TimescaleDB. База данных для хранения данных временного ряда
Версия: 2.19.3.
В исходном дистрибутиве установлено по умолчанию: да.
Связанные компоненты: отсутствуют.
Схема размещения:
ext.
Описание
TimescaleDB – это база данных временных рядов с открытым исходным кодом, оптимизированная для быстрой работы с данными и обработки сложных запросов. Она разработана на основе PostgreSQL и упакована как расширение.
TimescaleDB работает на полноценном SQL и, соответственно, проста в использовании, как традиционная реляционная база данных, но масштабируется так, как раньше могла только NoSQL.
При выборе между реляционным подходом и NoSQL приходится идти на компромиссы, тогда как TimescaleDB предлагает преимущества обоих подходов:
-
Простота использования:
- Предоставляется полноценный интерфейс SQL для всех элементов, изначально поддерживаемых PostgreSQL (включая вторичные индексы, вложенные запросы, объединения, оконные функции, а также агрегатные функции, не основанные на времени).
- Возможно подключение к любому клиенту, который работает с PostgreSQL, никаких изменений не требуется.
- Учитываются ориентированные на время особенности, предоставляются функции API и средства оптимизации.
- Осуществляется поддержка политик хранения данных.
-
Масштабируемость:
- Данные прозрачно сегментируются по пространству и времени для масштабирования в высоту (один узел) и в ширину (в разработке).
- Запись данных производится на высокой скорости (включая пакетные коммиты, индексы в памяти, транзакционную поддержку, поддержку наполнения исторических данных).
- Осуществляется подбор оптимального размера блоков (двумерных разделов данных), который на отдельных узлах обеспечивает быструю запись и обработку даже больших объемов данных.
- Производится распараллеливание операций между блоками и серверами.
-
Надежность:
- Решение разработано в качестве расширения на базе PostgreSQL.
- Гибкие настройки управления (совместимость с существующей экосистемой и инструментарием PostgreSQL).
API TimescaleDB по управлению гипертаблицами приведен в документе «Список PL/SQL функций продукта», раздел «TimescaleDB. Управление гипертаблицами» (документ доступен в личном кабинете).
Данные временных рядов
Многие приложения и базы данных приравнивают данные временных рядов к чему-то вроде серверных метрик определенного формата:
Name: CPU
Tags: Host=MyServer, Region=West
Data:
2017-01-01 01:02:00 70
2017-01-01 01:03:00 71
2017-01-01 01:04:00 72
2017-01-01 01:05:01 68
Во многих приложениях для мониторинга часто собираются различные показатели (например, процессор, память, сетевая статистика, время автономной работы). Таким образом, не всегда имеет смысл думать о каждой метрике отдельно. Рассмотрим альтернативную «расширенную» модель данных, которая поддерживает корреляцию между метриками, собранными в одно и то же время.
Metrics: CPU, free_mem, net_rssi, battery
Tags: Host=MyServer, Region=West
Data:
2017-01-01 01:02:00 70 500 -40 80
2017-01-01 01:03:00 71 400 -42 80
2017-01-01 01:04:00 72 367 -41 80
2017-01-01 01:05:01 68 750 -54 79
Этот тип данных относится к гораздо более широкой категории, будь то показания температуры от датчика, цена акций, состояние машины или даже количество входов в приложение.
Данные временных рядов — это данные, которые в совокупности отражают то, как система, процесс или поведение изменяются с течением времени.
Характеристики данных временных рядов
Среди характеристик временных рядов можно выделить:
- Ориентированность на время: записи данных всегда имеют временную метку.
- Только добавление: данные практически исключительно добавляются наращиванием (
INSERT). - Актуальность: новые данные обычно относятся к последним временным интервалам, что позволяет реже делать обновления или заполнять недостающие данные о старых интервалах.
Частота (или регулярность) не важна. Данные можно получать каждую миллисекунду или час. Кроме этого, сбор может быть как регулярным, так и нерегулярным (например, по событию).
Ключевая особенность данных временных рядов заключается в том, что изменения в них выполняются вставками, а не заменами (как это происходит, например, при работе с реляционными данными).
Данные временных рядов используются в различных сферах, среди которых:
- Мониторинг компьютерных систем: метрики виртуальных машин, серверов, контейнеров (процессор, объем свободной памяти, объем/скорость дисковых операций), метрики сервисов и приложений (частота запросов, время обработки).
