citus. Добавление столбцового хранения и возможности организации распределенной OLAP БД
Версия: 13.0.1
В исходном дистрибутиве установлено по умолчанию: нет.
Связанные компоненты: отсутствуют.
Схема размещения:
citus.В рамках данной задачи достигается совместимость свободно распространяемого расширения Citus с продуктом СУБД Pangolin. Необходимые доработки производятся в продукте Pangolin, расширение Citus тестируется на совместимость, как есть. В случае необходимости доработок их необходимо осуществлять через сообщество Citus.
Архитектура расширения
Термины и определения
Узлы
Citus - это расширение для PostgreSQL, которое позволяет обычным серверам баз данных (называемым узлами) взаимодействовать друг с другом в архитектуре “общего доступа”. Узлы образуют кластер, который позволяет PostgreSQL хранить больше данных и использовать больше процессорных ядер, чем это было бы возможно на одном компьютере. Эта архитектура также позволяет масштабировать базу данных, просто добавляя дополнительные узлы в кластер.
Узел-координатор и рабочие узлы
В каждом кластере есть один специальный узел, называемый координатором (остальные узлы называются рабочими). Приложения отправляют свои запросы на узел-координатор, который передает их соответствующим рабочим узлам и накапливает результаты. Для каждого запроса координатор либо направляет его на один рабочий узел, либо распараллеливает на несколько, в зависимости от того, хранятся ли требуемые данные на одном узле или на нескольких. Координатор знает, как это сделать, сверяясь со своими таблицами метаданных. В этих таблицах сохраняются DNS-имена и состояние рабочих узлов, а также распределение данных по узлам.
Сегментирование
Сегментирование - это метод, используемый в системах баз данных и распределенных вычислениях для горизонтального распределения данных по нескольким серверам или узлам. Он включает в себя разбиение большой базы данных или набора данных на более мелкие, более управляемые части, называемые сегментами. Каждый сегмент содержит подмножество данных, и вместе они образуют полный набор данных. Citus предлагает два типа сегментирования данных: на основе строк и на основе схем. Каждый вариант имеет свои собственные компромиссы в области сегментирования, позволяющие выбрать подход, который наилучшим образом соответствует требованиям приложения.
Сегментирование на основе строк
Традиционный способ сегментирования таблиц Citus в базе данных - это модель общей схемы, также известная как сегментирование на основе строк, при этом каждый узел содержит часть строк одной таблицы. Узел определяется путем столбца распределения, который позволяет разделить таблицу на строки. Это наиболее эффективный с точки зрения аппаратного обеспечения способ совместного использования. Клиенты плотно упакованы и распределены между узлами кластера. Однако при таком подходе необходимо убедиться, что все таблицы в схеме содержат столбец распределения и что все запросы в приложении фильтруются по нему. Сегментирование на основе строк отлично подходит для реализации, например, интернета вещей и позволяет добиться максимальной отдачи от использования оборудования.
Достоинства такого подхода:
- наилучшая производительность;
- наилучшая плотность пользователей на узел.
Недостатки:
- требует внесения изменений в схему;
- требует внесения изменений в запросы приложения;
- все клиенты должны использовать одну и ту же схему.
Сегментирование на основе схем
Доступное начиная с Citus 12.0 сегментирование на основе схем - это общая база данных, при этом схема становится логическим сегментом в базе данных. Мультитенантные приложения могут использовать схему для каждого клиента, что упрощает сегментирование по параметру клиента. Изменения запроса не требуются, и приложению обычно требуется лишь небольшая модификация для установки правильного пути поиска при переключении клиентов. Сегментирование на основе схем является идеальным решением для микросервисов и для интернет-провайдеров, развертывающих приложения, которые не могут подвергаться изменениям, необходимым для встроенного сегментирования на основе строк.
Достоинства:
- клиенты могут использовать разнородные схемы;
- модификация схемы не требуется;
- модификация запросов приложения не требуется;
- сегментирование на основе схемы обеспечивает лучшую совместимость с SQL по сравнению с сегментированием на основе строк.
Недостатки: меньшее количество арендаторов на узел по сравнению с сегментированием на основе строк
Особенности сегментирования разными способами
| Сегментирование на основе схем | Сегментирование на основе строк | |
|---|---|---|
| Мультитенантная модель | Отдельная схема на каждый тенант | Общая для всех тенантов таблица с распределением данных на основе уникального ключа |
| Поддерживаемая версия Citus | 12.0+ | Все версии |
| Дополнительные действия в PostgreSQL | Только изменение конфигурационных параметров | Изменение конфигурационных параметров, а также использование функции create_distributed_table для каждой таблицы и распределение по tenant ID(необходимо добавить ключ) |
| Количество тенантов | 1-10k | 1-1M+ |
| Требования к определению данных | Отсутствие внешних ключей между схемами | Необходимо добавление столбца tenant ID (столбец распределения, также называемый ключом сегментирования) в каждой таблице, в каждом первичном ключе и в каждом внешнем ключе |
| SQL требования к запросу на одном узле | Использование одной схемы в запросе | Joins и WHERE условия обязательно должны включать столбец с tenant_id(столбец распределения) |
| Параллельные кросс-тенантные запросы | Нет | Да |
| Собственные определения таблиц на тенантах | Да | Нет |
| Ролевая модель | Доступы в схеме | Доступы в схеме |
| Обмен данных между тенантами | Да, с использованием референсной таблицы(в отдельной схеме) | Да, с использованием референсной таблицы |
| Изоляция тенантов | У каждого тенанта есть своя собственная группа сегментов | Можно присвоить определенным идентификаторам тенантов их собственную группу сегмент с помощью функции isolate_tenant_to_new_shard |
Распределение данных
Существует 5 видов таблиц, каждый из которых используется для определенных задач.
Тип1: Распределенные таблицы
Первый тип, наиболее распространенный - это распределенные таблицы. Они выглядят как обычные таблицы для операторов SQL, но распределены по рабочим узлам горизонтально.
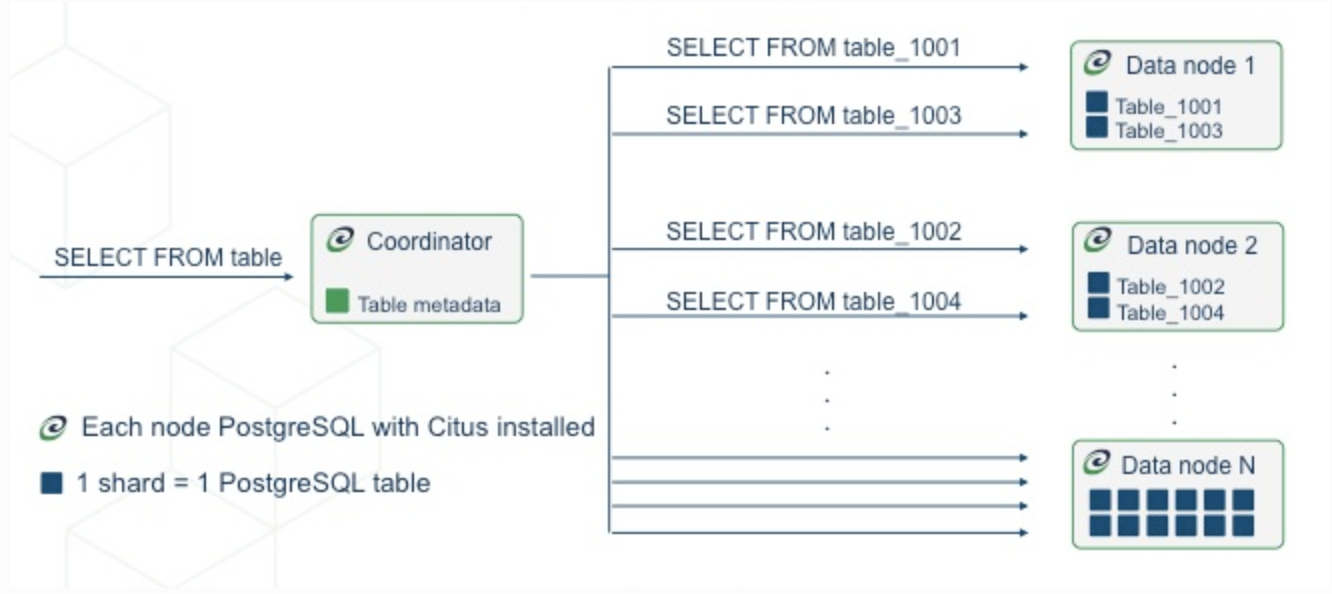
Здесь строки таблицы хранятся в таблицах table_1001, table_1002 и т.д. на рабочих узлах. Компоненты таблицы называются сегментами. Citus выполняет не только инструкции SQL, но и инструкции DDL в кластере, поэтому изменение схемы распределенной таблицы приводит к каскадному обновлению всех сегментов таблицы на узлах.
Столбец распределения
Citus использует алгоритмическое сегментирование для распределения строк по сегментам. Это означает, что назначение производится детерминистически – в данном случае на основе значения определенного столбца таблицы, называемого столбцом распределения. Администратор кластера должен назначить этот столбец при распределении таблицы. Правильный выбор важен для повышения производительности и функциональности, как описано в общем разделе о моделировании распределенных данных.
Тип 2: справочные(референсные) таблицы
Справочная таблица - это тип распределенной таблицы, все содержимое которой сосредоточено в одном сегменте, который реплицируется на каждом рабочем элементе. Таким образом, запросы на любом рабочем элементе могут получать доступ к справочной информации локально, без необходимости запрашивать строки из другого узла в сети. В справочных таблицах нет столбца распределения, поскольку нет необходимости выделять отдельные сегменты для каждой строки. Справочные таблицы обычно небольшие и используются для хранения данных, которые имеют отношение к запросам, выполняемым на любом рабочем узле. Например, перечисляемые значения, такие как статусы заказов или категории продуктов. При взаимодействии со справочной таблицей автоматически выполняется двухэтапная фиксация транзакций (2PC). Это означает, что Citus гарантирует, что данные всегда будут в согласованном состоянии, независимо от того, производится ли их запись, изменение или удаление.
Тип 3: локальные таблицы
При использовании Citus узел-координатор, к которому производится подключение, является обычной базой данных PostgreSQL с установленным расширением Citus. Таким образом, возможно создание обычных таблиц без предоставления к ним общего доступа. Это полезно для небольших административных таблиц, которые не участвуют в запросах объединения. Примером может служить таблица пользователей для входа в приложение и аутентификации. Создавать стандартные таблицы PostgreSQL легко, потому что они используются по умолчанию. При выполнении команды CREATE TABLE практически в каждом экземпляре Citus стандартные таблицы PostgreSQL сосуществуют с распределенными и справочными таблицами. Действительно, как упоминалось ранее, Citus сам использует локальные таблицы для хранения метаданных кластера.
Тип 4: локальные управляемые таблицы
Когда параметр citus.enable_local_reference_table_foreign_keys (boolean) включен, Citus может автоматически добавлять локальные таблицы в метаданные, если локальная таблица и справочная таблица связаны внешним ключом. Кроме того, эти таблицы можно создать вручную, выполнив функцию citus_add_local_table_to_metadata() для обычных локальных таблиц. Таблицы, представленные в метаданных, считаются управляемыми таблицами и могут быть запрошены с любого узла, Citus будет знать, как направить запрос координатору для получения данных из локальной управляемой таблицы. Такие таблицы отображаются как локальные в представлении таблиц Citus.
Тип 5: таблицы схем
При использовании сегментирования на основе схем, появившегося в Citus 12.0, распределенные схемы автоматически связываются с отдельными группами совместного размещения, так, что таблицы, созданные в этих схемах, автоматически преобразуются в распределенные таблицы без ключа сегмента. Такие таблицы считаются таблицами схемы и отображаются в виде схемы в представлении citus_tables.
Сегменты
В предыдущем разделе описывалось, как определяется подмножество строк распределенной таблицы в таблице меньшего размера внутри рабочего узла. В этом разделе более подробно рассматриваются технические детали. Таблица метаданных pg_dist_shared в координаторе содержит строку для каждого сегмента каждой распределенной таблицы в системе. Строка сопоставляет shardid с диапазоном целых чисел в хеш-пространстве (shardminvalue, shardmaxvalue):
SELECT * from pg_dist_shard;
logicalrelid | shardid | shardstorage | shardminvalue | shardmaxvalue
---------------+---------+--------------+---------------+---------------
github_events | 102026 | t | 268435456 | 402653183
github_events | 102027 | t | 402653184 | 536870911
github_events | 102028 | t | 536870912 | 671088639
github_events | 102029 | t | 671088640 | 805306367
(4 rows)
Если узел-координатор хочет определить, в каком сегменте содержится строка github_events, он хеширует значение столбца распределения в строке и проверяет, в каком диапазоне сегмента содержится хешированное значение. (Диапазоны определены таким образом, что хеш-функция представляет собой их непересекающееся объединение.)
Распределение сегментов
Предположим, что с указанной строкой связан сегмент 102027. Это означает, что строка должна быть прочитана или записана в таблицу с именем github_events_102027 на одном из рабочих узлов. Какой это узел? Это полностью определяется таблицами метаданных, а сопоставление сегмента с рабочим узлом называется размещением сегмента. Объединение таблиц метаданных дает ответ на данный вопрос. Координатор выполняет для маршрутизации запросов следующие действия: он делит запросы на фрагменты, которые ссылаются на конкретные таблицы, такие как github_events_102027, и запускает эти фрагменты в соответствующих рабочих системах.
SELECT
shardid,
node.nodename,
node.nodeport
FROM pg_dist_placement placement
JOIN pg_dist_node node
ON placement.groupid = node.groupid
AND node.noderole = 'primary'::noderole
WHERE shardid = 102027;
┌─────────┬───────────┬──────────┐
│ shardid │ nodename │ nodeport │
├─────────┼───────────┼──────────┤
│ 102027 │ localhost │ 5433 │
└─────────┴───────────┴──────────┘
В этом примере у таблицы github_events было четыре сегмента. Количество сегментов настраивается для каждой таблицы во время ее распределения по кластеру. Оптимальный выбор количества сегментов зависит от конкретного варианта использования.
Также обратите внимание на то, что Citus позволяет реплицировать сегменты для защиты от потери данных с помощью потоковой репликации PostgreSQL. Потоковая репликация позволяет создавать резервные копии каждого узла. Данный процесс прозрачен и не требует использования таблиц метаданных Citus.
Совместное расположение
Поскольку сегменты могут быть размещены на узлах как угодно, имеет смысл размещать сегменты, содержащие связанные строки связанных таблиц на одних и тех же узлах. Таким образом, запросы объединения таких данных позволяют избежать отправки большого количества информации по сети и могут выполняться внутри одного узла Citus. В качестве примера можно привести базу данных с магазинами, продуктами и покупками. Если все три таблицы содержат столбец store_id и распределяются по нему, то все запросы, ограниченные одним магазином, могут эффективно выполняться на одном рабочем узле. Это верно всегда, запросы могут включать любую комбинацию этих таблиц.
Параллелизм
Распределение запросов по нескольким компьютерам позволяет выполнять больше запросов одновременно и позволяет увеличить скорость обработки за счет добавления новых компьютеров в кластер. Кроме того, разбиение одного запроса на фрагменты, как описано в предыдущих разделах, повышает вычислительную мощность. В последнем случае достигается наиболее оптимальное распараллеливание. Запросы, считывающие сегменты или влияющие на них, равномерно распределенные по многим узлам, могут выполняться в реальном времени. Обратите внимание, что результаты запроса по-прежнему должны передаваться обратно через узел-координатор, поэтому ускорение наиболее заметно, когда конечные результаты являются компактными, например, при использовании агрегированных функций, таких как подсчет и описательная статистика.
