Архивирование и восстановление
Для архивирования и восстановления в СУБД Pangolin используется система резервного копирования и репликации. Она включает в себя утилиты для резервного копирования и восстановления (например, pg_probackup), а также для потоковой и логической репликации.
Система резервного копирования СУБД Pangolin позволяет защитить данные от потери в случае отказа оборудования, ошибок оператора, ошибок приложений, проблем сервисных служб, а также используется для целей аудита.
Функции системы:
- резервное копирование и восстановление данных СУБД Pangolin;
- создание полной резервной копии по расписанию;
- снятие резервных копий с любого сервера кластера высокой доступности;
- возможность хранения метаданных на отдельном служебном сервере;
- дедупликация;
- восстановление состояния на определенный момент времени (в соответствии с политиками хранения копий);
- обеспечение соответствия нефункциональным требованиям к системам уровня Mission critical.
В этом разделе рассматриваются следующие сценарии восстановления из резервной копии:
- Полное восстановление кластера. Например, кластер полностью неработоспособен и требуется восстановление из последней резервной копии всего кластера.
- Восстановление на определенный момент времени. Например, изменения в БД привели к сбою или потере данных. БД находится в рабочем состоянии, но требуется восстановление данных на определенный момент времени до сбоя. Также используется при миграции, для тестирования и аудита.
- Создание резервного сервера. Например, в результате сбоя на предыдущем резервном сервере БД на нем оказывается недоступна, требуется восстановление из резервной копии.
В качестве сетевой централизованной системы хранения резервных копий используется служебная база данных (далее — «Каталог»). Интеграция с Каталогом позволяет выполнять резервное копирование экземпляров СУБД и связанных с ними файлов журналов записи с опережением (файлы Write Ahead Log, WAL).
Резервное копирование файлов WAL обеспечивает целостность данных СУБД Pangolin. Такая резервная копия позволяет использовать таблицы базы данных во время сеанса без каких-либо ограничений.
Резервное копирование с ведомого сервера кластера производится в автоматизированном режиме с помощью клиентского приложения (далее — «Агент»). Выполняется либо снятие полной резервной копии, либо архива файлов WAL, накопившихся со времени последней резервной копии.
Восстановление инициируется пользователем и предполагает ручное указание параметров восстановления. СУБД потребуется учетная запись с правами на создание резервных копий: отдельная роль с минимальными правами, необходимыми для выбранной стратегии копирования. Управление функциями резервного копирования Pangolin выполняется специалистами по резервному копированию.
Поддержка резервного копирования настраивается в конфигурационном файле custom_file.yml через параметр SRC (резервная копия системы).
Резервное копирование
СУБД Pangolin, как и все современные СУБД, поддерживает возможность резервного копирования для защиты данных от потери в случае отказа оборудования, ошибки администратора, ошибок приложений, проблем сервисных служб, а также для помощи при миграции данных на новые сервера. Начиная с версии 4.1.0, добавлены улучшения, упрощающие мониторинг, управление и интеграцию с различными системами резервного копирования (СРК):
manage_backup.binвходит в пакет Manage Backup Tools и устанавливается в каталог/opt/pangolin-backup-tools-1.1.0/binна сервере с БД при интеграции Pangolin c СРК.pgse_backup– расширение, включающее набор представлений и процедур для организации и контроля мониторинга прохождения заданий резервного копирования;pg_probackup– утилита резервного копирования для подготовки и контроля архивов резервной копии.
Компонент Pangolin Backup Tools не является полноценной системой резервного копирования и управления резервными копиями. Предназначен для интеграции с внешними инструментами РК.
Главные функции резервного копирования:
- создание полной резервной копии данных;
- резервное копирование файлов WAL (Write Ahead Log) для обеспечения целостности данных;
- восстановление данных из резервной копии;
- восстановление на определенный момент времени (Point-in-Time Recovery или PITR);
- интеграция с системами резервного копирования.
Резервное копирование экземпляра СУБД Pangolin осуществляется Python-скриптом manage_backup.bin.
Этот скрипт автоматизирует вызовы стандартных функций управления резервным копированием Pangolin: pg_start_backup, pg_stop_backup.
При запуске скрипта создается отдельный процесс с подключением к libpq. Одновременно может быть выполнено только одно резервное копирование. Если существует старый сеанс резервного копирования, новое резервное копирование не будет запущено. Ошибки могут быть обнаружены в журнале postgres и в файле backup_manager.log в каталоге (по умолчанию /pgarclogs/[pangolin_<major_version>]) резервного копирования pg_probackup.
Пример:
/usr/local/pgsql/postgres_venv/bin/python3 manage_backup.py --host 127.0.0.1 -p 5432 -U user -d db -B <path_to_label_dir> --session-id=<SESS> start
# copy data from $PGDATA...
/usr/local/pgsql/postgres_venv/bin/python3 manage_backup.py --host 127.0.0.1 -p 5432 -U user -d db -B <path_to_label_dir> --session-id=<SESS> stop
Резервное копирование журналов предзаписи (WAL) в режиме онлайн осуществляется с помощью утилиты pg_probackup. Таким образом обеспечивается целостность резервной копии и возможность восстановления данных на любой момент времени (Point-in-Time Recovery, PITR).
Такая резервная копия позволяет активно использовать таблицы базы данных во время сеанса без каких-либо ограничений в использовании. Также при использовании СРК присутствует возможность выбирать между интерактивным и запланированным резервным копированием. Снятие полной резервной копии или архива WAL (журналов, накопившихся со времени последней резервной копии) может производиться в автоматизированном режиме с помощью клиентского приложения (агента) СРК с ведомого сервера кластера. Восстановление происходит по запросу вследствие инцидента либо запланированных работ и предполагает ручное указание параметров восстановления.
Более подробно о работе pg_probackup можно ознакомиться на страницах официальной документации проекта.
Важно!
Компонент Pangolin Backup Tools (Manage Backup Tools) разработан для интеграции с СРК HPE Data Protector. Работоспособность с другими СРК не гарантируется.
Доступные типы резервного копирования
Доступны следующие типы резервного копирования:
- полная резервная копия (включает все базы данных в экземпляре Pangolin);
- инкрементальное резервное копирование (режим ptrack). Подробнее в разделе ptrack. Инкрементальное резервное копирование;
- резервное копирование транзакций (включает только файлы WAL, заархивированные со времени предыдущего полного резервного копирования или резервного копирования транзакций. Данные резервной копии транзакции являются необходимыми для успешного восстановления кластера с применением непрерывного архивирования, поэтому цепочка архивированных WAL-файлов так же должна быть непрерывной. Для восстановления экземпляра сначала используется полная резервная копия и затем подается последовательность архивных WAL-файлов для применения на экземпляре, что позволяет восстановить копию на необходимый момент времени).
Создание полной резервной копии:
- инициализация процесса создания резервной копии агентом СРК или вручную;
- исполнение pre-exec-скриптов;
- копирование файлов БД;
- копирование архива WAL;
- исполнение post-exec-скриптов;
- завершение резервного копирования.
Восстановление данных
СУБД Pangolin поддерживает различные способы восстановления данных.
Перед восстановлением данных необходимо определить следующие аспекты процесса восстановления:
-
Область действия:
- Восстановление всего экземпляра – в таком случае восстановление производится отдельно на каждый сервер, после чего выполняется синхронизация с помощью Pangolin Manager.
- Восстановление ведомого сервера – в таком случае восстановление происходит из резервной копии на последний возможный момент времени.
-
Расположение восстанавливаемых данных:
- Исходное расположение.
- Другой путь на исходном клиенте.
- Другой клиент (на него тоже потребуется установить СУБД Pangolin).
-
Восстановление на определенный момент времени при условии наличия соответствующей цепочки восстановления (включая полный образ резервной копии и резервную копию соответствующих файлов WAL):
- На время последней резервной копии транзакции (откат к последнему возможному состоянию).
- На определенный момент времени по выбору (восстановление на момент времени с повтором).
- На момент выбранного успешного полного или резервного копирования транзакции.
На момент восстановления из резервной копии СУБД должна быть остановлена.
Мониторинг резервных копий
Функциональность мониторинга резервных копий реализована через расширение pgse_backup.
При установке расширения создаются следующие объекты:
- схема
backup; - представления для отображения истории и контроля резервных копий
backup.data_history,backup.wal_history,backup.history; - таблица для хранения настроек
backup.settings; - типы данных
backup.data_history_row_type,backup.wal_history_row_type; - функции для наполнения представлений
backup.read_data_history(),backup.read_wal_history(),backup.reset_history().
Для безопасного считывания файлов с историей (backup_state, wal_backup_state) используется функция СУБД Pangolin с атрибутом SECURITY DEFINER. Функция разрешает доступ к файлам с историей без прав суперпользователя, но в пределах строго фиксированного каталога, чтобы исключить доступ к чтению посторонних файлов. Директория, в которой хранятся файлы истории и предоставляется доступ через SECURITY DEFINER, задается через таблицу backup.settings. Данная таблица должна быть доступна только владельцу расширения (Администратору БД).
Информация в представлениях backup.data_history, backup.wal_history — результат работы функций backup.read_data_history и backup.read_wal_history. Данные функции через встроенную функцию PostgreSQL pg_read_file() читают файлы в формате JSON с историей резервного копирования, заполняемые утилитами manage_backup.bin и pg_probackup. Файлы с историей (backup_state, wal_backup_state) располагаются в каталоге резервного копирования (по умолчанию /pgarclogs/[pangolin_<major_version>] и указываются в таблице backup.settings).
postgres=# select * from backup.settings;
name | setting
------+---------------
dir | /pgarclogs/05
(1 row)
Итоговый результат сессии резервного копирования представляет собой сверку состояний из backup.data_history, backup.wal_history и доступен в backup.history, как на таблице ниже:
| Состояние сессии DATA | Состояние сессии WAL | Итоговое состояние |
|---|---|---|
| starting | * | starting |
| started | * | started |
| stopping | * | stopping |
| failed | * | failed |
| completed | Хотя бы одна сессия WAL началась после окончания сессии DATA, включает в свой интервал stop_walfile и имеет состояние completed | completed |
| completed | Хотя бы одна сессия WAL началась после окончания сессии DATA, включает в свой интервал stop_walfile и имеет состояние started | wal_backup_started |
| completed | Не найдена ни одна подходящая сессия WAL | waiting_for_wal_backup |
Ролевая модель
Для интеграции с СРК может потребоваться выделенная роль для проведения процедуры резервного копирования со следующими разрешениями:
BEGIN;
CREATE ROLE BACKUP_USER WITH LOGIN;
GRANT USAGE ON SCHEMA pg_catalog TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.current_setting(text) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_is_in_recovery() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_start_backup(text, boolean, boolean) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_stop_backup(boolean, boolean) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_create_restore_point(text) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_switch_wal() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_last_wal_replay_lsn() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current_snapshot() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_snapshot_xmax(txid_snapshot) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_control_checkpoint() TO BACKUP_USER;
COMMIT;
где BACKUP_USER – пользователь для возможности подключения к СУБД Pangolin со стороны СРК.
Резервное копирование конфигурации СУБД в различных ОС
ОС «Альт»
Создание резервных копий
Вне зависимости от того, где физически будет располагаться директория для сохранения копий, далее предполагается, что это директория /backup.
В простейшем случае скрипт для сохранения резервной копии выглядит следующим образом:
#!/bin/sh
tar -zcf /backup/home.tar.gz /home
tar -zcf /backup/etc.tar.gz /etc
Данный скрипт отображает основные принципы:
- сохранение и сжатие директории
/home(домашние директории пользователей) в отдельный файл; - сохранение и сжатие директории
/etc(общие системные настройки) в отдельный файл.
Использованные опции команды tar:
-z– сжать файл с использованием gzip;-c– создать новый архив;-f– использовать указанный файл.
Внимание!
Восстановление файлов из сжатого резервного архива будет невозможно, если хотя бы несколько байт в нем повреждены или если восстанавливаемый файл не находится в поврежденной области. Поэтому на такие носители как магнитная лента, резервные копии предпочтительнее записывать в не сжатом виде. Для этого необходимо указывать опцию
-zдля командыtar.`
Следующий скрипт реализует более широкие возможности для сохранения резервной копии:
#!/bin/sh
tar -zcvpf /backup/backup-`date '+%d-%B-%Y'`.tar.gz --directory / \
--exclude=proc --exclude=var --exclude=mnt --exclude=usr --exclude=backup .
В данном примере сохраняются не отдельные директории, а корневая директория /, исключая /proc, /var, /mnt, /usr и, конечно, /backup. Также к имени файла добавляется дата создания резервной копии.
Дополнительно к уже рассмотренным были задействованы опции команды tar:
-v– выводить список обработанных файлов;-p– сохранять информацию о правах доступа;--directory– директория для сохранения в архив;--exclude– исключить директорию при сохранении в архив.
Можно комбинировать оба предложенных варианта. Например, использовать первый скрипт ежедневно для ручного резервного копирования, а второй запускать по расписанию раз в неделю для полного сохранения.
Для резервного копирования на отдельный HDD по расписанию:
-
Подключите предварительно отформатированный HDD. Далее подразумевается, что это
/dev/hdb1, т.е. первый раздел на втором диске канала IDE1. -
Создайте точку монтирования:
cd /
mkdir backup -
Дополните скрипты для резервного копирования следующими строками:
#!/bin/sh
mount /dev/hdb1 /backup
#######################
# скрипт #
#######################
umount /backup -
Настройте запуск скрипта по расписанию. Используйте для этого программу
cron, предназначенную для выполнения действий по расписанию. Откройте файл/etc/crontabи запишите новое правило:#мин час число месяц день недели команда
0 1 * * 5 /usr/bin/full-backupЭто правило будет выполняться каждую пятницу в 1 час ночи. Для указания удобного времени запишите нужные значения в соответствующих колонках. В примере предполагается, что командой резервного копирования является
/usr/bin/full-backup. Замените эту команду на наименование реализованного скрипта.Результат работы будет отправлен пользователю
rootпо почте (при условии, что настроен SMTP-сервер).
Восстановление из резервных копий
Ниже приведены основные команды для восстановления файлов из архива резервной копии.
Перед извлечением файлов из резервной копии бывает необходимым просмотреть содержимое архива. Для этого укажите опцию -t команды tar. Команда для просмотра содержимого архива /backup/backup-07-March-2005.tar.gz:
tar -ztvpf /backup/backup-07-March-2005.tar.gz
Для извлечения файлов из архива предназначена опция -x команды tar. Пример восстановления всех файлов из архива /backup/backup-12-March-2005.tar.gz:
tar -zxvpf /backup/backup-12-March-2005.tar.gz
Для восстановления определенных файлов из архива укажите их имена после имени архива. Пример восстановления файлов home/alenitchev/adt/backup.xml и etc/sendmail.cf из архива /backup/backup-17-March-2005.tar.gz:
tar -zxvpf /backup/backup-17-March-2005.tar.gz home/alenitchev/adt/backup.xml \
etc/sendmail.cf
Перед восстановлением файла из резервной копии убедитесь, что восстанавливаемый файл не заменит более новый экземпляр.