- Финансовые трейдинговые системы: классические ценные бумаги, криптовалюты, платежи, транзакции.
- Интернет вещей: данные с датчиков на промышленных машинах и оборудовании, носимых устройствах, транспортных средствах, физических контейнерах, грузовых поддонах, устройствах для умных домов и т.д.
- Обработка событий: данные о взаимодействии пользователя и клиента, такие как истории перемещений, просмотры страниц, логины, регистрации и т.д.
- Бизнес-аналитика: отслеживание ключевых показателей и общего состояния бизнеса.
- Мониторинг окружающей среды: температура, влажность, давление, рН, количество пыльцы, расход воздуха, окись углерода (CO), диоксид азота (NO2), твердые частицы (PM10).
Модель данных
Как реляционная база данных с полноценным SQL TimescaleDB поддерживает гибкие модели данных, которые могут быть оптимизированы для различных случаев использования. Это несколько отличает TimescaleDB от большинства других баз данных временных рядов, которые обычно используют модели «узких таблиц».
TimescaleDB может поддерживать модели как с широкими, так и с узкими таблицами. В этом разделе описаны различные компромиссы производительности и последствия использования этих двух моделей на примере Интернета вещей (IoT).
К примеру, существует распределенная группа из 1000 устройств IoT, предназначенных для сбора данных об окружающей среде с различными интервалами. Эти данные могут включать:
- Идентификаторы: device_id, timestamp
- Метаданные: location_id, dev_type, firmware_version, customer_id
- Метрики устройств: cpu_1m_avg, free_mem, used_mem, net_rssi, net_loss, battery
- Метрики датчиков: temperature, humidity, pressure, CO, NO2, PM10
Входные данные могут выглядеть следующим образом:
| timestamp | device_id | cpu_1m_avg | free_mem | temperature | location_id | dev_type |
|---|---|---|---|---|---|---|
| 2017-01-01 01:02:00 | abc123 | 80 | 500MB | 72 | 335 | field |
| 2017-01-01 01:02:23 | def456 | 90 | 400MB | 64 | 335 | roof |
| 2017-01-01 01:02:30 | ghi789 | 120 | 0MB | 56 | 77 | roof |
| 2017-01-01 01:03:12 | abc123 | 80 | 500MB | 72 | 335 | field |
| 2017-01-01 01:03:35 | def456 | 95 | 350MB | 64 | 335 | roof |
| 2017-01-01 01:03:42 | ghi789 | 100 | 100MB | 56 | 77 | roof |
Далее рассмотрены различные способы моделирования этих данных.
Модель с узкими таблицами
Временные ряды могут быть представлены как:
- отдельные сущности (например, cpu_1m_avg и free_mem как две разных вещи);
- последовательности пар «время»-«значение» для каждой метрики;
- наборы тегов и связанные с ними метрики (каждая комбинация метрики и набора тегов рассматривается как отдельный «временной ряд», содержащий последовательность пар время/значение).
При таком подходе пример выше превращается в 9 различных «временных рядов», каждый из которых определяется уникальным набором тегов.
1. {name: cpu_1m_avg, device_id: abc123, location_id: 335, dev_type: field}
2. {name: cpu_1m_avg, device_id: def456, location_id: 335, dev_type: roof}
3. {name: cpu_1m_avg, device_id: ghi789, location_id: 77, dev_type: roof}
4. {name: free_mem, device_id: abc123, location_id: 335, dev_type: field}
5. {name: free_mem, device_id: def456, location_id: 335, dev_type: roof}
6. {name: free_mem, device_id: ghi789, location_id: 77, dev_type: roof}
7. {name: temperature, device_id: abc123, location_id: 335, dev_type: field}
8. {name: temperature, device_id: def456, location_id: 335, dev_type: roof}
9. {name: temperature, device_id: ghi789, location_id: 77, dev_type: roof}
Количество временных рядов будет расти пропорционально перекрестному произведению мощностей множеств каждого тега, то есть (количество имен) × (количество идентификаторов устройств) × (количество идентификаторов местоположений) × (типы устройств). Некоторые базы данных временных рядов плохо справляются с объемными тегами (включающими большое количество множеств), что в конечном итоге ограничивает количество типов устройств, а также число устройств, которые можно хранить в одной базе данных.