Выполнение запросов
При выполнении запросов с несколькими сегментами Citus должен балансировать между выгодой от параллелизма с издержками, связанными с подключениями к базе данных (задержка сети и использование ресурсов рабочего узла). Чтобы настроить выполнение запросов Citus для достижения наилучших результатов для конкретного профиля нагрузки на базу данных, полезно понять, как Citus управляет подключениями к базе данных между узлом-координатором и рабочими узлами и сохраняет их. Citus преобразует каждый входящий запрос с несколькими сегментами в запросы для каждого сегмента, называемые задачами. Он ставит задачи в очередь и запускает их, как только удается установить соединение с соответствующим рабочим узлом. Для запросов к распределенным таблицам foo и bar приведена схема управления подключениями:
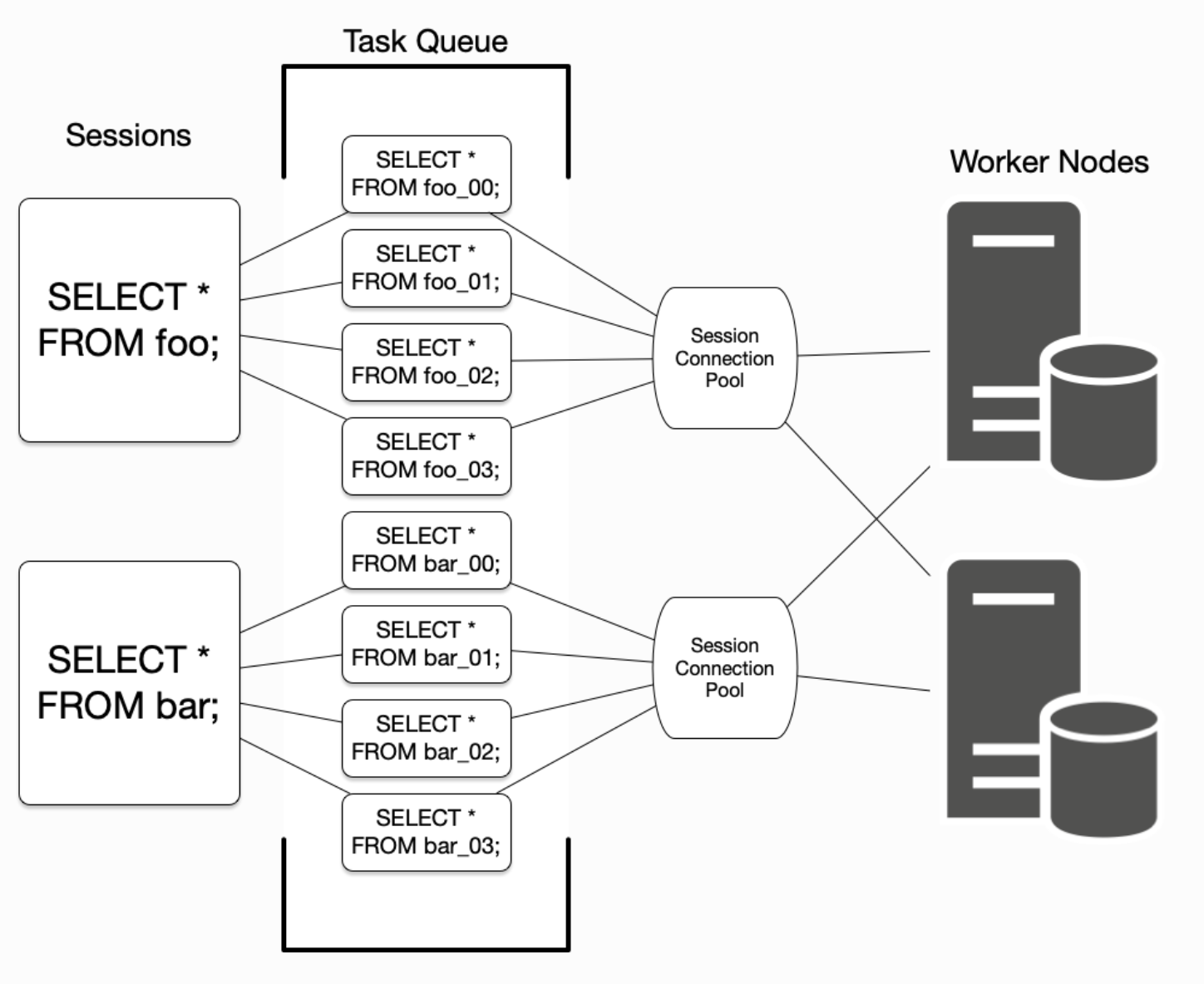
Узел-координатор удерживает пул подключений для каждой сессии. Каждый запрос (например, SELECT * FROM foo на диаграмме) ограничен открытием не более чем citus.max_adaptive_executor_pool_size(integer) одновременных подключений для каждого рабочего узла. Этот параметр настраивается на уровне сеанса для управления приоритетами.
Предполагается, что короткие задачи быстрее выполнять последовательно по одному и тому же соединению, чем устанавливать для них новые соединения параллельно. С другой стороны, для длительно выполняемых задач преимущество заключается в большем распараллеливании.
Для оптимизации коротких и длительных задачах, Citus опирается на параметр citus.executor_slow_start_interval (integer). Этот параметр определяет задержку между попытками подключения для задач в многосегментном запросе. Когда запрос сначала ставит задачи в очередь, они могут подключаться только к одному соединению. В конце каждого интервала, когда есть ожидающие подключения, Citus увеличивает количество одновременно открываемых подключений. Режим медленного запуска можно полностью отключить, установив значение параметра равным 0.
Когда задача завершается, соединение в пуле остается открытым для последующего использования. Кеширование соединения позволяет избежать затрат на восстановление соединения между координатором и рабочим узлом. Однако каждый пул будет содержать не более citus.max_cached_conns_per_worker(integer) свободных подключений, открытых одновременно, чтобы ограничить использование ресурсов ненужными соединениями на рабочем узле.
Наконец, параметр citus.max_shared_pool_size(integer) ограничивает общее количество подключений на один рабочий узел.
Описание функций
Команды DDL для управления таблицами и сегментами
citus_schema_distribute(schemaname regnamespace) returns void
Позволяет преобразовать существующие обычные схемы в распределенные схемы, которые автоматически связываются с отдельными группами совместного размещения, так что таблицы, созданные в этих схемах, будут автоматически преобразованы в совместно размещенные распределенные таблицы без ключа сегмента. В процессе распространения схемы она будет автоматически назначена и перемещена на существующий узел в кластере. В качестве аргумента данная функция принимает имя схемы, которую необходимо распределить.
Пример использования:
SELECT citus_schema_distribute('tenant_a');
SELECT citus_schema_distribute('tenant_b');
SELECT citus_schema_distribute('tenant_c');
citus_schema_undistribute(schemaname regnamespace) returns void
Преобразует существующую распределенную схему обратно в обычную схему. В результате этого процесса таблицы и данные перемещаются с текущего узла обратно на узел-координатор в кластере. В качестве аргумента принимает имя схемы, распределение для которой необходимо отменить.
Пример использования:
SELECT citus_schema_undistribute('tenant_a');
SELECT citus_schema_undistribute('tenant_b');
SELECT citus_schema_undistribute('tenant_c');
create_distributed_table (table_name regclass, distribution_column text, distribution_type citus.distribution_type, [ colocate_with text ], [ shard_count int ]) returns void
Используется для определения распределенной таблицы и создания ее фрагментов, если это таблица с распределенным хешем. Эта функция принимает в качестве аргументов:
- имя таблицы;
- столбец распределения;
- метод распределения (необязательный параметр) - данный параметр включает текущую таблицу в группу совместного размещения другой таблицы. По умолчанию таблицы размещаются совместно, если они распределены по столбцам одного типа с одинаковым количеством сегментов. В случае необходимости изменить это распределение позже, возможно использовать функцию
update_distributed_table_colocation. Возможными значениями дляcolocate_withявляютсяdefault, none для создания новой группы совместного размещения или имя другой таблицы для совместного размещения с этой таблицей (см. раздел совместное расположение таблиц). Имейте в виду, что значениеcolocate_withпо умолчанию подразумевает совместное расположение. Как поясняется в описании совместного расположения таблиц, это может быть полезно, когда таблицы связаны или будут объединены. Однако, когда две таблицы не связаны между собой, но случайно используют один и тот же тип данных для своих распределенных столбцов, их случайное совместное расположение может снизить производительность при ребалансировке сегментов. Сегменты таких таблиц будут перемещены совместно без необходимости указания директивы cascade. Если необходимо изменить это неявное поведение, возможно воспользоваться функциейupdate_distributed_table_colocation. Если новая распределенная таблица не связана с другими таблицами, лучше всего указатьcolocate_with => 'none'; - количество сегментов (необязательный параметр) - определяет количество сегментов, которые нужно создать для новой распределенной таблицы. При указании этого параметра нельзя указать значение
colocate_with, отличное отnone. Чтобы изменить количество сегментов в существующей таблице или группе совместного размещения (co-location group), используйте функциюalter_distributed_table. Возможные значения для параметраshard_countнаходятся в диапазоне от1до64000. Рекомендации по выбору оптимального значения приведены в разделе Количество сегментов.
В результате работы функция вставляет соответствующие метаданные, чтобы пометить таблицу как распределенную. Функция по умолчанию использует распределение по хешу, если метод распределения не указан. Если таблица распределена по хешу, функция также создает рабочие сегменты на основе значения конфигурации количества сегментов. Если таблица содержит какие-либо строки, они автоматически распределяются по рабочим узлам.
Пример использования:
SELECT create_distributed_table('github_events', 'repo_id');
-- alternatively, to be more explicit:
SELECT create_distributed_table('github_events', 'repo_id',
colocate_with => 'github_repo');
В этом примере таблица github_events будет распределена по хешу в столбце repo_id.
truncate_local_data_after_distributing_table (function_name regclass) returns void
Выполняет усечение всех локальных строк после распространения таблицы и предотвращает сбои из-за устаревших локальных записей. Усечение выполняется каскадно для таблиц, имеющих внешний ключ к указанной таблице. Если ссылающиеся таблицы сами по себе не распространяются, то усечение запрещено до тех пор, пока они не будут распространены, чтобы защитить целостность ссылок. При попытке выполнить такое усечение возникнет ошибка:
ERROR: cannot truncate a table referenced in a foreign key constraint by a local table
Усечение данных таблицы узлов локального координатора безопасно для распределенных таблиц, поскольку их строки, если таковые имеются, копируются на рабочие узлы во время распространения. В качестве аргумента функция принимает имя таблицы для усечения. Пример использования:
-- requires that argument is a distributed table
SELECT truncate_local_data_after_distributing_table('public.github_events');
undistribute_table (table_name regclass, cascade_via_foreign_keys boolean) returns void
Отменяет действие create_distributed_table или create_reference_table. Функция перемещает все данные из сегментов обратно в локальную таблицу на узле-координаторе (при условии, что данные могут поместиться), а затем удаляет сегменты. Citus не будет отменять распространение таблиц, которые содержат внешние ключи или на которые ссылаются внешние ключи, если только аргументу cascade_via_foreign_keys не присвоено значение true. Если этот аргумент имеет значение false (или опущен), то необходимо вручную удалить нарушающие ограничения внешнего ключа перед отменой распространения. В качестве аргументов функция принимает имя таблицы, распределение которой необходимо отменить, а также необязательный параметр cascade_via_foreign_keys. Если для этого параметра установлено значение true, функция также отменяет распределение всех таблиц, связанных с table_name через внешние ключи. Необходимо осторожно относиться к этому параметру, поскольку он потенциально может повлиять на многие таблицы.
Пример использования:
-- first distribute the table
SELECT create_distributed_table('github_events', 'repo_id');
-- undo that and make it local again
SELECT undistribute_table('github_events');
alter_distributed_table (table_name regclass, distribution_column text, shard_count int, colocate_with text, cascade_to_colocated boolean) returns void
Изменяет столбец распределения, количество сегментов или свойства расположения в распределенной таблице. В качестве аргументов принимает имя таблицы, столбец распределения(необязательный параметр), количество сегментов(необязательный параметр), таблицу для совмещения(см. параметр colocate_with функции create_distributed_table) и необязательный параметр cascade_to_colocated. Когда этому аргументу присвоено значение true, изменения shard_count и colocate_with также будут применены ко всем таблицам, которые ранее были размещены совместно с изменяемой таблицей, и расположение будет сохранено. Если оно равно false, текущее размещение этой таблицы будет нарушено. Пример использования:
-- change distribution column
SELECT alter_distributed_table('github_events', distribution_column:='event_id');
-- change shard count of all tables in colocation group
SELECT alter_distributed_table('github_events', shard_count:=6, cascade_to_colocated:=true);
-- change colocation
SELECT alter_distributed_table('github_events', colocate_with:='another_table');
alter_table_set_access_method (table_name regclass, access_method text) returns void
Изменяет метод хранения(heap или columnar). В качестве аргументов принимает имя таблицы и метод доступа.
Пример использования:
SELECT alter_table_set_access_method('github_events', 'columnar');
remove_local_tables_from_metadata() returns void
Удаляет локальные таблицы из метаданных Citus, если они больше не должны там находиться. (См. параметр citus.enable_local_reference_table_foreign_keys(boolean) )
Обычно, если локальная таблица находится в метаданных Citus, на это есть причина, например, наличие внешних ключей между таблицей и справочной таблицей. Однако, если параметр enable_local_reference_foreign_keys отключен, Citus больше не будет управлять метаданными в этой ситуации, и ненужные метаданные могут сохраняться до тех пор, пока они не будут удалены вручную.
Пример использования:
SELECT remove_local_tables_from_metadata();
create_reference_table (table_name regclass) returns void
Используется для определения небольшой справочной таблицы или таблицы измерений. Принимает в качестве аргумента имя таблицы и создает распределенную таблицу всего с одним сегментом, реплицируемую на каждый рабочий узел.
Пример использования:
SELECT create_reference_table('nation');
citus_add_local_table_to_metadata (table_name regclass, cascade_via_foreign_keys boolean) returns void
Добавляет локальную таблицу PostgreSQL в метаданные Citus. Основным вариантом использования этой функции является обеспечение доступа к локальным таблицам в координаторе с любого узла кластера. В основном это полезно при выполнении запросов с других узлов. Данные, связанные с локальной таблицей, остаются в координаторе – рабочим элементам отправляются только их схема и метаданные. Обратите внимание, что добавление локальных таблиц к метаданным сопряжено с небольшими затратами. При добавлении таблицы Citus должен отслеживать ее в таблице разделов. Локальные таблицы, добавляемые в метаданные, наследуют те же ограничения, что и справочные таблицы. Если используется undistributed_table, Citus автоматически удалит результирующие локальные таблицы из метаданных, что устранит такие ограничения для этих таблиц.
В качестве аргументов функция принимает имя таблицы на координаторе для распространения, а также параметр cascade_via_foreign_keys. Если для этого параметра установлено значение true, функция автоматически добавляет в метаданные другие таблицы, которые связаны внешним ключом с данной таблицей. Будьте осторожны с этим параметром, поскольку он потенциально может повлиять на многие таблицы.
Пример использования:
SELECT citus_add_local_table_to_metadata('nation');
update_distributed_table_colocation (table_name regclass, colocate_with text) returns void
Используется для обновления параметров совместного размещения распределенной таблицы. Эта функция также может использоваться для отмены совместного размещения распределенной таблицы. Citus неявно объединит две таблицы, если столбец распределения имеет один и тот же тип, это может быть полезно, если таблицы связаны и будут выполняться запросы с объединением этих таблиц. Если таблицы A и B будут объединены, и таблица A будет ребалансирована, таблица B также будет ребалансирована. Если таблица B не имеет идентификатора реплики, балансировка не будет выполнена. Следовательно, в этом случае эта функция может быть полезна для устранения неявного совместного размещения. Обратите внимание, что эта функция не перемещает какие-либо данные физически. В качестве аргументов принимается имя таблицы, параметры совместного размещения для которой необходимо обновить, а также имя таблицы, к которой должна быть выполнена привязка. Если необходимо совсем отменить привязку таблицы, следует указать colocate_with => 'no'.
Пример использования:
-
В этом примере показано, что расположение таблицы
Aобновляется как расположение таблицыB:SELECT update_distributed_table_colocation('A', colocate_with => 'B'); -
Предположим, что таблицы
AиBрасположены совместно (возможно, неявно), если необходимо нарушить их расположение:SELECT update_distributed_table_colocation('A', colocate_with => 'none'); -
Теперь предположим, что таблица
A, таблицаB, таблицаCи таблицаDрасположены вместе, и необходимо разместить их по парам - таблицуAи таблицуBвместе, а также таблицуCи таблицуD- вместе:SELECT update_distributed_table_colocation('C', colocate_with => 'none');
SELECT update_distributed_table_colocation('D', colocate_with => 'C'); -
Если есть распределенная по хешу таблица с методом распределения none и необходимо обновить ее расположение, нужно сделать следующее:
SELECT update_distributed_table_colocation('"none"', colocate_with => 'some_other_hash_distributed_table');
create_distributed_function (function_name regprocedure, [ distribution_arg_name text ], [ colocate_with text ]) returns void
Передает функцию от узла-координатора рабочим узлам и помечает ее для распределенного выполнения. Когда на координаторе вызывается распределенная функция, Citus использует значение “аргумента распределения”, чтобы выбрать рабочий узел для выполнения функции. Выполнение функции на рабочих устройствах увеличивает параллелизм и может приблизить код к данным в сегментах для снижения задержек. Обратите внимание, что путь поиска(search_path) в PostgreSQL не передается от координатора к рабочим узлам во время выполнения распределенной функции, поэтому код распределенной функции должен полностью определять имена объектов базы данных. Также уведомления, отправляемые функциями, не будут отображаться пользователю. В качестве аргументов принимаются:
- Имя функции, которая будет распространяться. В скобках должны быть указаны типы параметров функции, поскольку в PostgreSQL несколько функций могут иметь одинаковые имена. Например,
foo(int)отличается отfoo(int, text). - Имя аргумента, по которому будет осуществляться распределение(необязательный параметр). Для удобства (или если у аргументов функции нет имен) допускается использование позиционного заполнителя, такого как
$1. Если этот параметр не указан, то функция с именемfunction_nameпросто создается на рабочих узлах. Если в будущем будут добавлены рабочие узлы, функция будет автоматически создана и там. - Имя таблицы для совместного размещения(необязательный параметр). Когда распределенная функция выполняет чтение или запись в распределенную таблицу (или, в более общем случае, в совместно размещаемые таблицы), обязательно присваивайте имя этой таблицы, используя параметр
colocate_with. Это гарантирует, что каждый вызов функции выполняется на рабочем узле, содержащем соответствующие сегменты.
