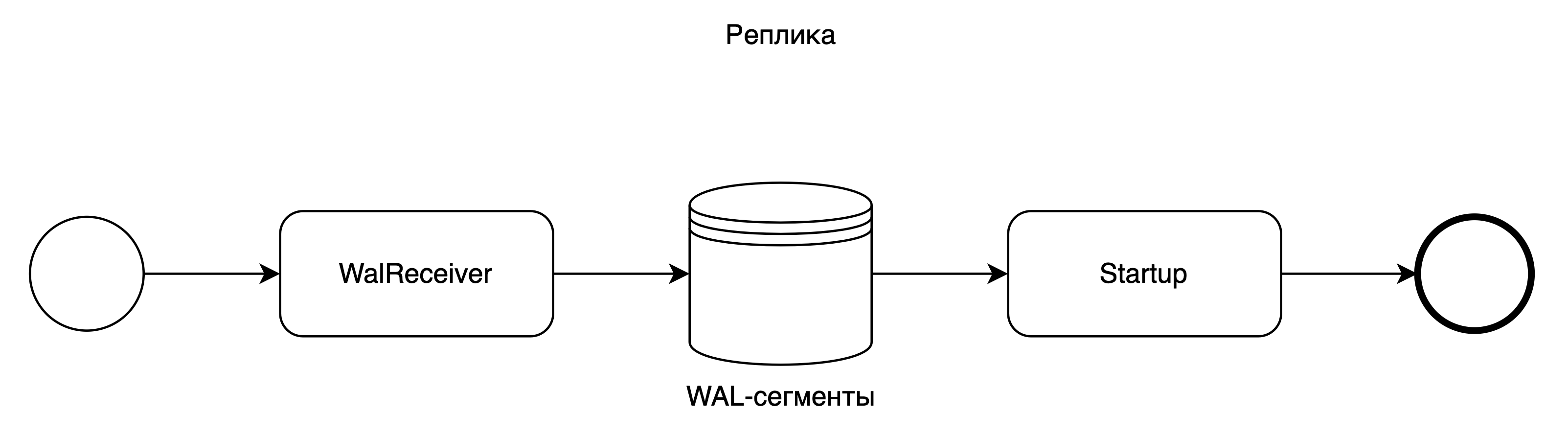
Конфигурационные параметры функциональности
К конфигурационным параметрам относятся:
-
wal_sender_check_crc- при включении этого параметра функциональность запускается. Параметр выключен по умолчанию, изменить его значение можно только на старте сервера. При значении параметраonпри запуске сервера инициируется процесс WALRecoveryWriter, а в разделяемой памяти создается очередь сообщений при передаче данных для сброса резервной копии WAL-данных на диск. -
wal_sender_panic_on_crc_error- при невозможности восстановления поврежденных WAL-данных, процесс WALSender поднимает ошибку уровняPANIC, когда данный параметр включен. По умолчанию параметр имеет значениеoff(выключено). В этом случае при невозможности восстановления поврежденной записи поднимается ошибка уровняFATAL. Параметр применяется только при включенном параметреwal_sender_check_crc. -
wal_sender_check_type- при значении параметраrecordиспользуется метод проверки корректности данных путем декодирования. При значенииblockиспользуется метод проверки контрольных сумм читаемых блоков. При значенииrecord, blockиспользуется гибридный метод. Параметр применяется только при включенном параметреwal_sender_check_crc. По умолчанию параметр имеет значениеrecord.Функциональность включает три способа контроля целостности:
- Проверка корректности данных путем декодирования.
- Проверка контрольных сумм читаемых блоков.
- Гибридная проверка с использованием контрольных сумм блоков и декодирования WAL-записей.
-
wal_sender_backup_directory- параметр, значением которого является путь до директории хранения резервных WAL-сегментов и файлов с контрольными суммами. По умолчанию используется$PGDATA/pg_wal. -
wal_sender_backup_strict- при значении параметраtrueсервер останавливается при недоступности. При значенииfalseпродолжает со стандартным значениемwal_sender_backup_directory.
Проверка корректности данных путем декодирования
WALSender проверяет контрольную сумму WAL-записей и корректность заголовка блока путем полного декодирования. Применяется только при включенном wal_sender_check_crc.
Конфигурационные параметры: wal_sender_check_crc = on, wal_sender_check_type = 'record'. Значение параметра wal_sender_panic_on_crc_error значения не имеет.
Ограничения решения:
- Декодирование WAL-записей требует дополнительного копирования данных записи для вычисления контрольной суммы. WAL-записи могут быть большого размера, а следовательно требуют большого объема временных буферов для верификации.
- При включенном преобразовании данных перед декодированием необходимо осуществить рассекречивание WAL-данных.
- Повреждение возможно не только в WAL-записях, но и в заголовках WAL-блоков, так как эти данные не защищены контрольной суммой. Некоторые поля могут быть проверены логически, но поля с битовыми флагами, а также таймлайны подлежат только проверке на валидность и не могут быть однозначно верифицированы.
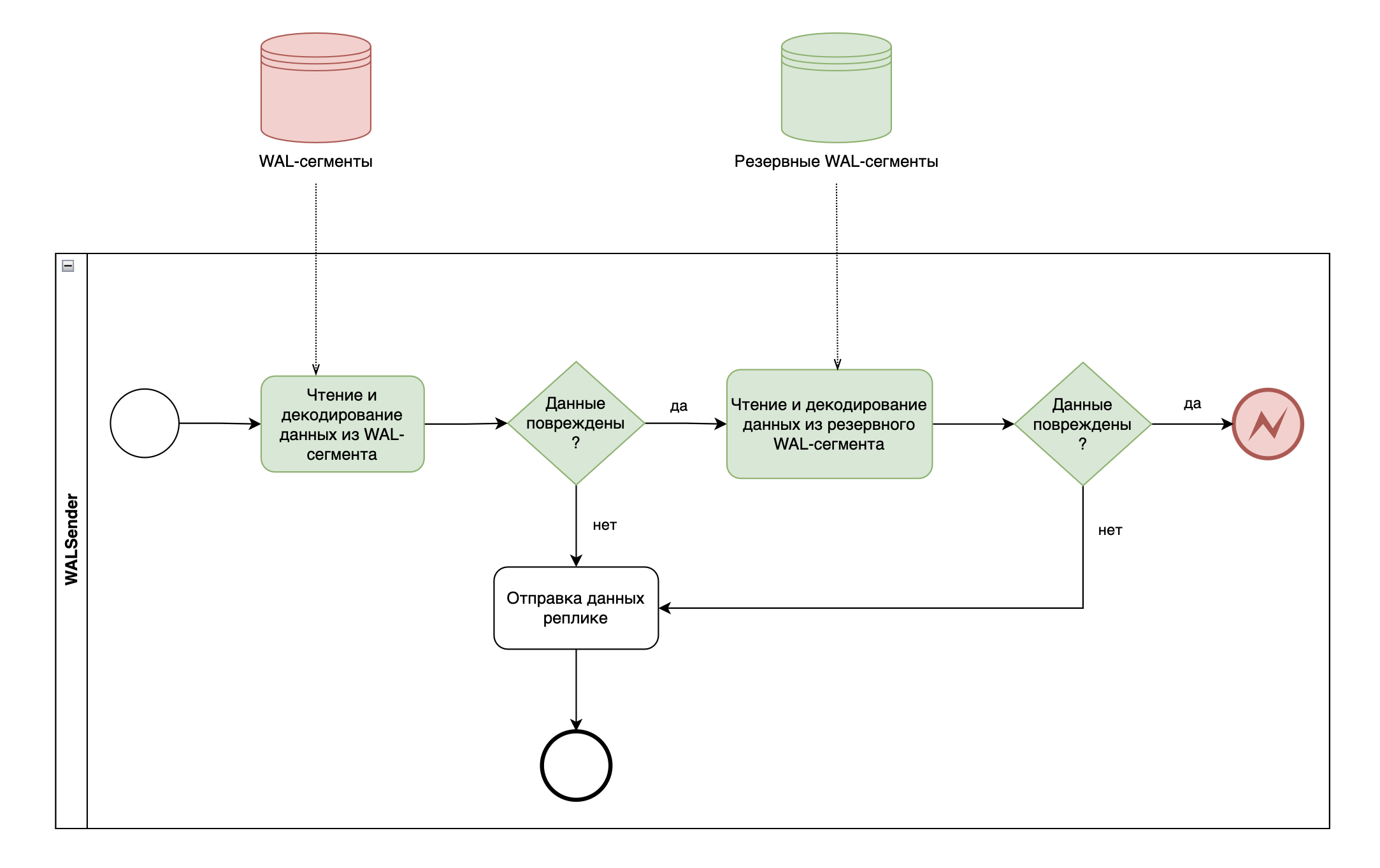
Проверка контрольных сумм читаемых блоков
WALRecoveryWriter генерирует дополнительный файл с контрольными суммами на каждый блок для каждого WAL-сегмента, а WALSender проверяет контрольную сумму прочитанного блока. По умолчанию этот параметр выключен (off) и применяется только при включенном wal_sender_check_crc.
Конфигурационные параметры: wal_sender_check_crc = on, wal_sender_check_type = 'block', значение параметра wal_sender_panic_on_crc_error значения не имеет.
Примечание:
Хранение контрольных сумм WAL-блоков в отдельном файле нарушает целостность данных и не несет гарантии, что непосредственно контрольная сумма не была повреждена.
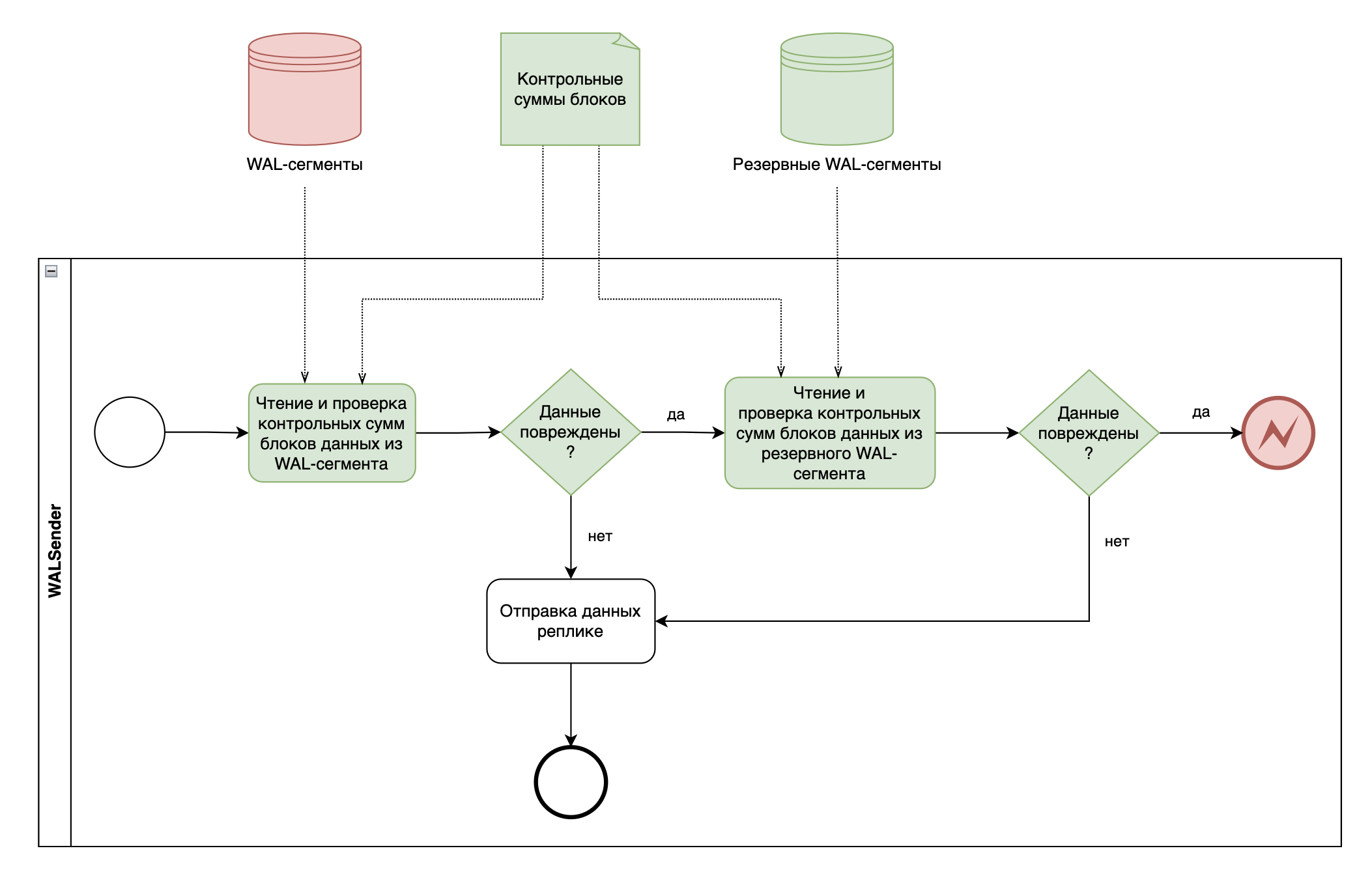
Гибридная проверка с использованием контрольных сумм блоков и декодирования WAL-записей
Конфигурационный параметр: wal_sender_check_crc = on, wal_sender_check_type = 'record, block', параметр wal_sender_panic_on_crc_error значения не имеет.
Возможен вариант конфигурации функциональности, когда применяются и проверка по контрольным суммам блока, и проверка путем декодирования. Это позволяет минимизировать ограничение повреждения контрольной суммы блока. Если записанная контрольная сумма блока не совпала с контрольной суммой из оригинального WAL-сегмента, а так же не совпала с контрольной суммой блока из резервной копии, то с высокой вероятностью повреждена именно контрольная сумма, а не оба (оригинальный и резервный) WAL-сегменты. Для того, чтобы удостовериться в этом предположении производится проверка данных путем декодирования.
