Глобальные индексы и глобальные ограничения на партиционированные таблицы
Описание
Партиционирование — это процесс разбиения логически одной большой таблицы на несколько физических частей. Такой подход дает ряд преимуществ:
- В определенных случаях работа с таблицей становится значительно быстрее, особенно если большая часть активно используемых строк находится всего в одном или нескольких разделах. Партиционирование может заменить верхние уровни индексов, что повышает шанс того, что наиболее востребованные их части будут находиться в оперативной памяти.
- Если запросы или обновления затрагивают значительную часть одного раздела, можно использовать последовательное сканирование этого раздела вместо индексного поиска. Это снижает количество случайных чтений, распределенных по всей таблице.
- Если архитектура партиционирования построена с учетом сценариев использования, можно добавлять или удалять целые разделы вместо выполнения массовых операций. Например, команды
DROP TABLEилиALTER TABLE DETACH PARTITION, применяемые для отдельного раздела, работают намного быстрее, чем массовое удаление строк, и не требуют последующей очистки (VACUUM). - Данные, к которым редко обращаются, можно переместить на более дешевые и медленные носители.
В СУБД Pangolin реализован механизм глобальных индексов, способных физически покрывать сразу множество таблиц и обеспечивающих ограничение уникальности по набору атрибутов (даже не включающих ключ партиционирования).
Функциональность глобального индекса входит только в редакцию Enterprise и Enterprise для ERP-систем. Без данной лицензии создание новых глобальных индексов недоступно (при последующем понижении лицензии с СУБД Pangolin Enterprise функционирование ранее созданных глобальных индексов сохраняется).
Создание глобального индекса
Синтаксис для создания глобального индекса:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON [ ONLY ] table_name
[ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass [ ( opclass_parameter = value [, ... ] ) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ INCLUDE ( column_name [, ...] ) ]
[ WITH ( storage_parameter [= value] [, ... ] ) ]
[ GLOBAL ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]
Глобальные индексы реализуются как надстройка над механизмом B-Tree индексов PostgreSQL. Объявление индекса как глобального выполняется через указание клаузы GLOBAL в запросе CREATE INDEX для партиционированной таблицы. Для индексов по другим видам отношений клауза GLOBAL смысла не имеет, а запрос создания глобального индекса будет завершаться с ошибкой. Уникальность глобального индекса, аналогично неглобальному индексу, определяется через клаузу UNIQUE в запросе CREATE INDEX.
Глобальный индекс поддерживает все операции над партициями и партиционированными таблицами - ATTACH, DETACH, DROP, VACUUM, VACUUM FULL, REINDEX, CLUSTER, а также DML-операции.
Статистическая информация о файле глобального индекса корректно отображается в представлениях pg_stat_all_indexes и pg_statio_all_indexes.
Команда psql \di+, выборки из каталогов pg_class и pg_index позволяют однозначно идентифицировать глобальный индекс как глобальный, а также получить информацию занимаемому им объему памяти. Выборка из каталога pg_inherits позволяет однозначно определить все дочерние индексы глобального индекса.
Настроечные параметры фонового процесса автоматического слияния глобальных индексов поддерживаются как валидатором компонента оркестратора кластера высокой доступности (Pangolin Manager), так и пользовательским конфигурационным файлом инсталлятора Pangolin.
Глобальный индекс поддерживает перемещение между табличными пространствами через команду ALTER INDEX SET TABLESPACE и перемещение партиций между табличными пространствами через команду ALTER TABLE SET TABLESPACE.
Создание глобального индекса успешно попадает в дамп схемы базы данных при использовании утилит pg_dump и pg_dumpall, в том числе в режиме --binary-upgrade для работы утилиты pg_upgrade.
Данные в глобальном индексе подпадают под преобразование TDE.
Ограничения
Ограничения при использовании глобальных индексов:
- Реализуется только для типа B-Tree.