Пример использования:
-- an example function which updates a hypothetical
-- event_responses table which itself is distributed by event_id
CREATE OR REPLACE FUNCTION
register_for_event(p_event_id int, p_user_id int)
RETURNS void LANGUAGE plpgsql AS $fn$
BEGIN
INSERT INTO event_responses VALUES ($1, $2, 'yes')
ON CONFLICT (event_id, user_id)
DO UPDATE SET response = EXCLUDED.response;
END;
$fn$;
-- distribute the function to workers, using the p_event_id argument
-- to determine which shard each invocation affects, and explicitly
-- colocating with event_responses which the function updates
SELECT create_distributed_function(
'register_for_event(int, int)', 'p_event_id',
colocate_with := 'event_responses'
);
alter_columnar_table_set (table_name regclass, chunk_group_row_limit int, stripe_row_limit int, compression name, compression_level int) returns void
Изменяет настройки таблицы с колоночным типом хранения. При вызове этой функции для таблицы, не содержащей столбцов, возникает ошибка. Все аргументы, кроме имени таблицы, являются необязательными. Чтобы просмотреть текущие параметры для всех колоночных таблиц, обратитесь к таблице columnar.options
Значения по умолчанию для вновь создаваемых колоночных таблиц могут быть переопределены с помощью параметров:
columnar.compression;columnar.compression_level;columnar.stripe_row_count;columnar.chunk_row_count.
На вход функция принимает следующие аргументы:
table_name: Имя столбчатой таблицы;chunk_row_count: (необязательно) Максимальное количество строк в блоке для вновь вставляемых данных. Существующие блоки данных не будут изменены и могут содержать больше строк, чем это максимальное значение. Значение по умолчанию -10000;stripe_row_count: (необязательно) Максимальное количество строк в строке для вновь вставляемых данных. Существующие строки данных не будут изменены и могут содержать больше строк, чем это максимальное значение. Значение по умолчанию равно150000;compression: (необязательно) Возможные значения:[none|pglz|zstd|lz4|lz4hc]. Тип сжатия для вновь вставляемых данных. Существующие данные не будут сжаты или распакованы. Стандартным и обычно рекомендуемым значением являетсяzstd(если поддержка была заявлена при компиляции);compression_level: (необязательно) Допустимые значения - от1до19. Если метод сжатия не поддерживает выбранный уровень, вместо него будет выбран ближайший уровень.
Пример использования:
SELECT alter_columnar_table_set(
'my_columnar_table',
compression => 'none',
stripe_row_count => 10000);
create_time_partitions (table_name regclass, partition_interval interval, end_at timestamptz, start_from timestamptz) returns boolean
Создает разделы с заданным интервалом, чтобы охватить заданный диапазон времени. Входные аргументы:
table_name: таблица (regclass), для которой необходимо создать новые разделы. Таблица должна быть разделена на один столбец типаdate,timestampилиtimestamptz;partition_interval: интервал времени, например2 hoursили1 month, который используется при настройке диапазонов для новых разделов;end_at: (timestamptz) создаст разделы до этого времени. Последний раздел будет содержать точкуend_at, и последующие разделы созданы не будут;start_from: (timestamptz, необязательный параметр) - выберет первый раздел так, чтобы он содержал точкуstart_from. Значение по умолчанию -now().
Функция вернет True, если требовалось создать новые разделы, и False, если все они уже существовали.
Пример использования:
-- create a year's worth of monthly partitions
-- in table foo, starting from the current time
SELECT create_time_partitions(
table_name := 'foo',
partition_interval := '1 month',
end_at := now() + '12 months'
);
drop_old_time_partitions (table_name regclass, older_than timestamptz)
Удаляет все разделы, интервалы между которыми приходятся на заданную временную метку. В дополнение к использованию этой функции можно рассмотреть использование функции alter_old_partitions_set_access_method для сжатия старых разделов с помощью колоночного хранилища. В качестве аргументов принимается:
table_name- имя таблицы, для которой необходимо удалить разделы. Таблица должна быть разделена по одному столбцу типаdate,timestampилиtimestamptz;older_than(timestamptz)- функция удалит разделы, верхний диапазон которых меньше или равен аргументуolder_than.
Пример использования:
-- drop partitions that are over a year old
CALL drop_old_time_partitions('foo', now() - interval '12 months');
alter_old_partitions_set_access_method (parent_table_name regclass, older_than timestamptz, new_access_method name)
В случае использования данных временных рядов таблицы часто разбиваются на разделы по времени, а метод хранения старых разделов меняется на колоночное хранилище, доступное только для чтения, для лучшего сжатия. На вход принимаются аргументы:
parent_table_name: таблица (regclass), для которой требуется изменить разделы. Таблица должна быть разделена по одному столбцу типаdate,timestampилиtimestamptz;older_than: функция изменит разделы, верхний диапазон которых старше или равен значению, переданному в этом аргументе;new_access_method: либоheapдля хранилища на основе строк, либоcolumnarдля колоночного хранилища.
Пример использования:
CALL alter_old_partitions_set_access_method(
'foo', now() - interval '6 months',
'columnar'
);
Конфигурационная информация и метаданные
citus_add_node(nodename text, nodeport integer, groupid integer, noderole noderole, nodecluster name) returns integer
Для работы функции требуются права суперпользователя.
Функция citus_add_node() регистрирует добавление нового узла в кластер в таблице метаданных pg_dist_node. Она также копирует справочные таблицы на добавляемый узел.
При запуске citus_add_node() в кластере с одним узлом, убедитесь, что предварительно была запущена функция citus_set_coordinator_host().
Функция принимает следующие аргументы:
nodename: DNS-имя или IP-адрес нового добавляемого узла;nodeport: порт PostgreSQL на рабочем узле;groupid: Группа из одного основного сервера и дочерних серверов, соответствующая только потоковой репликации. Обязательно установите дляgroupidзначение, большее нуля, поскольку ноль зарезервирован для узла-координатора. Значение по умолчанию равно-1;noderole: является ли он «основным»(primary) или «вторичным»(secondary). Значение по умолчанию -primary;nodecluster: Имя кластера. По умолчанию -default.
В результате работы функция вернет значение nodeid для добавленной в таблицу pg_dist_node строки.
Пример использования:
select * from citus_add_node('new-node', 12345);
citus_add_node
-----------------
7
(1 row)
citus_update_node (node_id int, new_node_name text, new_node_port int, force bool, lock_cooldown int) returns void
Для работы функции требуются права суперпользователя.
Функция citus_update_node() изменяет имя хоста и порт для узла, зарегистрированного в таблице метаданных citus.pg_dist_node. В качестве аргументов на вход функции передаются значение nodeid из таблицы pg_dist_node для сервера, параметры которого изменяются, dns-имя или адрес узла и порт для подключения.
Пример использования:
select * from citus_update_node(123, 'new-address', 5432);
citus_set_node_property (nodename text, nodeport integer, property text, value boolean) returns void
Функция citus_set_node_property() изменяет свойства в таблице метаданных Citus pg_dist_node. В настоящее время она может изменять только свойство shouldhaveshards. На вход принимаются dns-имя или IP-адрес узла, свойства которого меняются, порт для подключения к PostgreSQL, имя свойства в pg_dist_node (в настоящий момент поддерживается только shouldhaveshards) и значение параметра(true или false).
Пример использования:
SELECT * FROM citus_set_node_property('localhost', 5433, 'shouldhaveshards', false);
citus_add_inactive_node (nodename text, nodeport integer, groupid integer, noderole noderole, nodecluster name) returns integer
Для работы функции требуются права суперпользователя.
Функция citus_add_inactive_node() регистрирует добавление нового узла в кластер в таблице метаданных citus.pg_dist_node аналогично тому, как это делает функция citus_add_node, но в отличие от нее данная функция помечает рабочий узел как неактивный, что подразумевает, что на нем не могут быть размещены никакие сегменты. Также не копируются справочные таблицы на добавляемый узел.
Функция принимает следующие аргументы:
nodename: DNS-имя или IP-адрес нового добавляемого узла;nodeport: порт PostgreSQL на рабочем узле;groupid: Группа из одного основного сервера и дочерних серверов, соответствующая только потоковой репликации. Обязательно установите дляgroupidзначение, большее нуля, поскольку ноль зарезервирован для узла-координатора. Значение по умолчанию равно-1;noderole: является ли он «основным»(primary) или «вторичным»(secondary). Значение по умолчанию -primary;nodecluster: Имя кластера. По умолчанию -default.
В результате работы функция вернет значение nodeid для добавленной в таблицу pg_dist_node строки.
Пример использования:
select * from citus_add_inactive_node('new-node', 12345);
citus_add_inactive_node
--------------------------
7
(1 row)
citus_activate_node (nodename text, nodeport integer) returns integer
Для работы функции требуются права суперпользователя.
Помечает рабочий узел как активный в таблице pg_dist_node. Также копирует справочные таблицы на данный узел. На вход функция принимает dns-имя и порт подключения к PostgreSQL для рабочего узла.
В результате работы функция вернет значение nodeid для измененной в таблице pg_dist_node строки.
Пример использования:
select * from citus_activate_node('new-node', 12345);
citus_activate_node
----------------------
7
(1 row)
citus_disable_node (nodename text, nodeport integer, synchronous bool) returns void
Для работы функции требуются права суперпользователя.
Функция citus_disable_node является противоположностью функции citus_activate_node. Она помечает узел как неактивный в таблице метаданных Citus pg_dist_node, временно удаляя его из кластера. Функция также удаляет все справочные таблицы с отключенного узла. Чтобы повторно активировать узел, просто запустите citus_activate_node еще раз. В качестве аргументов функция принимает dns-имя и порт подключения к PostgreSQL для рабочего узла.
Пример использования:
select * from citus_disable_node('new-node', 12345);
citus_add_secondary_node (nodename text, nodeport integer, primaryname text, primaryport integer, nodecluster name) returns integer
Для работы функции требуются права суперпользователя.
Функция citus_add_secondary_node() регистрирует новый дочерний узел в кластере для существующего основного узла. Она обновляет таблицу метаданных Citus pg_dist_node. Функция принимает на вход следующие аргументы:
nodename: DNS-имя или IP-адрес нового добавляемого дочернего узла;nodeport: порт PostgreSQL на дочернем рабочем узле;primaryname: DNS-имя или IP-адрес основного узла;primaryport: порт PostgreSQL на основном узле;nodecluster: Имя кластера. По умолчанию -default.
В результате работы функция вернет значение nodeid для добавленной в таблицу pg_dist_node строки.
Пример использования:
select * from citus_add_secondary_node('new-node', 12345, 'primary-node', 12345);
citus_add_secondary_node
---------------------------
7
(1 row)
citus_remove_node (nodename text, nodeport integer) returns void
Для работы функции требуются права суперпользователя.
Функция citus_remove_node() удаляет указанный узел из таблицы метаданных pg_dist_node. Эта функция выдаст ошибку, если на этом узле существуют сегменты объектов кластера Citus. Таким образом, прежде чем использовать эту функцию, сегменты должны быть удалены с этого узла. На вход функция принимает dns-имя и порт подключения к PostgreSQL для удаляемого рабочего узла.
Пример использования:
select citus_remove_node('new-node', 12345);
citus_remove_node
--------------------
(1 row)
citus_get_active_worker_nodes () returns setof record
Функция citus_get_active_worker_nodes() возвращает список имен активных рабочих узлов и номеров портов. В результате работы функция вернет представление с именами и портами активных рабочих узлов.
Пример использования:
SELECT * from citus_get_active_worker_nodes();
node_name | node_port
-----------+-----------
localhost | 9700
localhost | 9702
localhost | 9701
(3 rows)
citus_backend_gpid () returns bigint
Функция citus_backend_gpid() возвращает глобальный идентификатор процесса (PID) для серверной части PostgreSQL, обслуживающей текущий сеанс. GPID кодируется как nodeid узла в кластере Citus, и идентификатор процесса операционной системы(PID) PostgreSQL на этом узле. Citus расширяет функции сервера PostgreSQL pg_cancel_backend() и pg_terminate_backend(), чтобы они принимали идентификаторы GPID. В Citus вызов этих функций на одном узле может повлиять на серверную часть, работающую на другом узле. В результате работы функция вернет GPID, который вычисляется по следующей формуле - (NodeId * 10,000,000,000) + ProcessId
Пример использования:
SELECT citus_backend_gpid();
citus_backend_gpid
--------------------
10000002055
citus_check_cluster_node_health () returns setof record
Проверяет соединение между всеми узлами. Если в кластере N узлов, будет проверено все N^2 соединений между ними. Возвращает список записей, в котором есть DNS-имя исходного рабочего узла, порт PostgreSQL на исходном рабочем узле, DNS-имя конечного рабочего узла, порт на целевом рабочем узле, удалось ли установить соединение.
Пример использования:
SELECT * FROM citus_check_cluster_node_health();
from_nodename │ from_nodeport │ to_nodename │ to_nodeport │ result
---------------+---------------+-------------+-------------+--------
localhost | 1400 | localhost | 1400 | t
localhost | 1400 | localhost | 1401 | t
localhost | 1400 | localhost | 1402 | t
localhost | 1401 | localhost | 1400 | t
localhost | 1401 | localhost | 1401 | t
localhost | 1401 | localhost | 1402 | t
localhost | 1402 | localhost | 1400 | t
localhost | 1402 | localhost | 1401 | t
localhost | 1402 | localhost | 1402 | t
(9 rows)
citus_set_coordinator_host (host text, port integer, node_role noderole, node_cluster name) returns void
Эта функция необходима при добавлении рабочих узлов в кластер Citus, который изначально был создан как одноузловой кластер. Когда координатор регистрирует новый узел, он добавляет имя хоста координатора из значения citus.local_hostname(text), которое по умолчанию имеет значение localhost. Рабочий узел будет пытаться подключиться к localhost, чтобы соединиться с координатором, что, очевидно, неверно. Таким образом, системный администратор должен вызвать citus_set_coordinator_host перед вызовом citus_add_node. Функция принмает следующие аргументы:
host: DNS-имя узла-координатора;port: (необязательный параметр) Порт PostgreSQL на координаторе. По умолчанию используется значениеcurrent_setting("порт");node_role: (необязательный параметр) По умолчанию используется значениеprimary;node_cluster: (необязательный параметр) По умолчанию используется значениеdefault.
Пример использования:
-- assuming we're in a single-node cluster
-- first establish how workers should reach us
SELECT citus_set_coordinator_host('coord.example.com', 5432);
-- then add a worker
SELECT * FROM citus_add_node('worker1.example.com', 5432);
master_get_table_metadata(table_name regclass) returns setof record
Возвращает метаданные, связанные с распределением, для распределенной таблицы. Эти метаданные включают идентификатор связи, тип хранилища, метод распространения, столбец распространения, количество репликаций (не рекомендуется), максимальный размер сегмента и политику размещения сегментов для этой таблицы. По сути, эта функция запрашивает таблицы метаданных Citus, чтобы получить необходимую информацию, и объединяет ее в кортеж, прежде чем вернуть пользователю. На вход функция принимает имя таблицы, метаданные для которой нужно получить. На выходе получается представление, в котором содержаться поля:
logical_relid: идентификатор(oid) распределенной таблицы. Это значение отсылает к столбцуrelfilenodeв таблице системного каталогаpg_class;part_storage_type: Тип хранилища, используемого для таблицы. Может бытьt(стандартная таблица),f(внешняя таблица) илиc(столбчатая таблица);part_method: Метод распределения, используемый для таблицы. Должно бытьh(хеш);part_key: столбец распределения для таблицы;part_replica_count: Текущее количество репликаций сегментов (устарело);part_max_size: Текущий максимальный размер сегмента в байтах;part_placement_policy: Политика размещения сегментов, используемая для размещения сегментов таблицы. Может быть1(local-node-first) или2(round-robin).
Пример использования:
SELECT * from master_get_table_metadata('github_events');
logical_relid | part_storage_type | part_method | part_key | part_replica_count | part_max_size | part_placement_policy
---------------+-------------------+-------------+----------+--------------------+---------------+-----------------------
24180 | t | h | repo_id | 1 | 1073741824 | 2
(1 row)
get_shard_id_for_distribution_column (table_name regclass, distribution_value "any") returns bigint
Citus присваивает каждой строке распределенной таблицы сегмент на основе значения столбца распределения строки и метода распределения таблицы. В большинстве случаев точное сопоставление является детализацией низкого уровня, которую администратор базы данных может проигнорировать. Однако может оказаться полезным определить сегмент строки, либо для выполнения задач обслуживания базы данных вручную, либо просто для удовлетворения любопытства. Функция get_shard_id_for_distribution_column предоставляет эту информацию для таблиц с распределением по хешу, а также для справочных таблиц. В качестве аргументов функция принимает имя таблицы и значение столбца распределения. В результате работы функция возвращает идентификатор сегмента Citus, в котором хранятся строки по заданному значению.
Пример использования:
SELECT get_shard_id_for_distribution_column('my_table', 4);
get_shard_id_for_distribution_column
--------------------------------------
540007
(1 row)
column_to_column_name (table_name regclass, column_var_text text) returns text
Преобразует столбец partkey в pg_dist_partition в текстовое имя столбца. Это полезно для определения столбца распределения в распределенной таблице. На вход функция принимает имя распределенной таблицы и значение параметра partkey в таблице pg_dist_partition. На выходе функция возвращает текстовое имя столбца.
Пример использования:
-- get distribution column name for products table
SELECT column_to_column_name(logicalrelid, partkey) AS dist_col_name
FROM pg_dist_partition
WHERE logicalrelid='products'::regclass;
┌───────────────┐
│ dist_col_name │
├───────────────┤
│ company_id │
└───────────────┘
citus_relation_size (logicalrelid regclass) returns bigint
Возвращает информацию о пространстве на диске, используемом всеми сегментами указанной распределенной таблицы. Включает размер “основного раздела”, но не включает карту видимости и карту свободного пространства для сегментов. На вход принимает имя распределенной таблицы.