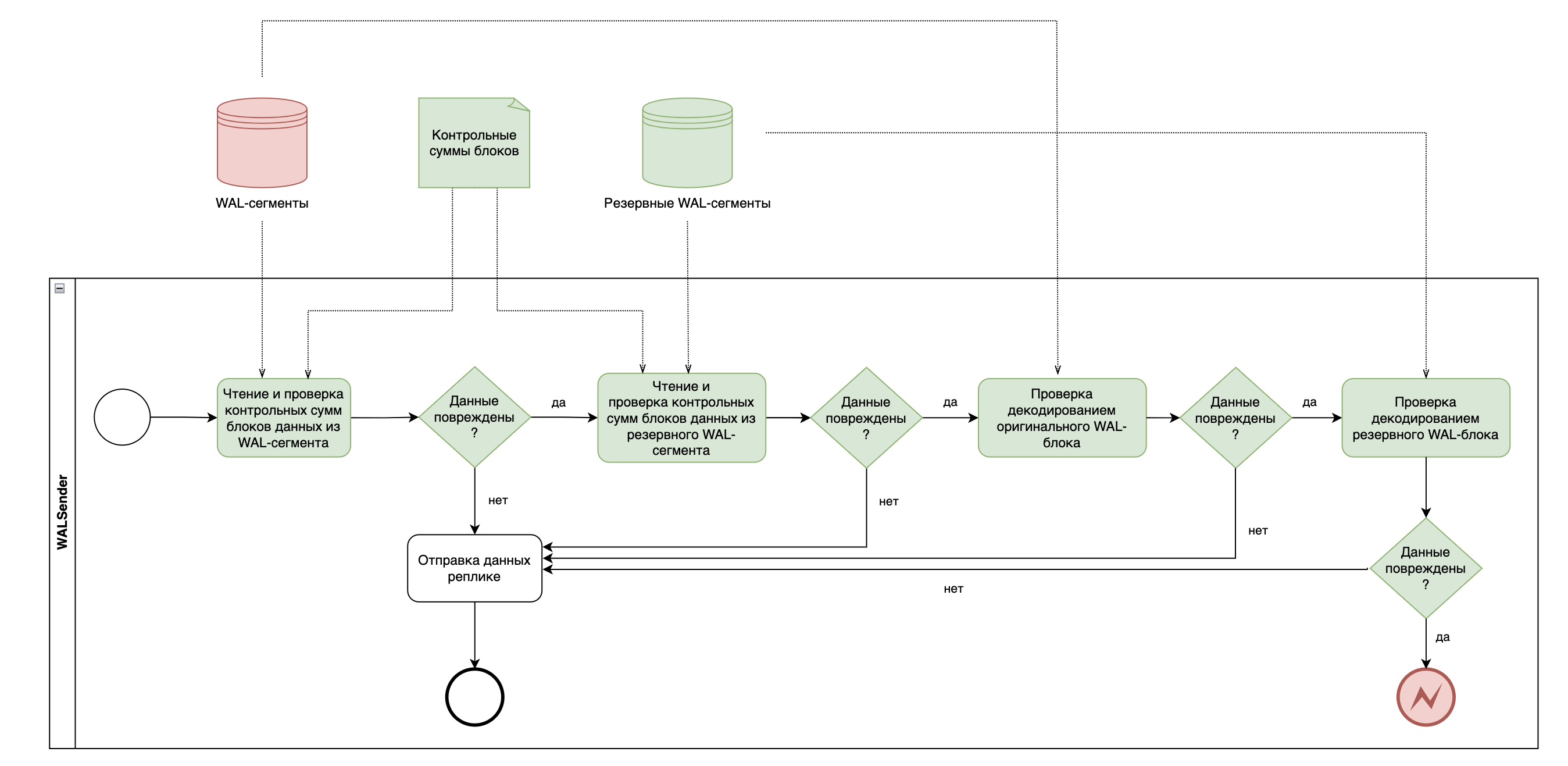
Параллельный анализ
Параллельный анализ улучшает производительности операции ANALYZE за счет использования нескольких рабочих процессов для одновременной обработки данных.
Параллельный анализ поддерживается параллелизацией операции ANALYZE:
- для нескольких таблиц одновременно;
- для одной таблицы с для сбора данных.
Внимание!
Приведенные методы несовместимы друг с другом.
Параллельный анализ для нескольких таблиц
Чтобы запустить параллельный анализ, используйте команду PARALLEL_ANALYZE <количество рабочих процессов>. Если количество рабочих процессов не указано — используется значение по умолчанию (GUC-параметр default_analyze_workers).
Примеры команд
-
Запуск с указанием количества рабочих процессов:
ANALYZE (PARALLEL_ANALYZE 4) table1, table2, ..., table100; -
Запуск с использованием значения по умолчанию:
ANALYZE (PARALLEL_ANALYZE) table1, table2, ..., table100;
Примечание:
Параллельный анализ работает с несколькими отношениями. Если при выполнении
ANALYZEуказаны несколько таблиц, разделенных запятыми, или если одно из отношений является разделенным, каждая таблица будет проанализирована разным рабочим процессом.
Особые случаи
- Временные отношения: не обрабатываются параллельно, выполняться последовательно через запускающий процесс.
- Только одно обычное отношение: одно обычное отношение обрабатывается запускающим процессом без запуска дополнительных рабочих процессов.
- Количество рабочих процессов
PARALLEL_ANALYZEпревышает количество отношений: запускается только необходимое количество рабочих процессов, так как для дополнительных рабочих процессов не будет работы.
Параметры конфигурации
default_analyze_workers
Описание: параметр определяет количество рабочих процессов, используемых по умолчанию для параллельного анализа, если количество рабочих процессов не указано.
Значение по умолчанию: 3.
Параллельный сбор данных для команды ANALYZE
Функция параллельного сбора данных для команды ANALYZE в PostgreSQL позволяет ускорить анализ больших таблиц, используя несколько рабочих процессов для параллельного сбора и выборки строк.
Доступна только для редакций Enterprise и Enterprise для ERP-систем.
Параметры конфигурации
| Параметр | Местоположение | Описание | Контекст | Минимум | Максимум | По умолчанию |
analyze_parallel_fetch | Файл postgresql.conf | Включает параллельный сбор данных во время выполнения ANALYZE: analyze_parallel_fetch = true | PGC_SIGHUP | - | - | false |
max_analyze_fetch_workers | Файл postgresql.conf | Максимальное количество рабочих процессов: max_analyze_fetch_workers = 3 | PGC_USERSET | 1 | MAX_BACKENDS | 3 |
min_pages_for_parallel_fetch | Файл postgresql.conf | Минимальное количество страниц для параллельного сбора данных: min_pages_for_parallel_fetch = 10000 | PGC_USERSET | 1000 | INT_MAX | 10000 |
Сценарии использования
Запуск ANALYZE с параллельным сбором данных
Когда параллельный сбор данных включен и таблица соответствует критериям (минимальное количество страниц и соответствующие настройки рабочих процессов), команда ANALYZE автоматически использует несколько рабочих процессов для сбора и выборки строк.
-
Запустите команду
ANALYZEдля целевой таблицы:ANALYZE <имя таблицы>; -
Проверьте журналы: следите за журналами PostgreSQL, чтобы получить информацию о процессе параллельного сбора данных. Уровень логирования для параллельных операций по умолчанию установлен на
DEBUG1, что предоставляет подробную информацию о выполнении:log_min_messages = debug1
Проверка возможности параллельного сбора данных
Параллельный сбор данных не будет использоваться в случаях, когда:
- Параллельный сбор данных отключен (
analyze_parallel_fetch = false). - Отношение является временной таблицей.
- Процесс уже находится в параллельном режиме или является процессом автоочистки (
AUTOVACUUM). - Таблица имеет меньше страниц, чем минимально указано (
min_pages_for_parallel_fetch). - Указано менее 2 рабочих процессов (
max_analyze_fetch_workers < 2). - Сервер не работает под процессом postmaster.
Логирование и мониторинг
Установите уровень логирования для мониторинга операций параллельного сбора данных:
log_min_messages = debug1
Проверяйте журналы на наличие записей, связанных с параллельным сбором данных, которые предоставят информацию о количестве использованных рабочих процессов, обработанных блоках и ходе анализа.
Параметры конфигурации для операций анализа
analyze_max_pages
Параметр определяет максимальное количество страниц, обрабатываемых за одну операцию анализа:
- тип данных:
integer; - по умолчанию:
0; - диапазон: от
0доINT_MAX.
Если этот параметр установлен на ненулевое значение, будет просканировано не более analyze_max_pages страниц за одну операцию анализа. Для партиционированных таблиц будет просканировано не более analyze_max_pages страниц из каждого раздела.
analyze_stat_array_size
Параметр определяет размер массива, используемого для хранения статистики анализа:
- тип данных:
integer; - по умолчанию:
-1; - диапазон: от
-1доINT_MAX.
Если этот параметр установлен на значение, отличное от -1, то как количество наиболее часто встречающихся значений (MCV), так и гистограммы будут установлены на analyze_stat_array_size.
Пример использования
В файле postgresql.conf параметры можно установить следующим образом:
analyze_max_pages = 1000 # Сканирует не более 1000 страниц во время анализа
analyze_stat_array_size = 200 # Устанавливает количество MCV и гистограмм на 200
Параметры настройки логической репликации
drop_repl_sync_slots_only_after_restart
Параметр определяет, будут ли не описанные в конфигурационном файле dcs-слоты синхронизации логической репликации удаляться только после рестарта СУБД или они удалятся как любые другие не описанные слоты репликации:
- тип данных:
boolean; - по умолчанию:
true.
Если этот параметр установлен на значение true, то не описанные в конфигурационном файле dcs-слоты синхронизации логической репликации будут удаляться только после рестарта СУБД. Иначе, если параметр установлен на значение false, такие слоты будут удаляться при тех же условиях, что и любые другие не описанные в конфигурационном файле dcs-слоты.
Пример использования
Данный параметр настраивается через команду edit-config утилиты pangolin-manager-ctl:
drop_repl_sync_slots_only_after_restart: false # Слоты синхронизации логической репликации не будут дропнуты без рестарта СУБД
forbid_create_pg_sync_slots_by_user
Параметр определяет, может ли пользователь создавать слоты с именем, как у слотов синхронизации логической репликации, то есть по шаблону pg_ЧИСЛО_sync_ЧИСЛО_ЧИСЛО:
- тип данных:
boolean; - по умолчанию:
false.
Если этот параметр установлен на значение on/true, то при попытке создать слот логической репликации с именем по шаблону pg_ЧИСЛО_sync_ЧИСЛО_ЧИСЛО (например, с именем pg_19732_sync_17854_7442686389907653644) будет выведена ошибка ERROR: pg_19732_sync_17854_7442686389907653644 matches forbidden pattern pg_%u_sync_%u_%llu that is used for logical replication synchronization slots. Иначе, если параметр установлен на значение off/false, можно будет создать слот с именем по шаблону pg_ЧИСЛО_sync_ЧИСЛО_ЧИСЛО.
Пример использования
В файле postgresql.conf параметр можно установить следующим образом:
forbid_create_pg_sync_slots_by_user = on # Будет запрещено создание слота с именем как у слота синхронизации логической репликации
Получение списка GUC-параметров Pangolin
Вызвать консольную утилиту get-pangolin-gucs:
/opt/pangolin-manager/bin/get-pangolin-gucs
Утилита выводит список параметров. Пример вывода:
[postgres ~]$ /opt/pangolin-manager/bin/get-pangolin-gucs
allow_in_place_tablespaces
allow_system_table_mods
allowed_servers
analyze_max_pages
analyze_parallel_fetch
analyze_stat_array_size
...
Для фильтрации списка параметров доступна опция -s (или --search), поиск не чувствителен к регистру и поддерживает регулярные выражения, например:
/opt/pangolin-manager/bin/get-pangolin-gucs -s pg_*
Поддержка сжатия данных при записи на диск
В рамках данной функциональности реализован алгоритм сохранения данных, позволяющий прозрачно их сжимать при сохранении на дисковый ресурс и разжимать при получении обратно. Это позволяет экономить ресурсы памяти и хранить исторические, малоактуальные данные экономней.
Функциональность решает задачи:
- минимизации дисковых ресурсов для хранения данных;
- эффективного хранения архивных данных, включая партиции, материальные представления и индексы;
- выбора алгоритма сжатия, его степени, а также количества сжимаемых блоков;
- контроль отсутствия изменений в процедуре снятия архивных/резервных копий при наличии сжатых объектов.
Описание
Сжатие данных на уровне страниц (блоков) в СУБД - это метод сжатия содержимого файлов отношений (таблиц, материализованных представлений и индексов) путем применения к страницам алгоритма сжатия.
Применение данного подхода позволяет достичь следующих целей:
- экономить место на диске;
- снижать нагрузку на подсистему ввода/вывода;
- снизить расход RAM под страничный кеш ОС.
Основной принцип механизма сжатия на уровне страниц состоит в следующем:
- При записи страницы на диск данные, содержащиеся в этой странице, сжимаются и сохраняются в файле сжатых данных (PCD - page compressed data), а место хранения каждой страницы в файле сжатых данных записывается в файл адресов сжатых данных (PCA - page compressed address).
- При чтении страницы сначала производится поиск соответствующего места хранения страницы в адресном файле (PCA), затем считываются необходимые данные из файла сжатых данных (PCD) с последующей декомпрессией для восстановления исходной страницы.
Формат хранения несжатых данных отношений
Несжатое отношение хранится в отдельном файле, именуемом по номеру файлового узла, который содержится в pg_class.relfilenode (NNNN). Этот файл называется главным или основным слоем. Помимо главного файла у каждого отношения есть файл с картой свободного пространства с суффиксом _fsm (NNNN_fsm) и файл с картой видимости с суффиксом _vm (NNNN_vm). Нежурналируемые отношения имеют файл инициализации, имя которого содержит суффикс _init (NNNN_init). Когда размер отношения превышает 1 ГБ, главный файл делится на сегменты размером в 1 ГБ. Файл первого сегмента именуется по номеру файлового узла (NNNN), а последующие сегменты получают имена NNNN.1, NNNN.2 и т. д.
Все страницы сегмента одинакового размера (по 8 КБ) и на диске располагаются в фиксированных позициях по порядку.
Формат хранения сжатых данных отношений
В случае сжатого отношения сегменты основного слоя создаются на диске, но с нулевым размером. К каждому сегменту добавляются следующие два файла:
- файл с суффиксом
_pcd(NNNN_pcd) - файл сжатых данных (PCD-файл, page compressed data); - файл с суффиксом
_pca(NNNN_pca) - файл адресов сжатых данных (PCA-файл, page compressed address).
Описание PCD-файла
В PCD-файле хранится сжатое содержимое страницы. Чтобы упростить доступ к метаданным страниц, заголовок каждой страницы не сжимается.
Одна сжатая страница (PageCompressData) состоит из частей:
| Поле | Размер | Описание |
|---|---|---|
| page_header | 24 байта | Данные заголовка страницы |
| size | 2 байта | Размер сжатых данных |
| data | Не фиксирован | Сжатые данные |
Основной единицей хранения в сжатом файле данных является фрагмент (chunk). Сжатая страница хранится в виде одного или нескольких фрагментов. Незанятое пространство фрагмента заполняется нулями. Размер каждого фрагмента настраивается на уровне отношений и может составлять 1/16, 1/8, 1/4 или 1/2 от BLCKSZ (размер блока - 8 КБ). Чем меньше размер фрагмента, тем выше степень сжатия, но и выше риск фрагментации.
Каждый фрагмент состоит из двух частей: заголовка и данных. Структура заголовка (PageCompressChunk) представлена в таблице:
| Поле | Размер | Описание |
|---|---|---|
| blockno | 4 байта | Номер страницы, хранящейся в этом фрагменте |
| chunkseq | 1 байт | Последовательный номер фрагмента, начиная с 1, для проверки, что сжатая страница собирается из фрагментов в правильном порядке |
| withdata | 1 байт | Флаг, указывающий на наличие данных в данном фрагменте |
| checksum | 2 байта | Контрольная сумма фрагмента |
В части данных фрагмента хранится сжатая страница:
chunk header N.1- заголовок первого фрагмента N-ой страницы сегмента,chunk header N.2- заголовок второго фрагмента N-ой страницы сегмента и т.д.;page header N- заголовок N-ой страницы сегмента;size- размер сжатой страницы как сумма размеров сжатых данных во всех фрагментах страницы. Например, для нулевой страницы это сумма размеров данных, расположенных в поляхcompressed data 0.1,compressed data 0.2,compressed data 0.3иcompressed data 0.4;compressed data N.1- часть сжатой N-ой страницы, помещенной в первый фрагмент,compressed data N.2- часть сжатой N-ой страницы, помещенной во второй фрагмент и т.д.
Доступ к PCD-файлам осуществляется с помощью системных вызовов read() и write().