- Не поддерживает ограничения-исключения и субпартиционирование, Bottom-up Index Deletion, Deduplication.
- При операции построения/перестроения глобального индекса, вне зависимости от его физического нахождения и табличного пространства, саб-индексы всегда создаются в каталоге
pg_data/base/pgsql_tmp. Это теоретически может спровоцировать нехватку памяти для выполнения команды и вызвать падение кластера. О том, как рассчитать память для построения/перестроения глобального индекса, рассмотрено в разделе «Процесс построения глобального индекса. - При перестроении глобального индекса (
REINDEX INDEX CONCURRENTLY) на автопартиционированной таблице невозможно выполнить операциюINSERT, которая в свою очередь сгенерирует новую партицию. - Очистка страниц индекса не может выполняться параллельно двумя процессами. Так как операция
VACUUMдля партиции приводит к удалению ссылок на ее кортежи в глобальном индексе, может возникнуть ситуация одновременной попытки очистки глобального индекса несколькими процессами. Во избежание коллизий на уровне постраничной очистки процесс будет пытаться захватить блокировкуShareUpdateExclusiveLock, которая доступна только одной транзакции.
Партиционированная таблица с ограничением Primary Key Global не поддерживает присоединение таблицы с уже существующим Primary Key с помощью команды ATTACH.
Для автопартиционированных таблиц невозможно выполнение команды INSERT, которая создаст новую партицию, если в предыдущих партициях присутствует саб-индекс.
Глобальные ограничения
Для партиционированных таблиц поддерживаются два вида глобальных ограничений с использованием глобальных индексов:
- глобальный первичный ключ;
- глобальный уникальный ключ.
Особенности глобальных ограничений:
- могут быть построены только по партиционированной таблице;
- ссылаются на уникальный глобальный индекс, привязанный к партиционированной таблице, а не на его саб-индекс для соответствующей партиции. Таким образом, зависимость от ограничения на партиционированной таблице и всех ее партициях имеет не саб-индекс, соответствующий партиции, а глобальный индекс, привязанный к партиционированной таблице;
- могут быть построены по любому уникальному
NOT NULL-полю, имеющемуся в каждой из партиций таблицы, при этом включение полей ключа партиционирования не является обязательным; - не могут быть построены по партиционированным таблицам с субпартициями в силу ограничений существующей реализации глобальных индексов;
- на созданные глобальные ограничения могут ссылаться внешние ключи с любых других таблиц, при этом ограничения целостности поддерживаются в полном объеме;
- в системном каталоге
pg_constraintглобальным ограничениям соответствуют новые значения поляcontype:'P'- для глобального первичного ключа,'U'- для глобального уникального ключа; - под глобальными ограничениями работает механизм глобальных индексов, поэтому для обслуживания физической структуры глобальных ограничений необходимо применять инструментарий глобальных индексов, включая конструкцию
ALTER TABLE .. UNITEпо соответствующему индексу, а также процесс автообъединения глобальных индексов; - если в партиционированной таблице создается глобальный индекс с ограничением Primary Key, а какая-либо партиция уже имеет свой локальный Primary Key, это приведет к ошибке. В сообщении об ошибке будет указано, что таблица не может иметь два ограничения Primary Key.
Синтаксис создания глобальных ограничений базируется на синтаксисе создания ограничений партиционированных таблиц с добавлением клаузы GLOBAL.
Пример №1:
CREATE TABLE t1 (
id bigint PRIMARY KEY GLOBAL,
someint bigint
) PARTITION BY RANGE (someint);
Пример №2:
CREATE TABLE measurement_1 (
id int not null,
logdate date not null,
peaktemp int not null,
unitsales int,
CONSTRAINT m_ui UNIQUE(peaktemp) GLOBAL
) PARTITION BY RANGE (id, logdate);
Пример №3:
CREATE TABLE measurement_2 (
id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (id, logdate);
ALTER TABLE measurement_2 ADD PRIMARY KEY (logdate) GLOBAL;
Глобальный индекс
Глобальный индекс — это индексная структура, которая охватывает все партиции партиционированной таблицы, включая кортежи из каждой партиции. Физически он работает как единый индекс, созданный для всей партиционированной таблицы. Кроме того, такой глобальный индекс может включать набор подиндексов, каждый из которых привязан к определенной партиции и индексирует только кортежи из этой партиции.