РЕД ОС
Создание резервных копий fsbackup
fsbackup – утилита для создания инкрементного или полного резервного копирования отдельных файлов или целой файловой системы.
Для установки утилиты перейдите в сеанс пользователя root:
su -
Выполните команду:
dnf install fsbackup
После установки программа будет находиться по пути /usr/local/fsbackup/.
Примеры конфигурационных файлов и документация расположены в каталоге /usr/share/doc/fsbackup/.
Создание файла конфигурации для резервного копирования
В конфигурационном файле перечислены настройки, которые используются во время процесса резервного копирования. Так же там располагаются необходимые файлы или директории, которые впоследствии будут сохранены в резервной копии. Для создания файла конфигурации:
-
Скопируйте пример конфигурационного файла и отредактируйте его. Таким образом можно создавать столько конфигураций резервного копирования, сколько требуется.
Внимание!Обратите внимание, что каждый конфигурационный файл должен иметь уникальное имя, отличающееся от других конфигурационных файлов, а также отдельный существующий на момент запуска процесса резервного копирования каталог сохранения резервной копии.
cp /usr/share/doc/fsbackup/cfg_example /usr/local/fsbackup/<имя_конфигурационного_файла>
nano /usr/local/fsbackup/<имя_конфигурационного_файла>В скопированном примере конфигурационного файла все поля имеют пояснения на русском языке. Далее приведены обязательные настройки, которые необходимо отредактировать:
$cfg_backup_name– имя файла резервной копии;$cfg_save_old_backup– сохранение старой резервной копии. По умолчанию старая копия помещается в папкуOLDвнутри директории резервной копии;$cfg_backup_style– выбор метода резервного копирования. По умолчанию установлен инкрементный метод;$cfg_local_path– директория хранения резервной копии;$cfg_cache_dir– директория хранения хеша резервной копии. Не должна совпадать с директорией хранения самой резервной копии;__DATA__– пути к файлам и директориям, которые необходимо занести в резервную копию.
-
Для наглядности создайте еще один конфигурационный файл для папок пользователей:
cp /usr/local/fsbackup/cfg_example /usr/local/fsbackup/cfg_users
nano /usr/local/fsbackup/cfg_users -
Отредактируйте необходимые поля:
$cfg_backup_name = "users"; # имя бэкапа
$cfg_save_old_backup = 0; # не сохранять бэкап
$cfg_backup_style = "full_backup"; # создание полного бэкапа
$cfg_local_path = "/mnt/personal"; # директория создания бэкапов
$cfg_cache_dir = "/srv/cache"; # директория для помещения текущих хешей
# Список файлов и условий для помещения в бэкап
__DATA__
/srv/user1
/srv/user2
Скрипт создания резервной копии
Далее отредактируйте скрипт создания резервной копии. Создайте для каждого конфигурационного файла свой файл создания резервной копии путем копирования исходного скрипта. Данный файл также имеет пояснения на русском языке:
cp /usr/local/fsbackup/create_backup.sh /usr/local/fsbackup/create_backup_users.sh
Отредактируйте необходимые параметры:
nano /usr/local/fsbackup/create_backup_users.sh
Самым главным параметром является config_files, в котором перечислены необходимые конфигурационные файлы.
config_files="cfg_users" # укажите необходимые конфигурации файлы для создания по ним бэкапа
Внимание!
Перед запуском резервной копии убедитесь, что скрипт запуска и конфигурационный файл расположены в одной папке с perl-скриптом
fsbackup.pl.
Скрипт полного восстановления из резервной копии
Для полного восстановления скопируйте и отредактируйте скрипт fsrestore.sh, расположенный в каталоге usr/local/fsbackup/scripts/.
cp /usr/local/fsbackup/scripts/fsrestore.sh /usr/local/fsbackup/scripts/fsrestore_users.sh
nano /usr/local/fsbackup/scripts/fsrestore_users.sh
backup_name="users" # имя резервной копии
backup_path="/mnt/personal/" # директория где находится резервная копия
restore_path="/ " # корневая директория куда будут помещены данные, установите /, т.к распаковка происходит с полными путями
Для каждой конфигурации создайте свой скрипт восстановления аналогичным образом.
Создание резервной копии
Команда дополнения архива новыми файлами или создания резервной копии:
/usr/local/fsbackup/create_backup_users.sh
Восстановление резервной копии
Для восстановления отдельных файлов из резервной копии воспользуйтесь утилитой tar:
tar -tf <имя архива>– просмотр директорий в архиве без его распаковки;tar -xf <имя архива> <имя файла> <имя файла>– разархивирование одного или нескольких файлов.
В текущем примере архив резервной копии находится по пути /mnt/personal.
После распаковки переместите извлеченный файл в нужный каталог.
Чтобы восстановить все файлы из резервной копии, воспользуйтесь ранее созданным скриптом fsrestore_<...>.sh. Помните, что файлы, созданные после процедуры резервной копии, останутся, а удаленные или измененные файлы вернутся в исходное состояние. В текущем примере скрипт восстановления назван fsrestore_users.sh:
/usr/local/fsbackup/scripts/fsrestore_users.sh
Добавление/удаление директорий в резервную копию
Для добавления новых директорий в резервную копию отредактируйте файл его создания.
Например, добавьте пользователя user3 в резервную копию users. Для этого добавьте папку с данными user3 в конец секции __DATA__. Для удаления директорий из резервной копии удалите путь к директории из файла:
nano /usr/local/fsbackup/create_backup_users.sh
… __DATA__
/srv/user1
/srv/user2
/srv/user3
Теперь каталоги трех пользователей будут добавляться в резервную копию users.
Автоматизированное создание резервных копий
Для автоматизации можно использовать cron. Отредактируйте файл /etc/crontab с помощью текстового редактора:
nano /etc/crontab
Или специальной команды:
crontab -e
Например, для создания еженедельной резервной копии общего каталога пользователей в 23:30 по субботам впишите следующую строку в конец файла:
30 23 * * 6 root /usr/local/fsbackup/create_backup_users.sh
Astra Linux
DD
Инструмент командной строки dd является самым простым средством полного резервного копирования.
Инструмент автоматически устанавливается при установке ОС и никаких настроек не требует.
Недостатками инструмента являются:
- избыточность копируемых данных (так как копируется пустое, не занятое файлами, пространство);
- необходимость размещения копии на отличном от копируемого физическом устройстве;
- необходимость использования дополнительных средств для копирования по сети.
Однако, команда dd весьма удобна для полного копирования дисков или дисковых разделов при переносе системы на новый диск, а также широко применяется для создания загрузочных накопителей из файлов с образами.
Команда для копирования системного раздела диска (обычно при установке ОС с параметрами «по умолчанию» это раздел /dev/sda1) в файл с условным названием /media/not-sda-device/sda.bin:
sudo dd if=/dev/sda1 of=/media/not-sda1-device/sda1.bin bs=4096
| Параметр | Значение |
|---|---|
| f | Имя входного файла. Если пропущено, то читает стандартный ввод |
| of | Имя выходного файла. Если пропущено, то пишет в стандартный вывод |
| bs | Размер блока. Увеличение размера блока может повысить скорость копирования. Можно выбрать размер блока равным или кратным размеру блока копируемого устройства. Узнать размер блока дискового устройства с файловой системой Ext2/Ext3/Ext4 можно командой tune2fs -l /dev/sda1 grep Block |
С учетом возможности перенаправления стандартного ввода/вывода команда dd позволяет применять для копирования алгоритмы сжатия или защитного преобразования:
sudo dd if=/dev/sda1 bs=4096 | sudo gzip > /media/not-sda1-device/sda1.bin.gz
Команда для восстановления системного раздела диска (для этого потребуется загрузиться с отдельного диска, и примонтировать носитель, на котором был размещен файл с образом):
sudo dd if=/media/mountpoint/sda1.bin of=/dev/sda1 bs=4096
Или, для сжатого файла:
sudo gzip -dc /media/not-sda1-device/sda1.bin.gz | sudo dd of=/dev/sda1 bs=4096
Полученный с помощью инструмента dd файл с образом дискового раздела (не подвергнутый сжатию или защитному преобразованию) может быть примонтирован и использоваться как обычный дисковый раздел:
sudo mount -o loop /media/mountpoint/sda1.bin /mnt
TAR
Инструмент командной строки tar в основном применяется для копирования данных в пределах одного компьютера.
Позволяет скопировать дерево файлов в один файл архива. Позволяет сжать копии с помощью программ архивации.
Для копирования с использованием сети требуется применение дополнительных средств.
Создание архива
Команда для копирования полного дерева файловых объектов в архив с условным названием /backup.tar.gz (файл архива располагается в той же файловой системе):
sudo tar --xattrs --acls -czf backup.tar.gz \
--exclude=/proc --exclude=/lost+found \
--exclude=/backup.tar.gz \
--exclude=/mnt \
--exclude=/sys \
--exclude=/parsecfs \
/
Значения параметров:
| Параметр | Значение |
|---|---|
| --xattrs | Включить поддержку расширенных атрибутов файлов |
| --- | --- |
| --acls | Включить поддержку списков контроля доступа (POSIX Access Control Lists, ACL) |
| -czf | Составной параметр: -c - создать новый архив -z - пропускать данные перед записью в архив через программу сжатия gzip -f - указывает на то, что следующим параметром является имя файла архива (в данном примере — файл backup.tar.gz) |
| --exclude | Указывает, какие файлы и каталоги копировать не нужно. В частности, обязательно: исключить из копирования необходимо сам файл архива; исключить из копирования виртуальную файловую систему /parsecfs/ Дополнительно можно исключить: /tmp /var/lib/samba/private/msg.sock/ /var/lib/samba/winbindd_privileged/pipe /var/lib/sss/pipes/ |
| / | Последним параметром указывается каталог, который нужно копировать |
Создание архива на удаленном компьютере
Инструмент tar не содержит собственных средств для работы через сеть, однако может использоваться совместно с другими инструментами для сетевой работы.
Типичным примерами таких инструментов являются netcat (nc) и tar.
Инструмент Netcat (nc)
Инструмент nc разработан как средство общего назначения для передачи данных через сеть, и позволяет установить простое соединение между двумя машинами.
Инструмент nc предоставляется пакетом netcat и может быть установлен командой:
sudo apt install netcat
Сценарий применения (опции архиватора tar для простоты не указаны):
-
Запустите инструмент
ncна принимающей машине. Инструмент принимает данные (опция-l) через сетевой порт номер 1024 (опция-p 1024) и записывает полученные данные в файлbackup.tar.gz. Команда:nc -l -p {Порт} > backup.tar.gz -
На передающей машине запустите архиватор
tarбез указания целевого файла архива. Архиватор при этом выводит создаваемый архив в стандартный вывод (stdout). Stdout с помощью механизма перенаправления вывода командной строки (pipe, «труба», задается символом «вертикальная черта») перенаправляется инструментуnc. Инструментncпередает полученные данные в принимающую машину.Параметр
-q 0указывает закрыть соединение после завершения входного потока данных. Команда:tar -cvpz / | nc -q 0 {IP-адрес} {Порт}
С помощью SSH
Более безопасным вариантом является использование SSH. Пример команды:
sudo tar -cvpz / | ssh {IP-адрес} "( cat > ssh_backup.tar.gz )"
В примере:
- Инструмент
tarприменяется без указания целевого файла, и выводит поток данных в стандартный вывод (stdout). - Стандартный вывод перенаправляется в SSH.
- SSH подключается к удаленному компьютеру и выполняет на удаленном компьютере команду записи в файл.
Восстановление
Пример команд для восстановления файлов из архива:
echo 1 | sudo tee /parsecfs/unsecure_setxattr
sudo /usr/sbin/execaps -c 0x1000 -- tar --xattrs --xattrs-include=security.{PDPL,AUDIT,DEF_AUDIT} --acls -xzf backup.tar.gz -C /
echo 0 | sudo tee /parsecfs/unsecure_setxattr
Значения команд и параметров:
| Команда/Параметр | Описание |
|---|---|
| echo 1 \ sudo tee /parsecfs/unsecure_setxattr | Команда, устанавливающая для параметра защиты файловой системы /parsecfs/unsecure_setxattr значение 1, разрешающее применять мандатную привилегию PARSEC_CAP_UNSAFE_SETXATTR |
| /usr/bin/execaps -c 0x1000 | Команда, устанавливающая для команды разархивирования мандатную привилегию PARSEC_CAP_UNSAFE_SETXATTR, позволяющую устанавливать мандатные атрибуты объектов файловой системы без учета мандатных атрибутов родительского объекта-контейнера. Для действия этой этой мандатной привилегии параметр /parsecfs/unsecure_setxattr должен быть установлен в значение 1 |
| -- | Параметр указывает, что следующим параметром является выполняемая команда |
| tar | Команда разархивирования, которая будет выполнена с мандатной привилегией PARSEC_CAP_UNSAFE_SETXATTR |
| --xattrs | Включить поддержку расширенных атрибутов файлов |
| --xattrs-include=security.{PDPL,AUDIT,DEF_AUDIT} | Задает шаблоны включаемых расширенных атрибутов |
| --acls | Включить поддержку списков контроля доступа (POSIX Access Control Lists, ACL) |
| -xzf | Составная команда: -x - извлечь файлы из архива -z - распаковать извлекаемые файлы с помощью программы gunzip -f - указывает на то, что следующим параметров является имя файла архива (в данном примере backup.tar.gz) |
| -C / | Указывает, что перед началом разархивирования нужно перейти в корневой каталог (каталог /). Это необходимо сделать для правильного восстановления первоначального размещения файлов, так как при копировании полные имена файлов были сохранены в архиве без начального символа / |
| echo 0 \ sudo tee /parsecfs/unsecure_setxattr | Команда восстанавливает запрет на применение мандатной привилегии PARSEC_CAP_UNSAFE_SETXATTR (настройка ОС Astra Linux Special Edition по умолчанию) |
Восстановление атрибутов файлов
Если восстановление файлов из архива производится не в том экземпляре ОС, в котором было сделано архивирование (например, восстановление производится из ОС, загруженной с LiveCD), то необходимо использовать дополнительную опцию --numeric-owner, запрещающую перепроверять имена пользователей/групп и изменять их числовые идентификаторы в соответствии с действующими в используемой системе.