Описание PCA-файла
PCA-файл используется для хранения информации о распределении фрагментов в PCD-файле. Его содержимое включает заголовок и несколько адресов. В заголовке (PageCompressHeader) содержится информация, представленная в таблице:
| Поле | Размер | Описание |
|---|---|---|
| nblocks | 4 байта | Общее количество страниц (блоков) |
| allocated_chunks | 4 байта | Общее количество фрагментов, выделенных в PCD-файле |
| algorithm | 1 байт | Алгоритм сжатия: 1 - pglz, 2 - lz4, 3 - zstd |
| level | 1 байт | Уровень сжатия. Имеет эффект только при выборе алгоритма сжатия zstd. Диапазон значений зависит от версии библиотеки zstd и определяется путем вызова библиотечных функций ZSTD_minCLevel(), ZSTD_maxCLevel(). Версия zstd v1.4.4 позволяет установить значения в диапазоне [1-19]. Чтобы узнать, какой диапазон значений поддерживает версия библиотеки zstd в текущем окружении, необходимо выполнить команду в терминале: ```$ zstd 2>&1 |
| chunks_per_block | 1 байт | Число фрагментов для хранения сжатых данных одной страницы |
| prealloc_chunks | 1 байт | Число предварительно выделенных фрагментов для хранения сжатых данных одной страницы |
Каждая адресная запись соответствует одной странице. В таблице ниже показана информация, содержащаяся в адресной записи:
| Поле | Размер | Описание |
|---|---|---|
| nchunks | 1 байт | Количество фрагментов, фактически используемых для хранения сжатой страницы |
| allocated_chunks | 1 байт | Количество фрагментов, выделенных для хранения сжатой страницы |
| chunknos | 4 * (2, 4, 8 или 16) + 4 байтов | Массив из номеров фрагментов |
Поскольку однажды выделенный фрагмент для сжатой страницы закрепляется за ней, то значения nchunks и allocated_chunks могут не совпадать, например, в следующих случаях:
- количество предварительно выделенных фрагментов больше числа фрагментов, в которых может разместиться сжатая страница;
- после обновления таблицы для хранения сжатой страницы требуется меньшее количество фрагментов, чем было использовано ранее.
Размер массива номеров фрагментов рассчитывается как BLCKSZ/(размер фрагмента) + 1, то есть максимальный размер одной сжатой страницы может занимать пространство BLCKSZ + (размер фрагмента):
- для размера фрагмента 1/16 от BLCKSZ (512 байт) - 17 фрагментов (8704 байт);
- для размера фрагмента 1/8 от BLCKSZ (1024 байт) - 9 фрагментов (9216 байт);
- для размера фрагмента 1/4 от BLCKSZ (2048 байт) - 5 фрагментов (10240 байт);
- для размера фрагмента 1/2 от BLCKSZ (4096 байт) - 3 фрагмента (12288 байт).
Достижение этого максимального размера может быть вызвано ошибкой сжатия или его неэффективным применением, приводящим к низкой степени компрессии, например, при сжатии бинарных данных с высокой энтропией: преобразование данных или уже сжатой информации (JPEG, H.264 и пр.). В этих случаях страница сохраняется в PCD-файл без сжатия, чтобы избежать лишних накладных расходов на разжатие данных при чтении с диска.
Примечание:
При большом количестве страниц, не поддающихся сжатию, рекомендуется не использовать постраничное сжатие для отношений, так как это приведет к расходу дискового пространства и росту потребления CPU.
Внимание!
Сжатие данных на уровне страниц не является подходящим решением для таблиц небольшого размера.
Использование сжатия
Для использования функциональности сжатия необходимо включить параметр enable_page_compression.
Параметр enable_page_compression заполняется в конфигурационном файле postgres.yml в секции postgresql с помощью текстового редактора.
Для применения параметра достаточно перечитать конфигурацию (reload).
Сжатие можно настроить как для определенных отношений, так и для конкретных табличных пространств.
Сжатие поддерживается для следующих типов объектов БД:
- обычные таблицы;
- партиционированные таблицы;
- материализованные представления;
- индексы, встроенные в ядро Pangolin: B-Tree, Hash, GiST, SP-GiST и GIN.
Чтобы включить сжатие для объекта БД, необходимо при его создании установить параметры:
compresstype- алгоритм сжатия:pglz,lz4,zstd;compresslevel- уровень сжатия. Параметр применим только для алгоритмаzstd. Диапазон значений -[0-19].0- установить значение по умолчанию для текущего алгоритма сжатия (в библиотекеzstdv1.4.4 уровень сжатия по умолчанию равен 3);compress_chunk_size- размер фрагмента в байтах: 512, 1024, 2048, 4096.compress_prealloc_chunks- число предварительно выделенных фрагментов для хранения сжатых данных одной страницы. Максимальное значение ограничивается числомBLCKSZ/compress_chunk_size - 1.
Параметр compresstype является обязательным для включения сжатия. Если параметр compress_chunk_size не задан, его значение по умолчанию будет равно 4096. Уровень сжатия compresslevel и число предустановленных фрагментов compress_prealloc_chunks, если не указано иное, будут равны 0.
Примеры создания объектов БД с параметрами сжатия:
CREATE TABLE compressed_table_1(id int PRIMARY KEY, c1 text) WITH (compresstype=pglz); -- первичный ключ compressed_table_1_pkey без параметров сжатия.
CREATE TABLE compressed_table_2(id int PRIMARY KEY WITH(compresstype=pglz, compress_chunk_size=1024), c1 text) WITH (compresstype=pglz, compress_chunk_size=512); -- первичный ключ compressed_table_2_pkey с параметрами сжатия.
CREATE TABLE compressed_table_3(id int PRIMARY KEY, c1 text) WITH (compresstype=pglz, compresslevel=0, compress_chunk_size=1024);
CREATE TABLE compressed_table_4(id int PRIMARY KEY, c1 text) WITH (compresstype=pglz, compresslevel=1, compress_chunk_size=2048, compress_prealloc_chunks=0);
CREATE MATERIALIZED VIEW compressed_mv_1 WITH (compresstype=pglz, compresslevel=0, compress_chunk_size=1024) AS SELECT id, c1 FROM compressed_table_1 WHERE id <= 10;
CREATE INDEX compressed_table_1_idx_1 on compressed_table_1 USING btree(c1) WITH(compresstype=pglz, compresslevel=1, compress_chunk_size=1024, compress_prealloc_chunks=2);
CREATE INDEX compressed_table_1_idx_2 on compressed_table_1 USING hash(c1) WITH(compresstype=pglz, compresslevel=1, compress_chunk_size=1024, compress_prealloc_chunks=2);
CREATE INDEX compressed_table_1_idx_3 on compressed_table_1 USING gin((ARRAY[id])) WITH(compresstype=pglz, compresslevel=1, compress_chunk_size=1024, compress_prealloc_chunks=2);
CREATE INDEX compressed_table_1_idx_4 on compressed_table_1 USING gist((point(id,id))) WITH(compresstype=pglz, compresslevel=1, compress_chunk_size=1024, compress_prealloc_chunks=2);
CREATE INDEX compressed_table_1_idx_5 on compressed_table_1 USING spgist(c1) WITH(compresstype=pglz, compresslevel=1, compress_chunk_size=1024, compress_prealloc_chunks=2);
Для упрощения управления базами данных параметры сжатия можно задать сразу для табличного пространства, вместо того чтобы вводить их каждый раз при создании нового объекта. Если параметры сжатия не были установлены для конкретного объекта, они будут наследоваться от табличного пространства.
Примеры создания табличных пространств с параметрами сжатия и таблиц в сжатом табличном пространстве:
CREATE TABLESPACE compressed_tablespace_1 LOCATION '' WITH (compresstype=pglz);
CREATE TABLESPACE compressed_tablespace_2 LOCATION '' WITH (compresstype=pglz, compress_chunk_size=512);
CREATE TABLESPACE compressed_tablespace_3 LOCATION '' WITH (compresstype=pglz, compresslevel=0, compress_chunk_size=1024);
CREATE TABLESPACE compressed_tablespace_4 LOCATION '' WITH (compresstype=pglz, compresslevel=1, compress_chunk_size=2048, compress_prealloc_chunks=0);
CREATE TABLE uncompressed_table(id int, c1 text) WITH (compresstype=none) TABLESPACE compressed_tablespace_1; -- таблица uncompressed_table не наследует опции сжатия табличного пространства compressed_tablespace_1, поэтому остается не в сжатом виде.
CREATE TABLE compressed_table_1(id int, c1 text) TABLESPACE compressed_tablespace_1; -- таблица compressed_table_1 наследует опции сжатия табличного пространства compressed_tablespace_1.
CREATE TABLE compressed_table_2(id int, c1 text) WITH (compresstype=pglz, compresslevel=0, compress_chunk_size=1024) TABLESPACE compressed_tablespace_1; -- таблица compressed_table_2 не наследует опции сжатия табличного пространства compressed_tablespace_1, так как для нее уже заданы опции сжатия.
CREATE MATERIALIZED VIEW uncompressed_mv WITH (compresstype=none) TABLESPACE compressed_tablespace_1 AS SELECT id, c1 FROM uncompressed_table WHERE id <= 10; -- материализованное представление uncompressed_mv не наследует опции сжатия табличного пространства compressed_tablespace_1, поэтому остается не в сжатом виде.
CREATE MATERIALIZED VIEW compressed_mv_1 TABLESPACE compressed_tablespace_1 AS SELECT id, c1 FROM uncompressed_table WHERE id <= 10; -- материализованное представление compressed_mv_1 наследует опции сжатия табличного пространства compressed_tablespace_1.
CREATE MATERIALIZED VIEW compressed_mv_2 WITH (compresstype=pglz, compresslevel=0, compress_chunk_size=1024) TABLESPACE compressed_tablespace_1 AS SELECT id, c1 FROM uncompressed_table WHERE id <= 10; -- материализованное представление compressed_mv_2 не наследует опции сжатия табличного пространства compressed_tablespace_1, так как для него уже заданы опции сжатия.
Изменение параметров сжатия не поддерживается, поэтому для преобразования таблицы из сжатого состояния в несжатое и наоборот, включая возможность изменения параметров, следует использовать следующие SQL-команды:
CREATE TABLE uncompressed_table AS SELECT * FROM compressed_table;
CREATE TABLE new_compressed_table WITH (compresstype=pglz, compresslevel=0, compress_chunk_size=1024) AS SELECT * FROM compressed_table;
Чтобы оценить, насколько уменьшится размер объекта БД после сжатия, можно воспользоваться функцией relation_estimate_compression_ratio(), доступной в расширении pageinspect. Результат этой функции поможет решить, стоит ли тратить ресурсы процессора на сжатие объекта. Функция имеет следующее определение:
CREATE FUNCTION relation_estimate_compression_ratio(
relation regclass, -- имя объекта БД
algorithm text, -- алгоритм сжатия
level integer, -- уровень сжатия
chunk_size integer, -- размер фрагмента
in_chunks boolean, -- выдать результат с учетом размещения сжатых данных по выделенным фрагментам
first_block integer, -- номер первой страницы, с которой начнется анализ
last_block integer -- номер последней страницы (включительно), на которой анализ закончится
) RETURNS double precision
AS 'MODULE_PATHNAME', 'relation_estimate_compression_ratio'
LANGUAGE C PARALLEL SAFE;
Первые два аргумента relation и algorithm обязательные. Остальные, если не указаны, принимают значения:
level = 0;chunk_size = 4096;in_chunks = FALSE;first_block = 0;last_block = 10(или количество страниц, выделенных для хранения объекта БД, если оно меньше 10).
Функция анализирует страницы объекта БД в диапазоне номеров [first_block, last_block] и пытается их сжать. Затем функция вычисляет среднее значение коэффициента сжатия. Например, если функция вернет значение 2.9, это будет означать, что сжатый объект БД будет занимать примерно в 3 раза меньше места, чем исходный. Если аргумент in_chunks имеет значение FALSE, то результатом будет оценка эффективности сжатия определенного алгоритма для набора данных в выбранном диапазоне номеров страниц. Если же требуется оценить реальный размер сжатых данных на диске, то следует установить значение in_chunks в TRUE. В этом случае будет учитываться значение аргумента chunk_size: чем меньше значение chunk_size (чем выше гранулярность сжатых данных), тем больше вероятность, что сжатые данные займут меньше места на диске.
Ограничения функциональности
- Параметр
full_page_writesдолжен быть включен. В таких сценариях, как сбой сервера или оперативное резервное копирование, страницы сжатых объектов БД с большей вероятностью будут находиться в несогласованном состоянии, чем обычные несжатые объекты, и их необходимо восстанавливать с помощью полностраничной записи. - Не поддерживается сжатие таблиц системного каталога, временных таблиц, последовательностей, индекса Brin и глобального индекса.
- Не рекомендуется использовать постраничное сжатие данных отношений, расположенных в преобразованном табличном пространстве (TDE). В настоящее время сжатие происходит после защитного преобразования данных, что снижает эффективность этого процесса.
- В процессе очистки (VACUUM) не поддерживается удаление пустых страниц в конце сегмента сжатого отношения. Возможно только усечение всего сегмента. Поскольку свободные страницы в конце сегмента могут быть представлены не в виде непрерывных фрагментов в конце PCD-файла, сокращение этих страниц может не привести к значительной экономии места в хранилище, а также может вызвать несогласованность содержимого файла сжатых данных (PCD) и файла сжатых адресов (PCA).
- Постраничное сжатие не подходит для сжатия отношений небольшого размера. PCA-файл должен иметь определенный фиксированный размер на диске, который зависит от размера фрагмента: чем меньше размер фрагмента, тем больше размер файла. Например, при размере фрагмента 512 байт он составит около 9 МБ, поэтому для слишком маленьких отношений общее пространство, занимаемое файлами сжатых данных (PCA + PCD), может оказаться больше, чем без сжатия.
- Не поддерживается изменение параметров сжатия.
- Было произведено удаление кода, обеспечивающего обратную совместимость с предыдущей минорной версией, так как для текущей версии (7.1.0) это неактуально.
На этапе запуска СУБД отсутсвует проверка наличия сжатых объектов, если функциональность отключена. Параметр enable_page_compression запрещает создавать новые сжатые объекты. Поддержка сжатых объектов, созданных до отключения сжатия, сохраняется.
Тюнинг параметров
Примечание:
В версии 6.5.0 добавляется утилита Pangolin Tuner (pangolin-tuner), которая предоставляет гибкое и эффективное управление конфигурацией СУБД, оптимизируя ее производительность путем тонкой настройки параметров (список конфигурируемых параметров см. в подразделе «Формулы расчета параметров»).
Утилита поставляется в виде отдельного RPM-пакета
pangolin-tuner-{version_component}-{OS}.x86_64.rpmв основной части дистрибутива продукта СУБД Pangolin. При установке будет создан рабочий каталог/opt/pangolin-tuner.
Pangolin Tuner — это инструмент для работы с конфигурацией СУБД Pangolin, предназначенный для оптимизации производительности баз данных в различных сценариях использования. Инструмент автоматически определяет оптимальные настройки в зависимости от профиля рабочей нагрузки / профиля использования. Это позволяет значительно сократить время настройки и минимизировать риски, связанные с неправильной конфигурацией.
Утилита не требует наличия установленной СУБД Pangolin на целевом сервере и поддерживает опциональные параметры для расчета, что делает ее универсальным инструментом для различных сценариев установки СУБД Pangolin.
Схема процесса работы утилиты:
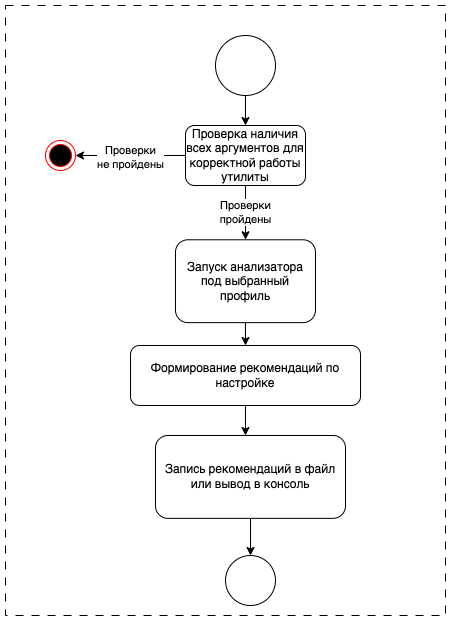
Настройка
В разделе описываются основные функции и возможности инструмента.