Пример использования:
SELECT pg_size_pretty(citus_relation_size('github_events'));
pg_size_pretty
--------------
23 MB
citus_table_size (logicalrelid regclass) returns bigint
Возвращает информацию о пространстве на диске, используемом всеми сегментами указанной распределенной таблицы, исключая индексы (но включая TOAST, карту свободного пространства и карту видимости). На вход принимает имя распределенной таблицы.
Пример использования:
SELECT pg_size_pretty(citus_table_size('github_events'));
pg_size_pretty
--------------
37 MB
citus_total_relation_size (logicalrelid regclass) returns bigint
Возвращает информацию о пространстве на диске, используемом всеми сегментами указанной распределенной таблицы, включая все индексы и TOAST. На вход принимает имя распределенной таблицы.
Пример использования:
SELECT pg_size_pretty(citus_total_relation_size('github_events'));
pg_size_pretty
--------------
73 MB
citus_stat_statements_reset () returns void
Удаляет все строки из citus_stat_statements. Обратите внимание, что эта функция работает независимо от pg_stat_statements_reset(). Чтобы сбросить все статистические данные, вызовите обе функции.
Пример использования:
SELECT citus_stat_statements_reset();
Функции управления кластером и восстановления
citus_move_shard_placement (shard_id bigint, source_node_name text, source_node_port integer, target_node_name text, target_node_port integer, shard_transfer_mode citus.shard_transfer_mode) returns void
Эта функция перемещает указанный сегмент (и совместно расположенные рядом с ним сегменты) с одного узла на другой. Обычно она используется косвенно во время ребалансировки сегмента, а не вызывается администратором базы данных напрямую. Существует два способа перемещения данных: блокирующий или неблокирующий. Блокирующий подход означает, что во время перемещения все изменения в сегменте приостанавливаются. Второй способ, который позволяет избежать блокировки записи в сегмент, основан на логической репликации Postgres 10+. После успешной операции перемещения сегменты в исходном узле удаляются. Если в какой-либо момент перемещение завершается неудачей, эта функция выдает ошибку и оставляет исходный и целевой узлы без изменений.
Аргументы функции:
-
shard_id: идентификатор сегмента, который необходимо переместить; -
source_node_name: DNS-имя узла, на котором находится рабочий в настоящий момент сегмент (узел «источник»); -
source_node_port: порт PostgreSQL на исходном рабочем узле; -
target_node_name: DNS-имя узла, на который будет перемещаться сегмент («целевой» узел); -
target_node_port: порт PostgreSQL на целевом рабочем узле; -
shard_transfer_mode: (Необязательно) Метод репликации, следует ли использовать логическую репликацию PostgreSQL или командуCOPYмежду рабочими узлами. Возможны следующие значения:auto: Требуется идентификатор реплики, если возможна логическая репликация, в противном случае используется ранее принятое поведение. Это значение по умолчанию;force_logical: Использовать логическую репликацию, даже если таблица не имеет идентификатора реплики. Любые инструкции по обновлению/удалению таблицы не будут выполняться во время репликации;block_writes: Использовать функциюCOPY(блокирует операции записи) для таблиц, в которых отсутствует первичный ключ или идентификатор реплики.
Пример использования:
SELECT citus_move_shard_placement(12345, 'from_host', 5432, 'to_host', 5432);
citus_rebalance_start (rebalance_strategy name, drain_only boolean, shard_transfer_mode citus.shard_transfer_mode) returns bigint
Функция citus_rebalance_start() перемещает сегменты таблицы, чтобы они были равномерно распределены между рабочими узлами. Она запускает фоновое задание для восстановления баланса и немедленно завершается. Процесс ребалансировки сначала вычисляет список перемещений, которые необходимо выполнить, чтобы обеспечить балансировку кластера в пределах заданного порога. Затем он перемещает места размещения сегментов одно за другим с исходного узла на целевой узел и обновляет соответствующие метаданные сегментов, чтобы отразить перемещение. Каждому сегменту присваивается стоимость при определении того, равномерно ли распределены сегменты. По умолчанию каждый сегмент имеет одинаковую стоимость (значение равно 1), поэтому распределение для выравнивания стоимости между рабочими узлами аналогично выравниванию количества сегментов на каждом. Стратегия ребалансировки, опирающейся на постоянную стоимость называется by_shard_count и является стратегией ребалансировки по умолчанию. Стратегия by_shard_count подходит в следующих случаях:
- сегменты примерно одинакового размера;
- сегменты получают примерно одинаковый объем трафика;
- все рабочие узлы имеют одинаковый размер/тип;
- сегменты не были привязаны к конкретным рабочим узлам.
Если какое-либо из этих предположений не выполняется, то ребалансировка by_shard_count может привести к неправильному плану. По умолчанию используется стратегия ребалансировки by_disk_size. Всегда можно настроить стратегию, используя параметр rebalance_strategy. Рекомендуется вызвать get_rebalance_table_shards_plan перед запуском citus_rebalance_start, чтобы увидеть и проверить, какие действия необходимо выполнить.
Входные аргументы:
-
rebalance_strategy: (необязательно) название стратегии в таблице стратегий ребалансировкиpg_dist_rebalance_strategy. Если этот аргумент опущен, функция выбирает стратегию по умолчанию, как указано в таблице; -
drain_only: (необязательно) При значенииtrueпереместите сегменты рабочих узлов, для которых в таблице рабочих узлов должно быть установлено значениеfalse; другие сегменты не перемещать; -
shard_transfer_mode: (необязательно) указать метод репликации - логическая репликация или командаCOPY. Этот аргумент может принимать следующие значения:auto: требовать идентификатор реплики, если возможна логическая репликация, в противном случае использовать ранее принятое поведение. Это значение по умолчанию;force_logical: использовать логическую репликацию, даже если таблица не имеет идентификатора реплики. Любые одновременные операторы изменения/удаления таблицы во время репликации завершатся ошибкой;block_writes: использовать командуCOPY(блокирующую запись) для таблиц, у которых нет первичного ключа или идентификатора реплики.
Пример использования:
SELECT citus_rebalance_start();
NOTICE: Scheduling...
NOTICE: Scheduled as job 1337.
DETAIL: Rebalance scheduled as background job 1337.
HINT: To monitor progress, run: SELECT details FROM citus_rebalance_status();
citus_rebalance_status () returns table
отслеживать ход выполнения балансировки, запущенной функцией citus_rebalance_start().
Пример использования:
-- all columns
SELECT * FROM citus_rebalance_status();
.
job_id | state | job_type | description | started_at | finished_at | details
--------+----------+-----------+---------------------------------+-------------------------------+-------------------------------+-----------
4 | running | rebalance | Rebalance colocation group 1 | 2022-08-09 21:57:27.833055+02 | 2022-08-09 21:57:27.833055+02 | { ... }
-- for details
SELECT details FROM citus_rebalance_status();
{
"phase": "copy",
"phase_index": 1,
"phase_count": 3,
"last_change":"2022-08-09 21:57:27",
"colocations": {
"1": {
"shard_moves": 30,
"shard_moved": 29,
"last_move":"2022-08-09 21:57:27"
},
"1337": {
"shard_moves": 130,
"shard_moved": 0
}
}
}
citus_rebalance_stop() returns void
Эта функция отменяет выполняемую ребалансировку, если таковая запущена.
Пример использования:
select citus_rebalance_stop();
citus_rebalance_wait() returns void
Эта функция блокируется(зависает) до завершения текущей ребалансировки. Если при вызове функции citus_rebalance_wait() отсутствует запущенная ребалансировка, функция немедленно завершается. Функция может быть полезна для сценариев НТ или сравнительного анализа.
Пример использования:
select citus_rebalance_wait();
get_rebalance_table_shards_plan(relation regclass, threshold float4, max_shard_moves int, excluded_shard_list bigint[], drain_only boolean, rebalance_strategy name)returns table
Вывести осуществляемые функцией citus_rebalance_start перемещения фрагментов, не выполняя их. Нужно учитывать, что хоть это и маловероятно, get_rebalance_table_shards_plan может выдать план, немного отличающийся от того, что будет делать вызов citus_rebalance_start с теми же аргументами. Это может произойти из–за того, что они выполняются не одновременно, поэтому данные о кластере – например, объем дискового пространства - могут отличаться между вызовами. На вход функция принимает расширенные аргументы функции citus_rebalance_start():
relation regclass;threshold float4;max_shard_moves int;excluded_shard_list bigint[];drain_only boolean;rebalance_strategy name.
В результате работы функция вернет таблицу состоящую из следующих столбцов:
table_name: Таблица, сегменты которой будут перемещены;shard: Соответствующий сегмент;shard_size: Размер в байтах;sourcename: Имя узла-источника;sourceport: Порт узла-источника;targetname: Имя узла-получателя;targetport: порт узла-получателя.
get_rebalance_progress() returns table
Как только начинается ребалансировка сегмента, функция get_rebalance_progress() отображает прогресс каждого задействованного сегмента. Она отслеживает действия, запланированные и выполненные функцией citus_rebalance_start(). Похожа на функцию citus_rebalance_status(), но возможно последняя будет проще для восприятия. В результате работы функция вернет представление из следующих полей:
sessionid: Postgres PID монитора восстановления баланса;tablename: таблица, сегменты которой перемещаются;shardid: Соответствующий сегмент;shard_size: Размер сегмента в байтах;sourcename: Имя узла-источника;sourceport: Порт исходного узла;targetname: Имя хоста конечного узла;targetport: порт конечного узла;progress:0= ожидание перемещения;1= перемещение;2= завершено;source_shard_size: Размер сегмента на исходном узле в байтах;target_shard_size: Размер сегмента на целевом узле в байтах.
Пример использования:
SELECT * FROM get_rebalance_progress();
┌───────────┬────────────┬─────────┬────────────┬───────────────┬────────────┬───────────────┬────────────┬──────────┬───────────────────┬───────────────────┐
│ sessionid │ table_name │ shardid │ shard_size │ sourcename │ sourceport │ targetname │ targetport │ progress │ source_shard_size │ target_shard_size │
├───────────┼────────────┼─────────┼────────────┼───────────────┼────────────┼───────────────┼────────────┼──────────┼───────────────────┼───────────────────┤
│ 7083 │ foo │ 102008 │ 1204224 │ n1.foobar.com │ 5432 │ n4.foobar.com │ 5432 │ 0 │ 1204224 │ 0 │
│ 7083 │ foo │ 102009 │ 1802240 │ n1.foobar.com │ 5432 │ n4.foobar.com │ 5432 │ 0 │ 1802240 │ 0 │
│ 7083 │ foo │ 102018 │ 614400 │ n2.foobar.com │ 5432 │ n4.foobar.com │ 5432 │ 1 │ 614400 │ 354400 │
│ 7083 │ foo │ 102019 │ 8192 │ n3.foobar.com │ 5432 │ n4.foobar.com │ 5432 │ 2 │ 0 │ 8192 │
└───────────┴────────────┴─────────┴────────────┴───────────────┴────────────┴───────────────┴────────────┴──────────┴───────────────────┴───────────────────┘
citus_add_rebalance_strategy (name name, shard_cost_function regproc, node_capacity_function regproc, shard_allowed_on_node_function regproc, default_threshold float4, minimum_threshold float4, improvement_threshold float4) returns void
Добавляет строку к таблице pg_dist_rebalance_strategy
Входные аргументы:
name: идентификатор новой стратегии;shard_cost_function: определяет функцию, используемую для определения «стоимости» каждого сегмента;node_capacity_function: определяет функцию для измерения пропускной способности узла;shard_allowed_on_node_function: определяет функцию, которая определяет, какие сегменты могут быть размещены на каких узлах;default_threshold: порог с плавающей точкой, который определяет, насколько точно должна быть сбалансирована совокупная стоимость сегментов между узлами;minimum_threshold: (необязательно) защитный столбец, содержащий минимальное значение, допустимое для порогового аргументаcitus_rebalance_start(). Его значение по умолчанию равно0.
citus_set_default_rebalance_strategy (name text) returns void
Устанавливает стратегию по умолчанию в таблице стратегий ребалансировки. В качестве аргумента передается имя функции для установки по умолчанию.
Пример использования:
SELECT citus_set_default_rebalance_strategy('by_disk_size');
citus_remote_connection_stats () returns setof record
Показывает количество активных подключений к каждому удаленному узлу.
Пример использования:
SELECT * from citus_remote_connection_stats();
hostname | port | database_name | connection_count_to_node
----------------+------+---------------+--------------------------
citus_worker_1 | 5432 | postgres | 3
(1 row)
citus_drain_node (nodename text, nodeport integer, shard_transfer_mode citus.shard_transfer_mode, rebalance_strategy name) returns void
Перемещает сегменты с указанного узла на другие узлы, для которых в таблице рабочих узлов должно быть установлено значение true для сегментов. Эта функция предназначена для вызова перед удалением узла из кластера, т.е. отключением физического сервера узла.
Входные аргументы:
-
nodename: имя или адрес узла; -
nodeport: порт PostgreSQL; -
shard_transfer_mode: (необязательно) указать метод репликации - логическая репликация или командаCOPY. Этот аргумент может принимать следующие значения:auto: требовать идентификатор реплики, если возможна логическая репликация, в противном случае использовать ранее принятое поведение. Это значение по умолчанию;force_logical: использовать логическую репликацию, даже если таблица не имеет идентификатора реплики. Любые одновременные операторы изменения/удаления таблицы во время репликации завершатся ошибкой;block_writes: использовать командуCOPY(блокирующую запись) для таблиц, у которых нет первичного ключа или идентификатора реплики;
-
rebalance_strategy: Стратегия ребалансировки(из таблицы стратегий).
Пример использования:
Вот типичные шаги для удаления отдельного узла:
-
Очистите узел.
SELECT * FROM citus_drain_node('<IP-адрес>', 5432); -
Дождитесь завершения команды.
-
Удалите узел.
При удалении нескольких узлов рекомендуется использовать citus_rebalance_start вместо этого. Это позволит Citus планировать заранее и перемещать сегменты минимальное количество раз:
-
Выполните это для каждого узла, который необходимо удалить:
SELECT * FROM citus_set_node_property(node_hostname, node_port, 'shouldhaveshards', false); -
Очистите их все сразу с помощью
citus_rebalance_start:SELECT * FROM citus_rebalance_start(drain_only := true); -
Дождитесь завершения ребалансировки.
-
Удалите узлы.
isolate_tenant_to_new_shard (table_name regclass, tenant_id "any", cascade_option text, shard_transfer_mode citus.shard_transfer_mode) returns bigint
Создает новый сегмент для хранения строк с определенным значением в столбце распределения. Это особенно удобно в случае использования Citus с несколькими арендаторами, когда крупный клиент может быть размещен отдельно на своем собственном сегменте и, в конечном счете, на своем собственном физическом узле.
Аргументы:
-
table_name: имя таблицы для получения нового сегмента; -
tenant_id: Значение столбца распределения, которое будет присвоено новому сегменту; -
cascade_option: (необязательно) Если установлено значениеCASCADE, также изолируются сегменты всех таблиц связанных с текущей таблицей в таблице совместного размещения; -
shard_transfer_mode: (необязательно) указать метод репликации - логическая репликация или командаCOPY. Этот аргумент может принимать следующие значения:auto: требовать идентификатор реплики, если возможна логическая репликация, в противном случае использовать ранее принятое поведение. Это значение по умолчанию;force_logical: использовать логическую репликацию, даже если таблица не имеет идентификатора реплики. Любые одновременные операторы изменения/удаления таблицы во время репликации завершатся ошибкой;block_writes: использовать командуCOPY(блокирующую запись) для таблиц, у которых нет первичного ключа или идентификатора реплики.
Пример использования:
SELECT isolate_tenant_to_new_shard('lineitem', 135);
┌─────────────────────────────┐
│ isolate_tenant_to_new_shard │
├─────────────────────────────┤
│ 102240 │
└─────────────────────────────┘
citus_create_restore_point (name text) returns pg_lsn
Временно блокирует запись в кластер и создает именованную точку восстановления на всех узлах. Эта функция аналогична функции pg_create_restore_point, но применяется ко всем узлам и обеспечивает согласованность точки восстановления на всех узлах. Эта функция хорошо подходит для оперативного восстановления и разветвления кластера. В качестве аргумента функция принимает имя точки восстановления. В результате своей работы функция вернет lsn в файле WAL узла координатора.