Восстановление загрузчика GRUB и параметров монтирования
После переноса с помощью tar или rsync содержимого загрузочного диска на другой диск требуется восстановить системный загрузчик grub. Для этого:
-
Примонтируйте восстанавливаемый диск, например в каталог
/mnt. -
Выполните следующие команды, указав при выполнении команды
dpkg-reconfigure grub-pcдиск, с которого должна выполняться загрузка:sudo -s
for f in dev dev/pts proc sys ; do mount --bind /$f /mnt/$f ; done
chroot /mnt
dpkg-reconfigure grub-pc
exit
exit -
При переносе системы на новый диск (дисковый раздел), исправьте таблицу монтирования в файле
/etc/fstab, указав данные для идентификации нового диска. Обычно для идентификации используется параметр UUID, узнать который можно выполнив команду:sudo blkid
Восстановление через сеть
С помощью netcat (nc)
Выполните шаги:
-
На компьютере, на котором восстанавливаются данные запустите инструмент
nc. Инструмент будет получать данные через порт номер1024и передавать полученные данные архиваторуtarдля распаковки. Архиваторtarпри этом получает данные через стандартный ввод (stdin) (параметрfс указанием тире вместо имени файла). Параметр-C /tmpуказывает каталог, в который будут распаковываться полученные данные (/tmp). Команда:nc -l 1024 | tar -xvpzf - -C /tmp -
На компьютере, на котором хранится архив, передайте архив через стандартный ввод-вывод инструменту
nc. Команда:cat backup.tar.gz | nc -q 0 {IP-адрес} {Порт}
С помощью SSH
Пример команды:
cat ssh_backup.tar.gz | ssh {IP-адрес} "tar -xvpzf - -C /tmp"
Сценарий проверки корректности работы с мандатными атрибутами
Details
Пример сценария копирования и восстановления с сохранением мандатных атрибутов и проверкой корректности восстановления:
# !/bin/bash
dir="/test_dir"
mac_cat_file="/etc/parsec/mac_categories"
mac_lev_file="/etc/parsec/mac_levels"
secure="/parsecfs/unsecure_setxattr"
u=`id -u -n`
red=$(tput setaf 1)
green=$(tput setaf 2)
coff=$(tput sgr0)
test_result="${green}TEST PASS${coff}\n"
mv $mac_cat_file $mac_cat_file.bak
> $mac_cat_file
usercat -a 10 cat_10
mv $mac_lev_file $mac_lev_file.bak
> $mac_lev_file
for i in 0 1 2 3; do
userlev -a $i Уровень_$i
done
mkdir $dir
pdpl-file 3:0:10:ccnr $dir
for l in lvl1 lvl2 lvl3; do
mkdir $dir/$l
done
for num in 1 2 3; do
pdpl-file $num:0:10:ccnr $dir/lvl$num
done
for d in lvl1 lvl2 lvl3; do
for f in 1 2 3; do
touch $dir/$d/file$f
done
done
pdpl-file 1:0:0 $dir/lvl1/file2
pdpl-file 1:0:10 $dir/lvl1/file3
pdpl-file 1:0:10 $dir/lvl2/file2
pdpl-file 2:0:10 $dir/lvl2/file3
pdpl-file 1:0:10 $dir/lvl3/file1
pdpl-file 2:0:10 $dir/lvl3/file2
pdpl-file 3:0:10 $dir/lvl3/file3
setfaud -R -m o:ocx:ocx $dir
setfaud -d -m o:udn:udn $dir/lvl1
setfacl -R -m u:$u:rwx $dir
tar --xattrs --acls -cvzf $dir.tar $dir &> /dev/null
rm -r $dir
echo 1 > $secure
execaps -c 0x1000 -- tar --xattrs --acls --xattrs-include=security.{PDPL,AUDIT,DEF_AUDIT} \
-xvf $dir.tar -C / &> /dev/null
echo 0 > $secure
pdp-ls -Md $dir | grep "Уровень_3:Низкий:cat_10:ccnr" &> /dev/null
check_dir=$(echo $?)
if [ $check_dir == 0 ]; then
printf "${green}PDPL on dir restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!\n${coff}"
printf "${red}PDPL on dir not restored!${coff}\n"
fi
pdp-ls -Md $dir/lvl1 | grep "Уровень_1:Низкий:cat_10:ccnr" &> /dev/null
check_sdir1=$(echo $?)
if [ $check_sdir1 == 0 ]; then
printf "${green}PDPL on subdir 1 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subdir 1 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir/lvl2 | grep "Уровень_2:Низкий:cat_10:ccnr" &> /dev/null
check_sdir2=$(echo $?)
if [ $check_sdir2 == 0 ]; then
printf "${green}PDPL on subdir 2 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subdir 2 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir/lvl3 | grep "Уровень_3:Низкий:cat_10:ccnr" &> /dev/null
check_sdir3=$(echo $?)
if [ $check_sdir3 == 0 ]; then
printf "${green}PDPL on subdir 3 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subdir 3 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir/lvl1/file3 | grep "Уровень_1:Низкий:cat_10" &> /dev/null
check_file1=$(echo $?)
if [ $check_file1 == 0 ]; then
printf "${green}PDPL on subfile 1 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subfile 1 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir/lvl2/file3 | grep "Уровень_2:Низкий:cat_10" &> /dev/null
check_file2=$(echo $?)
if [ $check_file2 == 0 ]; then
printf "${green}PDPL on subfile 2 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subfile 2 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir/lvl3/file3 | grep "Уровень_3:Низкий:cat_10" &> /dev/null
check_file3=$(echo $?)
if [ $check_file3 == 0 ]; then
printf "${green}PDPL on subfile 3 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subfile 3 lvl not restored!${coff}\n"
fi
getfaud $dir 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_dir_aud=$(echo $?)
if [ $check_dir_aud == 0 ]; then
printf "${green}AUDIT on dir restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on dir not restored!${coff}\n"
fi
getfaud $dir/lvl1 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sdir1_aud=$(echo $?)
if [ $check_sdir1_aud == 0 ]; then
printf "${green}AUDIT on subdir lvl1 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subdir lvl1 not restored!${coff}\n"
fi
getfaud $dir/lvl2 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sdir2_aud=$(echo $?)
if [ $check_sdir2_aud == 0 ]; then
printf "${green}AUDIT on subdir lvl2 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subdir lvl2 not restored!${coff}\n"
fi
getfaud $dir/lvl3 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sdir3_aud=$(echo $?)
if [ $check_sdir3_aud == 0 ]; then
printf "${green}AUDIT on subdir lvl3 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subdir lvl3 not restored!${coff}\n"
fi
getfaud $dir/lvl1 2> /dev/null | grep o:udn:udn &> /dev/null
check_def_aud=$(echo $?)
if [ $check_def_aud == 0 ]; then
printf "${green}AUDIT DEFAULT restored normaly${coff}\n"
else
printf "${red}AUDIT DEFAULT not restored!${coff}\n"
fi
getfaud $dir/lvl1/file3 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sfile1_aud=$(echo $?)
if [ $check_sfile1_aud == 0 ]; then
printf "${green}AUDIT on subfile lvl1 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subfile lvl1 not restored!${coff}\n"
fi
getfaud $dir/lvl2/file3 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sfile2_aud=$(echo $?)
if [ $check_sfile2_aud == 0 ]; then
printf "${green}AUDIT on subfile lvl2 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subfile lvl2 not restored!${coff}\n"
fi
getfaud $dir/lvl3/file3 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sfile3_aud=$(echo $?)
if [ $check_sfile3_aud == 0 ]; then
printf "${green}AUDIT on subfile lvl3 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subfile lvl3 not restored!${coff}\n"
fi
getfacl $dir 2> /dev/null | grep user:$u:rwx &> /dev/null
check_dir_acl=$(echo $?)
if [ $check_dir_acl == 0 ]; then
printf "${green}ACL on dir restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on dir not restored!${coff}\n"
fi
getfacl $dir/lvl1 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sdir1_acl=$(echo $?)
if [ $check_sdir1_acl == 0 ]; then
printf "${green}ACL on subdir lvl1 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subdir lvl1 not restored!${coff}\n"
fi
getfacl $dir/lvl2 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sdir2_acl=$(echo $?)
if [ $check_sdir2_acl == 0 ]; then
printf "${green}ACL on subdir lvl2 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subdir lvl2 not restored!${coff}\n"
fi
getfacl $dir/lvl3 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sdir3_acl=$(echo $?)
if [ $check_sdir3_acl == 0 ]; then
printf "${green}ACL on subdir lvl3 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subdir lvl3 not restored!${coff}\n"
fi
getfacl $dir/lvl1/file3 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sfile1_acl=$(echo $?)
if [ $check_sfile1_acl == 0 ]; then
printf "${green}ACL on subfile lvl1 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subfile lvl1 not restored!${coff}\n"
fi
getfacl $dir/lvl2/file3 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sfile2_acl=$(echo $?)
if [ $check_sfile2_acl == 0 ]; then
printf "${green}ACL on subfile lvl2 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subfile lvl2 not restored!${coff}\n"
fi
getfacl $dir/lvl3/file3 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sfile3_acl=$(echo $?)
if [ $check_sfile3_acl == 0 ]; then
printf "${green}ACL on subfile lvl3 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subfile lvl3 not restored!${coff}\n"
fi
rm -r $dir*
mv $mac_cat_file.bak $mac_cat_file
mv $mac_lev_file.bak $mac_lev_file
echo
printf "$test_result"
exit 0
RSYNC
Инструмент rsync является наиболее сложным инструментом и включает в свой состав инструмент rsync и службу rsync.service, обеспечивающую удаленный доступ для копирования.
Может применяться для локального и удаленного копирования.
В отличие от tar, копирует дерево файлов в дерево файлов и не позволяет сжать полученные копии.
Пакет не устанавливается по умолчанию при установке ОС, однако входит в зависимости многих других пакетов (например, системы контроля версий git и subversion, система резервного копирования luckyBackup, система контейнерной изоляции уровня ОС LXC), поэтому может быть установлен автоматически при их установке.
Инструмент обеспечивает очень много возможностей, в том числе:
- распараллеливание операций при копировании;
- сжатие при копировании по сети;
- инкрементное копирование, в том числе копирование только измененных частей файлов;
- копирование удалений файлов;
- возобновление прерванного копирования;
- сохранение нескольких «снимков».
При автоматической установке служба rsync.service также устанавливается, но автоматически не запускается и требует настройки.
Несмотря на отсутствие запущенной службы rsync.service удаленное копирование по сети можно выполнять через SSH.
Создание копии
По аналогии с примером для инструмента tar, пример локального копирования корневой файловой системы в каталог /backup:
sudo /usr/sbin/execaps -c 0x1000 -- sudo rsync -a --xattrs --acls --exclude=/proc --exclude=/lost+found --exclude=/backup --exclude=/mnt --exclude=/sys --exclude=/parsecfs / /backup
Значения параметров:
| Параметр | Значение |
|---|---|
-a | Параметр, задающий режим архивирования. Подразумевает следующие параметры: -r - рекурсивное копирование дерева файлов -l - копировать симлинки как симлинки -p - сохранять права доступа -t - сохранять время модификации -g - сохранять группы -o - сохранять владельцев -D - сохранять файлы устройств и специальные файлы |
--xattrs | Включить поддержку расширенных атрибутов файлов |
--acls | Включить поддержку списков контроля доступа (POSIX Access Control Lists, ACL) |
--exclude | Исключить объекты из копирования. В частности, исключить из копирования необходимо сам каталог архива |
/ | Источник данных для копирования (в данном случае — корневой каталог) |
/backup | Объект, в который осуществляется копирование |
Примечание:
Правила задания имен каталогов. Рассмотрим два каталога
SRCиDST, причемSRCсодержит подкаталогSUB(т.е.SRC/SUB/), и сравним варианты копирования.При использовании простой команды копирования
cpразницы в результатах работы между командамиcp -a SRC DSTиcp -a SRC/ DSTне будет: будет создана структураDST/SRC/SUB.Однако результатом команды
rsync -a SRC DSTбудетDST/SRC/SUB. А результатом командыrsync -a SRC/ DSTбудетDST/SUB.Разница между командами – в символе
/в конце имени каталога-источника.
Простейший пример для удаленного копирования отличается только объектом, в который осуществляется копирование (в примере – копирование с использованием SSH на хост host.astradomain.ru под именем пользователя admin в каталог ~admin/backup/):
sudo rsync -a --exclude=/proc --exclude=/lost+found --exclude=/mnt --exclude=/sys/ / admin@host.astradomain.ru:backup
Для подобного копирования служба rsync.service на компьютере-получателе не нужна, достаточно работающей службы ssh.
При этом автоматически используются алгоритмы защитного преобразования данных, встроенные в SSH.
Внимание!
При таком копировании атрибуты доступа к копиям будут установлены неверно, копии будут принадлежать пользователю
adminна компьютере-получателе, мандатные атрибуты установлены не будут.
Сохранение атрибутов файлов
Внимание!
Данный пример работает только на файловых системах, поддерживающих расширенные атрибуты файлов и разрешающих запись пользовательских атрибутов. Файловая система Ext4 (рекомендуется к использованию) и большинство современных файловых систем соответствуют этим условиям по умолчанию. Файловые системы Ext2/Ext3 должны быть смонтированы с дополнительной опцией монтирования
user_xattr.
Более продвинутый пример удаленного копирования с сохранением атрибутов файлов независимо от их валидности в целевой ОС:
sudo rsync -a --X --A --exclude=/proc --exclude=/lost+found --exclude=/mnt --exclude=/sys --exclude=/parsecfs -M --fake-super / / admin@host.astradomain.ru:backup
Примечание:
В примере применены ранее описанные атрибуты
--xattrsи--acls(в краткой форме-Xи-A), и добавлен новый атрибут-M, передающий следующий атрибут удаленному компьютеру. В данном случае удаленному компьютеру передается параметр--fake-super, заставляющий удаленный компьютер сохранять невалидные атрибуты доступа файлов в расширенных атрибутах (extended attributes) этих файлов. Т.е. если на принимающем компьютереrsyncне может установить атрибуты файла (потому что на принимающем компьютере нет пользователя и/или группы с таким идентификатором, или потому, чтоrsyncзапущен от имени пользователя, не имеющего права выставлять такие атрибуты), то файлу-копии будут выставлены атрибуты пользователя, от имени которого запущен на принимающем компьютереrsync, а реальные атрибуты будут сохранены в расширенных атрибутах файла-копии.В старых руководствах по
rsyncчасто встречается устаревший вариант сохранения атрибутов, переопределяющий вызов удаленного экземпляраrsyncкак--rsync-path="rsync --fake-super"или даже--rsync-path="sudo rsync --fake-super". В настоящее время использование команды-M --fake-superявляется предпочтительным вариантом, а использованиеsudoкрайне нежелательно с точки зрения безопасности.Вызов
rsyncна принимающем компьютере происходит от имени и с правами пользователя, осуществившего вход в SSH. Хорошей практикой является создание для этой цели специально назначенного пользователя с ограниченными правами.
Для полностью корректной работы приведенных примеров под ОС Astra Linux Special Edition должна быть определена политика предоставления мандатной привилегии PARSEC_CAP_UNSAFE_SETXATTR удаленному экземпляру rsync.