Утилита использует набор предопределенных формул для вычисления оптимальных значений параметров конфигурации СУБД Pangolin. Эти формулы учитывают:
- выбранный профиль (OLAP, OLTP, 1C);
- характеристики локального стенда (CPU, MEM и дисковое пространство);
- опциональные параметры (
dtype,cpu,mem,dbmsver).
Минимальные значения для расчета параметров конфигурации:
CPU = 4
MEM = 8GB
Профили использования
Pangolin Tuner поддерживает три готовых профиля рабочей нагрузки, каждый из которых адаптирован под конкретные потребности:
- OLAP: Оптимизация для аналитических запросов, характеризующихся обработкой больших объемов данных и сложными вычислениями. Настройки ориентированы на оптимизацию агрегации данных, параллельности выполнения задач и эффективного использования ресурсов памяти.
- OLTP: Оптимизация для транзакционных операций, где приоритетом является высокая скорость обработки, низкая задержка и целостность данных. Настройки направлены на минимизацию блокировок, оптимизацию ввода/вывода и эффективное использование ресурсов процессора.
- 1C: Специфическая конфигурация для интеграции с системой 1C:Предприятие. Настройки учитывают особенности взаимодействия с платформой 1C, оптимизируя производительность для типичных сценариев использования. Содержит рекомендации по параметрам с фиксированными значениями.
Опциональные параметры утилиты
Утилита предоставляет гибкие настройки для оптимизации выполнения задач в различных сценариях. Эти настройки позволяют пользователям адаптировать утилиту под конкретные требования, такие как тип дискового пространства, использование процессорных ресурсов, объем оперативной памяти и версия СУБД.
В случае, если утилита развернута не на том стенде, где будет эксплуатироваться СУБД Pangolin — расчет будет производится на основе значений переданных параметров.
| Параметр | Описание | Значение |
dtype | Тип дискового пространства | Варианты значений: HDD (по умолчанию), SSD |
cpu | Количество процессорных ядер или процессоров | Варианты значений: 4 и более |
mem | Объем оперативной памяти (RAM) | Варианты значений: 8GB и более |
dbmsver | Версия СУБД | Значение в формате: x.x.x (например, 6.5.0) |
Формулы расчета параметров
В таблицы описываются формулы по которым утилита Pangolin Tuner формирует значение параметров конфигурации.
Параметры памяти
| Параметр | Описание | Формула расчета |
|---|---|---|
shared_buffers | Определяет количество памяти, выделенной для кеширования данных | Все профили: RAM <= 32GB - 25% RAM > 32GB - 40% В случае, если итоговое значение будет > 50GB, то по умолчанию будет выставлено 50GB для корректного запуска БД с комментарием: '# для оптимальной производительности для данного объема MEM требуется установить shared_buffers в рекомендованное значение - {shared_buffers}GB, huge_pages=on, а также выставить на уровне ОС значения: vm.nr_hugepages=<количество больших страниц> vm.hugetlb_shm_group=<GID для группы postgres>'. где {shared_buffers} - это реальное итоговое значение. Реальное итоговое значение будет использоваться в расчетах других рекомендованных параметров для настройки |
work_mem | Определяет количество памяти, выделенной для сортировки и хеширования | OLTP: 16MB 1С: 256MB OLAP: min (512MB, (RAM * shared_buffers) / 10 / 5) |
maintenance_work_mem | Определяет количество памяти, выделенной для операций обслуживания базы данных, таких как VACUUM, CREATE INDEX, и ALTER TABLE | Все профили: RAM <= 8GB: 512MB 8GB < RAM <= 32GB: 1GB 32GB < RAM <= 64GB: 2GB 64GB < RAM: 4GB |
effective_cache_size | Определяет предполагаемый размер кеша операционной системы | Все профили: RAM - 2GB - shared_buffers |
temp_buffers | Определяет количество памяти, выделенной для временных таблиц и временных файлов | OLTP: RAM GB <= 32: 8MB RAM GB > 32: 16MB 1С: RAM GB <= 32: 128MB 32 < RAM GB <= 128: 256МБ RAM GB > 128: 512МБ OLAP: RAM GB < 256: 32MB RAM GB >= 256: 64MB |
random_page_cost | Определяет стоимость случайного чтения страницы с диска | OLTP: 1.1 1С: 1.1 OLAP: 2.0 |
seq_page_cost | Определяет стоимость последовательного чтения страницы с диска | Все профили: 1.0 |
cpu_tuple_cost | Определяет стоимость обработки одной строки данных | Все профили: 0.01 |
from_collapse_limit | Определяет максимальное количество таблиц в запросе, при котором планировщик будет пытаться объединить их в один подзапрос | OLTP: 8 1С: 11 OLAP: 8 |
join_collapse_limit | Определяет максимальное количество таблиц в запросе, при котором планировщик будет пытаться объединить их в один подзапрос | OLTP: 8 1С: 11 OLAP: 8 |
geqo | Управляет включением или отключением генетического оптимизатора запросов | Все профили: on |
geqo_threshold | Определяет порог сложности запроса, при превышении которого генетический оптимизатор будет использоваться | Все профили: 12 |
log_min_duration_statement | Определяет минимальную продолжительность выполнения запроса, при которой он будет записан в журнал | OLTP: 3000 1С: 3000 OLAP: 60000 |
Параметры производительности
| Параметр | Описание | Формула расчета |
|---|---|---|
max_prepared_transactions | Определяет максимальное количество подготовленных транзакций | OLTP: 01С: 256OLAP: 0 |
max_worker_processes | Определяет максимальное количество фоновых процессов | Все профили:CPU <= 12: 12CPU > 12: CPU |
effective_io_concurrency | Определяет количество одновременных операций ввода-вывода | Все профили: - для машин с SSD: 200- для машин с HDD: количество дисков в массиве, например 10 |
max_parallel_workers | Определяет максимальное количество параллельных рабочих процессов | OLTP: max_worker_processes / 21С: max_worker_processes / 2OLAP: max_worker_processes + 4 / 5 |
max_parallel_workers_per_gather | Определяет максимальное количество параллельных рабочих процессов для операции GATHER | OLTP: 21С: 4OLAP: 4 + max_parallel_workers / 8 |
max_files_per_process | Определяет максимальное количество открытых файлов для одного процесса | OLTP: 10001С: 10000OLAP: 1000 |
max_locks_per_transaction | Определяет максимальное количество блокировок, которые могут быть удержаны одной транзакцией | OLTP: 641С: 256OLAP: 64 |
Параметры журнала транзакций (WAL)
| Параметр | Описание | Формула расчета |
|---|---|---|
wal_buffers | Определяет количество памяти, выделенной для буферов журнала транзакций | Все профили: RAM <= 8GB: 16MB, RAM > 8GB: 64MB |
checkpoint_completion_target | Определяет целевую продолжительность контрольной точки | Все профили: 0.9 |
checkpoint_timeout | Определяет максимальное время между контрольными точками | Все профили: 30 минут |
Параметры реликации
| Параметр | Описание | Формула расчета |
|---|---|---|
max_wal_size | Определяет максимальный размер WAL файлов | Все профили: {CPU}GB |
min_wal_size | Определяет минимальный размер WAL файлов | Все профили: max_wal_size <= 8: 1GB max_wal_size > 8: max_wal_size GB / 4 |
wal_compression | Определяет сжатие WAL с использованием указанного метода сжатия | OLTP: CPU > 8: lz4 CPU <= 8: off 1С: lz4 OLAP: lz4 |
wal_sync_method | Определяет, как PostgreSQL будет обращаться к ядру, чтобы принудительно сохранить WAL на диск | Все профили: fdatasync |
Параметры автоочистки
| Параметр | Описание | Формула расчета |
|---|---|---|
autovacuum | Определяет, включена ли автоочистка. | Все профили: on |
autovacuum_max_workers | Определяет максимальное количество рабочих процессов автоочистки | Все профили: CPU <= 32: 3+ CPU / 8 CPU > 32: 7 + CPU / 16 |
autovacuum_vacuum_cost_delay | Определяет задержку между операциями автоочистки | Все профили: 20 |
log_autovacuum_min_duration | Определяет минимальную продолжительность выполнения автоочистки, при которой она будет записана в журнал | Все профили: 10 секунд |
autovacuum_naptime | Определяет время ожидания между запусками автоочистки | Все профили: 20s |
autovacuum_vacuum_scale_factor | Определяет долю таблицы, которая должна быть изменена, прежде чем автоочистка будет запущена | Все профили: 0.2 |
autovacuum_analyze_scale_factor | Определяет долю таблицы, которая должна быть изменена, прежде чем автоочистка будет запущена для анализа | Все профили: 0.1 |
bgwriter_delay | Управляет задержкой между запусками фонового процесса, который записывает измененные страницы из кеша в табличные пространства | Все профили: 20ms |
bgwriter_lru_maxpages | Определяет максимальное количество страниц, которые фоновый процесс может записать за один цикл | Все профили: 400 |
bgwriter_lru_multiplier | Определяет множитель, который используется для определения количества страниц, которые фоновый процесс должен записать за один цикл | Все профили: 4.0 |
pg_outline.enable | Включает или отключает использование планов выполнения запросов (outlines) для оптимизации запросов | Все профили: off |
enable_monitor_object_modification_date | Включает или отключает мониторинг даты изменения объектов базы данных | Все профили: off |
track_io_timing | Включает или отключает сбор статистики по времени ввода-вывода | Все профили: off |
Прочие параметры (профиль 1С)
| Параметр | Описание | Формула расчета |
|---|---|---|
optimize_for_1С | Включение поддержки 1С на развернутом экземпляре Pangolin | 1С: on |
escape_string_warning | Включает или отключает предупреждения о неправильных escape-последовательностях | 1С: off |
standard_conforming_strings | Включает или отключает соответствие строк стандарту SQL | 1С: off |
row_security | Определяет, включена ли функция Row-Level Security для текущей сессии | 1С: off |
plantuner.fix_empty_table | Включает или отключает исправление пустых таблиц | 1С: on |
commit_delay | Определяет задержку перед фиксацией транзакции | 1С: 1000 |
enable_bitmapscan | Включает или отключает использование битовых сканирований | 1С: on |
enable_hashagg | Включает или отключает использование хеш-агрегаций | 1С: on |
enable_hashjoin | Включает или отключает использование хеш-объединений | 1С: on |
enable_indexscan | Включает или отключает использование индексных сканирований | 1С: on |
enable_indexonlyscan | Включает или отключает использование индексных сканирований только по индексу | 1С: on |
enable_material | Включает или отключает использование материализации | 1С: on |
enable_nestloop | Включает или отключает использование вложенных циклов | 1С: on |
enable_seqscan | Включает или отключает использование последовательных сканирований | 1С: on |
enable_sort | Включает или отключает использование сортировок | 1С: on |
enable_tidscan | Включает или отключает использование сканирования по TID | 1С: on |
enable_mergejoin | Включает или отключает использование объединений слиянием | 1С: on |
lc_messages | Настройка нужной локали для объектов БД | 1С: ru_RU.UTF-8 |
lc_monetary | Настройка нужной локали для объектов БД | 1С: ru_RU.UTF-8 |
lc_numeric | Настройка нужной локали для объектов БД | 1С: ru_RU.UTF-8 |
lc_time | Настройка нужной локали для объектов БД | 1С: ru_RU.UTF-8 |
Иные параметры
| Параметр | Описание | Все профили |
|---|---|---|
autovacuum_work_mem | Определяет количество памяти, которое автоочистка может использовать для сортировки таблиц и индексов | -1 |
debug_pretty_print | Включает или отключает форматирование отладочной информации для улучшения читаемости | on |
hot_standby_feedback | Включает или отключает обратную связь от резервного сервера для улучшения производительности | on |
log_connections | Включает или отключает логирование успешных подключений к серверу | on |
log_disconnections | Включает или отключает логирование отключений от сервера | on |
log_lock_waits | Включает или отключает логирование длительных ожиданий блокировок | on |
log_replication_commands | Включает или отключает логирование команд репликации | on |
log_rotation_size | Определяет максимальный размер файла журнала, после которого происходит ротация | 100MB |
log_temp_files | Включает или отключает логирование создания временных файлов | 256MB |
log_truncate_on_rotation | Включает или отключает усечение старых файлов журнала при ротации | on |
logging_collector | Включает или отключает сбор журналов в отдельные файлы | on |
cron.max_running_jobs | Определяет максимальное количество одновременно выполняемых задач cron | 3 |
track_activities | Включает или отключает сбор статистики о выполнении функций | on |
track_functions | Включает или отключает сбор статистики о выполнении функций | none |
wal_keep_size | Определяет минимальное количество WAL, которое должно быть сохранено для репликации | 8GB |
wal_log_hints | Включает или отключает логирование подсказок WAL | on |
wal_receiver_status_interval | Определяет интервал времени для обновления статуса приемника WAL | 1s |
logical_decoding_work_mem | Определяет количество памяти, используемой для логической декодировки | 64MB |
pgaudit.log | Включает или отключает логирование аудита | none |
performance_insights.enable | Включает или отключает сбор данных для анализа производительности | off |
pg_stat_statements.track | Определяет, какие операторы должны быть отслежены модулем pg_stat_statements | all |
pg_stat_statements.max | Определяет максимальное количество операторов, которые могут быть сохранены модулем pg_stat_statements | 5000 |
pg_hint_plan.parse_messages | Включает или отключает разбор сообщений подсказок плана | warning |
pg_hint_plan.message_level | Определяет уровень сообщений для подсказок плана | log |
masking_mode | Определяет режим маскирования данных | disabled |
relnuffs_enable | Включает или отключает сбор статистики о блоках отношений | off |
enable_monitor_object_modification_date | Включает или отключает мониторинг даты изменения объектов | off |
Управление
Интерфейс утилиты
Входные параметры:
Pangolin Tuner принимает следующие аргументы командной строки:
--configили-c: путь до конфигурационного файла (обязательный аргумент);--output-fileили-r: путь до файла для фиксации вывода работы утилиты;--diffили-d: формат вывода рекомендаций в виде diff;--profileили-p: профиль для формирования списка параметров (по умолчаниюoltp);--optionили-o: опциональные параметры (возможные параметры:dtype,cpu,mem,dbmsver);--helpили-h: вывод справки и завершение работы;--versionили-v: вывод текущей версии утилиты и завершение работы;--logили-l: уровень логирования (по умолчаниюinfo).
Вывод команды pangolin-tuner --help
pangolin-tuner --help
usage: pangolin-tuner -c CONFIG [-h] [-r OUTPUT_FILE] [-d DIFF] [-p {oltp,1c,olap}] [-o OPTION] [-v] [-l {info,debug}]
pangolin-tuner -c file tune configuration for profile by default
or: pangolin-tuner -c file -p oltp tune configuration for custom profile
or: pangolin-tuner -c file -l debug tune configuration for profile by default with custom log level
or: pangolin-tuner -c file -r /path/to/file.conf tune configuration for profile by default with custom path output file
or: pangolin-tuner -c file -o cpu=10 tune configuration for profile by default with custom options
Pangolin Tuner is a Pangolin DBMS configuration tool designed to optimize database performance in various usage scenarios.
options:
-h, --help show this help message and exit
-c CONFIG, --config CONFIG
path to the current configuration file
-r OUTPUT_FILE, --output-file OUTPUT_FILE
path to result configuration file
-d, --diff format result configuration file
-p {oltp,1c,olap}, --profile {oltp,1c,olap}
profile for parameter tuning
-o OPTION, --option OPTION
optional parameters
-v, --version show version and exit
-l {info,debug}, --log {info,debug}
logging level
Выходные параметры:
По умолчанию утилита генерирует результат в формате key-value в консоль, содержащий рассчитанные оптимальные значения параметров. При использовании аргументов --diff/ --output-file вывод будет сгенерироват в формате diff, либо записан в файл соответственно.