TimescaleDB поддерживает узкие модели и не подвержен тем ограничениям, с которыми сталкиваются другие базы данных временных рядов. Узкая модель полезна, каждая метрика собирается независимо. Она позволяет создавать новые метрики, добавляя новые теги и не требуя формального изменения схемы.
Однако узкая модель менее эффективна, если для многих метрик характерна одна и та же метка времени, поскольку метка времени записывается для каждой метрики. Это приводит к росту требуемых ресурсов на хранение и обработку данных. Кроме этого, запросы, которые коррелируют различные метрики, усложняются, поскольку каждая дополнительная метрика требует очередной JOIN-операции. Если запрашиваются несколько метрик сразу, то рекомендуется хранить их в формате широких таблиц.
Модель с широкими таблицами
TimescaleDB полностью поддерживает модели с широкими таблицами. Запросы по нескольким метрикам в этой модели проще, так как они не требуют JOIN-операций. Кроме того, запись данных происходит быстрее, так как для нескольких метрик записывается только одна временная метка.
Типичная модель с широкой таблицей будет соответствовать потоку данных, в котором несколько метрик собираются в заданную временную метку:
| timestamp | device_id | cpu_1m_avg | free_mem | temperature | location_id | dev_type |
|---|---|---|---|---|---|---|
| 2017-01-01 01:02:00 | abc123 | 80 | 500MB | 72 | 42 | field |
| 2017-01-01 01:02:23 | def456 | 90 | 400MB | 64 | 42 | roof |
| 2017-01-01 01:02:30 | ghi789 | 120 | 0MB | 56 | 77 | roof |
| 2017-01-01 01:03:12 | abc123 | 80 | 500MB | 72 | 42 | field |
| 2017-01-01 01:03:35 | def456 | 95 | 350MB | 64 | 42 | roof |
| 2017-01-01 01:03:42 | ghi789 | 100 | 100MB | 56 | 77 | roof |
Здесь каждая строка представляет собой новый шаг сбора данных с набором измерений и метаданных в данный момент времени. Это позволяет сохранять связи внутри данных и задавать более сложные запросы.
JOIN-операции с реляционными данными
Модель данных TimescaleDB имеет еще одно сходство с реляционными базами данных: она поддерживает операции JOIN. Например, можно хранить дополнительные метаданные во вторичной таблице, а затем использовать эти данные во время запроса.
В примере ниже создается отдельная таблица locations, сопоставляющая location_id с дополнительными метаданными для местоположения:
| location_id | name | latitude | longitude | zip_code | region |
|---|---|---|---|---|---|
| 42 | Grand Central Terminal | 40.7527° N | 73.9772° W | 10017 | NYC |
| 77 | Lobby 7 | 42.3593° N | 71.0935° W | 02139 | Massachusetts |
Объединив эту таблицу с созданной выше, можно, например, создать запрос на вычисление средней free_mem устройств, у которых zip_code=10017.
Без JOIN понадобилась бы денормализация данных, а также сохранение всех метаданных со строками измерений. Это привело бы к «раздуванию» таблиц и затруднило бы управление ими.
С помощью операций JOIN можно хранить метаданные независимо, что упрощает обновление сопоставлений.
Например, если нужно обновить поле «region» для location_id 77 (т.е. изменить «Massachusetts» на «Boston»), возвращаться и перезаписывать данные не нужно.
Архитектура и концепции
Введение
TimescaleDB предоставляет собой отдельные таблицы, называемые гипертаблицами (Hypertable), которые являются абстракцией или виртуальным представлением множества отдельных таблиц, содержащих данные. Эти отдельные таблицы называются блоками (Chunk).

Блоки создаются путем партиционирования данных гипертаблиц на одно или несколько измерений: все гипертаблицы разбиваются по временному интервалу и дополнительно могут быть разбиты по ключу. В качестве ключа могут выступать, например, идентификатор устройства, местоположение, идентификатор пользователя. Такое партиционирование может быть названо партиционированием по времени и пространству.
Термины
Гипертаблицы
Основная точка взаимодействия с данными - это гипертаблица, абстракция одной непрерывной таблицы во всех пространственных и временных интервалах. К ней можно обращаться с помощью стандартного SQL.