Восстановление
Для восстановления достаточно выполнить команду, поменяв местами источник и назначение (и не забыв установить привилегию на изменение мандатных атрибутов, подробности см. в примере к инструменту tar):
echo 1 | sudo tee /parsecfs/unsecure_setxattr
/usr/sbin/execaps -c 0x1000 -- sudo rsync -a --xattrs --acls /backup/ /
echo 0 | sudo tee /parsecfs/unsecure_setxattr
Для восстановления копий, сделанных с помощью опции --fake-super следует также использовать эту опцию:
sudo rsync -a --X --A -M --fake-super / admin@host.astradomain.ru:backup /
Примечание:
В примере применены ранее описанные атрибуты
--xattrsи--acls(в краткой форме-Xи-A), и добавлен новый атрибут-M, передающий следующий атрибут удаленному компьютеру.
Сценарий проверки корректности работы с мандатными атрибутами
Details
Пример сценария копирования и восстановления с сохранением мандатных атрибутов и проверкой корректности восстановления:
# !/bin/bash
dpkg -l rsync &> /dev/null
if [ $? != 0 ]; then
printf "Installing rsync...\n"
apt-get install rsync &> /dev/null
fi
dir="/test_dir"
mac_cat_file="/etc/parsec/mac_categories"
mac_lev_file="/etc/parsec/mac_levels"
secure="/parsecfs/unsecure_setxattr"
dir_bak="/test_dir_bak"
u=`id -u -n`
red=$(tput setaf 1)
green=$(tput setaf 2)
coff=$(tput sgr0)
test_result="${green}TEST PASS${coff}\n"
mv $mac_cat_file $mac_cat_file.bak
> $mac_cat_file
usercat -a 10 cat_10
mv $mac_lev_file $mac_lev_file.bak
> $mac_lev_file
for i in 0 1 2 3; do
userlev -a $i Уровень_$i
done
mkdir $dir
pdpl-file 3:0:10:ccnr $dir
for l in lvl1 lvl2 lvl3; do
mkdir $dir/$l
done
for num in 1 2 3; do
pdpl-file $num:0:10:ccnr $dir/lvl$num
done
for d in lvl1 lvl2 lvl3; do
for f in 1 2 3; do
touch $dir/$d/file$f
done
done
pdpl-file 1:0:0 $dir/lvl1/file2
pdpl-file 1:0:10 $dir/lvl1/file3
pdpl-file 1:0:10 $dir/lvl2/file2
pdpl-file 2:0:10 $dir/lvl2/file3
pdpl-file 1:0:10 $dir/lvl3/file1
pdpl-file 2:0:10 $dir/lvl3/file2
pdpl-file 3:0:10 $dir/lvl3/file3
setfaud -R -m o:ocx:ocx $dir
setfacl -R -m u:$u:rwx $dir
echo 1 > $secure
rsync -rptgoAX $dir/ $dir_bak &> /dev/null
echo 0 > $secure
pdp-ls -Md $dir_bak | grep "Уровень_3:Низкий:cat_10:ccnr" &> /dev/null
check_dir=$(echo $?)
if [ $check_dir == 0 ]; then
printf "${green}PDPL on dir restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!\n${coff}"
printf "${red}PDPL on dir not restored!${coff}\n"
fi
pdp-ls -Md $dir_bak/lvl1 | grep "Уровень_1:Низкий:cat_10:ccnr" &> /dev/null
check_sdir1=$(echo $?)
if [ $check_sdir1 == 0 ]; then
printf "${green}PDPL on subdir 1 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subdir 1 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir_bak/lvl2 | grep "Уровень_2:Низкий:cat_10:ccnr" &> /dev/null
check_sdir2=$(echo $?)
if [ $check_sdir2 == 0 ]; then
printf "${green}PDPL on subdir 2 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subdir 2 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir_bak/lvl3 | grep "Уровень_3:Низкий:cat_10:ccnr" &> /dev/null
check_sdir3=$(echo $?)
if [ $check_sdir3 == 0 ]; then
printf "${green}PDPL on subdir 3 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subdir 3 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir_bak/lvl1/file3 | grep "Уровень_1:Низкий:cat_10" &> /dev/null
check_file1=$(echo $?)
if [ $check_file1 == 0 ]; then
printf "${green}PDPL on subfile 1 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subfile 1 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir_bak/lvl2/file3 | grep "Уровень_2:Низкий:cat_10" &> /dev/null
check_file2=$(echo $?)
if [ $check_file2 == 0 ]; then
printf "${green}PDPL on subfile 2 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subfile 2 lvl not restored!${coff}\n"
fi
pdp-ls -Md $dir_bak/lvl3/file3 | grep "Уровень_3:Низкий:cat_10" &> /dev/null
check_file3=$(echo $?)
if [ $check_file3 == 0 ]; then
printf "${green}PDPL on subfile 3 lvl restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}PDPL on subfile 3 lvl not restored!${coff}\n"
fi
getfaud $dir_bak 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_dir_aud=$(echo $?)
if [ $check_dir_aud == 0 ]; then
printf "${green}AUDIT on dir restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on dir not restored!${coff}\n"
fi
getfaud $dir_bak/lvl1 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sdir1_aud=$(echo $?)
if [ $check_sdir1_aud == 0 ]; then
printf "${green}AUDIT on subdir lvl1 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subdir lvl1 not restored!${coff}\n"
fi
getfaud $dir_bak/lvl2 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sdir2_aud=$(echo $?)
if [ $check_sdir2_aud == 0 ]; then
printf "${green}AUDIT on subdir lvl2 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subdir lvl2 not restored!${coff}\n"
fi
getfaud $dir_bak/lvl3 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sdir3_aud=$(echo $?)
if [ $check_sdir3_aud == 0 ]; then
printf "${green}AUDIT on subdir lvl3 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subdir lvl3 not restored!${coff}\n"
fi
getfaud $dir_bak/lvl1/file3 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sfile1_aud=$(echo $?)
if [ $check_sfile1_aud == 0 ]; then
printf "${green}AUDIT on subfile lvl1 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subfile lvl1 not restored!${coff}\n"
fi
getfaud $dir_bak/lvl2/file3 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sfile2_aud=$(echo $?)
if [ $check_sfile2_aud == 0 ]; then
printf "${green}AUDIT on subfile lvl2 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subfile lvl2 not restored!${coff}\n"
fi
getfaud $dir_bak/lvl3/file3 2> /dev/null | grep o:oxc:oxc &> /dev/null
check_sfile3_aud=$(echo $?)
if [ $check_sfile3_aud == 0 ]; then
printf "${green}AUDIT on subfile lvl3 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}AUDIT on subfile lvl3 not restored!${coff}\n"
fi
getfacl $dir_bak 2> /dev/null | grep user:$u:rwx &> /dev/null
check_dir_acl=$(echo $?)
if [ $check_dir_acl == 0 ]; then
printf "${green}ACL on dir restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on dir not restored!${coff}\n"
fi
getfacl $dir_bak/lvl1 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sdir1_acl=$(echo $?)
if [ $check_sdir1_acl == 0 ]; then
printf "${green}ACL on subdir lvl1 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subdir lvl1 not restored!${coff}\n"
fi
getfacl $dir_bak/lvl2 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sdir2_acl=$(echo $?)
if [ $check_sdir2_acl == 0 ]; then
printf "${green}ACL on subdir lvl2 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subdir lvl2 not restored!${coff}\n"
fi
getfacl $dir_bak/lvl3 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sdir3_acl=$(echo $?)
if [ $check_sdir3_acl == 0 ]; then
printf "${green}ACL on subdir lvl3 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subdir lvl3 not restored!${coff}\n"
fi
getfacl $dir_bak/lvl1/file3 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sfile1_acl=$(echo $?)
if [ $check_sfile1_acl == 0 ]; then
printf "${green}ACL on subfile lvl1 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subfile lvl1 not restored!${coff}\n"
fi
getfacl $dir_bak/lvl2/file3 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sfile2_acl=$(echo $?)
if [ $check_sfile2_acl == 0 ]; then
printf "${green}ACL on subfile lvl2 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subfile lvl2 not restored!${coff}\n"
fi
getfacl $dir_bak/lvl3/file3 2> /dev/null | grep user:$u:rwx &> /dev/null
check_sfile3_acl=$(echo $?)
if [ $check_sfile3_acl == 0 ]; then
printf "${green}ACL on subfile lvl3 restored normaly${coff}\n"
else
test_result="${red}TEST FAIL!${coff}\n"
printf "${red}ACL on subfile lvl3 not restored!${coff}\n"
fi
rm -r $dir*
mv $mac_cat_file.bak $mac_cat_file
mv $mac_lev_file.bak $mac_lev_file
echo
printf "$test_result"
exit 0
Настройка и применение rsync.service
Внимание!
С учетом того, что работа службы
rsyncd(rsync.service) осуществляется без защитного преобразования данных, использовать эту службу следует с осторожностью: либо в доверенной защищенной сети, либо для передачи данных, уже подвергнутых защитному преобразованию.
Для решения большинства задач копирования достаточно изложенных выше приемов работы через SSH без использования rsync.service.
Служба rsync.service может оказаться полезна:
- для копирования очень больших объемов информации, так как сервер
rsync.serviceможет локально определить, какую информацию копировать; - для работы со слабыми процессорами, так как отсутствие защитного преобразования данных снижает нагрузку на процессор (хотя, при необходимости, защитное преобразование данных можно отключить и при использовании
ssh);
Для использования rsync.service выполните действия:
-
Разрешите запуск службы, заменив в файле
/etc/default/rsyncзначение параметраRSYNC_ENABLE=falseнаRSYNC_ENABLE=true. -
Создайте и заполнить файл конфигурации
/etc/rsyncd.conf, например:max connections = 10
exclude = lost+found/ /tmp/
dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz *.rar *.7z *.mp3 *.jpg
[data1]
path = /data1/
comment = Public folders
read only = yes
list = yes
auth users = rsync_d1
secrets file = /etc/rsyncd.scrt
hosts allow = localhost {IP-адрес-1} {IP-адрес-2}
hosts deny = *где:
Параметр Описание max connectionsМаксимальное количество одновременных подключений excludeСписок каталогов, которые не нужно копировать dont compressСписок файлов, которые не нужно сжимать при передаче (которые уже сжаты) [data1]Заголовок описания секции данных (таких секций может быть несколько) pathПуть к месту хранения данных commentКомментарий read onlyЗапрет на переписывание данных listРазрешение на просмотр каталога данных auth usersСписок авторизованных пользователей secrets fileФайл с именами и паролями hosts allowСписок адресов, с которых разрешен доступ hosts denyСписок адресов, с которых доступ запрещен -
Создайте файл с адресами и паролями (в данном примере -
/etc/rsyncd.scrt):user1:password1
user2:password2
backup:password3В целях безопасности рекомендуется ограничить доступ к этому файлу:
sudo chmod 600 /etc/rsyncd.scrt -
Запустите сервис:
sudo systemctl start rsync -
Доступ к серверу rsync выполните точно так же, как и доступ через SSH, единственное различие - в использовании «двойного двоеточия», указывающего, что нужно использовать протокол
rsync:sudo rsync -a user1@host.astradomain.ru::data1 /tmp/
Копирование конфигурации СУБД Pangolin
Под копирование конфигурации понимается копирование конфигурационных файлов, в зависимости от типа конфигурации.
Определить конфигурацию можно с помощью команды:
SHOW installer.cluster_type;
Ответ для standalone:
┌─────────────────────────────────┐
│ installer.cluster_type │
├─────────────────────────────────┤
│ standalone-postgresql-pgbouncer │
└─────────────────────────────────┘
(1 row)
Ответ для кластера:
┌────────────────────────────────┐
│ installer.cluster_type │
├────────────────────────────────┤
│ cluster-patroni-etcd-pgbouncer │
└────────────────────────────────┘
(1 row)
Файлы, подлежащие резервному копированию:
-
для PostgreSQL:
- с Pangolin Manager:
/etc/pangolin-manager/postgres.yml; - без Pangolin Manager:
$PGDATA/postgresql.confи$PGDATA/pg_hba.conf, где$PGDATA–/pgdata/06/data(для 6 версии СУБД Pangolin);
- с Pangolin Manager:
-
для Pangolin Pooler:
- конфигурационный файл:
/etc/pangolin-pooler/pangolin-pooler.ini; - исполняемый файл (с версии Pangolin 6.1.2):
/opt/pangolin-pooler/bin/pangolin-pooler;
- конфигурационный файл:
-
для DCS (etcd):
- конфигурационный файл:
/etc/etcd/etcd.conf;
- конфигурационный файл:
-
утилита перекодирования:
- конфигурационный файл:
/etc/pangolin-auth-reencrypt/enc_util.cfg; - исполняемый файл:
/opt/pangolin-common/bin/pangolin-auth-reencrypt;
- конфигурационный файл:
-
хранилище паролей (файл
/etc/pangolin-auth-encryption/enc_utils_auth_settings.cfg); -
файл с параметрами оборудования и сетевыми интерфейсами (файл
enc_params.cfg.postgresиenc_params.cfg.kmadmin_pg); -
настройки подключения к KMS (файл
/etc/pangolin-security-utilities/enc_connection_settings.cfg); -
для восстановления утилиты из резервной копии необходимо хранить набор файлов:
-
конфигурационный файл утилиты (
/etc/pangolin-auth-reencrypt/enc_util.cfg); -
файл с параметрами оборудования и сетевыми интерфейсами (
enc_params.cfg.postgresиenc_params.cfg.kmadmin_pg); -
файлы с засекреченными параметрами подключения к БД (все, что перечислено в конфигурационном файле утилиты
enc_util.cfg):/etc/pangolin-security-utilities/enc_connection_settings.cfg;/etc/pangolin-security-utilities/enc_connection_settings_cert.cfg;/etc/pangolin-security-utilities/kms_static_params.cfg;/pg_ssl/intermediate/server.p12.cfg;/pg_ssl/intermediate/patroni_server.p12.cfg;/etc/pangolin-auth-encryption/enc_utils_auth_settings.cfg;/etc/pangolin-manager/postgres.yml;pg_hba.conf.