Поддерживаемые форматы исходного файла: yaml/conf. При повторной генерации Pangolin Tuner будет перезаписывать файл, если такой уже существует. Содержимое файла будет включать в себя не только рекомендованные параметры, но и основной состав параметров из исходного конфиграционного файла. Параметры из include-файлов не учитываются в расчете.
Необходимо отдельно учитывать особенности настройки параметров на стендах с включенной защитой конфигурации.
Пример вывода работы утилиты Pangolin Tuner + лог-сообщение
pangolin_tuner % pangolin-tuner --config /tmp/postgres.conf
archive_command = /opt/pangolin-backup-tools/bin/pg_probackup archive-push -B /pgarclogs/06 --instance clustername --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4 --batch-size=100
archive_mode = False
archive_timeout = 180
auth_activity_period = 60
authentication_max_workers = 16
authentication_port = 5544
authentication_proxy = 1
autounite = True
autounite_max_children_count = 0
autounite_naptime = 60
autounite_parent_children_size_ratio = 0
autounite_pause_period =
autovacuum_work_mem = 165MB
checkpoint_completion_target = 0.9
checkpoint_timeout = 1800
client_min_messages = notice
cluster_name = clustername
cron.database_name = postgres
cron.max_running_jobs = 3
datestyle = iso, mdy
debug_pretty_print = False
default_statistics_target = 100
default_text_search_config = pg_catalog.english
disk_check_tablespaces_count = 128
disk_check_timeout = 5
disk_operation_timeout = 3
disk_retry_count = 3
effective_cache_size = 12GB
effective_io_concurrency = 10
enable_filesystem_checker = False
enable_monitor_object_modification_date = False
enabled_extra_auth_methods = cert
enabled_sec_admin_extra_auth_methods = cert,md5
force_failover_timeout = 160
fsync = True
full_page_writes = True
grace_authid_enable = False
grace_authid_period = 0
grace_authid_skip_error = False
hot_standby = on
hot_standby_feedback = True
installer.cluster_type = cluster-patroni-etcd-pgbouncer
installer.inner_role_model = True
is_tde_on = False
lc_messages = en_US.utf8
lc_monetary = en_US.utf8
lc_numeric = en_US.utf8
lc_time = en_US.utf8
listen_addresses = 0.0.0.0
log_checkpoints = True
log_connections = True
log_destination = stderr
log_directory = /pangolinlogs/pangolin-dbms
log_disconnections = True
log_file_mode = 420
log_filename = postgresql-%Y-%m-%d_%H%M%S.log
log_line_prefix = %t [%p]: [%l-1] app=%a,user=%u,db=%d,client=%h,type=%b
log_lock_waits = True
log_min_duration_statement = 3000
log_min_error_statement = WARNING
log_replication_commands = True
log_rotation_age = 1440
log_rotation_size = 100MB
log_statement = none
log_temp_files = 0
log_timezone = Europe/Moscow
log_truncate_on_rotation = True
logging_collector = True
logical_decoding_work_mem = 64MB
maintenance_work_mem = 1GB
max_connections = 110
max_locks_per_transaction = 64
max_parallel_workers = 6
max_parallel_workers_per_gather = 2
max_prepared_transactions = 0
max_replication_slots = 10
max_standby_archive_delay = 30s
max_standby_streaming_delay = 30s
max_wal_senders = 10
max_wal_size = 12GB
max_worker_processes = 12
min_wal_size = 3.0GB
monitoring_ldap_servers = ^<server_name>$
object_modification_date_keep_interval = 1 week
password_encryption = scram-sha-256
password_policy.allow_hashed_password = False
password_policy.alpha_numeric = 3
password_policy.check_syntax = True
password_policy.deduplicate_ssl_no_ssl_fail_auth_attepmts = True
password_policy.deny_default = False
password_policy.expire_warning = 7 days
password_policy.failure_count_interval = 0
password_policy.grace_login_limit = 0
password_policy.grace_login_time_limit = 3 days
password_policy.illegal_values = True
password_policy.in_history = 4
password_policy.lockout = True
password_policy.lockout_duration = 24 hours
password_policy.max_age = 0
password_policy.max_failure = 6
password_policy.max_inactivity = 0
password_policy.max_rpt_chars = 0
password_policy.min_age = 0
password_policy.min_alpha_chars = 0
password_policy.min_length = 16
password_policy.min_lowercase = 0
password_policy.min_special_chars = 1
password_policy.min_uppercase = 1
password_policy.password_strength_estimator_score = 3
password_policy.reuse_time = 365 days
password_policy.track_login = False
password_policy.transport_password_life_time = 0
password_policy.transport_password_mark_automatic = False
password_policy.use_password_strength_estimator = True
performance_insights.enable = False
performance_insights.masking = true
performance_insights.num_samples_in_files = 17280
performance_insights.num_samples_in_ram = 12
performance_insights.sampling_enable = true
performance_insights.sampling_period = 5s
pg_hint_plan.debug_print = False
pg_hint_plan.message_level = debug
pg_hint_plan.parse_messages = warning
pg_outline.enable = False
pg_plugins_path = /usr/pangolin-6.4/lib
pg_profile.max_sample_age = 7
pg_profile.topn = 20
pg_profile.track_sample_timings = False
pg_stat_kcache.linux_hz = -1
pg_stat_statements.max = 5000
pg_stat_statements.track = top
pgaudit.log = ddl, role, connection, misc_set, protection
port = 5433
psql.save_history = False
psql_encrypt_password = True
random_page_cost = 1.1
relnblocks_enable = True
relnblocks_hash_init_db = 20
relnblocks_hash_init_size = 1024
relnblocks_hash_max_db = 1024
relnblocks_hash_max_size = 1000000
rotate_password.num_rounds = 20
search_path = ext
serverssl.pkcs12_config_path = /pg_ssl/intermediate/server.p12.cfg
session_tracing_default_level = 0
session_tracing_default_path = /pgdata/06/data/tracing/
session_tracing_enable = True
session_tracing_file_limit = -1
session_tracing_roles =
shared_buffers = 4GB
shared_preload_libraries = auto_explain,pg_cron,pg_stat_statements,pg_stat_kcache,pg_hint_plan,pg_outline
ssl = True
ssl_crl_dir = /pg_ssl/crl
ssl_crl_file = /pg_ssl/crl/intermediate.crl
ssl_min_protocol_version = TLSv1.2
superuser_reserved_connections = 10
synchronous_commit = True
synchronous_standby_names = "<server_name>"
syslog_facility = LOCAL3
syslog_ident = postgres
syslog_sequence_numbers = True
syslog_split_messages = False
timezone = Europe/Moscow
track_activities = True
track_commit_timestamp = False
track_counts = True
track_functions = none
track_io_timing = False
unix_socket_directories = /var/run/postgresql/
wal_buffers = 64MB
wal_keep_size = 8GB
wal_level = replica
wal_log_hints = True
wal_receiver_status_interval = 1s
wal_sync_method = fsync
work_mem = 16MB
hba_file = /pgdata/06/data/pg_hba.conf
ident_file = /pgdata/06/data/pg_ident.conf
recovery_target =
recovery_target_lsn =
recovery_target_name =
recovery_target_time =
recovery_target_timeline = latest
recovery_target_xid =
temp_buffers = 8MB
seq_page_cost = 1.0
cpu_tuple_cost = 0.01
from_collapse_limit = 8
join_collapse_limit = 8
geqo = True
geqo_threshold = 12
max_files_per_process = 1000
wal_compression = lz4
autovacuum = True
autovacuum_max_workers = 4
autovacuum_vacuum_cost_delay = 20
log_autovacuum_min_duration = 10s
autovacuum_naptime = 20s
autovacuum_vacuum_scale_factor = 0.2
autovacuum_analyze_scale_factor = 0.1
bgwriter_delay = 20ms
bgwriter_lru_maxpages = 400
bgwriter_lru_multiplier = 4.0
2025-01-19 19:01:03,198 - INFO - Tuning process successfully finished
Пример логов работы утилиты Pangolin Tuner с аргументом --output-file
pangolin_tuner % pangolin-tuner --config /tmp/postgres.conf --output-file /tmp/postgres.conf.tuner-oltp
2025-01-19 19:03:08,373 - INFO - Configuration was tuned: {path}/postgresql.conf.tuner-oltp
2025-01-19 19:03:08,373 - INFO - Tuning process successfully finished
Пример вывода работы утилиты Pangolin Tuner с аргументом --diff + лог-сообщение
pangolin_tuner % pangolin-tuner --config /tmp/postgres.yml --diff
---
+++
@@ -69,10 +69,20 @@
archive_timeout: '180'
authentication_port: '5544'
authentication_proxy: '1'
+ autovacuum: 'True'
+ autovacuum_analyze_scale_factor: '0.1'
+ autovacuum_max_workers: '4.5'
+ autovacuum_naptime: 20s
+ autovacuum_vacuum_cost_delay: '20'
+ autovacuum_vacuum_scale_factor: '0.2'
autovacuum_work_mem: 165MB
+ bgwriter_delay: 20ms
+ bgwriter_lru_maxpages: '400'
+ bgwriter_lru_multiplier: '4.0'
checkpoint_completion_target: '0.9'
checkpoint_timeout: '1800'
client_min_messages: notice
+ cpu_tuple_cost: '0.01'
cron.database_name: postgres
cron.max_running_jobs: '3'
datestyle: iso, mdy
@@ -83,15 +93,18 @@
disk_check_timeout: '5'
disk_operation_timeout: '3'
disk_retry_count: '3'
- effective_cache_size: 3976MB
- effective_io_concurrency: '300'
+ effective_cache_size: '12'
+ effective_io_concurrency: ''
enable_filesystem_checker: 'False'
- enable_monitor_object_modification_date: 'True'
+ enable_monitor_object_modification_date: 'False'
enabled_extra_auth_methods: cert
enabled_sec_admin_extra_auth_methods: cert,md5
force_failover_timeout: '160'
+ from_collapse_limit: '8'
fsync: 'True'
full_page_writes: 'True'
+ geqo: 'True'
+ geqo_threshold: '12'
grace_authid_enable: 'False'
grace_authid_period: '0'
grace_authid_skip_error: 'False'
@@ -100,11 +113,13 @@
installer.cluster_type: cluster-patroni-etcd-pgbouncer
installer.inner_role_model: 'True'
is_tde_on: 'False'
+ join_collapse_limit: '8'
lc_messages: en_US.utf8
lc_monetary: en_US.utf8
lc_numeric: en_US.utf8
lc_time: en_US.utf8
listen_addresses: 0.0.0.0
+ log_autovacuum_min_duration: 10s
log_checkpoints: 'True'
log_connections: 'True'
log_destination: stderr
@@ -114,7 +129,7 @@
log_filename: postgresql-%Y-%m-%d_%H%M%S.log
log_line_prefix: '%t [%p]: [%l-1] app=%a,user=%u,db=%d,client=%h,type=%b '
log_lock_waits: 'True'
- log_min_duration_statement: '5000'
+ log_min_duration_statement: '3000'
log_min_error_statement: WARNING
log_replication_commands: 'True'
log_rotation_age: '1440'
@@ -124,17 +139,21 @@
log_timezone: Europe/Moscow
log_truncate_on_rotation: 'True'
logging_collector: 'True'
- maintenance_work_mem: 256MB
- max_parallel_workers: '32'
+ maintenance_work_mem: 1GB
+ max_files_per_process: '1000'
+ max_locks_per_transaction: '64'
+ max_parallel_workers: '6'
max_parallel_workers_per_gather: '2'
+ max_prepared_transactions: '0'
max_standby_archive_delay: 30s
max_standby_streaming_delay: 30s
- max_wal_size: 4GB
- min_wal_size: 2GB
+ max_wal_size: '12'
+ max_worker_processes: '12'
+ min_wal_size: '3.0'
monitoring_ldap_servers: ^<server_name>$
object_modification_date_keep_interval: 1 week
password_encryption: scram-sha-256
password_policy.allow_hashed_password: 'False'
password_policy.alpha_numeric: '3'
password_policy.check_syntax: 'True'
@@ -164,7 +183,7 @@
password_policy.transport_password_life_time: '0'
password_policy.transport_password_mark_automatic: 'False'
password_policy.use_password_strength_estimator: 'True'
performance_insights.masking: 'True'
performance_insights.num_samples_in_files: '17280'
performance_insights.num_samples_in_ram: '12'
@@ -183,10 +202,12 @@
pg_stat_statements.track: top
pgaudit.log: ddl, role, connection, misc_set, protection
port: '5433'
- proverca: 'False'
+ proverca: on
+ proverca1: on
+ proverca2: on
psql.save_history: 'False'
psql_encrypt_password: 'True'
- random_page_cost: '2.0'
+ random_page_cost: '1.1'
relnblocks_enable: 'True'
relnblocks_hash_init_db: '20'
relnblocks_hash_init_size: '1024'
@@ -194,6 +215,7 @@
relnblocks_hash_max_size: '1000000'
rotate_password.num_rounds: '20'
search_path: ext
+ seq_page_cost: '1.0'
serverssl.pkcs12_config_path: /pg_ssl/intermediate/server.p12.cfg
shared_buffers: 4GB
shared_preload_libraries: auto_explain,pg_stat_statements,pg_stat_kcache,pg_cron,pg_hint_plan,pg_outline
@@ -206,17 +228,18 @@
syslog_ident: postgres
syslog_sequence_numbers: 'True'
syslog_split_messages: 'False'
- temp_buffers: 256
+ temp_buffers: '8'
timezone: Europe/Moscow
track_activities: 'True'
track_counts: 'True'
track_functions: none
- track_io_timing: 'True'
+ track_io_timing: 'False'
unix_socket_directories: /var/run/postgresql/
- wal_buffers: 16MB
+ wal_buffers: 64GB
+ wal_compression: lz4
wal_receiver_status_interval: 1s
wal_sync_method: fsync
- work_mem: 17MB
+ work_mem: 16MB
pg_hba:
- hostssl all postgres 127.0.0.1/32 cert
- host all profile_tuz 127.0.0.1/32 scram-sha-256
2024-12-11 13:50:25,491 - INFO - Tuning process successfully finished
Логирование
Логирование работы утилиты ведется только в режиме Runtime с выводом в консоль.
Перечень сообщений лога
Варианты сообщений, которые может вернуть утилита с описанием:
MSG = {
# main
1: 'Pangolin Tuner version: {}',
2: 'Current config file: {}',
3: 'Profile: {}',
4: 'Tuning process was started',
5: 'Tuning process successfully finished',
6: 'Configuration was tuned: {}',
7: 'Not tuned',
8: 'Operation was cancelled by user',
9: 'Tuning process finished with error: {}',
# base
10: 'File {} does not exist',
11: 'Incorrect file format: {}. Acceptable: .conf, .yml, .yaml',
12: 'Reading configuration: {}',
13: 'Error reading configuration {}: {}',
14: 'Building diff report for configurations: {}',
15: 'Got error while building diff report: {}',
16: 'Tuning configuration: {}',
17: 'Got error while tuning configuration: {}',
18: 'Writing configuration: {}',
19: 'Got error while writing configuration: {}',
# tuner
20: '--- CPU Info --- {}',
21: '--- Memory Info --- {}',
22: 'Profile {} is not recognized',
23: 'Invalid option format: {}. Expected format: key=value',
24: 'CPU value is unacceptable as DBMS Pangolin will not be able to work correctly with the suggested setting. The default value was used by tuning process: {}',
25: 'MEM value is unacceptable as DBMS Pangolin will not be able to work correctly with the suggested setting. The default value was used by tuning process: {}',
26: 'Providing recommendations for DBMS Pangolin version: {}',
27: 'Error printing configuration contents',
28: 'The tool processes only the limited list of parameters. The parameters out of the list are not considered for optimizing. The detailed list can be found in the documentation of Pangolin product',
}
Утилита поддерживает следующие уровни логирования:
INFO(по умолчанию) - Вывод базовых информационных сообщений о статусе работы утилиты.DEBUG- Вывод расширенных информационных сообщений о действиях работы утилиты.