Практически все операции пользователей с TimescaleDB происходят с гипертаблицами. Создание таблиц и индексов, их изменение, вставка данных и их выбор должны выполняться на основе гипертаблиц.
Гипертаблица определяется стандартной схемой с именами и типами столбцов. В одном из столбцов обязательно указывается значение времени, а в необязательном столбце может быть отражен дополнительный ключ партиционирования.
В одной базе TimescaleDB может храниться несколько гипертаблиц, каждая с различными схемами.
Гипертаблица в TimescaleDB создается двумя SQL-командами: CREATE TABLE (со стандартным синтаксисом SQL) и SELECT create_hypertable ().
Индексы по времени и ключу партиционирования для гипертаблиц создаются автоматически, но пользователем могут быть созданы дополнительные индексы (TimescaleDB поддерживает полный спектр типов индексов PostgreSQL).
Блоки
TimescaleDB автоматически разбивает каждую гипертаблицу на блоки, причем каждый блок соответствует определенному временному интервалу и области пространства ключа партиционирования (с использованием хеширования). Эти разделы не пересекают друг друга, что помогает планировщику запросов минимизировать набор блоков, по которым он должен пройти для разрешения запроса.
Каждый блок реализован с использованием стандартной таблицы базы данных. (Внутри PostgreSQL блоки на самом деле - «дочерние» таблицы «родительской» гипертаблицы.)
Блоки всегда создаются оптимального размера для того, чтобы все B-деревья для индексов таблицы помещались в памяти. Это позволяет избежать переполнения памяти при изменении произвольных местоположений в этих деревьях.
Кроме того, если нет слишком больших блоков, дорогостоящих операций можно избежать путем освобождения памяти от удаленных данных в соответствии с автоматизированными политиками хранения. Такие операции можно выполнять, удаляя определение блока (внутренней таблицы), а не отдельные строки.
Один узел и кластер
TimescaleDB активно партиционирует данные как на одном сервере, так и в кластере.
Хотя партиционирование традиционно используется только для масштабирования на нескольких машинах, его можно использовать и для достижения более высоких скоростей обработки данных и запросов (в том числе параллельных) даже на отдельных машинах.
Текущая версия TimescaleDB с открытым исходным кодом поддерживает только развертывание на одном узле. Следует отметить, что эта версия TimescaleDB тестировалась на гипертаблицах с более чем 10 миллиардами строк на машинах потребительского класса и не выявила потерь производительности по операции INSERT.
Преимущества партиционирования на одном узле
Распространенной проблемой при масштабировании производительности базы данных на одной машине является компромисс стоимости и эффективности между памятью и диском. Со временем данные перестают помещаться в памяти, и приходится записывать данные и индексы на диск.
Когда данные достигнут такого размера, что все страницы индексов (например, B-деревья) перестанут помещаться в памяти, обновление случайной части дерева может инициировать обращение к диску. Базы данных, такие как PostgreSQL, хранят B-дерево (или другую структуру данных) для каждого индекса таблицы, чтобы значения в этом индексе можно было эффективно находить. Таким образом, проблема усугубляется по мере роста количества индексируемых столбцов.
Поскольку каждый из блоков, созданных TimescaleDB, хранится как отдельная таблица базы данных, все его индексы строятся только по этим, гораздо меньшим, таблицам, а не по одной таблице, представляющей весь набор данных. Следовательно, если правильно определить размер этих блоков, можно полностью поместить самые новые таблицы (и их B-деревья) в память и избежать проблем чтения с диска, сохраняя при этом поддержку нескольких индексов.
Распределенные базы данных и узлы
Распределенная гипертаблица существует в распределенной базе данных, состоящей из нескольких баз, хранящихся в одном или нескольких экземплярах TimescaleDB. База данных, являющаяся частью распределенной базы данных, может выполнять роль либо узла доступа, либо узла данных (но не обоих одновременно).
Клиент подключается к базе данных - узлу доступа. Затем узел доступа распределяет запросы по узлам данных и агрегирует результаты, полученные от узлов данных. Узлы доступа хранят общекластерную информацию о различных узлах данных, а также о том, как блоки распределяются между этими узлами данных. Узлы доступа также могут хранить нераспределенные гипертаблицы, а также обычные таблицы PostgreSQL.