Пример использования:
select citus_create_restore_point('foo');
┌────────────────────────────┐
│ citus_create_restore_point │
├────────────────────────────┤
│ 0/1EA2808 │
└────────────────────────────┘
Описание таблиц и представлений
Метаданные координатора
Citus делит каждую распределенную таблицу на несколько логических сегментов на основе столбца распределения. Затем координатор поддерживает таблицы метаданных для отслеживания статистики и информации о работоспособности и местоположении этих сегментов. В этом разделе описывается каждая из этих таблиц метаданных и их схему. Эти таблицы можно проматривать с помощью SQL после входа в узел-координатор.
pg_dist_partition
Таблица pg_dist_partition хранит метаданные о том, какие таблицы в базе данных являются распределенными. Для каждой распределенной таблицы в ней также хранится информация о методе распределения и подробная информация о столбце распределения.
| Имя | Тип | Описание |
|---|---|---|
logicalrelid | regclass | Распределенная таблица, которой соответствует эта строка. Это значение ссылается на столбец relfilenode в таблице системного каталога pg_class |
partmethod | char | Метод, используемый для разделения/распределения. Значения этого столбца, соответствующие различным методам распределения, следующие: хеш: hсправочная таблица: n |
partkey | text | Подробная информация о столбце распределения, включая номер столбца, его тип и другую соответствующую информацию |
colocationid | integer | Группа совместного размещения, к которой принадлежит эта таблица. Таблицы в одной группе позволяют совместно размещать объединения и распределять сводные данные среди других оптимизаций. Это значение ссылается на столбец идентификатора colocation в таблице pg_dist_colocation |
repmodel | char | Метод, используемый для репликации данных. Значения этого столбца соответствуют различным методам репликации : потоковая репликация PostgreSQL: sдвухэтапная фиксация (для справочных таблиц): t |
Пример:
SELECT * from pg_dist_partition;
logicalrelid | partmethod | partkey | colocationid | repmodel
---------------+------------+------------------------------------------------------------------------------------------------------------------------+--------------+----------
github_events | h | {VAR :varno 1 :varattno 4 :vartype 20 :vartypmod -1 :varcollid 0 :varlevelsup 0 :varnoold 1 :varoattno 4 :location -1} | 2 | s
(1 row)
pg_dist_shard
Таблица pg_dist_shard хранит метаданные об отдельных сегментах таблицы. Это включает информацию о том, к какой распределенной таблице принадлежит сегмент, и статистические данные о столбце распределения для этого сегмента. В случае таблиц с распределенным хешем это диапазоны токенов хеша, назначенные этому сегменту. Эти статистические данные используются для удаления несвязанных фрагментов во время запросов SELECT.
| Имя | Тип | Описание |
|---|---|---|
logicalrelid | regclass | Распределенная таблица, которой соответствует эта строка. Это значение ссылается на столбец relfilenode в таблице системного каталога pg_class |
shardid | bigint | Глобальный уникальный идентификатор присвоенный сегменту |
shardstorage | char | Тип хранилища используемый сегментом |
shardminvalue | text | Для таблиц, распределенных по хешу, минимальное значение токена хеша присвоенное сегменту (включительно) |
shardmaxvalue | text | Для таблиц, распределенных по хешу, максимальное значение токена хеша присвоенное сегменту (включительно) |
Столбец shardstorage в pg_dist_shared указывает тип хранилища, используемого для сегмента. Ниже приведен краткий обзор различных типов общего хранилища и их представление.
| Тип хранилища | Значение поля shardstorage | Описание |
|---|---|---|
TABLE | t | Указывает, что сегмент хранит данные, принадлежащие обычной распределенной таблице. |
COLUMNAR | c | Указывает, что сегмент хранит колоночные данные. (Используется распределенными таблицами cstore_fdw) |
FOREIGN | f | Указывает, что сегмент хранит внешние данные. (Используется распределенными таблицами file_fdw) |
Пример:
SELECT * from pg_dist_shard;
logicalrelid | shardid | shardstorage | shardminvalue | shardmaxvalue
---------------+---------+--------------+---------------+---------------
github_events | 102026 | t | 268435456 | 402653183
github_events | 102027 | t | 402653184 | 536870911
github_events | 102028 | t | 536870912 | 671088639
github_events | 102029 | t | 671088640 | 805306367
(4 rows)
citus_shards
В дополнение к таблице метаданных сегмента низкого уровня, описанной выше, Citus предоставляет представление citus_shards, позволяющее легко проверить:
- где находится каждый сегмент (узел и порт);
- к какому типу таблицы он принадлежит;
- его размер.
Это представление помогает проверять сегменты, чтобы, помимо прочего, обнаружить любые несоответствия в размерах узлов.
Пример:
SELECT * FROM citus_shards;
table_name | shardid | shard_name | citus_table_type | colocation_id | nodename | nodeport | shard_size
------------+---------+--------------+------------------+---------------+-----------+----------+------------
dist | 102170 | dist_102170 | distributed | 34 | localhost | 9701 | 90677248
dist | 102171 | dist_102171 | distributed | 34 | localhost | 9702 | 90619904
dist | 102172 | dist_102172 | distributed | 34 | localhost | 9701 | 90701824
dist | 102173 | dist_102173 | distributed | 34 | localhost | 9702 | 90693632
ref | 102174 | ref_102174 | reference | 2 | localhost | 9701 | 8192
ref | 102174 | ref_102174 | reference | 2 | localhost | 9702 | 8192
dist2 | 102175 | dist2_102175 | distributed | 34 | localhost | 9701 | 933888
dist2 | 102176 | dist2_102176 | distributed | 34 | localhost | 9702 | 950272
dist2 | 102177 | dist2_102177 | distributed | 34 | localhost | 9701 | 942080
dist2 | 102178 | dist2_102178 | distributed | 34 | localhost | 9702 | 933888
Поле colocation_id ссылается на группу совместного размещения.
pg_dist_placement
Таблица pg_dist_placement отслеживает расположение сегментов на рабочих узлах. Соответствие сегмента определенному узлу называется размещением сегмента. В этой таблице хранится информация о работоспособности и местоположении каждого сегмента.
| Имя | Тип | Описание |
|---|---|---|
placementid | bigint | Уникальный автоматически сгенерированный идентификатор для каждого отдельного места размещения |
shardid | bigint | Идентификатор сегмента, связанный с этим размещением. Это значение ссылается на столбец shardid в таблице каталога pg_dist_shared |
shardstate | int | Описывает состояние этого размещения. Различные состояния сегмента обсуждаются в разделе ниже |
shardlength | bigint | Для таблиц распределенных по хешу здесь будет ноль |
groupid | int | Идентификатор, используемый для обозначения группы из одного основного сервера и нуля или более дополнительных серверов |
SELECT * from pg_dist_placement;
placementid | shardid | shardstate | shardlength | groupid
-------------+---------+------------+-------------+---------
1 | 102008 | 1 | 0 | 1
2 | 102008 | 1 | 0 | 2
3 | 102009 | 1 | 0 | 2
4 | 102009 | 1 | 0 | 3
5 | 102010 | 1 | 0 | 3
6 | 102010 | 1 | 0 | 4
7 | 102011 | 1 | 0 | 4
Начиная с Citus 7.0, аналогичная таблица pg_dist_shard_placement устарела. Она включала имя узла и порт для каждого размещения:
SELECT * from pg_dist_shard_placement;
shardid | shardstate | shardlength | nodename | nodeport | placementid
---------+------------+-------------+-----------+----------+-------------
102008 | 1 | 0 | localhost | 12345 | 1
102008 | 1 | 0 | localhost | 12346 | 2
102009 | 1 | 0 | localhost | 12346 | 3
102009 | 1 | 0 | localhost | 12347 | 4
102010 | 1 | 0 | localhost | 12347 | 5
102010 | 1 | 0 | localhost | 12345 | 6
102011 | 1 | 0 | localhost | 12345 | 7
Теперь эта информация доступна путем объединения pg_dist_placement с pg_dist_node по полю groupid. Для обеспечения совместимости Citus по-прежнему предоставляет pg_dist_shard_placement в качестве представления. Однако рекомендуется, по возможности, использовать новые, более нормализованные таблицы.
pg_dist_node
Таблица pg_dist_node содержит информацию о рабочих узлах в кластере.
| Имя | Тип | Описание |
|---|---|---|
nodeid | int | Автоматически сгенерированный идентификатор узла |
groupid | int | Идентификатор, используемый для обозначения группы из одного основного сервера и нуля или более дополнительных серверов. По умолчанию он совпадает с идентификатором узла |
nodename | text | DNS-имя или IP-адрес рабочего узла |
nodeport | int | Порт PostgreSQL рабочего узла |
noderack | text | (Необязательно) Информация о размещении стойки для рабочего узла |
hasmetadata | boolean | Зарезервированое для внутреннего использования поле |
isactive | boolean | Активен ли узел, принимающий размещения сегментов |
noderole | text | Является ли узел первичным или вторичным |
nodecluster | text | Имя кластера, в который входит данный узел |
metadatasynced | boolean | Зарезервированое для внутреннего использования поле |
shouldhaveshards | boolean | Если значение равно false, сегменты будут перемещены с узла (удалены) при ребалансировке, и сегменты из новых распределенных таблиц не будут размещены на узле, если только они не будут размещены совместно с уже существующими сегментами |
Пример:
SELECT * from pg_dist_node;
nodeid | groupid | nodename | nodeport | noderack | hasmetadata | isactive | noderole | nodecluster | metadatasynced | shouldhaveshards
--------+---------+-----------+----------+----------+-------------+----------+----------+-------------+----------------+------------------
1 | 1 | localhost | 12345 | default | f | t | primary | default | f | t
2 | 2 | localhost | 12346 | default | f | t | primary | default | f | t
3 | 3 | localhost | 12347 | default | f | t | primary | default | f | t
(3 rows)
pg_dist_object
Таблица citus.pg_dist_object содержит список объектов, таких как типы и функции, которые были созданы на узле-координаторе и распространены на рабочие узлы. Когда администратор добавляет в кластер новые рабочие узлы, Citus автоматически создает копии распределенных объектов на новых узлах (в правильном порядке для удовлетворения зависимостей объектов).
| Имя | Тип | Описание |
|---|---|---|
classid | oid | Класс распределенного объекта |
objid | oid | OID распределенного объекта |
objsubid | integer | Идентификатор вложенного объекта распределенного объекта, например, attnum |
type | text | Часть стабильного адреса, используемого при обновлении pg_upgrade |
object_names | text[] | Часть стабильного адреса, используемого при обновлении pg_upgrade |
object_args | text[] | Часть стабильного адреса, используемого при обновлении pg_upgrade |
distribution_argument_index | integer | Только для распределенных функций или процедур |
colocationid | integer | Только для распределенных функций или процедур |
«Стабильные адреса» в таблице выше однозначно идентифицируют объекты независимо от конкретного сервера. Citus отслеживает объекты во время обновления PostgreSQL, используя стабильные адреса, созданные с помощью функции pg_identify_object_as_address(). Вот пример того, как функция create_distributed_function() добавляет записи в таблицу citus.pg_dist_object:
CREATE TYPE stoplight AS enum ('green', 'yellow', 'red');
CREATE OR REPLACE FUNCTION intersection()
RETURNS stoplight AS $$
DECLARE
color stoplight;
BEGIN
SELECT *
FROM unnest(enum_range(NULL::stoplight)) INTO color
ORDER BY random() LIMIT 1;
RETURN color;
END;
$$ LANGUAGE plpgsql VOLATILE;
SELECT create_distributed_function('intersection()');
-- will have two rows, one for the TYPE and one for the FUNCTION
TABLE citus.pg_dist_object;
-[ RECORD 1 ]---------------+------
classid | 1247
objid | 16780
objsubid | 0
type |
object_names |
object_args |
distribution_argument_index |
colocationid |
-[ RECORD 2 ]---------------+------
classid | 1255
objid | 16788
objsubid | 0
type |
object_names |
object_args |
distribution_argument_index |
colocationid |
citus_schemas
В Citus 12.0 появилась концепция сегментирования на основе схем, а вместе с ней и представление citus_schemas, которое показывает, какие схемы были распространены в системе. В представлении отображаются только распределенные схемы, локальные схемы не отображаются.
| Имя | Тип | Описание |
|---|---|---|
schema_name | regnamespace | Имя распределенной схемы |
colocation_id | integer | Идентификатор совместного размещения распределенной схемы |
schema_size | text | Сводная информация о размерах всех объектов в схеме, доступная для чтения человеком |
schema_owner | name | Роль-владелец схемы |
Пример:
schema_name | colocation_id | schema_size | schema_owner
--------------+---------------+-------------+--------------
user_service | 1 | 0 bytes | user_service
time_service | 2 | 0 bytes | time_service
ping_service | 3 | 632 kB | ping_service
citus_tables
В представлении citus_tables отображается сводная информация обо всех таблицах, управляемых Citus (распределенные и справочные таблицы). В представлении объединена информация из таблиц метаданных Citus для простого и понятного пользователю обзора свойств этих таблиц:
- тип таблицы;
- столбец распределения;
- идентификатор группы размещения;
- удобочитаемый размер;
- количество сегментов;
- владелец (пользователь базы данных);
- метод доступа (
heapилиcolumnar).
Пример:
SELECT * FROM citus_tables;
┌────────────┬──────────────────┬─────────────────────┬───────────────┬────────────┬─────────────┬─────────────┬───────────────┐
│ table_name │ citus_table_type │ distribution_column │ colocation_id │ table_size │ shard_count │ table_owner │ access_method │
├────────────┼──────────────────┼─────────────────────┼───────────────┼────────────┼─────────────┼─────────────┼───────────────┤
│ foo.test │ distributed │ test_column │ 1 │ 0 bytes │ 32 │ citus │ heap │
│ ref │ reference │ <none> │ 2 │ 24 GB │ 1 │ citus │ heap │
│ test │ distributed │ id │ 1 │ 248 TB │ 32 │ citus │ heap │
└────────────┴──────────────────┴─────────────────────┴───────────────┴────────────┴─────────────┴─────────────┴───────────────┘
time_partitions
Citus предоставляет функции для управления разделами в случае использования данных временных рядов. Он также поддерживает представление time_partitions для проверки разделов, которыми он управляет.
Столбцы:
parent_table: таблица, которая является партиционированной;partition_column: столбец, на который разбита родительская таблица;partition: имя таблицы партиционирования;from_value: нижняя граница по времени для строк в этом разделе;to_value: верхняя граница по времени для строк в этом разделе;access_method:heapилиcolumnar.
Пример:
SELECT * FROM time_partitions;
┌────────────────────────┬──────────────────┬─────────────────────────────────────────┬─────────────────────┬─────────────────────┬───────────────┐
│ parent_table │ partition_column │ partition │ from_value │ to_value │ access_method │
├────────────────────────┼──────────────────┼─────────────────────────────────────────┼─────────────────────┼─────────────────────┼───────────────┤
│ github_columnar_events │ created_at │ github_columnar_events_p2015_01_01_0000 │ 2015-01-01 00:00:00 │ 2015-01-01 02:00:00 │ columnar │
│ github_columnar_events │ created_at │ github_columnar_events_p2015_01_01_0200 │ 2015-01-01 02:00:00 │ 2015-01-01 04:00:00 │ columnar │
│ github_columnar_events │ created_at │ github_columnar_events_p2015_01_01_0400 │ 2015-01-01 04:00:00 │ 2015-01-01 06:00:00 │ columnar │
│ github_columnar_events │ created_at │ github_columnar_events_p2015_01_01_0600 │ 2015-01-01 06:00:00 │ 2015-01-01 08:00:00 │ heap │
└────────────────────────┴──────────────────┴─────────────────────────────────────────┴─────────────────────┴─────────────────────┴───────────────┘
pg_dist_colocation
Таблица pg_dist_colocation содержит информацию о том, какие сегменты таблиц следует размещать совместно. Когда две таблицы находятся в одной и той же группе размещения, Citus гарантирует, что сегменты с одинаковыми значениями партиций будут размещены на одних и тех же рабочих узлах. Это позволяет оптимизировать объединение в запросах, использовать некоторые распределенные сводные таблицы и поддерживать внешние ключи. Совместное расположение предполагается, когда количество сегментов и типы столбцов партиционирования совпадают в двух таблицах, однако при создании распределенной таблицы может быть указана пользовательская группа совместного расположения, если это необходимо.
| Имя | Тип | Описание |
|---|---|---|
colocationid | int | Уникальный идентификатор для группы совместного размещения, которой соответствует эта строка |
shardcount | int | Количество сегментов для всех таблиц в этой группе совместного размещения |
replicationfactor | int | Коэффициент репликации для всех таблиц в этой группе совместного размещения. (Устарел) |
distributioncolumntype | oid | Тип столбца распределения для всех таблиц в этой группе совместного размещения |
distributioncolumncollation | oid | Правила сортировки(collation) столбца распределения для всех таблиц в этой группе совместного размещения |
Пример:
SELECT * from pg_dist_colocation;
colocationid | shardcount | replicationfactor | distributioncolumntype | distributioncolumncollation
--------------+------------+-------------------+------------------------+-----------------------------
2 | 32 | 1 | 20 | 0
(1 row)
pg_dist_rebalance_strategy
В этой таблице определены стратегии, которые citus_rebalance_start может использовать для определения того, куда перемещать сегменты.
| Имя | Тип | Описание |
|---|---|---|
name | name | Уникальное имя стратегии |
default_strategy | boolean | Должен ли citus_rebalance_start() выбирать эту стратегию по умолчанию. Используйте citus_set_default_rebalance_strategy() для обновления этого столбца |
shard_cost_function | regproc | Идентификатор функции вычисления стоимости, которая должна принять значение shardid как bigint и вернуть вычисленную для него стоимость как тип real |
node_capacity_function | regproc | Идентификатор для функции емкости, которая должна принимать nodeid в виде int и возвращать вычисленную емкость узла в виде типа real |
shard_allowed_on_node_function | regproc | Идентификатор для функции, которая принимает shardid (bigint) и nodeidarg (int), возвращает булево значение, указывающее, разрешено ли сохранять сегмент на узле |
default_threshold | float4 | Порог для определения узла как слишком заполненного или слишком пустого, который определяет, когда citus_rebalance_start() должен попытаться переместить сегменты |
minimum_threshold | float4 | Средство защиты , предотвращающее слишком низкое значение порогового параметра citus_rebalance_start() |
improvement_threshold | float4 | Определяет, стоит ли перемещать сегмент во время ребалансировки. Балансировщик переместит сегмент, когда соотношение улучшения при перемещении сегмента к улучшению без него превысит пороговое значение. Это наиболее полезно при использовании стратегии by_disk_size |
Citus устанавливается со следующими предопределенными стратегиями ребалансировки:
SELECT * FROM pg_dist_rebalance_strategy;
-[ RECORD 1 ]------------------+---------------------------------
name | by_shard_count
default_strategy | f
shard_cost_function | citus_shard_cost_1
node_capacity_function | citus_node_capacity_1
shard_allowed_on_node_function | citus_shard_allowed_on_node_true
default_threshold | 0
minimum_threshold | 0
improvement_threshold | 0
-[ RECORD 2 ]------------------+---------------------------------
name | by_disk_size
default_strategy | t
shard_cost_function | citus_shard_cost_by_disk_size
node_capacity_function | citus_node_capacity_1
shard_allowed_on_node_function | citus_shard_allowed_on_node_true
default_threshold | 0.1
minimum_threshold | 0.01
improvement_threshold | 0.5
Стратегия by_disk_size присваивает каждому сегменту одинаковую стоимость. Ее целью является выравнивание количества сегментов в узлах. Стратегия по умолчанию by_disk_size присваивает стоимость каждому сегменту, соответствующую размеру его диска в байтах, плюс размер сегментов, которые расположены рядом с ним. Размер диска рассчитывается с использованием pg_total_relation_size, поэтому он включает еще размеры индексов. Эта стратегия направлена на достижение одинакового объема дискового пространства на каждом узле. Обратите внимание на пороговое значение 0,1 – оно предотвращает ненужное перемещение фрагментов, вызванное незначительными различиями в объеме дискового пространства.