-
Архитектура
Концептуальная архитектура СУБД Pangolin в части резервного копирования
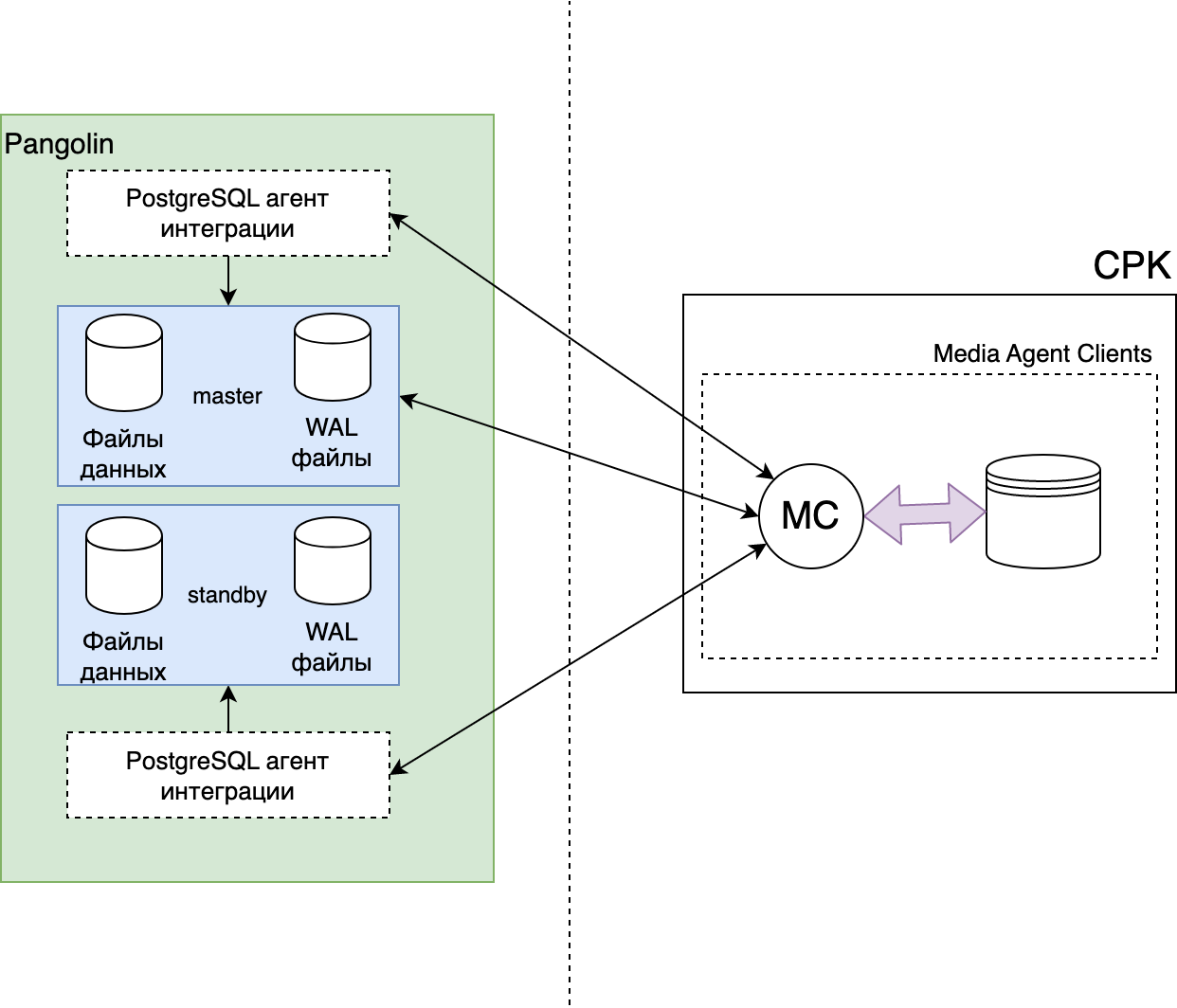
Схема процесса создания резервной копии СУБД Pangolin

Табличное описание процесса
| Наименование шага | Входной документ | Описание | Исполнитель | Характер изменений | Продолжительность | Выходной документ | ИТ-система | Переход к шагу |
| 010 Инициация создания резервной копии | Инициация создания резервной копии по расписанию либо вручную по запросу | Инженер СРК или по расписанию | В зависимости от размера БД | СРК | 020 | |||
| 020 Исполнение скрипта определяющего роль сервера | Исполнение заранее заданного скрипта, определяющего роль сервера в кластере СУБД Pangolin и запускающего необходимую спецификацию копирования | Автоматически | СРК | 030 | ||||
| 030 Исполнение pre-exec скриптов | Выполнение заранее заданных скриптов на целевом узле до создания резервной копии | Автоматически | Снятие резервной копии в локальный каталог резервных копий с помощью pg_probackup | СРК Pangolin | 040 | |||
| 040 Копирование файлов БД | Копирует каталог СУБД Pangolin на серверы СРК, вносит информацию о резервной копии в Каталог | Автоматически | СРК | 050 | ||||
| 050 Копирование файлов WAL | Копирование архива файлов WAL на серверы СРК | Автоматически | Резервная копия БД | СРК | 060 | |||
| 060 Исполнение post-exec скриптов | Выполнение заранее заданных скриптов на целевом узле после завершения копирования резервной копии | Автоматически | Удаление локальной резервной копии с помощью pg_probackup | СРК | 070 | |||
| 070 Завершение резервного копирования | Завершение резервного копирования | Автоматически | СРК |
Схема процесса восстановление СУБД Pangolin из резервной копии

Табличное описание процесса
| Наименование шага | Описание | Исполнитель | Характер изменений | ИТ-система | Переход к шагу |
| 010 Инициация восстановления | Запрос операции восстановления | Инженер эксплуатации | Service Manager | 020 или 025 | |
| 020 Выбор экземпляра СУБД Pangolin и версии резервной копии для восстановления | Выбор СУБД Pangolin для восстановления и версии резервной копии для восстановления | Инженер СРК | СРК | 030 | |
| 025 Выбор КТС и версии резервной копии для восстановления | Выбор КТС для восстановления и версии резервной копии для восстановления | Инженер СРК | СРК | 030 | |
| 030 Установка параметров для восстановления | Установка параметров для восстановления выбранного экземпляра СУБД Pangolin или КТС | Инженер СРК | СРК | 040 | |
| 040 Проверка доступности носителей и устройств для восстановления | Проверка доступности копий и данных для восстановления | Автоматически | СРК | 050 | |
| 050 Установка параметров процесса восстановления | Выбор допустимой нагрузки на сеть, а также уровня логирования при восстановлении | Инженер СРК | СРК | 060 или 070 | |
| 060 Исполнение preexec скриптов | Выполнение preexec-скриптов | Автоматически | При необходимости | СРК | 070 |
| 070 Копирование файлов резервной копии на узел | Копирование файлов резервной копии и архива WAL с серверов СРК на целевую систему в локальный каталог копий | Автоматически | СРК | 080 или 090 | |
| 080 Исполнение postexec скриптов | Выполнение postexec-скриптов | Автоматически | При необходимости | СРК | 090 |
| 090 Запуск восстановления БД | Использование восстановление из локального каталога копий с помощью pg_probackup | Автоматически | Pangolin | 100 или 110 или 120 | |
| 100 Обновление ключа TDE | Администратор БД производит следующие действия: - получает из резервной копии метку мастер-ключа, актуального на момент резервного копирования; - получает из KMS мастер-ключ, актуальный на момент бэкапа; - получает из KMS мастер-ключ, актуальный на текущий момент; - загружает ключи засекречивания из резервной копии, перекодируя их | Администратор БД | Pangolin | 120 | |
110 Настройка параметров recovery_conf в файла Pangolin Manager | Настройка recovery_conf секции для успешного восстановления БД | Администратор БД | Pangolin | 120 | |
| 120 Запуск Pangolin Manager | Запуск службы Pangolin Manager | Администратор БД | Pangolin |
Администрирование
Настройка
Проверка установленного расширения и утилит
СУБД Pangolin изначально поставляется со всеми необходимыми установленными расширениями и утилитами для организации резервного копирования.
Проверка наличия расширения pgse_backup :
postgres=# SELECT * FROM pg_extension WHERE extname = 'pgse_backup';
oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+--------------------+----------+--------------+----------------+------------+---------------+--------------
16407 | pgse_backup | 10 | 16404 | f | 1.2 | |
(1 row)
Из вывода видно, что расширение pgse_backup (oid 16407) установлено и готово к использованию.
Внимание!
С Pangolin совместима только та утилита
pg_probackup, что идет в составе дистрибутива.
Проверка наличия утилиты pg_probackup:
$ which pg_probackup
/usr/pgsql-se-{version}/bin/pg_probackup
Утилита manage_backup.bin входит в пакет Manage Backup Tools и устанавливается в каталог /opt/pangolin-backup-tools-1.1.0/bin на сервере с БД при интеграции Pangolin c СРК.
Настройка СУБД Pangolin для организации резервного копирования
Инсталлятор автоматически устанавливает и настраивает все необходимые для организации резервного копирования, расширения и утилиты:
-
Устанавливает утилиту
pg_probackup. -
Инициализирует локальный каталог резервных копий:
pg_probackup init -B $PGBACKUP -
Определяет копируемый экземпляр (по умолчанию) резервных копий:
pg_probackup add-instance -B $PGBACKUP -D $PGDATA --instance <название экземпляра> -
Устанавливает параметры БД:
wal_level = replica
hot_standby = on
full_pages_writes = on
archive_mode = always
archive_command = 'pg_probackup archive-push -B <локальный каталог копий> --instance <экземпляр> --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4'
archive_timeout = 180 -
Добавляет параметры работы
pg_probackup:pg_probackup set-config -B $PGBACKUP -D $PGDATA --instance <название экземпляра> -d <имя_базы> -h <локальный сервер> -p <локальный порт> -U <имя_пользователя>
Ручная установка rpm/deb-пакета компонента Pangolin Backup Tools
-
Установите пакет
pangolin-backup-tools-venv(обязательная зависимость дляpangolin-backup-tools):- SberLinux, РЕД ОС, CentOS
- Astra Linux
- Альт СП
sudo dnf install pangolin-backup-tools-venv-{version_component}-{OS}.x86_64.rpmsudo apt install pangolin-backup-tools-venv-{version_component}_amd64.debsudo apt-get install pangolin-backup-tools-venv-{version_component}-{OS}.x86_64.rpmПример заполненной команды:
cd distributive/3rdparty/
sudo dnf install -y pangolin-backup-tools-venv-1.1.0-sberlinux9.x86_64.rpm -
Установите пакет компонента:
- SberLinux, РЕД ОС, CentOS
- Astra Linux
- Альт СП
sudo dnf install pangolin-backup-tools-{version_component}-{OS}.x86_64.rpmsudo apt install pangolin-backup-tools-{version_component}_amd64.debsudo apt-get install pangolin-backup-tools-{version_component}-{OS}.x86_64.rpmПример заполненной команды:
cd distributive
sudo dnf install -y pangolin-backup-tools-1.2.4-sberlinux9.x86_64.rpm -
Актуализируйте конфигурационный файл
backup-tools-envсогласно шаблону ниже, если установка компонента первичная. Файлbackup-tools-envнаходится в/etc/pangolin-backup-tools/.backup-tools-env
backup-tools-env:# PATH, used for access to required executable files, default value: "${PATH}:{PGHOME}/bin/"
PATH="${PATH}:/usr/pangolin-6.5/bin/"
# path to PGHOME, default value: "/opt/pangolin-backup-tools/bin"
PGHOME="/opt/pangolin-backup-tools"
# path to python libraries, required for manage_backup.bin, default value: "/opt/pangolin-backup-tools/lib/python3/site-packages"
PYTHONPATH="/opt/pangolin-backup-tools/lib/python3/site-packages"
# path to libraries, required for executable files, default value: "/opt/pangolin-backup-tools/lib"
LD_LIBRARY_PATH="/opt/pangolin-backup-tools/lib"
# path to plugins libraries, default value: "/opt/pangolin-backup-tools/lib"
PG_PLUGINS_PATH="/opt/pangolin-backup-tools/lib"
# Pangolin DBMS server IP, default value: "127.0.0.1"
ARG_KEY_DBMS_SERVER_IP="127.0.0.1"
# Pangolin DBMS port, default value: "5433"
ARG_KEY_DBMS_SERVER_PORT="5433"
# user used for access to database, default value: "backup_user"
ARG_KEY_DBMS_CONNECT_USER="backup_user"
# database to connect, default value: "postgres"
ARG_KEY_DBMS_CONNECT_DATA_BASE="postgres"
# path to backup storage, default value: "/pgarclogs"
ARG_KEY_DBMS_CONNECT_BACKUP_DIR="/pgarclogs/06"
# password to connect to Pangolin DBMS, default value: 'sample_password'
# cluster name, default value: "clustername"
PGINSTANCE="clustername"
# WAL archives list
WALSTATE_FILE="$ARG_KEY_DBMS_CONNECT_BACKUP_DIR/wals_to_delete"
# Log file
LOG_FILE="$ARG_KEY_DBMS_CONNECT_BACKUP_DIR/archive.log"
# path to script, used for creating backup files, default value: "/opt/pangolin-backup-tools/bin/manage_backup.sh"
MANAGE_BACKUP_SCRIPT="/opt/pangolin-backup-tools/bin/manage_backup.sh"
# setting up of connection string
PANGOLIN_BACKUP_TOOLS_ARGS="$PANGOLIN_BACKUP_TOOLS_ARGS --host $ARG_KEY_DBMS_SERVER_IP"
PANGOLIN_BACKUP_TOOLS_ARGS="$PANGOLIN_BACKUP_TOOLS_ARGS -p $ARG_KEY_DBMS_SERVER_PORT"
PANGOLIN_BACKUP_TOOLS_ARGS="$PANGOLIN_BACKUP_TOOLS_ARGS -U $ARG_KEY_DBMS_CONNECT_USER"
PANGOLIN_BACKUP_TOOLS_ARGS="$PANGOLIN_BACKUP_TOOLS_ARGS -d $ARG_KEY_DBMS_CONNECT_DATA_BASE"
PANGOLIN_BACKUP_TOOLS_ARGS="$PANGOLIN_BACKUP_TOOLS_ARGS -B $ARG_KEY_DBMS_CONNECT_BACKUP_DIR"
# environment variables to launch manage backup
export PATH
export PGHOME
export PYTHONPATH
export LD_LIBRARY_PATH
export PG_PLUGINS_PATHПредупреждение!Значения указаны по умолчанию, если они не соответствуют значениям с обновляемого стенда, актуализируйте.
:::
ПодсказкаПуть к файлу настроек по умолчанию можно изменить используя переменную окружения
BACKUP_TOOLS_CONFIG_PATH_FILE.
Интеграция с системой мониторинга
В системе мониторинга используются следующие метрики:
| Метрика | Запрос | Описание |
|---|---|---|
backup completed count | SELECT count(state) FROM backup.history WHERE state = ‘completed’ AND start_time >= (now() - ‘1 day’::interval); | Возвращает количество успешных резервных копий за последние 24 часа |
backup failed count | SELECT count(state) FROM backup.history WHERE state = ‘failed’ AND start_time >= (now() - ‘1 day’::interval); | Возвращает количество неуспешных резервных копий за последние 24 часа |
backup wal failed count | SELECT count(state) FROM backup.wal_history WHERE state = ‘failed’ AND start_time >= (now() - ‘1 day’::interval); | Возвращает количество неуспешных резервных копий WAL-сессий за последние 24 часа |
Если резервная копия снята успешно, то значение backup completed count будет больше 0, а значение backup wal failed count равно 0.
Состояние резервной копии на каждом экземпляре БД свое, поэтому при мониторинге необходимо опросить все узлы кластера, чтобы гарантировано получить самую последнюю резервную копию.