Узлы данных не хранят информацию по всему кластеру и в остальном функционируют, как автономные экземпляры TimescaleDB. Прямые обращения к гипертаблицам или блокам на узлах данных выполнять нельзя. Это может привести к несогласованности распределенных гипертаблиц.
Важно отметить, что узлы доступа и узлы данных работают на TimescaleDB и во всех отношениях действуют точно так же, как один экземпляр TimescaleDB с операционной точки зрения.
Настройка распределенных гипертаблиц
Для обеспечения оптимальной производительности распределенные гипертаблицы должны быть партиционированы по времени и пространству. Если данные партиционируются только по времени, то каждый новый блок будет заполняться, пока узел доступа не выберет другой узел данных для хранения следующего блока, поэтому в течение этого интервала времени все записи в последний интервал будут обрабатываться одним узлом данных, а не балансироваться по нагрузке между всеми доступными узлами данных. С другой стороны, если включить партиционирование по пространству, узел доступа распределит блоки между несколькими узлами данных так, чтобы для заданного интервала времени были созданы несколько блоков, и как чтение, так и запись в этот последний интервал времени будут сбалансированы по нагрузке на весь кластер.
По умолчанию количество разделов пространства устанавливается равным количеству узлов данных, если не указано иное. Система увеличит количество пространственных разделов при добавлении новых узлов данных, если это необходимо. При настройке вручную для оптимального распределения данных между узлами данных рекомендуется, чтобы число пространственных разделов было равно или кратно числу узлов данных, связанных с распределенной гипертаблицей. Если создано несколько пространственных разделов, только первый будет использоваться для определения того, как блоки распределяются между серверами.
Масштабирование распределенных гипертаблиц
По мере роста объема данных временных рядов распространенным вариантом использования становится добавление узлов данных для расширения хранилища и вычислительной емкости распределенных гипертаблиц. Таким образом, TimescaleDB можно эластично масштабировать, просто добавляя узлы данных в распределенную базу данных.
Как упоминалось ранее, TimescaleDB регулирует количество пространственных разделов по мере добавления новых узлов данных. Хотя в существующих блоках пространственные разделы не обновятся, новые настройки будут применены к вновь созданным блокам. Из-за такого поведения не требуется перемещать данные между узлами данных при увеличении размера кластера - достаточно обновлять способ распределения данных на следующий интервал времени. Записи для новых входящих данных будут использовать новые параметры партиционирования, в то время как узел доступа все еще может поддерживать запросы по всем блокам (даже тем, которые были созданы с использованием старых параметров партиционирования). Обратите внимание, что, хотя количество пространственных разделов может быть изменено, столбец, данные по которому партиционируются, не может быть изменен.
Преимущества использования TimescaleDB относительно реляционных баз данных
TimescaleDB предлагает три ключевых преимущества по сравнению с PostgreSQL и другими традиционными СУБД для хранения данных временных рядов:
- гораздо более высокая скорость приема и обработки данных, особенно при больших размерах баз данных;
- производительность запросов варьируется от эквивалентной до на порядки большей;
- особенности, уникальные для временных данных.
TimescaleDB позволяет использовать весь спектр функций и инструментов PostgreSQL, например: JOIN-операции с реляционными таблицами, геопространственные запросы через PostGIS, pg_dump и pg_restore.
Скорость обработки данных
TimescaleDB обеспечивает гораздо более высокую и стабильную скорость приема и обработки данных временных рядов по сравнению с PostgreSQL.
В разделе про архитектуру уже говорилось, что производительность PostgreSQL начинает значительно падать, как только индексированные таблицы перестают помещаться в памяти. В частности, всякий раз, когда добавляется новая строка, база данных должна обновлять индексы (например, B-деревья) для каждого из индексированных столбцов таблицы, что будет включать подгрузку одной или нескольких страниц с диска. Расширение объема памяти только снижает пропускную способность (показатель 10K-100K+ строк в секунду может упасть до сотен строк в секунду, как только таблица временных рядов разрастется до десятков миллионов строк).
TimescaleDB решает эту проблему за счет активного использования пространственно-временного партиционирования, даже при работе на одной машине. Таким образом, все записи в последние временные интервалы относятся только к таблицам, которые остаются в памяти, и в результате обновление любых вторичных индексов также происходит быстро.