Создание собственной стратегии ребалансировки
Ниже приведены примеры функций, которые могут быть использованы в рамках новых стратегий балансировки сегментов и зарегистрированы в таблице стратегий балансировки с помощью функции citus_add_rebalance_strategy.
Настройка исключения пропускной способности узла по шаблону имени хоста:
-- example of node_capacity_function
CREATE FUNCTION v2_node_double_capacity(nodeidarg int)
RETURNS real AS $$
SELECT
(CASE WHEN nodename LIKE '%.v2.worker.citusdata.com' THEN 2.0::float4 ELSE 1.0::float4 END)
FROM pg_dist_node where nodeid = nodeidarg
$$ LANGUAGE sql;
ребалансировка по количеству запросов, поступающих в сегмент, определяется таблицей статистики запросов:
-- example of shard_cost_function
CREATE FUNCTION cost_of_shard_by_number_of_queries(shardid bigint)
RETURNS real AS $$
SELECT coalesce(sum(calls)::real, 0.001) as shard_total_queries
FROM citus_stat_statements
WHERE partition_key is not null
AND get_shard_id_for_distribution_column('tab', partition_key) = shardid;
$$ LANGUAGE sql;
Изолирование определенного сегмента (10000) на узле:
-- example of shard_allowed_on_node_function
CREATE FUNCTION isolate_shard_10000_on_10_0_0_1(shardid bigint, nodeidarg int)
RETURNS boolean AS $$
SELECT
(CASE WHEN nodename = '<IP-адрес>' THEN shardid = 10000 ELSE shardid != 10000 END)
FROM pg_dist_node where nodeid = nodeidarg
$$ LANGUAGE sql;
-- The next two definitions are recommended in combination with the above function.
-- This way the average utilization of nodes is not impacted by the isolated shard.
CREATE FUNCTION no_capacity_for_10_0_0_1(nodeidarg int)
RETURNS real AS $$
SELECT
(CASE WHEN nodename = '<IP-адрес>' THEN 0 ELSE 1 END)::real
FROM pg_dist_node where nodeid = nodeidarg
$$ LANGUAGE sql;
CREATE FUNCTION no_cost_for_10000(shardid bigint)
RETURNS real AS $$
SELECT
(CASE WHEN shardid = 10000 THEN 0 ELSE 1 END)::real
$$ LANGUAGE sql;
citus_stat_statements
В Citus реализовано представление citus_stat_statements для получения статистики о том, как выполняются запросы. Представление аналогично (и может быть объединено с) представлению pg_stat_statements в PostgreSQL, которое отслеживает статистику выполнения запросов.
| Имя | Тип | Описание |
|---|---|---|
queryid | bigint | Идентификатор запроса (подходит для объединения с pg_stat_statements) |
userid | oid | Пользователь, запустивший запрос |
dbid | oid | Идентификатор БД на координаторе |
query | text | Анонимизированная строка запроса |
executor | text | Используемый исполнитель Citus: адаптивный, или insert-select |
partition_key | text | Значение столбца распределения в маршрутизируемых запросах, иначе NULL |
calls | bigint | Количество запусков запроса |
Пример:
-- create and populate distributed table
create table foo ( id int );
select create_distributed_table('foo', 'id');
insert into foo select generate_series(1,100);
-- enable stats
-- pg_stat_statements must be in shared_preload libraries
create extension pg_stat_statements;
select count(*) from foo;
select * from foo where id = 42;
select * from citus_stat_statements;
-[ RECORD 1 ]-+----------------------------------------------
queryid | <queryid>
userid | 10
dbid | 13340
query | insert into foo select generate_series($1,$2)
executor | insert-select
partition_key |
calls | 1
-[ RECORD 2 ]-+----------------------------------------------
queryid | <queryid>
userid | 10
dbid | 13340
query | select count(*) from foo;
executor | adaptive
partition_key |
calls | 1
-[ RECORD 3 ]-+----------------------------------------------
queryid | <queryid>
userid | 10
dbid | 13340
query | select * from foo where id = $1
executor | adaptive
partition_key | 42
calls | 1
Предостережения:
- Статистические данные не реплицируются и не сохраняются при сбоях базы данных или переходе на другой ресурс.
- Отслеживает ограниченное количество запросов, заданное параметром
pg_stat_statements.max(по умолчанию5000). - Чтобы очистить представление, используйте функцию
citus_stat_statements_reset().
citus_state_tenants
Представление citus_state_tenants дополняет таблицу статистики запросов информацией о том, сколько запросов выполняется каждым клиентом. Отслеживание запросов на клиентах помогает, среди прочего, принимать решения о том, когда следует изолировать клиента. В этом представлении подсчитываются последние запросы от одного клиента, выполненные в течение настраиваемого периода времени. Количество запросов, доступных только для чтения, и общее количество запросов за период увеличивается до окончания текущего периода. После этого данные переносятся в статистику последнего периода, которая остается постоянной до истечения срока действия. Длительность периода может быть задана в секундах с помощью citus.stats_tenants_period и по умолчанию составляет 60 секунд. В представлении отображается до 100 строк, это количество регулируется параметром citus.state_tenants_limit (по умолчанию 100). Он учитывает только запросы, отфильтрованные для одного клиента, игнорируя запросы, которые применяются сразу к нескольким клиентам.
| Имя | Тип | Описание |
|---|---|---|
nodeid | int | Идентификатор узла из таблицы рабочих узлов |
colocation_id | int | Идентификатор группы совместного размещения |
tenant_attribute | text | Значение столбца распределения идентифицирующее узел |
read_count_in_this_period | int | Количество операций чтения (SELECT) для узла за текущий период |
read_count_in_last_period | int | Количество запросов на чтение за прошлый период |
query_count_in_this_period | int | Количество операций чтения/записи для узла за текущий период |
query_count_in_last_period | int | Количество запросов чтения/записи за прошлый период |
cpu_usage_in_this_period | double | Процессорное время потраченное узлом за текущий период |
cpu_usage_in_last_period | double | Процессорное время потраченное узлом за прошлый период |
Отслеживание статистики на уровне арендаторов увеличивает накладные расходы и по умолчанию отключено. Чтобы включить его, установите для citus.stat_tenants_track значение all.
Пример:
Предположим, что есть распределенная таблица с именем dist_table и столбцом распределения tenant_id. Затем выполняются несколько запросов:
INSERT INTO dist_table(tenant_id) VALUES (1);
INSERT INTO dist_table(tenant_id) VALUES (1);
INSERT INTO dist_table(tenant_id) VALUES (2);
SELECT count(*) FROM dist_table WHERE tenant_id = 1;
Статистика на уровне клиента будет отражать запросы, которые только что выполнились:
SELECT tenant_attribute, read_count_in_this_period,
query_count_in_this_period, cpu_usage_in_this_period
FROM citus_stat_tenants;
tenant_attribute | read_count_in_this_period | query_count_in_this_period | cpu_usage_in_this_period
------------------+---------------------------+----------------------------+--------------------------
1 | 1 | 3 | 0.000883
2 | 0 | 1 | 0.000144
citus_state_activity, citus_dist_state_activity и citus_lock_waits
В некоторых ситуациях запросы могут удерживаться блокировками на уровне строк на одном из сегментов рабочего узла. Если это произойдет, то эти запросы не будут отображаться в pg_locks на узле-координаторе Citus. Citus предоставляет специальные представления для просмотра запросов и блокировок по всему кластеру, включая запросы, относящиеся к сегментам, которые используются внутри системы для получения результатов для распределенных запросов.
citus_state_activity: показывает распределенные запросы, которые выполняются на всех узлах. Надмножествоpg_stat_activity, используемое везде, где находится последнее.citus_dist_state_activity: то же, что иcitus_state_activity, но ограничено только распределенными запросами и исключает запросы фрагментов Citus.citus_lock_waits: Заблокированные запросы по всему кластеру.
Первые два представления содержат все столбцы pg_stat_activity плюс глобальный PID рабочего узла, который инициировал запрос. Например, рассмотрим подсчет строк в распределенной таблице:
-- run in one session
-- (with a pg_sleep so we can see it)
SELECT count(*), pg_sleep(3) FROM users_table;
Запрос можно увидеть в citus_dist_stat_activity
-- run in another session
SELECT * FROM citus_dist_stat_activity;
-[ RECORD 1 ]----+-------------------------------------------
global_pid | 10000012199
nodeid | 1
is_worker_query | f
datid | 13724
datname | postgres
pid | 12199
leader_pid |
usesysid | 10
usename | postgres
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2022-03-23 11:30:00.533991-05
xact_start | 2022-03-23 19:35:28.095546-05
query_start | 2022-03-23 19:35:28.095546-05
state_change | 2022-03-23 19:35:28.09564-05
wait_event_type | Timeout
wait_event | PgSleep
state | active
backend_xid |
backend_xmin | 777
query_id |
query | SELECT count(*), pg_sleep(3) FROM users_table;
backend_type | client backend
Представление citus_dist_stat_activity скрывает внутренние запросы фрагментов Citus. Чтобы увидеть их, можно использовать более подробное представление citus_stat_activity. Например, для предыдущего запроса count(*) требуется информация из всех сегментов. Некоторая информация содержится в сегменте user_table_102039, которая видна в приведенном ниже запросе:
SELECT * FROM citus_stat_activity;
-[ RECORD 1 ]----+-----------------------------------------------------------------------
global_pid | 10000012199
nodeid | 1
is_worker_query | f
datid | 13724
datname | postgres
pid | 12199
leader_pid |
usesysid | 10
usename | postgres
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2022-03-23 11:30:00.533991-05
xact_start | 2022-03-23 19:32:18.260803-05
query_start | 2022-03-23 19:32:18.260803-05
state_change | 2022-03-23 19:32:18.260821-05
wait_event_type | Timeout
wait_event | PgSleep
state | active
backend_xid |
backend_xmin | 777
query_id |
query | SELECT count(*), pg_sleep(3) FROM users_table;
backend_type | client backend
-[ RECORD 2 ]----------+-----------------------------------------------------------------------------------------
global_pid | 10000012199
nodeid | 1
is_worker_query | t
datid | 13724
datname | postgres
pid | 12725
leader_pid |
usesysid | 10
usename | postgres
application_name | citus_internal gpid=10000012199
client_addr | 127.0.0.1
client_hostname |
client_port | 44106
backend_start | 2022-03-23 19:29:53.377573-05
xact_start |
query_start | 2022-03-23 19:32:18.278121-05
state_change | 2022-03-23 19:32:18.278281-05
wait_event_type | Client
wait_event | ClientRead
state | idle
backend_xid |
backend_xmin |
query_id |
query | SELECT count(*) AS count FROM public.users_table_102039 users WHERE true
backend_type | client backend
В поле query отображаются строки, подсчитываемые в сегменте 102039. Ниже приведены примеры полезных запросов, которые можно создать, используя citus_state_activity:
-- active queries' wait events
SELECT query, wait_event_type, wait_event
FROM citus_stat_activity
WHERE state='active';
-- active queries' top wait events
SELECT wait_event, wait_event_type, count(*)
FROM citus_stat_activity
WHERE state='active'
GROUP BY wait_event, wait_event_type
ORDER BY count(*) desc;
-- total internal connections generated per node by Citus
SELECT nodeid, count(*)
FROM citus_stat_activity
WHERE is_worker_query
GROUP BY nodeid;
Следующее представление – citus_lock_waits. Чтобы увидеть, как это работает, сгенерируйте ситуацию блокировки вручную. Сначала настройте тестовую таблицу с помощью координатора:
CREATE TABLE numbers AS
SELECT i, 0 AS j FROM generate_series(1,10) AS i;
SELECT create_distributed_table('numbers', 'i');
Затем, используя две сессии на координаторе, запустите последовательность инструкций:
-- session 1 -- session 2
------------------------------------- -------------------------------------
BEGIN;
UPDATE numbers SET j = 2 WHERE i = 1;
BEGIN;
UPDATE numbers SET j = 3 WHERE i = 1;
-- (this blocks)
Представление citus_lock_waits позволяет увидеть блокировки:
SELECT * FROM citus_lock_waits;
-[ RECORD 1 ]-------------------------+--------------------------------------
waiting_gpid | 10000011981
blocking_gpid | 10000011979
blocked_statement | UPDATE numbers SET j = 3 WHERE i = 1;
current_statement_in_blocking_process | UPDATE numbers SET j = 2 WHERE i = 1;
waiting_nodeid | 1
blocking_nodeid | 1
В этом примере запросы исходят от координатора, но в представлении также могут отображаться блокировки между запросами, исходящими от рабочих узлов.
Таблицы на всех узлах
У Citus есть другие информационные таблицы и представления, которые доступны на всех узлах, а не только на координаторе.
pg_dist_authinfo
Таблица pg_dist_authinfo содержит параметры аутентификации, используемые узлами Citus для подключения друг к другу.
| Имя | Тип | Описание |
|---|---|---|
nodeid | integer | идентификатор узла(nodeid) из таблицы узлов, или 0, или -1 |
rolename | name | Роль PostgreSQL |
authinfo | text | Разделенные пробелом параметры подключения libpq |
При установке соединения каждый узел обращается к этой таблице, чтобы узнать, существует ли строка с идентификатором(nodeid) узла назначения и желаемым именем роли. Если это так, узел включает соответствующую строку authinfo в свое соединение libpq. Распространенным примером является сохранение пароля, например password=abc123, но возможно указание и других параметров libpq. Параметры в authinfo разделяются пробелами в форме key=val. Чтобы ввести пустое значение или значение, содержащее пробелы, заключите его в одинарные кавычки, например, keyword='значение'. Одинарные кавычки и обратные косые черты внутри значения должны быть экранированы обратной косой чертой, т.е. \' и \\. Столбец nodeid также может принимать специальные значения 0 и -1, которые означают все узлы или обратные соединения, соответственно. Если для данного узла существуют как специфические, так и общие для всех узлов правила, то это конкретное правило имеет приоритет.
Пример:
SELECT * FROM pg_dist_authinfo;
nodeid | rolename | authinfo
--------+----------+-----------------
123 | jdoe | password=abc123
(1 row)
pg_dist_poolinfo
При необходимости использовать пул соединений для подключения к узлу, можно указать параметры пула, используя pg_dist_poolinfo. В этой таблице метаданных содержатся хост, порт и имя базы данных, которые Citus будет использовать при подключении к узлу через пул. Если информация о пуле присутствует, Citus попытается использовать эти значения вместо установки прямого соединения. Информация pg_dist_poolinfo в этом случае заменяет pg_dist_node.
| Имя | Тип | Описание |
|---|---|---|
nodeid | integer | Идентификатор узла из таблицы рабочих узлов |
poolinfo | text | Параметры, разделенные пробелом: host, port, или dbname |
В некоторых ситуациях Citus игнорирует настройки в pg_dist_poolinfo. Например, ребалансировка сегментов несовместима с пулами подключений, такими как pgbouncer. В этих сценариях Citus будет использовать прямое подключение.
Пример:
-- how to connect to node 1 (as identified in pg_dist_node)
INSERT INTO pg_dist_poolinfo (nodeid, poolinfo)
VALUES (1, 'host=127.0.0.1 port=5433');
Доработка
Доработка расширения не производилась.
Ограничения
-
Расширение не работает с хранилищем паролей, для успешной работы кластера необходимо настраивать методы аутентификации без пароля(файл .pgpass, аутентификация по сертификату).
-
Для установки и настройки кластера нужен суперпользователь.
-
Для колоночного формата хранения существуют следующие ограничения:
- Только
INSERT(без поддержкиUPDATE/DELETE). - Нет возможности освободить место (например, при откате транзакций может потребоваться место на диске).