Уровень логирования можно настроить с помощью аргумента --log/-l. Пример команды:
pangolin-tuner --config /pgdata/data/data/postgresql.conf --log DEBUG
Формат вывода лога: <дата и время> - <уровень логирования> - <текст сообщения>.
Пример логов о работе Pangolin Tuner с различными уровнями логирования:
2024-12-11 13:59:14,330 - INFO - Configuration was tuned: /tmp/postgres.yml.tune-oltp
2024-12-11 13:59:14,330 - INFO - Tuning process successfully finished
---
2024-12-11 14:14:55,523 - DEBUG - Pangolin Tuner version: 1.0.0
2024-12-11 14:14:55,523 - DEBUG - Current config file: /tmp/postgres.yml
2024-12-11 14:14:55,523 - DEBUG - Profile: oltp
2024-12-11 14:14:55,523 - DEBUG - Tuning process was started
2024-12-11 14:14:55,523 - DEBUG - Reading configuration: /tmp/postgres.yml
---
2024-12-11 14:14:22,665 - ERROR - File /tmp/postgres_test.yml does not exist
---
2024-12-24 09:45:40,213 - WARNING - CPU value is unacceptable as DBMS Pangolin will not be able to work correctly with the suggested setting. The default value was used by tuning process: 4
Требования к запуску утилиты
Для успешного запуска утилиты необходимы:
-
Локальный доступ к конфигурационному файлу и права на его чтение.
Настройку можно проводить не на сервере СУБД, а на рабочей станции пользователя, с последующим копированием на сервер;
-
Наличие прав у пользователя на запуск утилиты.
Ограничения
Обратите внимание на данные ограничения:
- Рекомендации, полученные с помощью утилиты Pangolin Tuner, не следует рассматривать как окончательный вариант конфигурации.
- Утилита обрабатывает только тот конфигурационный файл, который был передан ей на вход.
- Утилита не отвечает за применение созданного файла конфигурации, перечитывания или перезапуск служб.
- Кастомизация параметров, таких как
shared_preload_libraries,search_path,ssl, включение/отключение расширений и другие подобные настройки, утилитой не выполняется. Однако она может предоставить рекомендации по их настройке в закомментированном виде. - Запуск утилиты Pangolin Tuner в Docker должен выполняться с опциональными параметрами, определяющими количество CPU и памяти, для корректного расчета значений. Это связано с особенностью вычисления значений утилитой этих характеристик. Формируемое значение соответствует общей памяти сервера и CPU, на котором развернут контейнер, а не значениям конкретного контейнера.
Сценарии использования
Использование функциональности утилиты доступно несколькими способами:
- без использования скриптов автоматизации;
- с использованием скриптов автоматизации.
Без использования скриптов автоматизации
-
Установите rpm-пакет pangolin-tuner:
-
РЕД ОС, CentOS, SberLinux:
dnf install -y <distributive>/utilities/pangolin-tuner-{version_component}-{OS}.x86_64.rpmПример:
dnf install -y distributive/utilities/pangolin-tuner-{version_component}-sberlinux{version_OS}.x86_64.rpm -
Astra Linux
apt-get install -y <distributive>/utilities/pangolin-tuner_{version_component}_amd64.deb -
Альт СП:
apt install -y <distributive>/utilities/pangolin-tuner-{version_component}-altlinux{version_OS}.x86_64.rpm
-
-
Запустите утилиту с необходимыми настройками:
-
на стенде, где будет эксплуатироваться СУБД:
Сконфигурируйте файл под нужный профиль:
# для конфигурации без pangolin-manager
/opt/pangolin-tuner/bin/pangolin-tuner --config /pgdata/data/data/postgresql.conf --profile <профиль> --output-file /pgdata/data/data/postgresql.conf.oltp
# для конфигурации с pangolin-manager
/opt/pangolin-tuner/bin/pangolin-tuner --config /etc/pangolin-manager/postgres.yml --profile <профиль> --output-file /etc/pangolin-manager/postgres.yml.oltp -
на стенде, где не будет эксплуатироваться СУБД:
# для конфигурации без pangolin-manager
/opt/pangolin-tuner/bin/pangolin-tuner --config /pgdata/data/data/postgresql.conf --profile <профиль> --output-file /pgdata/data/data/postgresql.conf.oltp -o cpu=<количество cpu со стенда с БД> -o mem=<количество mem со стенда с БД>
# для конфигурации с pangolin-manager
/opt/pangolin-tuner/bin/pangolin-tuner --config /etc/pangolin-manager/postgres.yml --profile <профиль> --output-file /etc/pangolin-manager/postgres.yml.oltp -o cpu=<количество cpu со стенда с БД> -o mem=<количество mem со стенда с БД>Внимание!Предварительно необходимо выяснить количество CPU и MEM на стенде, где будет эксплуатироваться БД.
-
-
Сохраните копию старого конфигурационного файла:
sudo su - postgres
# для конфигурации без pangolin-manager
cp /pgdata/data/data/postgresql.conf /pgdata/data/data/postgresql.conf.backup
# для конфигурации с pangolin-manager
cp /etc/pangolin-manager/postgres.yml /etc/pangolin-manager/postgres.yml.backup -
Примените новый конфигурационный файл:
sudo su - postgres
# для конфигурации без pangolin-manager
mv /pgdata/data/data/postgresql.conf.oltp /pgdata/data/data/postgresql.conf
# для конфигурации с pangolin-manager
mv /etc/pangolin-manager/postgres.yml.oltp /etc/pangolin-manager/postgres.yml -
Произведите перезапуск актуальной службы:
sudo su - postgres
# для конфигурации без pangolin-manager
/usr/pangolin/bin/pg_ctl reload
/usr/pangolin/bin/pg_ctl restart
# для конфигурации с pangolin-manager
/opt/pangolin-manager/bin/pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml reload clustername
/opt/pangolin-manager/bin/pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml restart clustername
С использованием ansible-скриптов
При запуске плейбука playbook_install.yml коллекция pangolin.tuner.configure будет запущена автоматически.
-
Заполните обязательные переменные, которые могут быть указаны в пользовательском конфигурационном файле. Обязательным параметром является путь к файлу
tuner_config. Остальные параметры будут использованы по умолчанию. Пример заполнения:#################################################### PANGOLIN TUNER ###############################################
tuner_config: "/pgdata/data/data/postgresql.conf"
tuner_profile: olap -
Запустите
configure.yml. Скрипт учтет пользовательские параметры файла (custom_config_initial.yml) и выполнит все действия по настройке конфигурации. Пример команды:source /opt/pangolin-ansible-venv-controller/bin/activate # на слейве предварительно необходимо установить пакет pangolin-ansible-venv-controller, который входит в состав дистрибутива
ansible-playbook configure.yml -vv
Механизм переключения режимов транзакций Pangolin
В версиях Pangolin до 6.5.0, управление режимом транзакций по умолчанию осуществляется при помощи GUC-параметра default_transaction_read_only. Однако внутри сессии режим транзакций меняется, если изменить значение параметра или установить характеристики текущей транзакции при помощи SET TRANSACTION. Поэтому нельзя гарантировать одинаковый режим транзакций для Pangolin.
В Pangolin 6.5.0 реализован механизм, обеспечивающий перевод режима транзакций для всего Pangolin при помощи специального API с ролевым ограничением.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Управление механизмом переключения режимов
Управление осуществляется с помощью функции psql_set_transaction_mode, которая переключает режимы RO, RW (RO – только чтение, RW – чтение и запись). При переключении из режима RW в RO происходит прерывание пишущих транзакций, при этом сессии не останавливаются. Вызывающая функцию сессия блокируется до завершения всех пишущих транзакции. Если происходит вызов функции в одной сессии, то в других сессиях вызов функции блокируется (mutual exclusive).
Примечание:
Если пишущая транзакция не может быть остановлена штатными средствами, то будет остановлена вся сессия. Соответствующая информация будет записана в системный лог.
Функция принимает параметры:
mode(обязательный параметр) – может принимать значения'RO'или'RW'(не зависит от регистра) и определяет режим, в который нужно переключить базу;timeout(обязательный параметр) – задает в миллисекундах время ожидания завершения всех пишущих транзакций. Параметр может принимать значение-1, что означает бесконечное ожидание завершения всех пишущих транзакций, и0– немедленное завершение всех пишущих транзакций, или любое целое число (максимальное значение не ограничено). При переключении от режима только чтение в режим чтение-запись, переход мгновенный. Параметрtimeoutнеобходимо передавать всегда, даже если происходит переключение в режим RW, иначе вызов функции закончится ошибкой.
Если режим успешно переключен после вызова функции, то выводится сообщение об успешном переключении режима уровня WARNING и функция возвращает текущий режим (RO либо RW). Если пользователю не доступна эта функция, то попытка вызова завершается ошибкой, функция ничего не возвращает.
Пример вызова функции psql_set_transaction_mode:
SELECT psql_set_transaction_mode('RO', 100);
WARNING: transaction mode successfully set to RO with 0 of aborted transactions
psql_set_transaction_mode
-----------------------
RO
(1 row)
Попытка вызова функции psql_set_transaction_mode пользователем, не добавленным в список set_xact_mode_users, заканчивается ошибкой:
SELECT psql_set_transaction_mode('RO', 100);
ERROR: permission denied for function psql_set_transaction_mode
При вызове функции psql_set_transaction_mode с параметром mode='RW' всегда необходимо указывать параметр timeout (иначе вызов функции закончится ошибкой), хотя переключение в режим RW происходит немедленно, без ожидания завершения текущих транзакций.
Пример вызова функции psql_set_transaction_mode с параметрами mode=RW, timeout=100:
SELECT psql_set_transaction_mode('RW', 100);
WARNING: transaction mode successfully set to RW
psql_set_transaction_mode
-----------------------
RW
(1 row)
Вызов функции psql_set_transaction_mode выводит предупреждение, если переключение режима не требуется, функция возвращает текущий режим (RW/RO).
Вызов функции psql_set_transaction_mode выводит предупреждение, если переключение режима не требуется:
SELECT psql_set_transaction_mode('RO', 200);
WARNING: current mode is "RO" (read only), nothing to do
psql_set_transaction_mode
----------------------
RO
(1 row)
Вызов функции psql_set_transaction_mode с неверными параметрами mode или timeout пользователем, добавленным в параметр set_xact_mode_users, заканчивается ошибкой.
Вызов функции psql_set_transaction_mode с неверным параметром mode заканчивается ошибкой:
SELECT psql_set_transaction_mode('READ', 100);
ERROR: mode "READ" does not exist, choose a correct mode: "RO" or "RW"
Вызов функции psql_set_transaction_mode с неверными параметром timeout заканчивается ошибкой
SELECT psql_set_transaction_mode('RO', -120);
ERROR: timeout must be a positive integer or "0" to interrupt all RW transactions immediately or "-1" for unlimited timeout
Вызов функции psql_set_transaction_mode с недопустимым значением параметров mode или timeout пользователем, добавленным в параметр set_xact_mode_users, заканчивается системной ошибкой.
Вызов функции psql_set_transaction_mode с попыткой передать строку в параметр timeout заканчивается ошибкой:
SELECT psql_set_transaction_mode('RO', 'l2o');
ERROR: invalid input syntax for type integer: "l2o"
Вызов функции psql_set_transaction_mode с попыткой передать дробное число в параметр timeout заканчивается ошибкой
SELECT psql_set_transaction_mode('RO', 120.7);
ERROR: function psql_set_transaction_mode(unknown, numeric) does not exist
Вызов функции psql_set_transaction_mode в параллельной сессии блокируется и заканчивается ошибкой.
Пример вызова функции psql_set_transaction_mode в параллельной сессии:
SELECT psql_set_transaction_mode('RO', 200);
ERROR: function "psql_set_transaction_mode" was blocked due to concurrent call
Просмотреть текущий режим можно вспомогательной функцией psql_get_transaction_mode, которая возвращает RW (текущий режим чтение-запись) либо RO (текущий режим только чтение). Функция доступна любому пользователю:
SELECT psql_get_transaction_mode();
psql_get_transaction_mode
---------------------------
RO
(1 row)
Вызывать функцию psql_set_transaction_mode могут пользователи, которые перечислены в специальном списке (см. раздел «Управление списком пользователей, имеющих права на переключение режимов»).
При вызове функции, в лог базы данных пишется сообщение с уровнем WARNING:
- в какой режим выполнено переключение;
- результат операции;
- количество прерванных транзакций.
Информация о текущем режиме и история переключений содержится в представлении psql_transaction_mode_history. Представление отражает:
- текущее состояние БД, дату/время начала, причину его наступления (старт СУБД или вызов функции);
- следующее состояние, дату/время вызова функции для переключения в следующее состояние, запрошенный «тайм-аут» завершения текущих RW транзакций.
Просмотреть представление psql_transaction_mode_history можно запросом SELECT:
SELECT * FROM psql_transaction_mode_history;
mode | started | ended | source | pending | function_called | timeout
--------------+----------------------------+----------------------------+----------+---------+----------------------------+---------
RW | 2025-01-21 10:44:04.582146 | 2025-01-21 11:56:16.790523| START | False | <NULL> | <NULL>
RO | 2025-01-21 11:56:16.090523 | 2025-01-21 14:42:14.230106| FUNCTION | False | 2025-01-21 11:56:15.991376 | 200
RW | 2025-01-21 14:42:14.230106 | 2025-01-21 14:49:54.067529| FUNCTION | False | 2025-01-21 14:42:14.230106 | 0
RO | 2025-01-21 14:49:54.067529 | 2025-01-21 16:15:28.292891| FUNCTION | False | 2025-01-21 14:49:53.967529 | 250
RW | 2025-01-21 16:15:28.292891 | <NULL> | FUNCTION | False | 2025-01-21 16:15:28.292887 | 0
RO | <NULL> | <NULL> | FUNCTION | True | 2025-01-21 18:53:34.891701 | -1
(6 rows)
Максимальное количество записей в представлении psql_transaction_mode_history определяется параметром transaction_mode_max_records (по умолчанию 10000 записей). Просмотреть параметр запросом SHOW может любой пользователь:
SHOW transaction_mode_records;
transaction_mode_records
---------------------------
10000
(1 rows)
Изменять параметр может только суперпользователь, изменение параметра требует рестарта сервера:
ALTER SYSTEM SET transaction_mode_max_records = 100;
\q
sudo systemctl restart postgresql
Попытка изменить параметр transaction_mode_max_records не суперпользователем заканчивается ошибкой:
ALTER SYSTEM SET transaction_mode_max_records=2000;
ERROR: permission denied to set parameter "transaction_mode_max_records"
Минимальное значение параметра transaction_mode_max_records - 0 (представление не хранит информацию об истории переключений режимов), максимальное - 100000 записей.
Попытка присвоить параметру transaction_mode_max_records значение, превышающее максимальное, заканчивается ошибкой:
ALTER SYSTEM SET transaction_mode_max_records=7007007;
ERROR: 7000007 is outside the valid range for parameter "transaction_mode_max_records" (0 .. 100000)
Попытка присвоить параметру transaction_mode_max_records невалидное значение заканчивается ошибкой:
ALTER SYSTEM SET transaction_mode_max_records='thousand';
ERROR: invalid value for parameter "transaction_mode_max_records": "thousand"
Внимание!