Тесты показывают явное преимущество такого подхода. Приведенный ниже тест на 1 миллиард строк (на одной машине) эмулирует сценарий мониторинга, когда клиенты базы данных вставляют пакеты данных среднего размера, содержащие время, набор тегов устройства и несколько числовых метрик (в данном случае 10). Здесь эксперименты проводились на стандартной виртуальной машине Azure (DS4 v2, 8 core) с подключенным по сети SSD-накопителем.
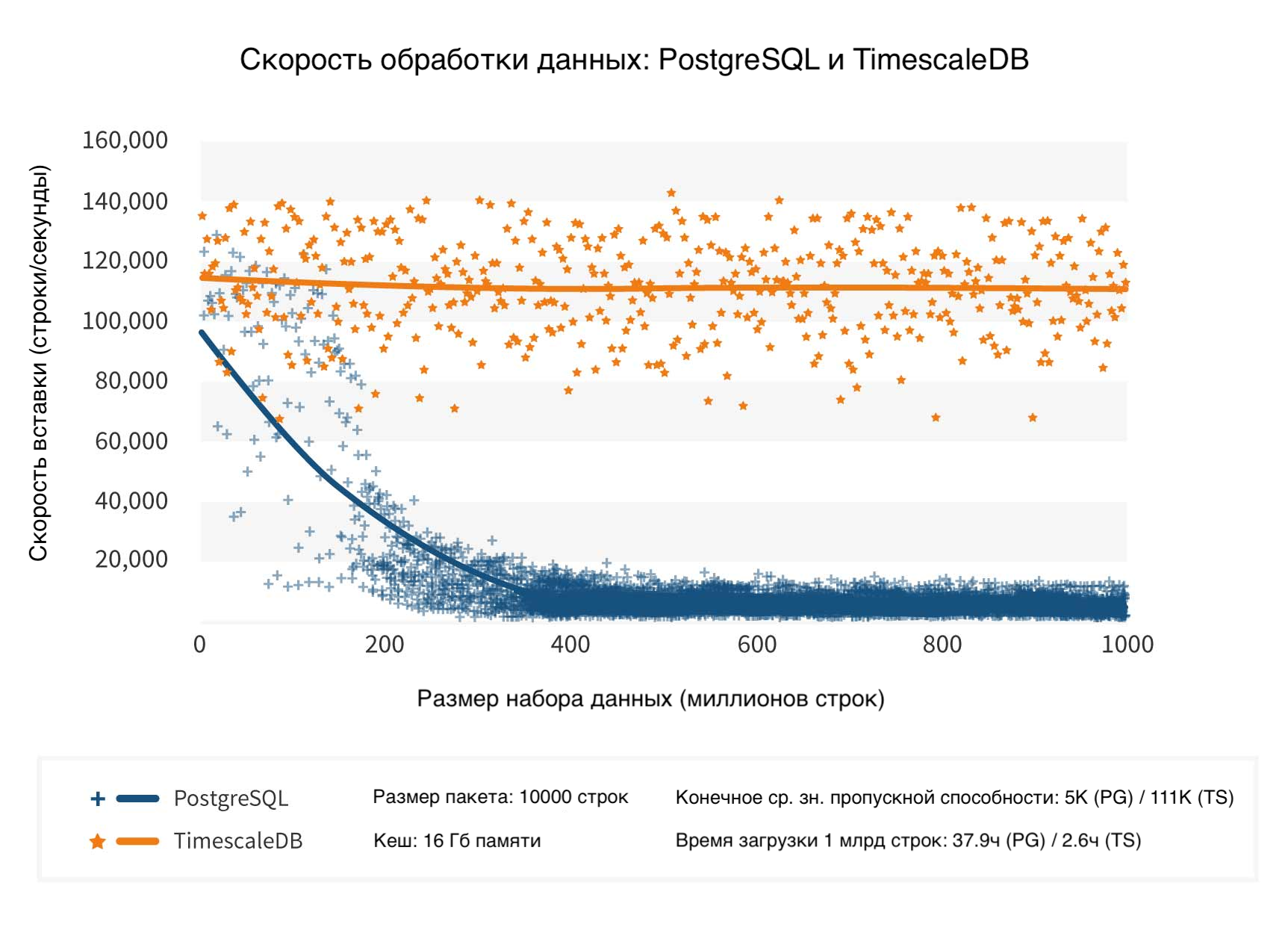
И PostgreSQL, и TimescaleDB начинают примерно с одинаковой пропускной способности (106K и 114K соответственно) для первых 20 млн запросов, или более 1 млн метрик в секунду. Однако на уровне около 50 млн строк производительность PostgreSQL начинает резко падать. Ее среднее значение за последние 100 млн строк составляет всего 5 тыс. строк/сек, в то время как TimescaleDB сохраняет свою пропускную способность в 111 тыс. строк/сек.