Управление
Интерфейс просмотра истории резервных копий (РК)
Просмотр истории полного цикла РК
Для просмотра истории полного цикла РК создано специальное представление backup.data_history.
backup.data_history берет информацию из локального файла $PGBACKUP/backup_state и выводит его содержимое в виде таблицы:
postgres=# select * from backup.data_history;
session_id | state | tli | start_time | start_lsn | stop_time | stop_lsn | duration | stop_walfile
------------+-----------+-----+------------------------+------------+------------------------+------------+----------+--------------------------
FULL-16 | completed | 54 | 2020-11-13 01:52:22+03 | 4/5A000060 | 2020-11-13 01:52:31+03 | 4/{хеш} | 00:00:09 | {wal_file}
FULL-16 | completed | 54 | 2020-11-13 01:53:05+03 | 4/5A000060 | 2020-11-13 01:53:11+03 | 4/{хеш} | 00:00:06 | {wal_file}
Где:
session_id- id сессии;state- состояние сессии;tli- timeline снятой копии;start_time- начало выполнения сессии;start_lsn- позиция WAL-сегмента при переходе БД в режим снятия РК;stop_time- конец выполнения сессии;stop_lsn- позиция WAL-сегмента при выходе БД из режима снятия РК;duration- длительность сессии (end_time-start_time);stop_walfile- конечный WAL-архив.
Просмотр истории РК промежуточных WAL
Для просмотра истории резервных копий промежуточных WAL создано специальное представление backup.wal_history:
postgres=# select * from backup.wal_history;
session_id | state | start_time | stop_time | duration | info
-----------+-----------+------------------------+------------------------+----------------
WAL-5 | completed | 2020-11-09 16:11:02+03 | 2020-11-09 16:11:04+03 | 00:00:02 | [{"tli": 40, "parent_tli": 0, "switchpoint": "0/0", "min_segn
o": {хеш}, "max_segno": {хеш}, "n_segments": 11, "size": 955436, "zratio": 193.16, "status": "ok", "lost_s
egments": []}]
Где:
session_id- id сессии СРК;state- состояние сессии;start_time- начало выполнения сессии;stop_time- конец выполнения сессии;duration- длительность сессии (end_time-start_time);info- информация о хранящихся на диске архивах WAL (собирается на старте копирования с помощьюpg_probackup).
В поле info помещается номер стартового и конечного архивов WAL. Если на диске отсутствуют промежуточные архивы — будет выведена ошибка, и в поле info.lost_segments будут записаны потерянные файлы.
Для мониторинга связанных сессий PGDATA и WAL используется представление backup.history. Оно учитывает представления backup.data_history и backup.wal_history. Состояние completed выставляется только тогда, когда для сессии PGDATA существует успешно завершенная сессия WAL, скопировавшая необходимый архив WAL (поле data_history.stop_walfile).
postgres=# select * from backup.history ;
session_id | state | tli | start_time | start_lsn | stop_time | stop_lsn | duration
------------+------------------------+-----+------------------------+------------+------------------------+------------+----------
FULL-5 | completed | 40 | 2020-11-09 16:36:09+03 | 2/50000028 | 2020-11-09 16:46:59+03 | 2/5103C430 | 00:10:50
FULL-5 | completed | 40 | 2020-11-09 16:47:01+03 | 2/53000028 | 2020-11-09 16:47:36+03 | 2/53000108 | 00:00:35
Автоматическая очистка истории старых резервных копий
В файле backup_state хранится состояние нескольких резервных копий (по умолчанию последние 6).
Размер хранимой истории задается параметром утилиты manage_backup.bin: --rotate-history N - количество успешных (completed) резервных копий, хранимых в истории (0 - история не удаляется).
История сессий WAL удаляется автоматически, удаляются все записи старше самой старой сессии полного резервного копирования. Таким образом, история содержит все сессии WAL, связанные с текущими сессиями полного копирования.
Ручная очистка истории резервных копий
Если файлы с историей резервных копий содержат данные в некорректном формате (например, в результате проблем с дисками), представления backup.*_history не смогут их прочитать. В таком случае будет выведена ошибка:
postgres=# select * from backup.history;
ERROR: invalid input syntax for type json
DETAIL: history file "/pgarclogs/05/backup_state" might be corrupted
HINT: you may need to clean up all backup history with "SELECT backup.reset_history()" CONTEXT: PL/pgSQL function backup.read_data_history() line 18 at RAISE
В случае возникновения этой ошибки можно воспользоваться механизмом ручной очистки истории. Для ручной очистки истории предусмотрена функция backup.reset_history(), доступная только администраторам БД:
postgres=# select backup.reset_history();
reset_history
---------------
(1 row)
После выполнения будут очищены сессии DATA и WAL. Также можно вручную удалить файлы /pgarclogs/{version}/backup_state и /pgarclogs/{version}/wal_backup_state или дождаться очередной сессии (DATA/WAL), которая сама очистит некорректные файлы.
Даже если файлы испорчены, сам процесс резервного копирования будет происходить без ошибок. В начале сессии испорченный файл перезапишется автоматически. Состояние старых резервных копий хранится в журнале /pgarclogs/{version}/backup_manager.log.
Если файлов backup_state и wal_backup_state не существует, соответствующие представления выполнятся без ошибок и вернут пустые наборы строк.
Утилита manage_backup.bin
Утилита имеет следующие ключи:
usage: manage_backup.bin [-h] -B label_dir --host host -p port -d database -U
user [--password password] [--session-timeout sec]
[--start-timeout sec] [--stop-timeout sec]
[--patroni-host patroni_host]
[--patroni-port patroni_port]
[--rotate-history rotate_history] --session-id
session_id
action
Поддержка смещения значения LSN после переноса БД через pg_dump и pg_restore
При миграции базы данных с помощью связки утилит pg_dump и pg_restore значение LSN в новой базе оказывается меньше, чем в исходной. Если переключить логическую репликацию на новую базу, то изменения не будут реплицироваться, так как для корректной работы логической репликации последовательность LSN должна быть возрастающей.
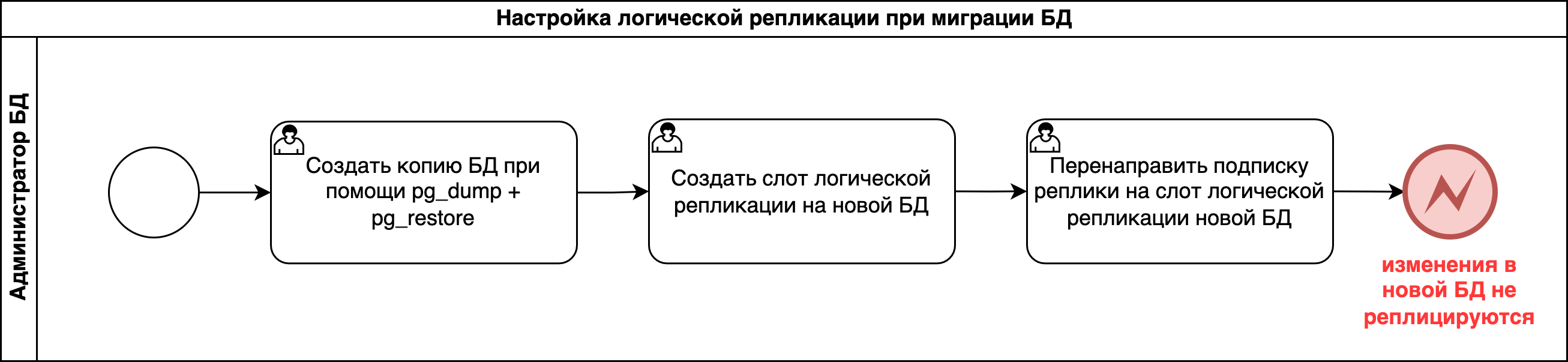
Для решения этой проблемы в СУБД Pangolin реализована утилита psql_set_lsn, которая изменяет значение LSN для указанной базы данных. С ее помощью устанавливается возрастающая последовательность LSN, необходимая для корректной работы логической репликации после переключения на новую базу данных.

Внимание!
Ограничения
psql_set_lsn:
- не работает при включенном прозрачном защитном преобразовании (TDE);
- не заполняет память между старым и новым LSN. Таким образом, между старым и новым LSN в WAL-сегменте остается сегмент без записей.
Функциональность доступна только для редакций Enterprise и Enterprise для ERP-систем.
Утилита psql_set_lsn поставляется в составе пакета dbms (серверная часть).
Интерфейс утилиты
Утилита принимает на вход ключи:
-D,--pgdata– директория с данными кластера;-L,--lsn– LSN, который необходимо установить для базы данных строго в шестнадцатеричном формате. Допускается формат LSN в виде 16 шестнадцатеричных цифр или двух групп по 8 шестнадцатеричных цифр, разделенных слешом (допускаются лидирующие нули);-B,--backup-dir– директория для резервной копии изменяемых файлов. По умолчанию сохраняются вPGDATA/psql_set_lsn_backupsс таким же именем, как и у оригинальных файлов, но с добавленным суффиксом_backup. Если используется пользовательская директория, она должна быть создана пользователем;-S,--skip-error– игнорирование ошибки создания резервных копий изменяемых файлов (Control File и WAL-segment);-V,--version– версияpsql_set_lsn;-h,--help– помощь.
Сценарий использования утилиты
Внимание!
После смещения LSN необходимо создать полную резервную копию кластера, так как после выполнения смещения, в случае аварийной ситуации, восстановиться из сделанной до смещения LSN резервной копии без потери данных будет невозможно.
Пример использования утилиты psql_set_lsn для изменения значения LSN при миграции данных:
-
Создайте копию
DB1при помощи утилитpg_dumpиpg_restore;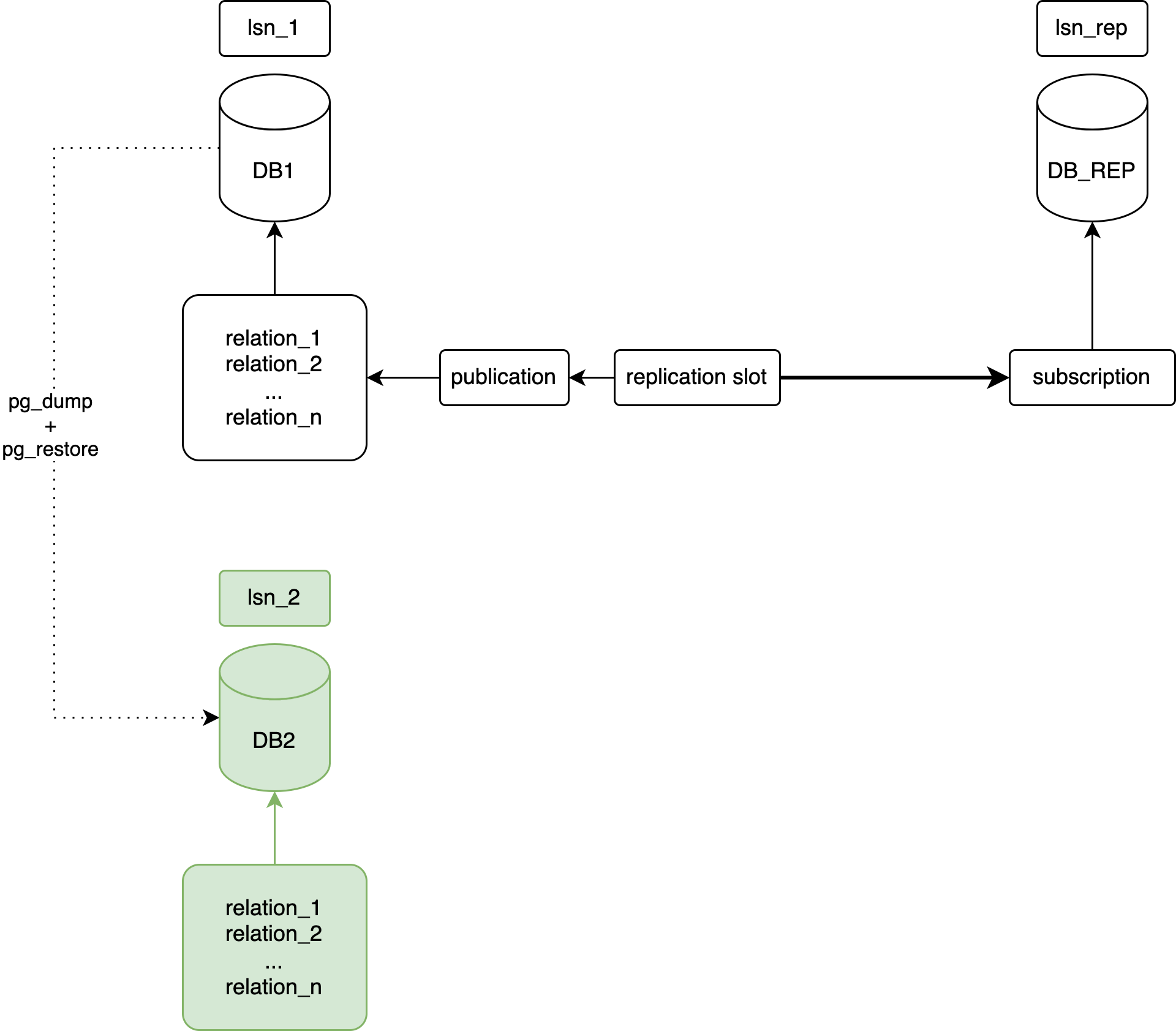
Сущности на диаграмме:
DB1– первоначальная база данных;relation_1, relation_2, ... , relation_n– отношения вDB1;publication– публикация для отношенийrelation_1, relation_2, ... , relation_n;replication slot– слот репликации дляpublication;DB_REP– репликаDB1;subscription– подписка, присоединенная кreplication slot;DB2– копия базыDB1, созданная при помощиpg_dumpиpg_restore;lsn_1- LSN базыDB1;lsn_2- LSN базыDB2;lsn_rep- LSN базыDB_REP.