При перезапуске режим RO не сохраняется. После запуска база данных переходит в режим чтения и записи (RW). Пример:
psql -U user2
SELECT psql_set_transaction_mode('RO', 110);
WARNING: transaction mode successfully set to RO with 0 of aborted transactions
psql_set_transaction_mode
-----------------------
RO
(1 row)
INSERT INTO test_table(id, data) VALUES(100, 'very important data');
ERROR: cannot execute INSERT in a read-only transaction
\q
sudo systemctl restart postgresql
psql -U user2
INSERT INTO test_table(id, data) VALUES(100, 'very important data');
INSERT 0 1
Управление списком пользователей, имеющих права на переключение режимов
Имена пользователей, имеющих права на вызов функции psql_set_transaction_mode перечисляются в настроечном GUC-параметре set_xact_mode_users. Имена пользователей разделяются символом ,.
По умолчанию параметр пуст. Просмотреть список пользователей, имеющих права на переключение режимов, можно запросом SHOW:
SHOW set_xact_mode_users;
set_xact_mode_users
-----------------------
(1 row)
Изменять параметр set_xact_mode_users может только суперпользователь. Изменение параметра не требует перезагрузки сервера:
ALTER SYSTEM SET set_xact_mode_users = 'user1, user2';
SELECT pg_reload_conf();
Просматривать параметр set_xact_mode_users может любой пользователь:
SHOW set_xact_mode_users;
set_xact_mode_users
-----------------------
user1, user2
(1 row)
Попытка изменения параметра set_xact_mode_users не суперпользователем заканчивается ошибкой:
ALTER SYSTEM SET set_xact_mode_users = 'user1, user2';
ERROR: permission denied to set parameter "set_xact_mode_users"
Очистить параметр set_xact_mode_users можно либо запросом RESET:
ALTER SYSTEM RESET set_xact_mode_users;
SELECT pg_reload_conf();
SHOW set_xact_mode_users;
set_xact_mode_users
------------------------
(1 row)
Либо передав в параметр пустую строку:
ALTER SYSTEM SET set_xact_mode_users='';
SELECT pg_reload_conf();
SHOW set_xact_mode_users;
set_xact_mode_users
------------------------
(1 row)
Попытка вызова функции psql_set_transaction_mode пользователем, не добавленным в список set_xact_mode_users, заканчивается ошибкой (даже если он добавлен в параметр set_rw_users или является суперпользователем):
SELECT psql_set_transaction_mode('RO', 100);
ERROR: permission denied for function psql_set_transaction_mode
Управление списком пользователей имеющих права на выполнение пишущих транзакций в режиме RO
Имена пользователей, имеющих права на выполнение пишущих транзакций в режиме RO перечисляются в настроечном GUC-параметре set_rw_users.
По умолчанию параметр пуст. Просмотреть список пользователей, имеющих права на выполнение пишущих транзакций в режиме RO, можно запросом SHOW:
SHOW set_rw_users;
set_rw_users
----------------
(1 row)
Изменять параметр set_rw_users может только суперпользователь. Изменение параметра не требует перезагрузки сервера:
ALTER SYSTEM SET set_rw_users = 'user1, user2';
SELECT pg_reload_conf();
Просматривать параметр может любой пользователь:
SHOW set_rw_users;
set_rw_users
---------------
user1, user2
(1 row)
Попытка изменения параметра не суперпользователем заканчивается ошибкой:
ALTER SYSTEM SET set_rw_users = 'user1, user2';
ERROR: permission denied to set parameter "set_rw_users"
Очистить параметр можно либо запросом RESET:
ALTER SYSTEM RESET set_rw_users;
SELECT pg_reload_conf();
SHOW set_rw_users;
set_rw_users
----------------
(1 row)
Либо передав в параметр пустую строку:
ALTER SYSTEM SET set_rw_users='';
SELECT pg_reload_conf();
SHOW set_rw_users;
set_rw_users
----------------
(1 row)
Пользователь, указанный в параметре set_rw_users, может выполнять пишущие транзакции после переключения в режим RO. Сессия данного пользователя открывается сразу в режиме RW, никаких дополнительных действий не требуется:
psql
ALTER SYSTEM SET set_rw_users = 'user1';
ALTER SYSTEM SET set_xact_mode_users='user1, user2';
SELECT pg_reload_conf();
\q
psql -U user1
SELECT psql_set_transaction_mode('RO', 10);
WARNING: transaction mode successfully set to RO with 0 of aborted transactions
psql_set_transaction_mode
-----------------------
RO
(1 row)
INSERT INTO test_table(id, data) VALUES(100, 'very important data');
INSERT 0 1
После вызова функции psql_set_transaction_mode, с переключением всех транзакций в режим RO, попытки выполнить RW-транзакции в тестовой базе данных по истечении периода, заданного в параметре timeout, пользователями, не добавленными в параметр set_rw_users, заканчиваются ошибкой (даже если они добавлены в параметр set_xact_mode_users или являются суперпользователями):
psql -U user2
SELECT psql_set_transaction_mode('RO', 10);
WARNING: transaction mode successfully set to RO with 0 of aborted transactions
psql_set_transaction_mode
-----------------------
RO
(1 row)
INSERT INTO test_table(id, data) VALUES(100, 'very important data');
ERROR: cannot execute INSERT in a read-only transaction
Выгрузка данных в дамп при включенных СЗИ
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
В данном разделе описываются механизм сохранения данных БД, находящихся под защитой в засекреченных файлах, и механизм загрузки данных из засекреченного файла в БД (БД могут быть разными).
В рамках описываемого далее решения данные снимаются только в sql-формате. Сжатие данных при формировании защищенного дампа не поддерживается.
Установка и подключение СЗИ описаны в разделе «СЗИ. Установка и подключение».
Описание
Механизм позволяет формировать дампы с заданными объектами одной БД и последующей их загрузкой в другую БД. Выгрузка и загрузка дампа доступны в том числе пользователю, не имеющему доступа к защищенным объектам. База данных может содержать в себе как защищенные объекты, так и не защищенные. Защищенные объекты переносятся между БД без изменений, а защищенные данные внутри объектов (таблиц и партиций) переносятся без их раскрытия. Возможен перенос объектов между базами с различными мажорными версиями СУБД Pangolin.
Для формирования защищенного дампа требуется установка расширения secret_dump. Данное расширение может работать только с включенной функциональностью защиты данных от привилегированных пользователей (admin protection или AP). Расширение должно быть установлено в БД, на которой будет формироваться дамп.
Добавлять расширение в shared_preload_libraries нельзя.
Формирование дампа происходит в соответствии с оригинальным поведением утилиты pg_dump, за исключением режимов работы:
--compress/-Z- отсутствует сжатие;--format/F- поддерживается только текстовый формат (sql);--inserts- нельзя выгружать данные в форматеinsert, поддерживается толькоCOPY.--clean- командыDROPдля удаления существующих объектов базы данных не генерируются при формировании защищенного дампа. Если указаны оба ключа-cи-Содновременно, командаDROP DATABASEне будет создана.
При нахождении главной партиции партиционированной таблицы в незащищенной схеме и постановке ее под защиту, когда дочерние таблицы этой партиционированной таблицы находятся в защищенной схеме (не поставлены отдельно под защиту), дамп при загрузке выдаст ошибку, после чего загрузка защищенных объектов остановится.
В текущей версии операции постановки под защиту для схемы public и ее объектов не выгружаются.
Сформированный дамп отличается от оригинального рядом функций, с которыми можно ознакомиться подробнее в подразделе «secret_dump. Создание защищенного дампа».
За формирование файла для хранения ключа засекречивания отвечает компонент Pangolin-security-utilities.
Засекречивание данных и контрольных сумм в дампе
Засекречивание данных и контрольных сумм в дампе осуществляться с помощью ключа (KEY), который не доступен пользователю в открытом виде. В качестве идентификатора такой ключ будет иметь GUID, по которому пользователь сможет указывать, каким ключом засекречивать данные дампа.
Комбинация GUID с соответствующим ему ключом (GUID+KEY) уникальна для каждого дампа и указана в нем. Сами ключи засекречивания с GUID находятся в базе данных, с которой будет формироваться дамп в открытой таблице. Чтобы не допустить раскрытия ключей, они засекречиваются отдельным ключом, который хранится в файле /etc/pangolin-security-utilities/secret_dump_key.bin и формируется утилитой pg_dump_generate_secret_file. Также есть возможность задать его в хранилище ключей (субдомен secure_dump_key) в формате key/value: key_base64.
Наличие файла или ключа в хранилище ключей является обязательным для формирования дампа.
Схема формирования дампа:
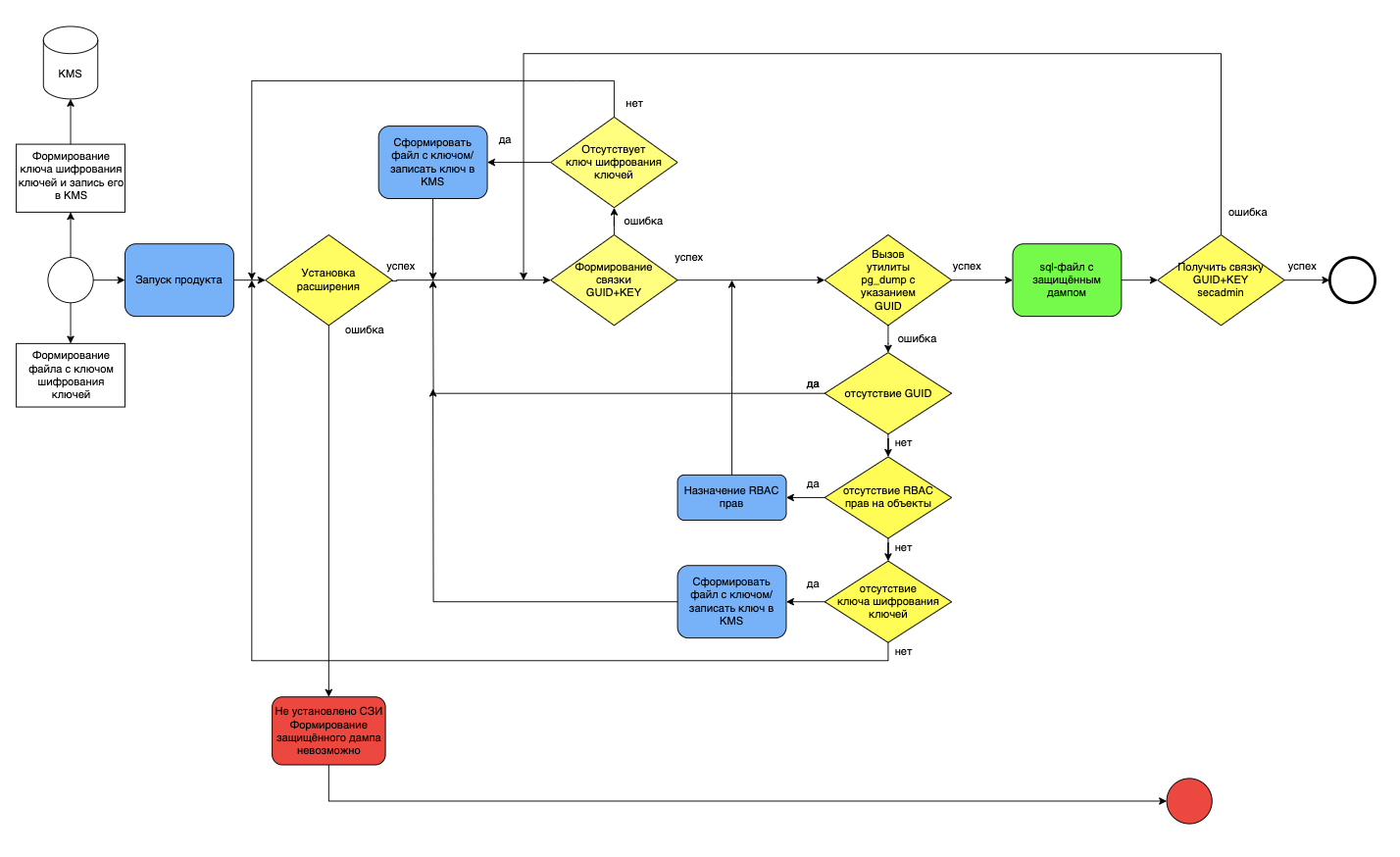
Схема применения дампа на новой БД сервера с переносом связки GUID+KEY:
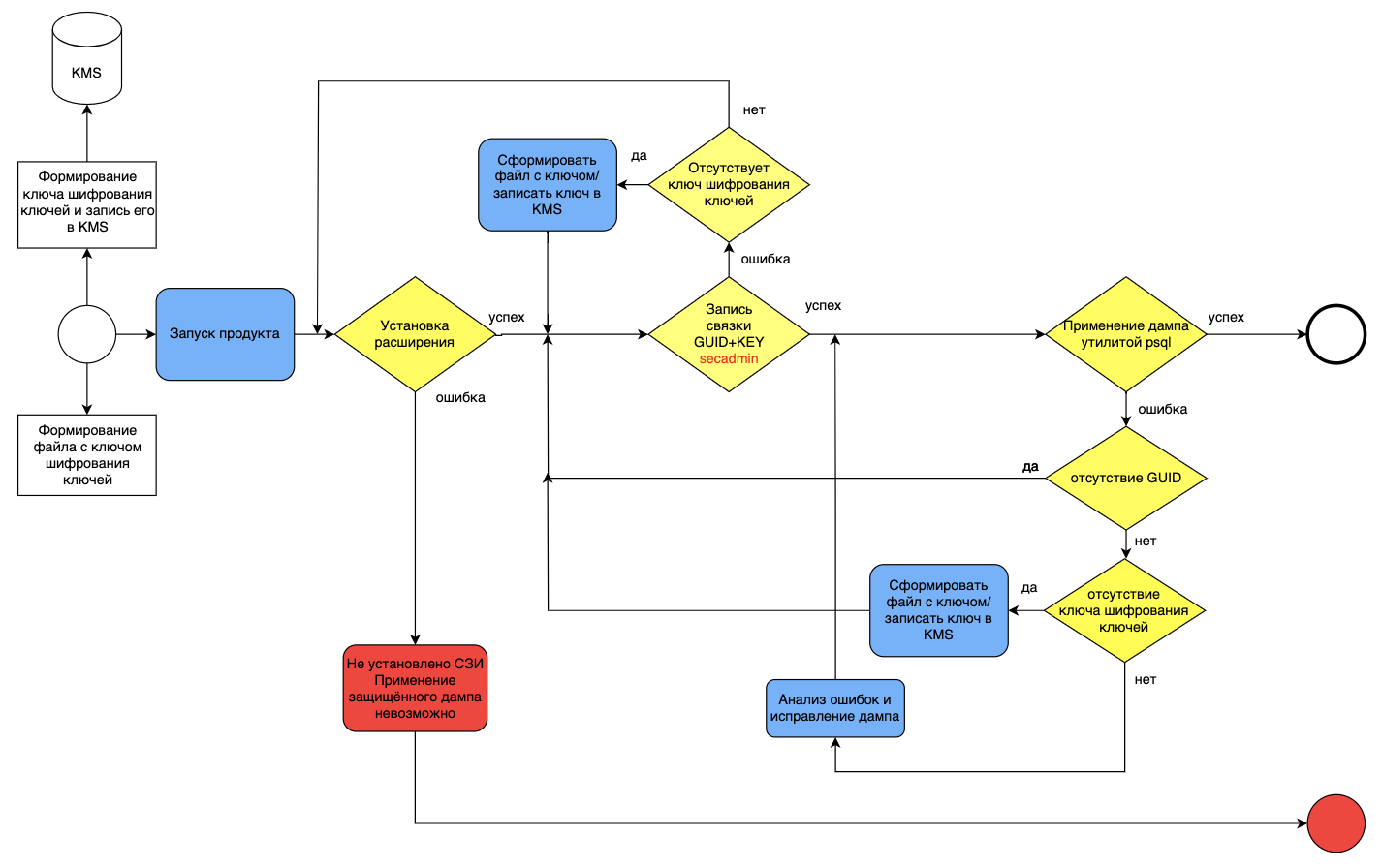
Схема применения дампа на новой БД сервера без переноса связка GUID+KEY:
Утилита pg_dump_generate_secret_file
Утилита используется для генерации файла /etc/pangolin-security-utilities/secret_dump_key.bin. В сгенеренном файле присутствует ключ для засекречивания ключей кодирования защищенного дампа. Ключ засекречен на параметрах сервера. Он может формироваться утилитой автоматически или задаваться пользователем. Задание ключа пользователем используется при кластерной конфигурации, чтобы ключ засекречивания ключей был одинаковым и на мастере, и на реплике.