Метод доступа для сканирования глобального индекса не отличается от стандартного метода доступа в B-Tree. Чтение строк таблиц, на которые указывают индексные кортежи, полученные в результате сканирования глобального индекса, выполняется с подменой отношения.
При вставке в глобальный индекс захватывается блокировка RowExclusiveLock, которая не блокирует чтение и запись из других транзакций. Вставка дубликатов в разные партиции в параллельных транзакциях приведет к параллельной вставке дубликатов в глобальном индексе, которая не нарушит ограничение уникальности.
В некоторых ситуациях для оптимизации работы с глобальными индексами у них могут возникать саб-индексы.
Глобальный индекс представляет собой реальный B-Tree индекс, у которого могут быть дочерние B-Tree индексы.
Саб-индекcы отвечают за свои партиции, а за все остальные партиции (без саб-индексов) отвечает основной индекс.
Схема его структуры:
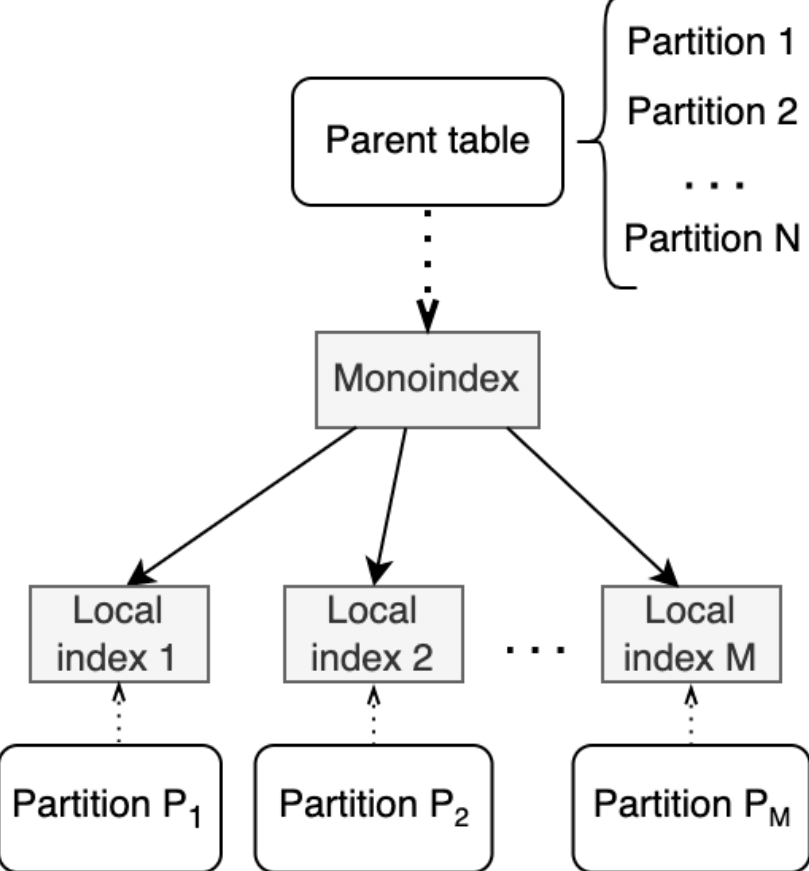
Сканирование глобального индекса включает чтение основного индекса и, при наличии, объединение результатов, полученных из всех его саб-индексов:
Append:
Index Scan using parent index
[Index Scan using local index 1]
...