-
Остановите базу
DB1иDB_REP.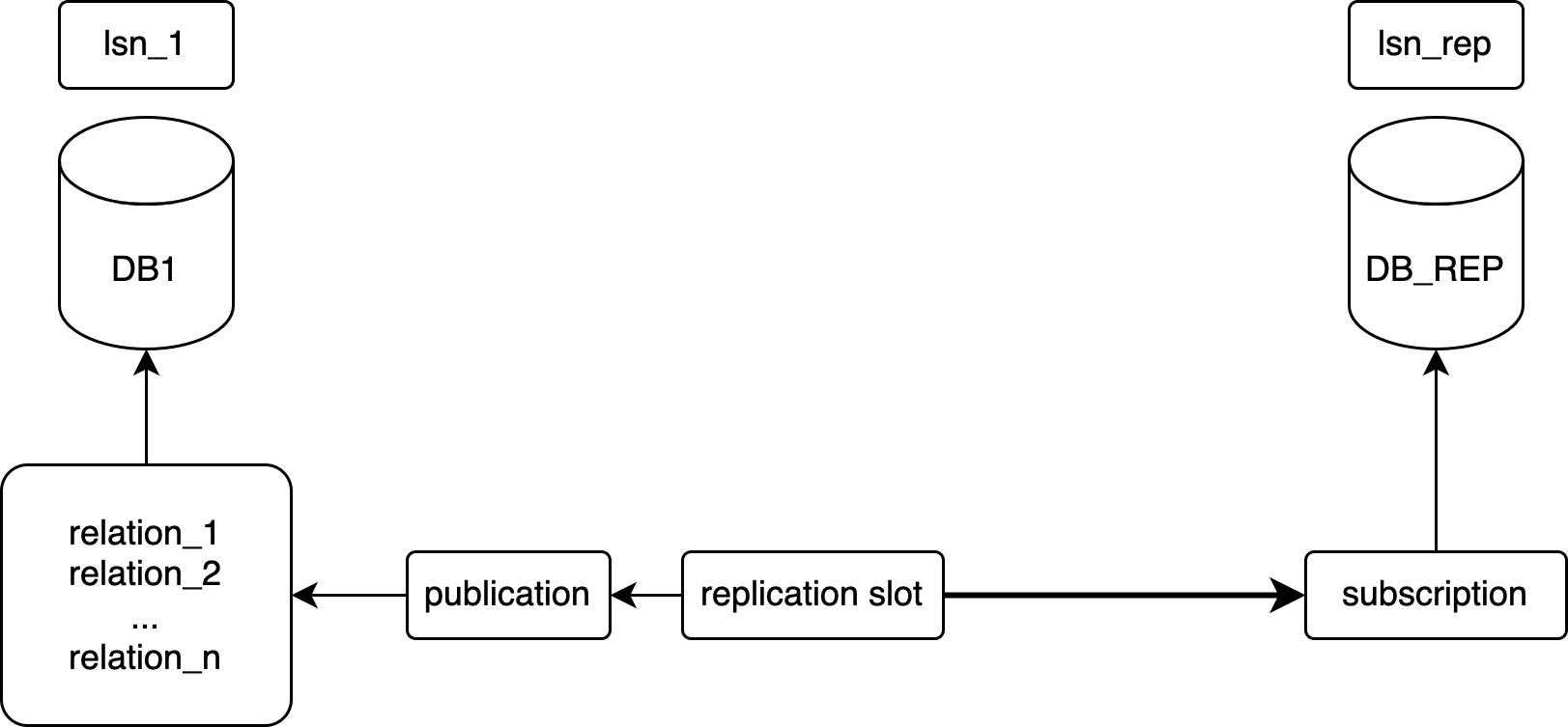
Сущности на диаграмме аналогичны сущностям на диаграмме в пункте 1.
-
Определите LSN базы
DB1, например, при помощиpg_controldata:pg_controldata -D <DB1_dir>/data | grep 'Latest checkpoint location';<DB1_dir>– каталог базы DB1. -
При помощи утилиты
psql_set_lsnобновите LSN у БД2:psql_set_lsn -D <DB2_dir>/data -L lsn_1;<DB2_dir>– каталог базы DB2. -
Запустите базы
DB2иDB_REP. -
Убедитесь, что в
DB2есть необходимый слот репликации, если нет, создайте его при помощи pg_create_logical_replication_slot. -
Перенаправьте подписку базы
DB_REPна базуDB2при помощи ALTER SUBSCRIPTION. -
Выполните рестарт
DB2иDB_REP, если в пункте 6 создавался слот репликации или в пункте 7 переподключалась подпискаDB_REP. Изменения базыDB2должны реплицироваться в базуDB_REP: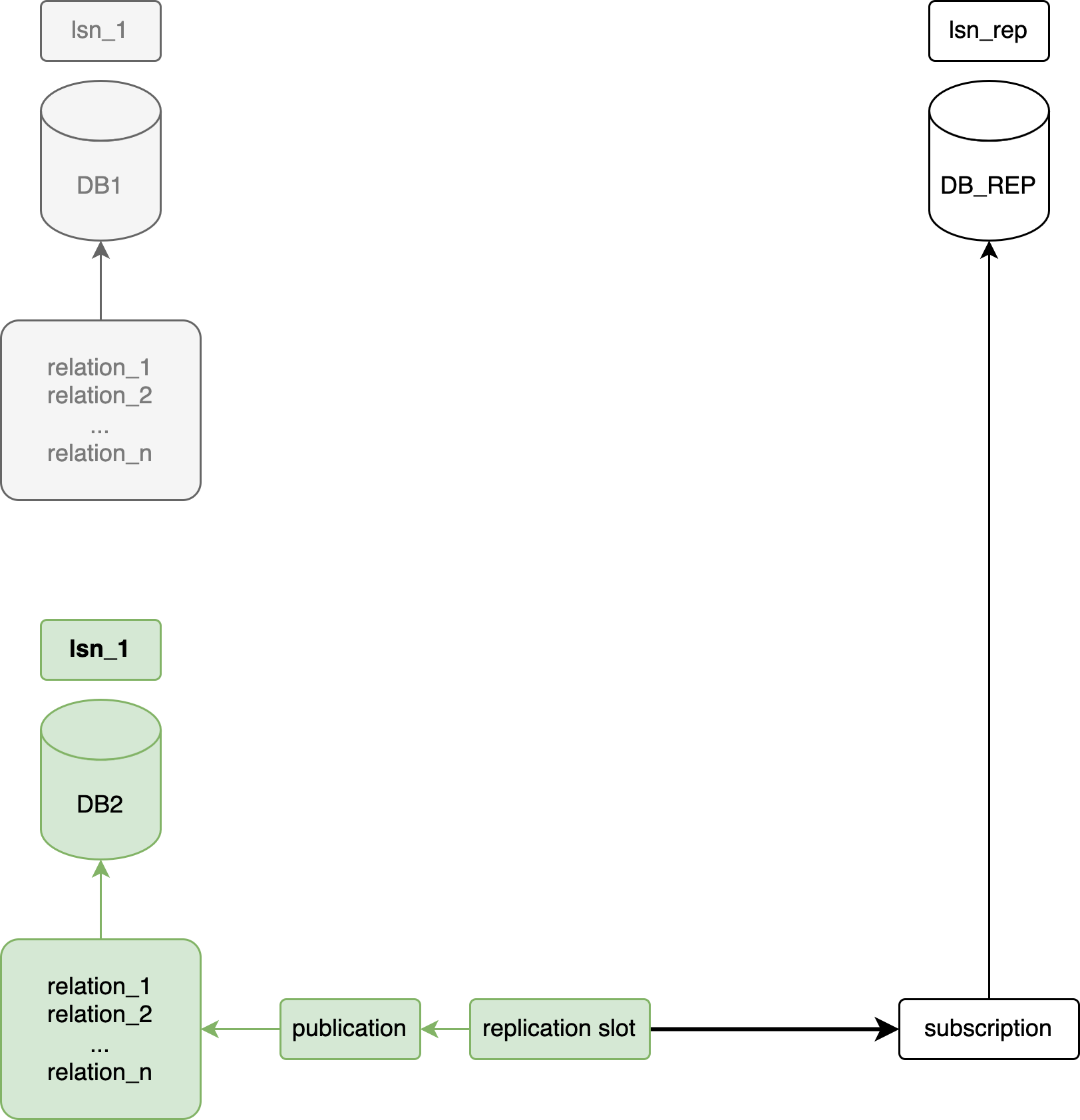
Устранение неисправностей
Ошибки, возникающие в процессе копирования, заносятся в журнал, в приложение backup_session и в файл backup_manager.log в каталоге резервного копирования.
При нештатном прерывании процедуры резервного копирования (например, при отключении сервера) может возникнуть ситуация, при которой незавершенная копия останется в промежуточном состоянии. Такая процедура считается неуспешной (эквивалентной failed). В начале следующей сессии резервного копирования такие зависшие состояния будут автоматически переведены в failed.
Сообщения системного журнала опционально в формате вывода поддерживаемом функциональностью.
Безопасность
Для проведения процедуры резервного копирования в СУБД Pangolin существует выделенная роль со следующими разрешениями:
BEGIN;
CREATE ROLE BACKUP_USER WITH LOGIN;
GRANT USAGE ON SCHEMA pg_catalog TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.current_setting(text) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_is_in_recovery() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_start_backup(text, boolean, boolean) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_stop_backup(boolean, boolean) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_create_restore_point(text) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_switch_wal() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_last_wal_replay_lsn() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current_snapshot() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_snapshot_xmax(txid_snapshot) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_control_checkpoint() TO BACKUP_USER;
COMMIT;
Где:
BACKUP_USER - пользователь для возможности подключения к СУБД Pangolin со стороны СРК.
Роль BACKUP_USER имеет атрибут LOGIN, тем самым ей разрешена авторизация на сервере. По умолчанию после инсталляции в конфигурационной секции pg_hba для роли BACKUP_USER определено правило: host all backup_user 0.0.0.0/0 scram-sha-256.
Пароль для этой роли задается при инсталляции с помощью переменной pg_backup_user_passwd в предустановочном конфигурационном файле custom_config_initial.yml (раздел с описанием параметров конфигурационного файла доступен в личном кабинете). Пароль должен удовлетворять парольной политике. После инсталляции хеш пароля хранится в системной таблице pg_authid.
Для обеспечения безопасности критичных данных в резервных копиях в СУБД Pangolin используется прозрачное защитное преобразование данных (TDE). При включенном механизме засекречиваются данные, которые находятся в файлах данных, резервных копиях и временных файлах баз данных, а также данные, передаваемые по каналам связи в ходе физической и логической репликации.
Для засекречивания сетевого трафика между клиентом и сервером в СУБД Pangolin встроена поддержка SSL, по умолчанию ssl = on.
Описание объектов
Схемы
Создание схемы:
CREATE SCHEMA backup;
Таблицы
Создание таблицы:
CREATE TABLE backup.settings(name text, setting text);
INSERT INTO backup.settings(name, setting) VALUES ('dir', '/pgarclogs/' ||
-- get major version (11, 12, ...)
(SELECT split_part((SELECT setting FROM pg_settings WHERE name = 'server_version'), '.', 1)));
Пример таблицы:
| Имя столбца | Тип | Описание |
|---|---|---|
| name | text | Поле, в котором содержится тип настройки (в данный момент он единственный и называется dir) |
| setting | text | Путь к каталогу файловой системы, где будут храниться архивы |
Типы
Создание полей с указанным типом:
CREATE TYPE backup.data_history_row_type AS (
session_id text,
state text,
tli integer,
start_time text,
start_lsn text,
stop_time text,
stop_lsn text,
duration text,
stop_walfile text COLLATE "C"
);
CREATE TYPE backup.wal_history_row_type AS (
session_id text,
state text,
start_time text,
stop_time text,
duration text,
info json
);
Функции
Создание функций:
CREATE OR REPLACE FUNCTION backup.read_data_history()
RETURNS SETOF backup.data_history_row_type AS
$$
DECLARE
filename text;
json_data text;
BEGIN
filename := (SELECT setting FROM backup.settings WHERE name = 'dir') || '/backup_state';
json_data := replace(trim(pg_read_file(filename)), e'\n', '');
if (json_data = '') is not false then
return;
end if;
return QUERY SELECT * FROM json_populate_recordset(null::backup.data_history_row_type, json_data::json);
EXCEPTION
WHEN undefined_file THEN
return;
WHEN invalid_text_representation THEN
RAISE EXCEPTION '%', SQLERRM
USING DETAIL = format('history file "%s" might be corrupted', filename),
HINT = 'you may need to clean up all backup history with "SELECT backup.reset_history()"';
END;
$$
LANGUAGE plpgsql SECURITY DEFINER;
CREATE OR REPLACE FUNCTION backup.read_wal_history()
RETURNS SETOF backup.wal_history_row_type AS
$$
DECLARE
filename text;
json_data text;
BEGIN
filename := (SELECT setting FROM backup.settings WHERE name = 'dir') || '/wal_backup_state';
json_data := replace(trim(pg_read_file(filename)), e'\n', '');
if (json_data = '') is not false then
return;
end if;
return QUERY SELECT * FROM json_populate_recordset(null::backup.wal_history_row_type, json_data::json);
EXCEPTION
WHEN undefined_file THEN
return;
WHEN invalid_text_representation THEN
RAISE EXCEPTION '%', SQLERRM
USING DETAIL = format('history file "%s" might be corrupted', filename),
HINT = 'you may need to clean up all backup history with "SELECT backup.reset_history()"';
END;
$$
LANGUAGE plpgsql SECURITY DEFINER;
CREATE OR REPLACE FUNCTION backup.reset_history()
RETURNS void AS
$x$
DECLARE
dir text := (SELECT setting FROM backup.settings WHERE name = 'dir');
data_dir text := dir || '/backup_state';
wal_dir text := dir || '/wal_backup_state';
BEGIN
EXECUTE format('COPY (SELECT '''') TO %L', data_dir);
EXECUTE format('COPY (SELECT '''') TO %L', wal_dir);
END;
$x$
LANGUAGE plpgsql SECURITY DEFINER;
Представления
Представление backup.data_history – просмотр истории полного цикла РК. Берет информацию из локального файла $PGBACKUP/backup_state и выводит его содержимое в виде таблицы.
| Имя столбца | Тип | Описание |
|---|---|---|
session_id | text | Уникальный идентификатор сессии |
state | text | Состояние сессии |
tli | integer | Номер линии времени снятой копии |
start_time | text | Начало выполнения сессии |
start_lsn | text | Позиция WAL-сегмента при переходе БД в режим снятия РК |
stop_time | text | Конец выполнения сессии |
stop_lsn | text | Позиция WAL-сегмента при выходе БД из режима снятия РК |
duration | text | Длительность сессии (stop_time - start_time) |
stop_walfile | text | Конечный WAL-архив |
CREATE VIEW backup.data_history AS
SELECT
s.session_id,
s.state,
s.tli,
TO_TIMESTAMP(s.start_time, 'YYYY-MM-DD HH24:MI:SS') as start_time,
s.start_lsn,
TO_TIMESTAMP(s.stop_time, 'YYYY-MM-DD HH24:MI:SS') as stop_time,
s.stop_lsn,
TO_TIMESTAMP(s.stop_time, 'YYYY-MM-DD HH24:MI:SS')
- TO_TIMESTAMP(s.start_time, 'YYYY-MM-DD HH24:MI:SS') as duration,
s.stop_walfile
FROM backup.read_data_history() AS s;
Представление backup.wal_history – для просмотра истории резервных копий (РК), промежуточных WAL.
| Имя столбца | Тип | Описание |
|---|---|---|
session_id | text | Уникальный идентификатор сессии |
state | text | Состояние сессии |
start_time | text | Начало выполнения сессии |
stop_time | text | Конец выполнения сессии |
duration | text | Длительность сессии (stop_time - start_time) |
info | json | Информация о хранящихся на диске архивах WAL (собирается на старте копирования с помощью pg_probackup). В поле info помещается номер стартового и конечного архивов WAL. Если на диске отсутствуют промежуточные архивы — будет выведена ошибка, и в поле info.lost_segments будут записаны потерянные файлы |
CREATE VIEW backup.wal_history AS
SELECT
s.session_id,
s.state,
TO_TIMESTAMP(s.start_time, 'YYYY-MM-DD HH24:MI:SS') as start_time,
TO_TIMESTAMP(s.stop_time, 'YYYY-MM-DD HH24:MI:SS') as stop_time,
TO_TIMESTAMP(s.stop_time, 'YYYY-MM-DD HH24:MI:SS')
- TO_TIMESTAMP(s.start_time, 'YYYY-MM-DD HH24:MI:SS') as duration,
s.info
FROM backup.read_wal_history() AS s;
Представление backup.history – для просмотра состояния резервных копий (РК).