Утилита имеет следующие ключи:
-m,--manual- ключ задания ключа пользователем;-t,--type- формат ключа:BASE64,HEX,ASCII;-h,--help- руководство утилиты.
Пример работы утилиты c автоматической генерацией ключа:
pg_dump_generate_secret_file
Пример работы утилиты c заданием ключа в формате BASE64 в ручном режиме (флаг -m):
pg_dump_generate_secret_file -m -t BASE64
Формат запросов
Дамп формируется в SQL-формате. Все SQL-запросы для защищенных объектов выгружаются в засекреченном виде. При применении дампа осуществляется проверка контрольных сумм перед выполнением SQL-запросов защищенных объектов на сервере. Все данные рассекречиваются только на сервере во избежание их раскрытия.
Также при формировании дампа выполняются SQL-запросы на создание политик, в которых присутствуют выгружаемые защищенные объекты и SQL-запросы, назначающие политики на действия к конкретным защищенным объектам. Все описанные SQL-запросы сохраняются в дампе в открытом виде и защищаются от изменений засекреченной контрольной суммой.
Формирование дампа
Для формирования дампа необходимо:
-
Установить расширение
secret_dump. Расширение возможно установить только на БД, с включенным механизмом защиты данных. -
Запустить утилиту
pg_dumpс ключом--secret-dumpи указаниемGUID. -
Сформировать ключ, которым будет шифроваться содержимое защищенных объектов:
SELECT pg_catalog.sd_generate_guid_key_dump();Функция возвращает
GUID(идентификатор ключа), который необходимо далее передать в утилитуpg_dump. Сам ключ пользователю недоступен, доступ к ключу есть только у администратора безопасности. -
Вызвать утилиту
pg_dumpс ключами, необходимыми для выгрузки нужных объектов, и указаниемGUID:pg_dump <vanila keys> --secret-dump GUID
По итогу выполнения этих действий будет сформирован sql-дамп структуры:
--
-- PostgreSQL database dump
--
-- Dumped from database version 15.5
-- Dumped by pg_dump version 15.5
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
SELECT pg_catalog.sd_load_secret_dump('<GUID>', '<TimeStamp>', '<EncodingCRC>', '<EncodingKeyDump>');
-- Создание DDL
-- Пример защищенного DDL создания таблицы
SELECT pg_catalog.sd_protection_action('<EncodingCRC>', 'CREATE TABLE public.test_protect_table (
id integer,
data text DEFAULT ''test_protect_table''::text
);
SELECT pm_protect_object(''table'', ''public.test_protect_table'');
');
-- Пример защищенного DDL создания MATERIALIZED VIEW
SELECT pg_catalog.sd_protection_action('<EncodingCRC>', 'CREATE MATERIALIZED VIEW public.test_protect_matview AS
SELECT 1 AS "?column?"
WITH NO DATA;
SELECT pm_protect_object(''matview'', ''public.test_protect_matview'');
');
-- Пример незащищенного DDL (ванильный)
CREATE TABLE public.test_open_table (
a integer,
b text
);
...
-- Формирование политик SELECT pg_catalog.sd_protection_policies('<EncodingCRC>', 'SELECT pm_make_policy(''policy_sd'');
SELECT pm_grant_to_policy(''policy_sd'',''table'',''public.test_protect_table'',array[''insert'',''select'']::name[]);
SELECT pm_grant_to_policy(''policy_sd'',''matview'',''public.test_protect_matview'',array[''select'']::name[]);
...
');
-- Выгрузка данных
-- Выгрузка защищенных данных в шифрованном виде
COPY public.test_protect_table (id, data) FROM stdin;
<EncodingBase64Data>
\.
-- Выгрузка незащищенных данных
COPY public.test_open_table (a, b) FROM stdin;
1 aaa
2 bbb
...
\.
-- Выгрузка ACL
GRANT SELECT,INSERT ON TABLE public.test_protect_table TO not_protect;
SELECT pg_catalog.sd_protection_action('<EncodingCRC>', 'REFRESH MATERIALIZED VIEW public.test_protect_matview;
');
-- Завершение дампа
-- Функция завершения загрузки
SELECT pg_catalog.sd_end_secret_dump();
--
-- PostgreSQL database dump complete
--
На заключительном этапе формирования дампа администратор безопасности получает ключ засекречивания дампа и переносит его вместе с GUID на целевую БД:
SELECT pg_catalog.sd_get_guid_dump('GUID');
Загрузка данных в новую БД
Для успешной загрузки данных в новую БД необходимо перенести в нее ключ засекречивания. Так как доступ к ключам в открытом виде будет только у администратора безопасности, он должен самостоятельно перенести связки GUID+KEY на другую базу данных до формирования дампа. Также возможен вариант выгрузки дампа в базу данных, находящуюся на текущем сервере. Для этого перенос ключа не требуется, так как он будет браться из самого дампа при условии совпадения ключа засекречивания ключей, с тем, который присутствовал при формировании загружаемого дампа.
Восстановление дампа необходимо выполнять в другую предварительно созданную базу данных из шаблона template0 с установленным расширением secret_dump.
Загрузка защищенного дампа на БД с новым ключом засекречивания ключей
В данном случае предполагается, что ключ засекречивания ключей на сервере с целевой БД отличается от ключа засекречивания ключей на сервере с БД, на которой был сформирован дамп. При этом не имеет значение, где изначально этот ключ хранился - в файле /etc/pangolin-security-utilities/secret_dump_key.bin или в хранилище ключей.
Для применения (загрузки) дампа:
-
Администратор безопасности должен установить на целевую БД связку
GUID+KEY:SELECT pg_catalog.sd_set_guid_key_dump('GUID', 'KEY');ВажноУстановленным ключом можно только загрузить дамп, сформировать защищенный дамп с его использованием невозможно.
-
Пользователь утилитой
psqlприменяет (загружает) дамп аналогично ванильному дампу:psql -p <port> -h <host> -f protected_dump.sqlВажноПри сбоях, загрузка засекреченных объектов будет остановлена.
-
Администратор безопасности должен назначить на пользователей политики, созданные в дампе.
Загрузка засекреченного дампа на БД с исходным ключом засекречивания ключей
В данном сценарии предполагается, что ключ засекречивания ключей на сервере с целевой БД не отличается от ключа засекречивания ключей на сервере с БД, где был сформирован дамп. Не имеет значения, где изначально ключ хранился - в файле /etc/pangolin-security-utilities/secret_dump_key.bin или в хранилище ключей.
Для загрузки дампа:
-
Пользователь утилитой
psqlдолжен применить дамп аналогично ванильному:psql -p <port> -h <host> -f protected_dump.sqlЕсли во время загрузки объектов возникла ошибка, то все защищенные объекты после ошибки будет невозможно загрузить, так как применятся только объекты, загруженные до ошибки. Незащищенные объекты применятся в соответствии с оригинальынм поведением утилиты
pg_dump. -
Администратор безопасности должен назначить политики, созданные в дампе, на пользователей.
Принцип работы автоочистки
Операция VACUUM:
- производит очистку таблиц и индексов от неактуальных версий строк (модель MVCC) для оптимизации хранения данных и доступа к ним;
- собирает статистику об использовании таблицы, что позволяет составить более точный план запросов;
- защищает от переполнения счетчика транзакций.
Подробное описание представлено в разделе «Регулярная очистка».
Команда VACUUM над каждой таблицей с блокировкой ShareUpdateExclusiveLock (защищена от параллельных изменений) производит следующие действия:
- Сканирование страниц на «мертвые» (невидимые после
DELETEилиUPDATE) строки, их заморозку при необходимости, и удаление ссылок из индексов; - Удаление «мертвых» строк и перемещение «живых» в каждом блоке, обновление карт видимости и свободного пространства (VM, FSM);
- Очистку индексов после удаления, обрезку таблицы по возможности, обновление статистики и системных каталогов таблицы. По завершению происходит очистка clog.
Статусы транзакций хранятся в commit log (clog) файлах, расположенных в папках pg_xact, по два бита на xid. Возможны четыре варианта: транзакция в процессе, подтверждена, отменена или является субтранзакцией (статус субтранзакции определяется статусом основной транзакции). При периодическом выполнении VACUUM будут постепенно замораживаться строки, страницы и таблицы БД. Обычные строки имеют свой отрезок видимости в транзакциях от времени создания xmin до времени удаления xmax, а замороженные строки считаются всегда видимыми, и xid текущей транзакции не влияет на их видимость. Для каждой таблицы имеется xid, до которого все строки заморожены, это relfrozenxid. После обработки всех таблиц обновляется такой же xid для всей БД - datfrozenxid. Горизонт транзакций — это все транзакции, начиная с datfrozenxid до xid текущей транзакции. Хранение статусов в commit log имеет смысл только для горизонта транзакций, так как замороженные строки видны для любой транзакции, и VACUUM удаляет все файлы за горизонтом.
Аналогично хранятся статусы мультитранзакций со своей структурой хранения pg_multixact.
Очистка (VACUUM) может работать в двух режимах – «ленивом» и «жадном»:
-
«Ленивый» пропускает страницы, в которых нет «мертвых» строк, поэтому он не может заморозить все строки и обновить
relfrozenxid. Замораживает строки старше, чемvacuum_freeze_min_age. -
«Жадный» режим проходит по всем страницам (кроме полностью замороженных), если при работе очистки возраст таблицы (
relfrozenxid) превышает параметрvacuum_freeze_table_age.Таким образом, при срабатывании автовакуума по трем условиям (описаны далее),
vacuum_freeze_table_ageвлияет на агрессивность заморозки.
VACUUM необходим для стабильной и быстрой работы таблицы, поэтому его может запускать фоновый процесс, называемый autovacuum. В силу различной нагрузки на БД выполнять VACUUM по расписанию может быть или избыточно, или накладно, поэтому автоочистка (autovacuum) запускается в зависимости от интенсивности использования таблицы:
- Если количество «мертвых» строк таблицы превышает
autovacuum_vacuum_threshold+autovacuum_vacuum_scale_factor*reltuples(общее количество строк в таблице); - Если количество новых строк таблицы превышает
autovacuum_vacuum_insert_threshold+autovacuum_vacuum_insert_scale_factor*reltuples; - При превышении возраста таблицы
relfozenxidпараметраautovacuum_freeze_max_age.
Обычно автоочистка срабатывает в «ленивом» режиме, замораживая строки старше vacuum_freeze_min_age.
В агрессивном режиме запускается, если возраст таблицы больше vacuum_freeze_table_age или autovacuum_freeze_max_age. При работе в агрессивном режиме выставляется флаг «to prevent wraparound», при котором выводятся соответствующие предупреждения и запрещается прерывание процесса автовакуума, если таблица заблокирована.
Параметры
Таблицы с параметрами автоочистки и их описанием представлены в документе «Справочная информация» разделе «Конфигурационные параметры».
Параметры аварийной автоочистки: vacuum_failsafe_age и vacuum_multixact_failsafe_age, не используются для 64-битного счетчика (xid).
Описание реализованных параметров
Параметр autovacuum_disable_freeze_max_age
При включении данной настройки кластер игнорирует достижение порога для срабатывания агрессивной автоочистки с защитой от переполнения счетчика транзакций (autovacuum_freeze_max_age и autovacuum_multixact_freeze_max_age). В исключения добавлены таблицы системного каталога и шаблонные базы данных или базы данных без возможности подключения, для них использование этих параметров сохраняется, чтобы обновить их relfrozenxid и datfrozenxid.
Настройка используется для избежания блокировок больших таблиц с часто пишущимися и редко изменяющимися данными на время агрессивной автоочистки при использовании 64-битных счетчиков.
Полная заморозка таблицы все еще возможна при достижении порогов vacuum_freeze_table_age и vacuum_multixact_freeze_table_age, это позволяет обновить ее relfrozenxid, а для полного отключения заморозки их следует выставить в 2^63-1. Также при включенном параметре autovacuum_disable_freeze_max_age автовакуум не будет выбирать в приоритетном режиме самые старые таблицы и базы данных для обработки, иначе это приводило бы к работе над одними и теми же таблицами и базами с самым низким frozenxid, а остальные бы игнорировались.
Однако, на практике использование этого параметра может привести к постоянному увеличению горизонта транзакций из-за удерживающего relfrozenxid, например, в результате отсутствия агрессивной заморозки старой toast-таблицы. Поэтому использовать его следует с осторожностью, периодически выполняя VACUUM FREEZE во избежание накопления clog файлов из-за удержания горизонта.
Проверка установки параметров
Текущие значения параметров можно получить командой:
SELECT * FROM pg_settings WHERE name LIKE '%vacuum%'
Проверка работоспособности
Выполнение автоочистки возможно проверить в логах сервера. При чтении сообщений лог-файла обратите внимание на конфигурационный параметр log_autovacuum_min_duration, ограничивающий вывод логов. Информация о работе представлена в таблице статистики:
SELECT R.relname, R.relfrozenxid, S.autovacuum_count, S.last_autovacuum FROM pg_class R
LEFT JOIN pg_stat_all_tables S ON S.relname = R.relname WHERE R.relname = 'tablename';
Также есть возможность проверить:
- появляются ли замороженные строки в страницах таблиц – это будет свидетельствовать о работе автоочистки по
freeze_min_age; - поднимается ли
relfrozenxidиdatfrozenxidв течение работы сервера – это информирует о корректной работе агрессивной заморозки без неорганиченного увеличения горизонта транзакций и увеличения файлов clog.
Cценарии использования
Автоочистка с параметрами по умолчанию подойдет для большинства случаев. Периодичность запуска обслуживания обеспечивает своевременное удаление неиспользуемых данных, очистку индексов и обновление статистики. Заморозка периодически блокирует таблицы, ненадолго мешая производить изменения в них. Тонкая настройка может понадобиться для определенных профилей нагрузки на БД.
Например, есть понимание, что в некоторых таблицах очень часто обновляются или удаляются данные, в таком случае для ускорения работы желательно почаще их чистить для оптимизации хранения и поиска – нужно уменьшить autovacuum_vacuum_threshold и autovacuum_vacuum_scale_factor.
При постоянно добавляющихся данных типа логов (без удалений и редактирований) имеет смысл использовать autovacuum_vacuum_insert_threshold = -1, т.к. очистка не потребуется, и нужна будет только заморозка.
При наличии огромной, постоянно и быстро, пополняемой таблицы избавиться от долгих блокировок на агрессивной автоочистке можно настройками autovacuum_disable_freeze_max_age, но существуют дополнительные детали (описание приведено в подразделе «Описание реализованных параметров»).
Рекомендации
Замечено, что использование низкого значения autovacuum_naptime при резкой накрутке счетчика транзакций, приводит к тому, что агрессивный вакуум не успевает отрабатывать за отведенное время, и автоочистка циклично обрабатывает одну и ту же таблицу одной БД («to prevent wraparound», ждет блокировок с предыдущих запусков), пропуская другие БД и таблицы.