[Index Scan using local index M]
Проверка уникальности в глобальном индексе
При вставке в уникальный глобальный индекс проверка на уникальность проводится по основному индексу и всем саб-индексам (если существуют). При этом на все части захватывается блокировка RowExclusiveLock.
Настройка
Подмена отношения
Так как индексный кортеж в глобальном индексе содержит информацию о таблице, в которую указывает CTID, все базовые операции, связанные с чтением кортежа из таблицы после сканирования, используют механизм подмены отношения:
-
Чтение
OID-атрибута из индексного кортежа. -
Обращение к кешу глобольного индекса по заданному
OID:- если кеш вернул
NULL, то обрабатывается индексный кортеж, ссылающийся на запись в таблице, которая не видна ни одной транзакции. В таком случае эти кортежи пропускаются при обработке, то есть данных из такой таблицы не будет. Проверка на список партиций уже имеется; - если возвращено валидное состояние открытого отношения, то индексный кортеж является ссылкой на запись. В таком случае чтение и проверка видимости будут происходить непосредственно в этом отношении.
- если кеш вернул
Любое обращение DDL\DML к глобальному индексу или таблице с глобальными индексами (при этом открытие отношений для подмены происходит только при непосредственном обращении, например, через индексные методы доступа) является внешней операцией.
Кеш глобального индекса инициализируется в начале внешней операции, освобождается по ее завершении и состоит из:
- хеш-таблицы
H = (OID, Relation), отображающейOIDв состояние открытого отношения; - упорядоченного списка
S = [OID]идентификаторов таблиц, покрываемых глобальным индексом.
При обращении к кешу выполняется поиск в хеш-таблице по заданному OID:
-
если в хеш-таблице элемент с таким
OIDотсутствует – проверяется входит ли он в списокS:- если не входит в список – возвращается
NULL; - если входит – соответствующее отношение открывается без блокировки,
OIDдобавляется в хеш-таблицу, и возвращается полученное состояние.
- если не входит в список – возвращается
-
если элемент найден в хеш-таблице — возвращается его значение.
Процесс построения глобального индекса
При отсоединении партиции, то есть при вызове ALTER TABLE DETACH PARTITION, глобальный индекс не изменяется, а все ссылки на кортежи отсоединенной партиции остаются в нем. При выполнении операций подмена отношения для индексных кортежей, ссылающихся на отсоединенные партиции, возвращает NULL.
При использовании VACUUM (не VACUUM FULL) со страниц глобального индекса удаляются все индексные кортежи, подмена отношений для которых возвращает NULL.
Управление
Анализирование структуры глобального индекса
Проанализировать глубину структуры глобального индекса (BLevel) можно при помощи расширения pageinspect:
CREATE EXTENSION pageinspect;
SELECT btpo_level FROM bt_page_stats('globidx_name', (SELECT root FROM bt_metap('globidx_name')) );
или выполнив:
SELECT level FROM bt_metap('globidx_name');
ATTACH/DETACH PARTITION при использовании глобальных индексов
Отсоединение партиций
При отсоединении партиции с помощью команды ALTER TABLE ... DETACH PARTITION, глобальный индекс не изменяется, а все ссылки на кортежи отсоединенной партиции остаются в нем. При выполнении SQL-запросов, подмена отношения для индексных кортежей, ссылающихся на отсоединенные партиции, возвращает NULL. Если у отсоединяемой партиции есть дочерний локальный индекс, он также отсоединяется от глобального индекса.
Присоединение партиций
При добавлении новой партиции, происходит создание локального саб-индекса. Если глобальный индекс является уникальным, то после сортировки кортежей в процессе построения локального индекса выполняется сравнение отсортированных кортежей с частью глобального индекса на наличие пересечений по ключу. Это сравнение реализовано с использованием алгоритма, аналогичного merge-этапу алгоритма merge-sort, при котором происходит параллельный проход по отсортированным кортежам и листовым страницам глобального индекса. В данном случае на основной индекс и также на саб-индексы (если существуют) устанавливается блокировка ShareRowExclusiveLock.