| Имя столбца | Тип | Описание |
|---|---|---|
session_id | text | Уникальный идентификатор сессии |
state | text | Состояние сессии |
tli | integer | Номер линии времени снятой копии |
start_time | text | Начало выполнения сессии |
start_lsn | text | Позиция WAL-сегмента при переходе БД в режим снятия РК |
stop_time | text | Конец выполнения сессии |
stop_lsn | text | Позиция WAL-сегмента при выходе БД из режима снятия РК |
duration | text | Длительность сессии (stop_time - start_time) |
CREATE VIEW backup.history AS
SELECT
d.session_id,
-- $PGDATA has been successfully backed up, look for a valid WAL backup
CASE WHEN d.state = 'completed' THEN
COALESCE(
-- WAL backup done successfully -> mark full backup record as 'completed'
(SELECT 'completed' FROM backup.wal_history w
WHERE
w.state = 'completed' AND
w.start_time >= d.stop_time AND
d.stop_walfile >= w.info -> d.tli::text ->> 'min_segno' AND
d.stop_walfile <= w.info -> d.tli::text ->> 'max_segno' LIMIT 1),
-- WAL backup has not been completed yet, but WAL session was started -> show this in our history
(SELECT 'wal_backup_started' FROM backup.wal_history w
WHERE
w.state = 'started' AND
w.start_time >= d.stop_time AND
d.stop_walfile >= w.info -> d.tli::text ->> 'min_segno'::text COLLATE "C" AND
d.stop_walfile <= w.info -> d.tli::text ->> 'max_segno'::text COLLATE "C" LIMIT 1),
-- WAL backup has not been started (or some WAL session failed) -> show that we are currently waiting for a session
'waiting_for_wal_backup')
ELSE d.state END as state,
d.tli,
d.start_time,
d.start_lsn,
d.stop_time,
d.stop_lsn,
d.duration
FROM backup.data_history d;
Развертывание на КТС
Ниже перечислены операции, которые должны быть выполнены при развертывании на КТС, где будут располагаться БД. Данные действия выполняются в автоматическом режиме при развертывании инсталлятором.
-
Создайте директорию PGBACKUP:
/pgbackup/13. -
Установите
pg_probackup. -
Создайте локальный каталог резервных копий:
pg_probackup-13 init -B $PGBACKUP. В случае, если каталог не пустой, операция завершится с ошибкой, поэтому перед установкой каталог должен быть очищен. -
Определите копируемый экземпляр резервных копий:
pg_probackup-13 add-instance -B $PGBACKUP -D $PGDATA --instance <название экземпляра>. -
Установите параметры БД:
wal_level = replica
hot_standby = on
full_pages_writes = on
archive_mode = always
archive_command = 'pg_probackup-13 archive-push -B <локальный каталог копий> --instance <экземпляр> --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4'
archive_timeout = 180 -
Добавьте параметры работы
pg_probackup:pg_probackup-13 set-config -B $PGBACKUP -D $PGDATA --instance <название экземпляра> -d <имя_базы> -h <локальный сервер> -p <локальный порт> -U <имя_пользователя>.
Ролевая модель
В силу особенностей работы Data Protector необходима выделенная роль для резервного копирования со следующими разрешениями:
BEGIN;
CREATE ROLE masteromni WITH LOGIN;
GRANT USAGE ON SCHEMA pg_catalog TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.current_setting(text) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_is_in_recovery() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_start_backup(text, boolean, boolean) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_stop_backup(boolean, boolean) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_create_restore_point(text) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_switch_wal() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_last_wal_replay_lsn() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current_snapshot() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_snapshot_xmax(txid_snapshot) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_control_checkpoint() TO masteromni;
COMMIT;
В файле pg_hba.conf необходимо разрешить подключение к кластеру баз данных пользователю с именем masteromni.
Восстановление БД из резервной копии
Для восстановления необходима новая установка СУБД Pangolin, созданная вручную. При наличии доступа к изначальному кластеру, проверить, что полная резервная копия существует:
SELECT * FROM backup.history;
Обозначение параметров
Ниже по тексту используются в качестве параметров следующие обозначения:
clustername- имя кластера на новом сервере;new_clustername- имя кластера для сервера, с которого снята резервная копия.
Это общие обозначения, которые необходимо заменить действительными. Получить их можно, например, командой:
etcdctl ls /service
Идентификатор system-identifier для файла pg_probackup.conf можно получить на сервере, с которого снята резервная копия командой (clustername в данном случае нужно заменить на имя кластера):
etcdctl get /service/clustername/initialize
Для восстановления БД кластера cluster-patroni-etcd-pgbouncer из резервной копии:
-
Остановите сервис Pangolin Manager сначала на реплике, потом на лидере:
sudo systemctl stop pangolin-manager -
Очистите каталоги
dataиtablespacesна реплике и лидере:rm -rf /pgdata/0{major_version}/data
rm -rf /pgdata/0{major_version}/tablespaces -
Очистите хранилище etcd (
clusternameзамените на действительное имя кластера):etcdctl rm -r /service/clustername -
Исправьте конфигурационный файл Pangolin Manager (
clusternameиnew_clusternameзамените на действительные лидера и реплику, добавьте секциюrecovery_confна лидере):scope: new_clustername
…
…
…
parameters:
archive_mode: 'always'
archive_command: '/usr/pgsql-se-{version}/bin/pg_probackup archive-push -B /pgarclogs/{version} --instance new_clustername --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4 --batch-size=100'
…
…
…
wal_sync_method: 'fsync'
work_mem: '16384kB'
…
…
is_tde_on: 'off'
recovery_conf:
recovery_target_timeline: latest
standby_mode: off
restore_command: /usr/pgsql-se-{version}/bin/pg_probackup archive-get -B /pgarclogs/04 --instance new_clustername --wal-file-path=%p --wal-file-name=%f -j 4 --batch-size=100
…
…
… -
Восстановите на новый сервер со старого каталоги
/pgarclogs/{version},/pgdata/{version}/data,/pgdata/{version}/tablespaces. -
Скопируйте файл
/pgarclogs/{version}/backups/clustername/pg_probackup.confв/pgarclogs/{version}/backups/new_clustername/pg_probackup.confи исправьте в немsystem-identifier(clusternameиnew_clusternameзамените на действительные имена кластеров):# Backup instance information
pgdata = /pgdata/0{major_version}/data
system-identifier = 6855546122949875180
xlog-seg-size = 16777216
# Connection parameters
pgdatabase = postgres
pghost = {IP-адрес}
pgport = {Порт}
pguser = backup_userПримечание:
IP-адрес и порт (
pghostиpgport) указаны в качестве примера. -
Запустите сервис Pangolin Manager на лидере и убедитесь, что БД запущена и загружаются файлы журналов:
sudo systemctl start pangolin-manager
less /pgerrorlogs/clustername/postgresql.log -
Запустите сервис Pangolin Manager на реплике, дождитесь синхронизации и убедитесь, что кластер перешел в синхронный режим:
sudo systemctl start pangolin-manager
pangolin-manager-ctl -c /etc/pangolin-manager/postgresql.yml list
Восстановление типа инсталляции standalone-patroni-etcd-pgbouncer
-
Остановите сервис Pangolin Manager:
sudo systemctl stop pangolin-manager -
Очистите каталоги
dataиtablespaces:rm -rf /pgdata/{version}/data
rm -rf /pgdata/{version}/tablespaces -
Очистите хранилище etcd (
clusternameзамените на действительное имя кластера):etcdctl rm -r /service/clustername -
Исправьте конфигурационный файл pangolin-manager (
clusternameиnew_clusternameзамените на действительные, добавьте секциюrecovery_conf):scope: new_clustername
parameters:
archive_mode: 'always'
archive_command: '/usr/pgsql-se-04/bin/pg_probackup archive-push -B /pgarclogs/{version} --instance new_clustername --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4 --batch-size=100'
wal_sync_method: 'fsync'
work_mem: '16384kB'
is_tde_on: 'off'
recovery_conf:
standby_mode: off
restore_command: /usr/pgsql-se-{version}/bin/pg_probackup archive-get -B /pgarclogs/{version} --instance new_clustername --wal-file-path=%p --wal-file-name=%f -j 4 --batch-size=100 -
Восстановите на новый сервер со старого каталоги
/pgbackup/0{major_version},/pgdata/0{major_version}/data,/pgdata/0{major_version}/ts(ЗНО на СРК). -
Скопируйте файл
/pgbackup/04/backups/clustername/pg_probackup.confв/pgbackup/0{major_version}/backups/new_clustername/pg_probackup.confи исправьте в немsystem-identifier(clusternameиnew_clusternameзамените на действительные имена кластеров):# Backup instance information
pgdata = /pgdata/{version}/data
system-identifier = 6855546122949875180
xlog-seg-size = 16777216
# Connection parameters
pgdatabase = postgres
pghost = {IP-адрес}
pgport = {Порт}
pguser = backup_user -
Запустите сервис Pangolin Manager и убедитесь, что БД запустилась и загружаются файлы журналов (в логах отсутствуют ошибки проигрывания WAL-файлов):
sudo systemctl start pangolin-manager
less /pgerrorlogs/clustername/postgresql.log
Восстановление типа инсталляции standalone-postgresql-only или standalone-postgresql-pgbouncer
Примечание:
Различий в восстановлении типов кластера standalone-postgresql-only и standalone-postgresql-pgbouncer нет.
-
Остановите сервис PostgreSQL :
sudo systemctl stop postgresql.service -
Очистите каталоги
dataиtablespaces:rm -rf /pgdata/{version}/data
rm -rf /pgdata/{version}/tablespaces -
Создайте конфигурационный файл
recovery.conf:recovery_target_timeline = 'latest'
restore_command = '/usr/pgsql-se-04/bin/pg_probackup archive-get -B /pgarclogs/{version} --instance new_clustername --wal-file-path=%p --wal-file-name=%f -j 4 --batch-size=100' -
Восстановите на новый сервер со старых каталогов
/pgbackup/{version},/pgdata/{version}/data,/pgdata/{version}/ts(ЗНО на СРК). -
Скопируйте файл
/pgbackup/04/backups/clustername/pg_probackup.confв/pgbackup/04/backups/new_clustername/pg_probackup.confи исправьте в немsystem-identifier(clusternameиnew_clusternameзамените на действительные имена кластеров):# Backup instance information
pgdata = /pgdata/{version}/data
system-identifier = 6855546122949875180
xlog-seg-size = 16777216
# Connection parameters
pgdatabase = postgres
pghost = {IP-адрес}
pgport = {Порт}
pguser = backup_user -
Запустите сервис PostgreSQL, чтобы убедиться что БД запустилась, и загружаются файлы журналов (в логах отсутствуют ошибки проигрывания WAL-файлов):
sudo systemctl start postgresql.service
less /pgerrorlogs
/clustername/postgresql.log
Восстановление сервера реплики из резервной копии
-
Остановите сервис pangolin-manager на реплике:
sudo systemctl stop pangolin-manager -
Очистите каталоги
dataиtablespacesна реплике:rm -rf /pgdata/{version}/data
rm -rf /pgdata/{version}/tablespaces -
Исправьте конфигурационный файл pangolin-manager (добавьте секцию
recovery_conf):parameters:
archive_mode: 'always'
archive_command: '/usr/pgsql-se-04/bin/pg_probackup archive-push -B /pgarclogs/{version} --instance new_clustername --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4 --batch-size=100'
wal_sync_method: 'fsync'
work_mem: '16384kB'
is_tde_on: 'off'
recovery_conf:
recovery_target_time: latest
standby_mode: off
restore_command: /usr/pgsql-se-{version}/bin/pg_probackup archive-get -B /pgarclogs/{version} --instance new_clustername --wal-file-path=%p --wal-file-name=%f -j 4 --batch-size=100Внимание!Исполненных WAL-файлов будет недостаточно для того, чтобы успеть за состоянием ведущего сервера, если нагрузка на ведущий сервер не будет снижена. Необходимо снятие резервную копии WAL-файлов ведущего сервера, а так же настроить синхронизацию директорий с помощью
lsyncd. -
Восстановите на новый сервер со старого каталоги
/pgbackup/{version},/pgdata/{version}/data,/pgdata/{version}/ts(ЗНО на СРК). -
Запустите сервис pangolin-manager и убедитесь, что БД запустилась и загружаются файлы журналов, дождитесь синхронизации и убедитесь, что кластер перешел в синхронный режим:
sudo systemctl start pangolin-manager
less /pgerrorlogs/clustername/postgresql.log
Шаблон параметров формирования SRC спецификаций для резервного копирования
Ниже приведен пример шаблона параметров формирования SRC спецификаций для резервного копирования (файл datalist_serveraXserverb_RUN_PG_FULL.j2, где servera - имя мастера-сервера, serverb - имя реплицирующего сервера):
DATALIST "hostname-serveraXhostname-serverb_RUN_PG_FULL"`
GROUP "DININFRA"
DESCRIPTION "PostgreSQL_SE"
RECONNECT
DYNAMIC 1 1
POSTEXEC "patroni_session_run.sh" -on_host "{{ data_protector_host }}"
DEFAULTS
{
FILESYSTEM
{
-vss no_fallback
} -protect days 3
RAWDISK
{
}
}
DEVICE "{{ device }}"
{
}
FILESYSTEM "fqdn-servera" fqdn-serverb:"/"
{
-trees
"/etc/opt/omni/client/cell_server"
}
FILESYSTEM "fqdn-serverb" fqdn-serverb:"/"
{
-trees
"/etc/opt/omni/client/cell_server"
}
А также шаблон формирования расписания создания резервной копии (файл schedule_serveraXserverb_RUN_PG_FULL.j2, где servera - имя мастер-сервера, serverb - имя реплицирующего сервера):
-full
-every
-day
-at {{ (23,0,1,2) |random }}:{{ '%02d' | format( 59 | random | int )}}
Снятие резервной копии с реплики
Функция резервного копирования позволяет снять с базы данных архивную копию, которую в дальнейшем можно использовать для восстановления. СУБД Pangolin поддерживает создание резервной копии как с лидера, так и с реплики.
Резервное копирование выполняется командой:
PGPASSWORD={backup_pass} pg_probackup backup -B {PGBACKUP} --instance {cluster_name} -b FULL
Восстановление из резервной копии:
pg_probackup restore -B {PGBACKUP} --instance {cluster_name} --recovery-target='latest'
Процедуры резервного копирования на главном сервере и на копии принципиально идентичны.