- Поддерживаются только индексы
btreeиhash. - Нет поддержки
TOAST(большие значения хранятся непосредственно в таблице). - Нет поддержки инструкций
ON CONFLICT(кроме действияDO NOTHINGбез указания цели). - Нет поддержки уровня блокировок
SELECT … FOR SHARE,SELECT … FOR UPDATE. - Нет поддержки уровня изоляции
serializable. - Поддержка только для серверов PostgreSQL версий 12+.
- Нет поддержки внешних ключей, уникальных ограничений или ограничений исключения.
- Нет поддержки логического декодирования.
- Нет поддержки параллельного сканирования внутри узла.
- Нет поддержки триггеров
AFTER…FOR EACH ROW. - Нет возможности создать
UNLOGGEDилиTEMPORARYтаблицы.
- Только
-
Расширение не работает с партиционированными таблицами и глобальными индексами.
Установка
Сборка расширения производится при помощи PGXS. Чтобы расширение собралось, необходимо изменить некоторые флаги сборки. Итоговый процесс сборки расширения под продукт Pangolin выглядит следующим образом:
cd $POSTGRESQL_SRC_DIR
git clone https://github.com/citusdata/citus.git contrib
cd contrib/citus
CFLAGS="-Wno-format -Wno-format-security -Wno-missing-braces -Wno-switch" ./configure
make install DESTDIR=$PGHOME
Для удобства расширение собрано и упаковано под конкретную версию Pangolin в дистрибутиве c зависимостями 3rd-party. Для установки расширение необходимо распаковать и скопировать в директорию с установленным продуктом:
sudo cp -r ./third_party/citus/usr /usr
После сборки расширение доступно для установки. Поскольку расширение инициализируется на старте системы и использует общую память перед установкой оно должно быть добавлено в shared_preload_libraries, причем расширение должно идти первым в списке. После того как расширение добавлено в shared_preload_libraries, его можно установить в целевую БД командой:
CREATE EXTENSION citus;
Данная команда установит два расширения - citus для распределенного хранилища и citus_columnar для колоночного метода доступа:
citus=# \dx
List of installed extensions
Name | Version | Schema | Description
---------------+---------+------------+------------------------------
citus | 12.1-3 | pg_catalog | Citus distributed database
citus_columnar | 12.1-3 | pg_catalog | Citus Columnar extension
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(3 rows)
Для реализации распределенного хранилища необходимо аналогичные действия проделать на всех узлах кластера, при этом надо иметь в виду, что на всех узлах имя БД должно быть одинаковым. Также на всех узлах должен существовать пользователь с тем же именем, с которым будут запускаться команды на координаторе. Часть действий требует привилегий суперпользователя. Для первоначальной настройки кластера необходимо, чтобы пользователь под которым осуществляется настройка мог аутентифицироваться на всех узлах без пароля(возможно настроить аутентификацию по сертификату и положить сертификаты в стандартный для PostgreSQL путь - ~/.postgresql).
Архитектурно кластер citus разделен на две части — узел координатор, который хранит метаданные и справочную информацию кластера, и рабочие узлы, которые хранят сегменты данных. Для построения кластера необходимо сначала зарегистрировать узел координатор, после чего на координаторе добавить в кластер рабочие узлы:
SELECT citus_set_coordinator_host('<IP-address>', 5433);
SELECT * from citus_add_node('<IP-address>', 15433);
SELECT * from citus_add_node('<IP-address>', 15434);
Далее все команды выполняются на узле координаторе. Например, можно создавать распределенные таблицы:
CREATE TABLE github_users
(
user_id bigint,
url text,
login text,
avatar_url text,
gravatar_id text,
display_login text
);
SELECT create_distributed_table('github_users', 'user_id');
И распределенные схемы:
CREATE SCHEMA AUTHORIZATION user_service;
CREATE SCHEMA AUTHORIZATION time_service;
CREATE SCHEMA AUTHORIZATION ping_service;
SELECT citus_schema_distribute('user_service');
SELECT citus_schema_distribute('time_service');
SELECT citus_schema_distribute('ping_service');
Для лучшего сжатия архивных данных в аналитических таблицах расширение реализует колоночный метод доступа, для его использования в БД с установленным расширением необходимо создавать таблицу с использованием директивы USING columnar. Пример:
CREATE TABLE contestant (
handle TEXT,
birthdate DATE,
rating INT,
percentile FLOAT,
country CHAR(3),
achievements TEXT[]
) USING columnar;
Также есть возможность менять существующий формат хранения. Для этого реализована следующая функция citus:
-- Convert to row-based (heap) storage
SELECT alter_table_set_access_method('contestant', 'heap');
-- Convert to columnar storage (indexes will be dropped)
SELECT alter_table_set_access_method('contestant', 'columnar');
Подробное описание всех функций, таблиц и представлений, а также конфигурационных параметров расширения с их подробным описанием приведены в соответствующих разделах документации.
Настройка
Конфигурационные параметры
Существуют различные параметры конфигурации, которые влияют на поведение Citus. К ним относятся как стандартные параметры PostgreSQL, так и параметры, специфичные для Citus. Чтобы узнать больше о параметрах конфигурации PostgreSQL, обратитесь к разделу документации по PostgreSQL, посвященный конфигурационным параметрам. Ниже описываются параметры конфигурации, специфичные для Citus. Эти параметры можно задать аналогично параметрам PostgreSQL, изменив файл postgresql.conf или используя команду SET. В качестве примера можно обновить настройки с помощью:
ALTER DATABASE citus SET citus.multi_task_query_log_level = 'log';
Глобальная конфигурация
citus.max_background_task_executors_per_node (integer)
Определяет, сколько фоновых задач может выполняться параллельно в данный момент времени. Например, эти задачи предназначены для перемещения фрагментов от узла к узлу. При увеличении этого значения возможно придется увеличить citus.max_background_task_executors и max_worker_processes. Значения, которые может принимать данный параметр:
- минимальное значение -
1; - максимальное значение -
128; - значение по умолчанию -
1.
citus.max_worker_nodes_tracked (integer)
Citus отслеживает местоположение рабочих узлов и их принадлежность к общей таблице хешей на узле-координаторе. Это значение конфигурации ограничивает размер таблицы хешей и, следовательно, количество отслеживаемых рабочих узлов. Значение по умолчанию для этого параметра равно 2048. Этот параметр может быть установлен только при запуске сервера и действует на узле-координаторе.
citus.use_secondary_nodes (enum)
Устанавливает политику, которая будет использоваться при выборе узлов для запросов SELECT. Если для этого параметра установлено значение always, планировщик будет запрашивать только те узлы, которые помечены как secondary в pg_dist_node. Поддерживаемые значения для этого списка следующие:
never: (по умолчанию) Все операции чтения выполняются на первичных узлах;always: операции чтения выполняются на вторичных узлах, а инструкцииinsert/updateотключены.
citus.cluster_name (text)
Информирует планировщик узла-координатора о том, какой кластер он координирует. Как только будет задано значение cluster_name, планировщик будет запрашивать рабочие узлы только в этом кластере.
citus.enable_version_checks (boolean)
Для обновления версии Citus требуется перезагрузка сервера (для загрузки новой общей библиотеки), а также выполнение команды ALTER EXTENSION UPDATE. Невыполнение обоих шагов потенциально может привести к ошибкам или сбоям. Таким образом, Citus проверяет соответствие версии кода и версии расширения и выдает ошибку, если они не совпадают. Значение по умолчанию равно true и действует на координаторе. В редких случаях для сложных процессов обновления может потребоваться установить для этого параметра значение false, что отключит проверку.
citus.log_distributed_deadlock_detection (boolean)
Следует ли регистрировать в журнале сервера события, связанные с обнаружением распределенной взаимоблокировки. По умолчанию установлено значение false.
citus.distributed_deadlock_detection_factor (floating point)
Устанавливает время ожидания перед проверкой распределенных взаимоблокировок. В частности, время ожидания будет равно этому значению, умноженному на параметр deadlock_timeout в PostgreSQL. Значение по умолчанию равно 2. Значение -1 отключает обнаружение распределенных взаимоблокировок.
citus.node_connection_timeout (integer)
Параметр citus.node_connection_timeout устанавливает максимальную продолжительность ожидания установления соединения (в миллисекундах). Citus выдает ошибку, если по истечении времени ожидания не будет установлено хотя бы одно рабочее соединение. Этот параметр влияет на соединения координатора с рабочими узлами и рабочих узлов друг с другом. Возможные значения:
- по умолчанию: тридцать секунд;
- минимум: десять миллисекунд;
- максимум: один час.
Пример установки параметра:
-- set to 60 seconds
ALTER DATABASE foo
SET citus.node_connection_timeout = 60000;
citus.node_conninfo (text)
В параметре citus.node_conninfo устанавливаются конфиденциальные параметры соединения libpq, используемые для всех межузловых подключений.
-- key=value pairs separated by spaces.
-- For example, ssl options:
ALTER DATABASE foo
SET citus.node_conninfo =
'sslrootcert=/path/to/citus.crt sslmode=verify-full';
Citus поддерживает только определенное подмножество разрешенных опций, а именно:
application_name;connect_timeout;gsslib†;keepalives;keepalive_count;keepalive_idle;keepalive_interval;krbsrvname†;ssl_compression;sslcrl;sslmode(по умолчанию используется значениеrequireначиная с Citrus 8.1);sslrootcert;tcp_user_timeout.
† – при условии наличия во время выполнения дополнительных возможностей PostgreSQL.
Параметр node_conninfo вступает в силу только для новых подключений. Чтобы заставить все подключения использовать новые настройки, обязательно перезагрузите конфигурацию postgres:
SELECT pg_reload_conf();
citus.local_hostname
Узлам Citus иногда требуется подключаться к самим себе для системных операций. По умолчанию они используют адрес localhost для ссылки на себя, но это может вызывать проблемы. Например, когда хост требует sslmode=verify-full для входящих подключений, добавление localhost в качестве альтернативного имени хоста в SSL–сертификат не всегда желательно или даже неосуществимо. Параметр citus.local_hostname определяет имя хоста, которое узел использует для подключения к себе. Значение по умолчанию - localhost.
Пример изменения параметра:
ALTER SYSTEM SET citus.local_hostname TO 'mynode.example.com';
citus.show_shards_for_app_name_prefixes
По умолчанию Citus скрывает сегменты из списка таблиц, которые PostgreSQL предоставляет клиентам в SQL-запросах. Это происходит потому, что в каждой распределенной таблице есть несколько сегментов, и сегменты могут отвлекать клиента. Параметр citus.show_shards_for_app_name_prefixes позволяет отображать сегменты для выбранных клиентов, которые хотят их видеть. Его значение по умолчанию равно пустой строке('')
Пример:
-- show shards to psql only (hide in other clients, like pgAdmin)
SET citus.show_shards_for_app_name_prefixes TO 'psql';
-- also accepts a comma separated list
SET citus.show_shards_for_app_name_prefixes TO 'psql,pg_dump';
citus.rebalancer_by_disk_size_base_cost (integer)
При использовании стратегии ребалансировки by_disk_size каждая группа сегментов получит эту стоимость в байтах, добавленную к ее фактическому размеру диска. Это используется для того, чтобы избежать нарушения баланса, когда в некоторых сегментах очень мало данных. Предполагается, что даже пустые сегменты имеют определенную стоимость из-за параллелизма и из-за того, что группы пустых сегментов, вероятно, будут увеличиваться в будущем. Значение по умолчанию равно 100 МБ.
citus.stat_statements_purge_interval (integer)
Устанавливает частоту, с которой демон обслуживания удаляет записи из citus_stat_statements, которые не соответствуют pg_stat_statements. Это значение конфигурации устанавливает интервал времени между очистками в секундах, значение по умолчанию равно 10. Значение 0 отключает очистку. Этот параметр действует для координатора и может быть изменен во время выполнения.
Пример:
SET citus.stat_statements_purge_interval TO 5;
citus.stat_statements_max (integer)
Максимальное количество строк для хранения в citus_stat_statements. Значение по умолчанию равно 50000 и может быть изменено на любое значение в диапазоне от 1000 до 10000000. Обратите внимание, что для каждой строки требуется 140 байт памяти, поэтому установка stat_statements_max на максимальное значение 10M потребляет 1,4 ГБ памяти. Изменение этого параметра не вступит в силу до перезапуска PostgreSQL.
citus.stat_statements_track (enum)
Запись статистики для citus_stat_statements требует дополнительных ресурсов процессора. Когда база данных загружается, администратор может захотеть отключить отслеживание запросов. Параметр citus.stat_statements_track может включать и выключать отслеживание. Возможные значения:
all(по умолчанию) – отслеживать все запросы;none– отключить отслеживание.
citus.stat_tenants_untracked_sample_rate (floating point)
Частота выборки для новых арендаторов в citus_stat_tenants. Коэффициент может быть в диапазоне от 0,0 до 1,0. Значение по умолчанию равно 1,0, что означает, что отбираются 100% неотслеживаемых запросов клиентов. Установка меньшего значения означает, что запросы уже отслеживаемых клиентов отбираются на 100%, но запросы клиентов, которые в данный момент не отслеживаются, отбираются только с указанной частотой.
citus.multi_shard_commit_protocol (enum)
Устанавливает протокол фиксации, который будет использоваться при выполнении операций COPY в распределенную таблицу хешей. При каждом отдельном размещении сегмента операция COPY выполняется в блоке транзакций, чтобы гарантировать, что данные не будут пропущены, если во время копирования возникнет ошибка. Однако существует особый случай сбоя, при котором копирование выполняется успешно при всех размещениях, но (аппаратный) сбой происходит до фиксации всех транзакций. Этот параметр можно использовать для предотвращения потери данных в этом случае, выбрав один из следующих протоколов фиксации:
2pc: (по умолчанию) Транзакции, в которых выполняются операцииCOPYв местах размещений сегментов, сначала подготавливаются с использованием командыPREPARE TRANSACTIONв PostgreSQL, а затем фиксируются. Неудачные фиксации могут быть восстановлены вручную или прерваны с помощьюCOMMIT PREPAREDилиROLLBACK PREPARED, соответственно. При использовании2pcзначениеmax_prepared_transactionsдолжно быть увеличено для всех рабочих элементов, обычно до того же значения, что и значениеmax_connections.1pc: Транзакции, в которых выполняются операцииCOPYв местах размещений сегментов фиксируются за одну операцию. Данные могут быть потеряны в случае сбоя фиксации после успешного копирования во все местах размещения (редко).
citus.shard_count (integer)
Задает количество сегментов для таблиц с разделением по хешу и по умолчанию равно 32. Это значение используется функцией create_distributed_table при создании таблиц с распределением по хешу. Этот параметр может быть установлен во время выполнения и действует на координаторе.
citus.shard_max_size (integer)
Устанавливает максимальный размер, до которого может увеличиться сегмент перед разделением, и по умолчанию он равен 1 ГБ. Когда размер исходного файла (который используется для промежуточной обработки) для одного сегмента превышает это значение конфигурации, база данных гарантирует, что будет создан новый сегмент. Этот параметр может быть установлен во время выполнения и действует на координаторе.
citus.replicate_reference_tables_on_activate (boolean)
Сегменты справочной таблицы должны быть размещены на всех узлах, которые имеют распределенные таблицы. По умолчанию сегменты справочной таблицы копируются на узел во время активации узла, то есть при вызове таких функций, как citus_add_node или citus_activate_node. Однако активация узла может оказаться неудобным моментом для копирования, поскольку копирование больших справочных таблиц может занять много времени. Возможно отложить репликацию справочных таблиц, установив для параметра citus.replicate_reference_tables_on_activate значение off. Репликация справочных таблиц произойдет, когда будут созданы новые сегменты на этом узле. Например, при вызове create_distributed_table, create_reference_table или при ребалансировке сегментов, когда сегменты перемещаются на новый узел. Значение по умолчанию для этого параметра равно on.
citus.metadata_sync_mode (enum)
Для изменения данного параметра необходимы привилегии суперпользователя.
Этот параметр определяет, как Citus синхронизирует метаданные между узлами. По умолчанию Citus обновляет все метаданные за одну транзакцию для обеспечения согласованности. Однако PostgreSQL имеет жесткие ограничения по объему памяти, связанные с аннулированием кеша, и синхронизация метаданных Citus для большого кластера может завершиться сбоем из-за нехватки памяти. В качестве решения Citus предоставляет дополнительный режим безтранзакционной синхронизации, который использует серию небольших транзакций. Хотя этот режим работает в условиях ограниченной памяти, существует вероятность сбоя транзакций и несоответствия метаданных. Чтобы решить эту потенциальную проблему, синхронизация метаданных, не связанных с транзакциями, разработана как идемпотентное действие, поэтому при необходимости можно ее запустить повторно. У этого параметра есть два значения:
transactional: (по умолчанию) синхронизация всех метаданных в одной транзакции.nontransactional: синхронизировать метаданные с помощью нескольких небольших транзакций.