Если при попытке присоединения обнаруживается дублирование ключей между новой партицией и основной таблицей, операция завершается с ошибкой:
vmtest_db=> alter table vm_schema.vmtest_table
vmtest_db-> attach partition vm_schema.vmtest_table_add
vmtest_db-> for values from ('2024/07/01 00:00:00')
vmtest_db-> to ('2024/08/01 00:00:00');
ERROR: could not create index "vmtest_table_add_id_tableoid_idx",
part of unique global index "unq_vmtest_table__idx"
DETAIL: Key (id)=(60000000) is duplicated.
HINT: Duplicate keys are first encountered in "vmtest_table_20240101"
Если присоединяемая таблица уже имеет локальный индекс, то он не пересоздается, а используется существующий.
В контексте глобальных индексов, локальными индексами (так же называемыми саб-индексами) называют локальные индексы, которые относятся к глобальному индексу. Локальные индексы объединяются с глобальным индексом благодаря запросу UNITE (или через autounite).
Оригинальным индексом обозначается стандартный B-Tree индекс оригинального PostgreSQL.
Требования к свободному пространству
Для глобального индекса размером 500 ГБ при каждом добавлении/удалении партиции нужно иметь не менее 700 ГБ свободного места в PGDATA. Например, при выполнении команд:
ALTER TABLE .... ATTACH PARTITION part_1;
ALTER TABLE .... ATTACH PARTITION part_2;
Сначала строятся локальные индексы для новых партиций таблицы (саб-индексы). Допустим, размер каждого из вновь созданных индексов составляет 100 ГБ.
Далее при выполнении ALTER INDEX ... UNITE; происходит объединение трех индексов (исходный глобальный индекс и два локальных индекса присоединенных партиций в новый глобальный индекс).
Для построения глобального потребуется еще 500 + (2 * 100) = 700 ГБ.
Исходные индексы (исходный глобальный индекс и два локальных индекса присоединенных партиций) удаляются только после успешного построения нового глобального индекса.
Объединение саб-индексов в один глобальный индекс
Тривиальный подход к построению глобального индекса для набора партиций заключается в создании пустого индекса и последовательной вставке в него всех кортежей из всех партиций. При каждой вставке выполняется проход от корневой страницы индекса к соответствующей листовой странице. Асимптотическая сложность такого подхода составляет O(N × log N), где N — общее количество кортежей во всех партициях.
Поскольку каждая операция вставки сопровождается чтением кортежей и модификацией структуры индекса, что вызывает значительное количество операций ввода-вывода, такой способ оказывается неэффективным и приводит к неприемлемому времени построения индекса в производственной среде.
Для ускорения объединения саб-индексов в один глобальный индекс в СУБД Pangolin введен метод построения слиянием (ambuildmerge). Слияние происходит в одном потоке.
Слияние B-Tree
Листовой уровень страниц в B-Tree представляет собой упорядоченный связный список. Если для какого-то отношения имеется B-Tree индекс, необходимость в сортировке кортежей этого отношения по соответствующем набору атрибутов отсутствует. Метод построения слиянием (ambuildmerge) использует этот факт для слияния множества B-Tree индексов с одинаковым определением в единый глобальный индекс.
Алгоритм объединения саб-индексов в один глобальный индекс слиянием:
- Инициализация итераторов: для каждого индекса открывается, привязывается и блокируется на чтение буфер, соответствующий крайней левой странице. Итераторы предоставляют интерфейс последовательного чтения индексных кортежей.
- Инициализация двоичной кучи, куда вставляются итераторы каждого индекса. Двоичная куча выдает итератор, указывающий на кортеж с минимальным ключом. Это аналог k-way merge алгоритма для объединения
kотсортированных массивов в один отсортированный. - Bulk-loading (пакетная загрузка) кортежей в новый индекс, где двоичная куча предоставляет интерфейс отсортированного массива всех кортежей из всех индексов.