TimescaleDB загружает базу данных с одним миллиардом строк в пятнадцать раз быстрее PostgreSQL и показывает пропускную способность более чем в 20 раз больше, чем у PostgreSQL при этих больших объемах данных.
Проведенные тесты TimescaleDB показывают, что она поддерживает стабильную производительность на уровне более 10 миллиардов строк, даже с одним диском.
Производительность запросов
На машинах с одним диском многие простые запросы, которые выполняют индексированный поиск или сканирование таблиц, работают с одинаковой производительностью и на PostgreSQL, и на TimescaleDB.
Например, в таблице на 100 млн строк с индексированным временем, именем хоста и информацией об использовании ЦП следующий запрос займет менее 5 мс для каждой базы данных:
SELECT date_trunc('minute', time) AS minute, max(user_usage)
FROM cpu
WHERE hostname = 'host_1234'
AND time >= '2017-01-01 00:00' AND time < '2017-01-01 01:00'
GROUP BY minute ORDER BY minute;
Аналогичные запросы, которые включают базовое сканирование по индексу, также эквивалентно эффективны:
SELECT * FROM cpu
WHERE usage_user > 90.0
AND time >= '2017-01-01' AND time < '2017-01-02';
Более крупные запросы, включающие основанные на времени группировки, довольно распространены в ориентированном на время анализе и часто достигают более высокой производительности в TimescaleDB.
Например, следующий запрос, который проходит по 33 млн строк, в 5 раз быстрее в TimescaleDB, когда вся гипертаблица состоит из 100 млн строк, и примерно в 2 раза быстрее, когда она состоит из 1 млрд строк:
SELECT date_trunc('hour', time) as hour,
hostname, avg(usage_user)
FROM cpu
WHERE time >= '2017-01-01' AND time < '2017-01-02'
GROUP BY hour, hostname ORDER BY hour;
Более того, другие запросы (например, с упорядочиванием по времени), могут быть гораздо более производительными в TimescaleDB. Например, TimescaleDB вводит временную оптимизацию merge append, которая минимизирует количество групп, подлежащих обработке, для выполнения представленного ниже запроса (учитывая, что база знает заранее, что время уже упорядочено). Для таблицы на 100 млн строк результат обработки в 396 раз быстрее, чем у PostgreSQL (82 мс против 32,566 мс):
SELECT date_trunc('minute', time) AS minute, max(usage_user) FROM cpu WHERE time < '2017-01-01' GROUP BY minute ORDER BY minute DESC LIMIT 5;
Таким образом, почти для каждого рассмотренного запроса TimescaleDB достигает либо аналогичной, либо превосходящей (или значительно превосходящей) производительности в сравнении со стандартной PostgreSQL.
В качестве недостатка TimescaleDB в сравнении с PostgreSQL можно привести более сложное планирование (учитывая, что одна гипертаблица порой состоит из большого количества блоков). Это может привести к нескольким дополнительным миллисекундам времени планирования, что может иметь непропорциональное влияние на запросы с очень низкой задержкой (менее 10 мс).
Дополнительные функции для временных данных
TimescaleDB включает в себя ряд ориентированных на время функций, которые не встречаются в традиционных реляционных базах данных.
К ним относятся специальные оптимизации запросов (например, merge append, упомянутый выше), которые обеспечивают некоторые из улучшений производительности для ориентированных на время запросов, а также другие функции, ориентированные на время (некоторые из которых перечислены ниже).