Примеры:
-- to add a new node and sync nontransactionally
SET citus.metadata_sync_mode TO 'nontransactional';
SELECT citus_add_node(<ip>, <port>);
-- to manually (re)sync
SET citus.metadata_sync_mode TO 'nontransactional';
SELECT start_metadata_sync_to_all_nodes();
Рекомендуется сначала попробовать режим по умолчанию и только если будут случаться сбои из-за нехватки памяти переключаться на нетранзакционный режим.
citus.local_table_join_policy (enum)
Этот параметр определяет, как Citus перемещает данные при выполнении объединения между локальной и распределенной таблицами. Настройка политики объединения может помочь уменьшить объем данных, передаваемых между рабочими узлами. Citus отправит локальные или распределенные таблицы узлам по мере необходимости для поддержки объединения. Копирование табличных данных называется “преобразованием”. Если локальная таблица преобразована, то она будет отправлена всем рабочим узлам, которым нужны ее данные для выполнения объединения. Если распределенная таблица преобразована, то она будет собрана в координаторе для поддержки объединения. Планировщик Citus отправит только те строки, которые необходимы для преобразования. Для выражения предпочтений в отношении преобразования доступны четыре режима:
auto: (по умолчанию) Citus преобразует либо все локальные, либо все распределенные таблицы для поддержки объединения локальных и распределенных таблиц. Citus решает, какие из них преобразовать, используя эвристику. Он преобразует распределенные таблицы, если они объединены с использованием постоянного фильтра по уникальному индексу (например, первичному ключу). Это гарантирует, что между рабочими узлами будет передаваться меньше данных.never: Citus не разрешает объединения между локальными и распределенными таблицами.prefer-local: Citus предпочтет преобразование локальных таблиц для поддержки объединения локальных и распределенных таблиц.prefer-distributed: Citus предпочтет преобразование распределенных таблиц для поддержки объединения локальных и распределенных таблиц. Если распределенные таблицы огромны, использование этой опции может привести к перемещению большого количества данных между рабочими узлами.
Например, предположим, что citus_table - это распределенная таблица, распределяемая по столбцу x, а postgres_table - это локальная таблица, тогда:
CREATE TABLE citus_table(x int primary key, y int);
SELECT create_distributed_table('citus_table', 'x');
CREATE TABLE postgres_table(x int, y int);
-- even though the join is on primary key, there isn't a constant filter
-- hence postgres_table will be sent to worker nodes to support the join
SELECT * FROM citus_table JOIN postgres_table USING (x);
-- there is a constant filter on a primary key, hence the filtered row
-- from the distributed table will be pulled to coordinator to support the join
SELECT * FROM citus_table JOIN postgres_table USING (x) WHERE citus_table.x = 10;
SET citus.local_table_join_policy to 'prefer-distributed';
-- since we prefer distributed tables, citus_table will be pulled to coordinator
-- to support the join. Note that citus_table can be huge.
SELECT * FROM citus_table JOIN postgres_table USING (x);
SET citus.local_table_join_policy to 'prefer-local';
-- even though there is a constant filter on primary key for citus_table
-- postgres_table will be sent to necessary workers because we are using 'prefer-local'.
SELECT * FROM citus_table JOIN postgres_table USING (x) WHERE citus_table.x = 10;
citus.limit_clause_row_fetch_count (integer)
Задает количество строк для выборки в каждой задаче для оптимизации условия ограничения(limit). В некоторых случаях для запросов select с условием ограничения может потребоваться выборка всех строк из каждой задачи для получения результатов. В тех случаях, когда аппроксимация может привести к значимым результатам, это значение конфигурации определяет количество строк для извлечения из каждого сегмента. По умолчанию предельные аппроксимации отключены, и этому параметру присвоено значение -1. Это значение может быть установлено во время выполнения и действует на координаторе.
citus.count_distinct_error_rate (floating point)
Citus может вычислять приблизительные значения count(distinct) с помощью расширения postgresql-hll. Этот параметр конфигурации устанавливает желаемый уровень ошибок при вычислении count(distinct). Значение 0.0, установленное по умолчанию, отключает аппроксимацию для функции count(distinct), а значение 1.0 не гарантирует точность результатов. Рекомендуется установить для этого параметра значение 0.005 для получения наилучших результатов. Это значение может быть установлено во время выполнения и действительно для координатора.
citus.task_assignment_policy (enum)
Этот параметр применим для запросов к справочным таблицам. Устанавливает политику, которая будет использоваться при назначении задач рабочим узлам. Координатор назначает задачи рабочим узлам на основе расположения сегментов. Этот параметр конфигурации определяет политику, которая будет использоваться при выполнении этих назначений. В настоящее время существует три возможных политики назначения задач, которые можно использовать.
greedy: эта политика используется по умолчанию и направлена на равномерное распределение задач между рабочими узлами.round-robin: распределяет задачи между рабочими узлами в циклическом режиме, чередуя реплики. Это позволяет значительно повысить эффективность использования кластера, когда количество сегментов для таблицы невелико по сравнению с количеством рабочих узлов.first-replica: назначает задачи на основе порядка размещения фрагментов (реплик) для сегментов. Другими словами, запрос фрагмента для сегмента просто назначается рабочему узлу, у которого есть первая реплика этого сегмента. Этот метод позволяет получить надежные гарантии того, какие сегменты будут использоваться на каких узлах (т.е. более надежные гарантии наличия постоянной памяти). Этот параметр может быть установлен во время выполнения и действует на координаторе.
enable_non_colocated_router_query_pushdown (boolean)
Включает в планировщике маршрутизирование запросов, которые ссылаются на распределенные таблицы без привязки к ним. Обычно маршрутизирование включено только для запросов, которые ссылаются на совместно размещенные распределенные таблицы, поскольку не гарантируется, что целевые сегменты всегда будут находиться на одном и том же узле, например, после ребалансировки сегментов. По этой причине, хотя включение этого флага позволяет в некоторой степени оптимизировать запросы, которые ссылаются на распределенные таблицы без совместного размещения, не гарантируется, что тот же запрос будет работать после ребалансировки сегментов или изменения количества сегментов в одной из этих распределенных таблиц. Значение по умолчанию off.
citus.binary_worker_copy_format (boolean)
Использовать формат бинарной копии для передачи промежуточных данных между рабочими узлами. При объединении больших таблиц Citus может потребоваться динамическое перераспределение и перетасовка данных между разными рабочими узлами. Для Postgres 13 и более поздних версий значение по умолчанию равно false, что означает, что для передачи этих данных используется кодирование текста. Для Postgres 14 и более поздних версий значение по умолчанию равно true. Установка значения true для этого параметра означает, что база данных должна использовать бинарный формат PostgreSQL для передачи данных. Этот параметр действует для рабочих узлов и должен быть изменен в файле postgresql.conf. После редактирования конфигурационного файла пользователи могут отправить сигнал SIGHUP или перезапустить сервер, чтобы это изменение вступило в силу.
citus.max_intermediate_result_size (integer)
Максимальный размер в КБ промежуточных результатов для CTE, которые невозможно отправить на рабочие узлы для выполнения, и для сложных подзапросов. Значение по умолчанию равно 1 ГБ, а значение -1 означает отсутствие ограничений. Запросы, превышающие это ограничение, будут отменены и выдадут сообщение об ошибке.
citus.enable_ddl_propagation (boolean)
Указывает, следует ли автоматически распространять изменения DDL от координатора на все рабочие узлы. Значение по умолчанию - true. Поскольку для некоторых изменений схемы требуется блокировка исключительного доступа к таблицам, а автоматическое распространение применяется ко всем рабочим узлам последовательно, это может временно снизить эффективность работы кластера Citus. Параметр может быть отключен.
citus.enable_local_reference_table_foreign_keys (boolean)
Этот параметр, включенный по умолчанию, позволяет создавать внешние ключи между справочными и локальными таблицами. Чтобы функция работала, узел-координатор должен зарегистрировать сам себя, используя функцию citus_add_node. Обратите внимание, что внешние ключи между справочными и локальными таблицами имеют небольшую стоимость. Когда создается внешний ключ, Citus должен добавить простую таблицу в метаданные Citus и отслеживать ее в таблице pg_dist_partition. Локальные таблицы, добавляемые в метаданные, наследуют те же ограничения, что и справочные таблицы. Если удаляются внешние ключи, Citus автоматически удалит такие локальные таблицы из метаданных, что устранит подобные ограничения для этих таблиц.
citus.enable_change_data_capture (boolean)
Этот параметр, отключенный по умолчанию, определяет будет ли Citus изменять логические декодеры wal2json и pgoutput для работы с распределенными таблицами. В частности, он переписывает имена сегментов (например, foo_102027) в выходных данных декодера в базовые имена распределенных таблиц (например, foo). Это также позволяет избежать публикации повторяющихся событий во время изоляции клиента и операций разделения/перемещения/ребалансировки сегментов.
citus.enable_schema_based_sharding (boolean)
Если для параметра установлено значение ON, все созданные схемы будут распространяться по умолчанию. Распределенные схемы автоматически связываются с отдельными группами совместного размещения, так что таблицы, созданные в этих схемах, будут автоматически преобразованы в совместно размещенные распределенные таблицы без ключа сегмента. Эту настройку можно изменить для отдельных сеансов.
citus.all_modifications_commutative (boolean)
Citus применяет правила коммутативности и устанавливает соответствующие блокировки для операций изменения, чтобы гарантировать корректность поведения. Например, предполагается, что оператор INSERT взаимодействует с другим оператором INSERT, но не с оператором UPDATE или DELETE. Аналогично, предполагается, что оператор UPDATE или DELETE не взаимодействует с другим оператором UPDATE или DELETE. Это означает, что для обновления и удаления требуется, чтобы Citus получал более надежные блокировки. Если есть инструкции UPDATE, которые являются коммутативными для вставок или других обновлений, можно ослабить эти предположения о коммутативности, установив для этого параметра значение true. Когда для этого параметра установлено значение true, все команды считаются коммутативными и требуют общей блокировки, что может повысить общую пропускную способность. Этот параметр может быть установлен во время выполнения и действует на координаторе.
citus.multi_task_query_log_level (enum)
Устанавливает уровень ведения журнала для любого запроса, который генерирует более одной задачи (т.е. который затрагивает более одного сегмента). Это полезно во время миграции мультитенантного приложения, так как можно выбрать ошибку или предупреждение для таких запросов, найти их и добавить к ним фильтр tenant_id. Этот параметр может быть установлен во время выполнения и действует на координаторе. Значение по умолчанию для этого параметра равно off. Поддерживаемые значения для этого перечисления следующие:
off: Отключить ведение журнала любых запросов, которые генерируют несколько задач (т.е. охватывают несколько сегментов);debug: Регистрирует запросы с уровнеDEBUG;log: Регистрирует запросы с уровнемLOG. В строке журнала будет указан выполненный SQL-запрос;notice: Регистрирует запросы с уровнемNOTICE;warning: Регистрирует запросы с уровнемWARNING;error: Регистрирует запросы с уровнемERROR. Обратите внимание, что может быть полезно использоватьerrorво время тестирования разработки и более низкий уровень ведения журнала, напримерlog, во время фактического производственного развертывания.
При выборе log в журналах базы данных будут отображаться многозадачные запросы, а сам запрос будет отображаться после тега STATEMENT:
LOG: multi-task query about to be executed
HINT: Queries are split to multiple tasks if they have to be split into several queries on the workers.
STATEMENT: select * from foo;
citus.propagate_set_commands (enum)
Определяет, какие команды SET передаются от координатора к рабочим узлам. Значение по умолчанию для этого параметра равно none. Поддерживаемые значения:
none: командыSETне передаются;local: распространяются только командыSET LOCAL.
citus.enable_repartition_joins (boolean)
Обычно попытка выполнить повторное объединение с помощью адаптивного исполнителя завершается сообщением об ошибке. Однако, если для параметра citus.enable_repartition_joins установить значение true, то Citus сможет выполнить соединение. Значение по умолчанию - false.
citus.enable_repartitioned_insert_select (boolean)
По умолчанию оператор INSERT INTO ... SELECT, который не может быть запущен, попытается повторно разделить строки из инструкции SELECT и передать их между рабочими узлами для вставки. Однако, если в целевой таблице слишком много сегментов, повторное разбиение, вероятно, не будет эффективным. Слишком велики затраты на обработку интервалов разбиения на сегменты при определении способа разбиения результатов. Перераспределение можно отключить вручную, установив для параметра citus.enable_repartitioned_insert_select значение false.
citus.enable_binary_protocol (boolean)
Установка для этого параметра значения true указывает узлу-координатору использовать бинарный формат PostgreSQL (если применимо) для передачи данных между рабочими узлами. Некоторые типы столбцов не поддерживают бинарную сериализацию. Включение этого параметра в основном полезно, когда узлы должны возвращать большие объемы данных. Например, когда запрашивается много строк, в строках много столбцов или используются большие типы, такие как hll, из расширения postgresql-hll. Значение по умолчанию равно true. Если установлено значение false, все результаты кодируются и передаются в текстовом формате.
citus.max_shared_pool_size (integer)
Указывает максимальное количество подключений, которое узлу-координатору разрешено устанавливать для каждого рабочего узла во всех одновременных сеансах. PostgreSQL должен выделять фиксированные ресурсы для каждого подключения, и этот параметр помогает снизить нагрузку на рабочие узлы при подключении. Без регулирования подключения каждый запрос с несколькими сегментами создает соединения для каждого рабочего узла пропорционально количеству сегментов, к которым он обращается. Одновременное выполнение десятков многосегментных запросов может легко привести к превышению предела max_connections рабочих узлов, что приведет к сбою выполнения запросов. По умолчанию это значение автоматически устанавливается равным значению max_connections самого координатора, которое не обязательно совпадает с значением для рабочих узлов (см. примечание ниже). Значение -1 отключает регулирование.
Существуют определенные операции, которые не подчиняются citus.max_shared_pool_size, что наиболее важно для перераспределения соединений. Вот почему может быть разумным увеличить значение max_connections для рабочих узлов немного выше, чем значение max_connections для координатора. Это дает дополнительное пространство для подключений, необходимых для запросов на перераспределение в рабочих системах.
citus.max_adaptive_executor_pool_size (integer)
В то время как citus.max_shared_pool_size ограничивает рабочие соединения во всех сеансах, max_adaptive_executor_pool_size ограничивает рабочие соединения только в текущем сеансе. Это полезно для:
- Предотвращения доступа одного серверного сеанса ко всем рабочим ресурсам.
- Обеспечения управления приоритетами: назначьте сеансам с низким приоритетом низкое значение
max_adaptive_executor_pool_size, а сеансам с высоким приоритетом - более высокие значения.
Значение по умолчанию - 16.
citus.executor_slow_start_interval (integer)
Время ожидания в миллисекундах между открытием соединений с одним и тем же рабочим узлом. Когда отдельные задачи запроса с несколькими сегментами занимают очень мало времени, их часто можно выполнить за одно (часто уже кешированное) подключение. Чтобы избежать избыточного открытия дополнительных подключений, исполнитель ожидает между попытками подключения заданное количество миллисекунд. В конце интервала он увеличивает количество подключений, которые ему разрешено открыть в следующий раз. Для длинных запросов (которые занимают >500 мс) медленный запуск может увеличить задержку, но для коротких запросов это происходит быстрее. Значение по умолчанию - 10 мс.
citus.max_cached_conns_per_worker (integer)
Каждый сервер открывает соединения с рабочими узлами для запроса сегментов. В конце транзакции настроенное количество подключений остается открытым для ускорения выполнения последующих команд. Увеличение этого значения уменьшит задержку запросов с несколькими сегментами, но также увеличит нагрузку на рабочие узлы. Значение по умолчанию равно 1. Большее значение, например 2, может быть полезно для кластеров, использующих небольшое количество одновременных сеансов, но заходить намного дальше нецелесообразно (например, 16 это слишком много).
citus.force_max_query_parallelization (boolean)
Имитирует устаревший и в настоящее время не существующий исполнитель в реальном времени. Используется для открытия как можно большего количества подключений для максимального распараллеливания запросов. Когда этот параметр включен, Citus заставит адаптивный исполнитель использовать как можно больше подключений при выполнении параллельного распределенного запроса. Если этот параметр выключен, исполнитель может выбрать меньшее количество подключений для оптимизации общей производительности выполнения запроса. Внутренне, установка этого значения в true приведет к использованию одного подключения для каждой задачи. Одно из мест, где это полезно, - это транзакция, первый запрос которой является легким и требует небольшого количества подключений, в то время как последующий подзапрос выиграет от большего количества подключений. Citus решает, сколько соединений использовать в транзакции, на основе первого подзапроса, который может ограничить другие запросы, если не используется параметр для предоставления подсказки.
BEGIN;
-- add this hint
SET citus.force_max_query_parallelization TO ON;
-- a lightweight query that doesn't require many connections
SELECT count(*) FROM table WHERE filter = x;
-- a query that benefits from more connections, and can obtain
-- them since we forced max parallelization above
SELECT ... very .. complex .. SQL;
COMMIT;
Значение по умолчанию для данного параметра - false
citus.explain_all_tasks (boolean)
По умолчанию Citus отображает выходные данные одной произвольной задачи при выполнении EXPLAIN в распределенном запросе. В большинстве случаев выходные данные explain будут одинаковыми для всех задач. Иногда некоторые задачи планируются по-другому или время их выполнения значительно увеличивается. В таких случаях может быть полезно включить этот параметр, после чего в выводе EXPLAIN будут отображаться все задачи. Это может привести к увеличению времени выполнения команды EXPLAIN.
citus.explain_analyze_sort_method (enum)
Определяет метод сортировки задач в выходных данных EXPLAIN ANALYZE. Значением по умолчанию для citus.explain_analyze_sort_method является execution-time. Поддерживаемые значения:
execution-time: сортировка по времени выполнения;taskId: сортировка по идентификатору задачи.
Ссылки на документацию разработчика
Дополнительно поставляемый модуль citus.