Схема слияния B-Tree:
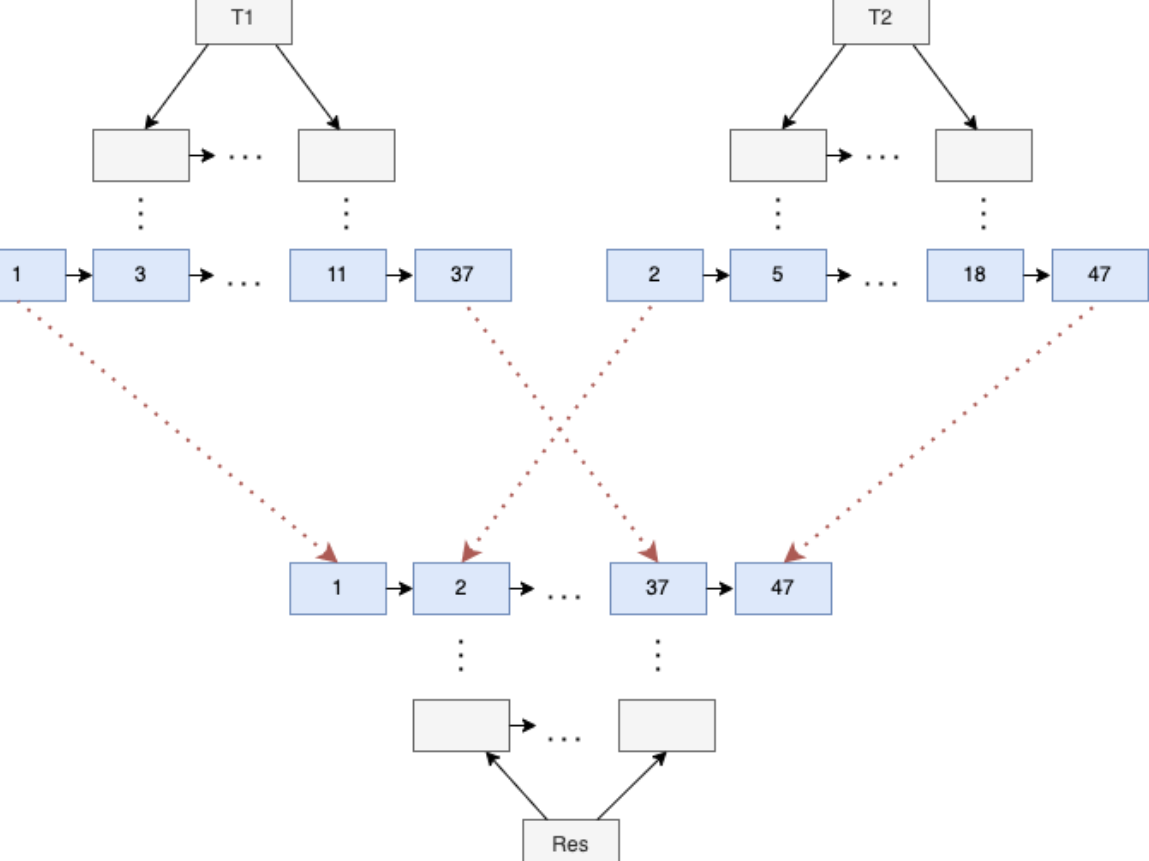
Асимптотическая сложность алгоритма — O(N × log k), где k — количество объединяемых партиций.
Данный алгоритм слияния B-Tree используется внутри запроса ALTER INDEX UNITE [CONCURRENTLY], который объединяет родительский индекс и дочерние локальные индексы в новый глобальный индекс, при этом удаляя дочерние. Также в процессе autounite и при построении/перестроении глобальных индексов.