Использование в аналитике
TimescaleDB включает в себя новые функции для ориентированной на время аналитики, например:
time_bucket: более мощная версия стандартной функцииdate_trunc. Эта функция позволяет использовать произвольные временные интервалы (например, 5 минут, 6 часов и так далее), а также гибкие группировки и смещения, а не только секунды, минуты, часы и так далее;- агрегаты
lastиfirst: эти функции позволяют получить значение одного столбца по порядку другого. Например,last (temperature, time)вернет последнее значение температуры, основанное на времени внутри группы (например, час).
Эти типы функций позволяют выполнять очень естественные ориентированные на время запросы. Следующий финансовый запрос, например, выводит на печать открытие, закрытие, максимум и минимум цены каждого актива:
SELECT time_bucket('3 hours', time) AS period asset_code, first(price, time) AS opening, last(price, time) AS closing, max(price) AS high, min(price) AS low FROM prices WHERE time > NOW() - INTERVAL '7 days' GROUP BY period, asset_code ORDER BY period DESC, asset_code;
Способность last упорядочивать по вторичному столбцу (даже отличающемуся от агрегата) позволяет выполнять некоторые сложные типы запросов. Например, в финансовой отчетности часто применяется метод битемпорального моделирования, который отдельно определяет время, связанное с наблюдением, и время, когда это наблюдение было зарегистрировано. В такой модели исправления вставляются в виде новой строки (с более поздним полем time_recorded) и не заменяют существующие данные.
Следующий запрос возвращает дневную цену для каждого актива, упорядоченную по последней зарегистрированной цене:
SELECT time_bucket('1 day', time) AS day, asset_code, last(price, time_recorded) FROM prices WHERE time > '2017-01-01' GROUP BY day, asset_code ORDER BY day DESC, asset_code;
Управление временными данными
TimescaleDB предоставляет ряд возможностей управления данными, которые не всегда доступны или эффективны в PostgreSQL. Например, при работе с данными временных рядов данные часто накапливаются очень быстро. К примеру, необходимо описать политику хранения данных следующего вида: «хранить необработанные данные только в течение недели».
На самом деле это часто сочетается с использованием непрерывных агрегатов, поэтому можно сохранить две гипертаблицы: одну с необработанными данными, другую с данными, которые уже были свернуты в поминутные или почасовые агрегаты. Затем можно определить различные политики хранения для двух гипертаблиц, сохраняя агрегированные данные гораздо дольше.
TimescaleDB позволяет эффективно удалять старые данные на уровне блоков, а не на уровне строк, благодаря функции drop_chunks.
SELECT drop_chunks('conditions', INTERVAL '7 days');
Эта команда удалит все блоки (файлы) из таблицы conditions, которые включают только данные старше этой продолжительности, а не какие-либо отдельные строки данных в блоках. Так избегается фрагментация в основных файлах базы данных, а это, в свою очередь, позволяет исключить очистку памяти — операцию, которая может быть непомерно дорогой в очень больших таблицах.
Установка
-
Пропишите в конфигурационном файле СУБД Pangolin название расширения в настроечный параметр
shared_preload_libraries:shared_preload_libraries = 'timescaledb' -
Активируйте расширение
timescaledbкомандой:CREATE EXTENSION timescaledb SCHEMA ext;
Первоначальное заполнение данными
Если используется кластерный вариант поставки Pangolin, то перед первоначальным наполнением данных необходимо перевести кластер в асинхронный режим и остановить ведомый сервер. Далее ведущий сервер пополняется данными. Чтобы возобновить потоковую репликацию, требуется привести ведомый сервер в состояние, когда он сможет воспроизводить файлы журнала с ведущего сервера:
-
Удалите директории БД и табличных пространств ведомого сервера:
rm -rf $PGDATA/* ; rm -rf <tablespace_location>/* -
Выполните команду восстановления используя IP-адрес ведущего сервера:
pg_basebackup -h <primary_ip> -D <local_data_directory> -U <user with replication grants> -P -R -X stream -
Запустите Pangolin на ведомом сервере, дождитесь синхронизации.
Также возможно использовать команду reinit сервиса Pangolin Manager.
Обновления
В релизе Pangolin 7.1.0 расширение TimescaleDB было обновлено до версии 2.19.3.
Список изменений можно посмотреть в «Timescale release notes» официальной документации.
Ссылки на документацию разработчика
Дополнительно поставляемый модуль timescaledb: https://docs.timescale.com/