ALTER INDEX UNITE
При большом количестве саб-индексов глобальный индекс становится партиционированным индексом, что сводит на нет его преимущества. Поэтому в СУБД Pangolin реализована команда ALTER INDEX UNITE, которая объединяет родительский индекс и его дочерние индексы в новый глобальный индекс, удаляя при этом дочерние:
ALTER INDEX name UNITE;
Кроме того, существует фоновый процесс autounite, выполняющий ту же операцию автоматически.
Эта команда состоит из следующих шагов:
- захват блокировки
ShareUpdateExclusiveLock(илиShareLockеслиunite_concurrently = off) на родительскую таблицу и все саб-индексы; - создание пустой копии X глобального индекса;
ambuildmerge- слияние всех частей глобального индекса. При этом параллельные транзакции могут модифицировать данные в его саб-индексах;- ожидание завершения всех транзакций, для которых видны части глобального индекса с саб-индексами;
- валидация индекса включает в себя сравнение всех его кортежей с кортежами во всех частях глобального индекса с саб-индексами, а также вставку в индекс недостающих кортежей. При
unite_concurrently = offданный шаг пропускается; - swap-процесс X-индекса и старого глобального индекса;
- удаление дочерних индексов.
Процесс объединения для глобальных индексов
В СУБД Pangolin реализован механизм объединения глобальных индексов, обеспечивающий возможность фоново выполнять слияние саб-индексов в один глобальный индекс. Эта функциональность представлена двумя взаимосвязанными возможностями: ручным объединением (UNITE) и автоматическим объединением (autounite).
UNITE
Функция UNITE предоставляет механизм для объединения или слияния саб-индексов в глобальный индекс с возможностью переключения между конкурентным и неконкурентным режимами для оптимизации производительности в зависимости от конкретных случаев использования.
Настройка unite_concurrently позволяет переключаться между конкурентным и неконкурентным режимами UNITE. По умолчанию эта настройка включена, что означает использование конкурентного режима.
Использование конкурентного режима UNITE
Конкурентный режим подходит, когда необходимо обеспечить непрерывный доступ к чтению и записи во время выполнения операции UNITE.
Чтобы включить конкурентный режим UNITE, необходимо установить параметр unite_concurrently в значение on (включено по умолчанию):
ALTER SYSTEM SET unite_concurrently TO on;
SELECT pg_reload_conf();
В этом режиме система использует блокировку sharedUpdateExclusiveLock, что позволяет пользователям продолжать чтение и запись в базе данных. Сессионные блокировки и sharedUpdateExclusiveLock применяются к самой таблице, всем ее разделам и всем глобальным саб-индексам, связанных с таблицей.
Для процессов autounite рабочие процессы всегда запущены в режиме CONCURRENTLY.
Использование неконкурентного режима UNITE
Данный режим рекомендуется, когда операция UNITE должна быть выполнена быстро и надежно, особенно при работе с большим количеством саб-индексов. Требует эксклюзивного доступа к таблице и ее компонентам, временно блокируя операции чтения и записи. Может быть вызвана в транзакционном блоке.
Чтобы выключить конкурентный режим UNITE, установите параметр unite_concurrently в значение off:
ALTER SYSTEM SET unite_concurrently TO off;
SELECT pg_reload_conf();
Когда unite_concurrently установлено в значении off, система не использует параллельный режим, который разработан для более быстрой и надежной работы, особенно при большом количестве саб-индексов.
Непараллельный режим обеспечивает более быструю процедуру UNITE.
autounite
Функция autounite, аналогичная autovacuum, поддерживает несколько рабочих процессов. Пользователи могут контролировать количество рабочих процессов, устанавливая параметр autounite_max_workers. Каждый рабочий процесс работает с одной базой данных. При необходимости нескольким рабочим процессам можно назначить одну и ту же базу данных.
Несмотря на возможность работы нескольких рабочих процессов с одной и той же базой данных, они будут пропускать разделенные таблицы, если другой рабочий процесс уже их обрабатывает. Это поведение сохраняется, даже если у разделенной таблицы больше одного глобального индекса.
Параметр autounite_enabled
Параметр autounite_enabled управляет автоматическим выполнением процесса Unite для конкретного глобального индекса. Поведение зависит от его значения:
- если
autounite_enabledотключен, процессUniteдля этого индекса не выполняется. Это дает пользователю возможность запускатьUniteвручную, в удобное время; - если
autounite_enabledвключен после того, как индекс уже был добавлен в очередь обработки фонового процессаautounite, процессUniteвсе равно будет выполнен в текущем цикле. Настройка начнет учитываться только при следующих циклах запуска.
Создание глобального индекса с выключенным autounite:
CREATE INDEX index_name ON table_name(column_name) WITH (autounite_enabled = false) global;
Изменение параметра на существующим глобальном индексе:
ALTER INDEX tvac_id_gidx SET (autounite_enabled = false);
Проверка состояния параметра конкретного глобального индекса:
SELECT relname, reloptions FROM pg_class WHERE relname = 'index_name';
Отключение autounite
Для отключения автоматического объединения саб-индексов в глобальный индекс выполните команду:
ALTER SYSTEM SET autounite TO off;
SELECT pg_reload_conf();
При отключении этой функциональности необходимо самостоятельно производить ручное объединение саб-индексов с помощью команды ALTER INDEX index_name UNITE.
Для отключения параллельного выполнения autounite выполните команду:
ALTER SYSTEM SET autounite_max_workers = 1;
SELECT pg_reload_conf();
Мониторинг процесса Unite
Для мониторинга прогресса процесса Unite можно использовать один из следующих методов:
- уровень логирования
Debug1– получение подробных логов процессаUnite; - представление
pg_stat_progress_unite– доступно для мониторинга общего процессаUniteпо всем базам данных. Это представление предоставляет информацию в реальном времени о прогрессе и статусе процессаUnite.
При создании глобальных индексов в разделенных таблицах, которые наследуются от других таблиц или которые имеют в качестве наследников другие разделенные таблицы, выводится ошибка:
global indexes are not supported on partitioned tables that are partitions
cannot create global index on partitioned table '%s' : Table '%s' contains partitions that are partitioned tables.
Для мониторинга процесса построения и перестроения глобальных индексов можно использовать представление pg_stat_progress_create_index, которое предоставляет информацию о текущем состоянии операции создания индекса, включая количество обработанных страниц и кортежей.
Для обеспечения фонового объединения глобальных индексов в продукт добавлены процессы автообъединения. Процесс автообъединения может быть запускающим или выполняющим работу по автообъединению.
Процесс-инициатор постоянно находится в памяти и периодически активирует задачу автообъединения в заданной базе данных с интервалом, заданным параметром autounite_naptime. При каждом запуске он инициирует объединение глобальных индексов, которые имеют дочерние индексы (саб-индексы) и соответствуют условиям настройки автообъединения. По умолчанию объединению подлежат все такие глобальные индексы.
Настройки автообъединения:
| Параметр | Тип | Значение | Описание |
autounite | bool | По умолчанию true | Флаг включения процесса автообъединения |
autounite_naptime | int | По умолчанию 60 | Интервал между запусками автообъединения на одной базе данных (в секундах) |
autounite_parent_children_size_ratio | int | Диапазон – 0 – 1024. По умолчанию 0. | Соотношение суммарного размера саб-индексов к размеру родительского глобального индекса, при превышении которого выполняется автообъединение. Например, значение 0 - автобъединение без анализа соотношения размеров, 1 - соотношение предка к потомкам 1:1 (объединение будет выполнено, как только суммарный размер индексов потомков превысит размер глобального индекса предка); 2 - соотношение предка к потомкам 1:2 (объединение будет выполнено, как только суммарный размер индексов потомков превысит 1/2 от размера глобального индекса предка) и так далее |
autounite_max_children_count | int | Диапазон – 0–INT_MAX. По умолчанию 0 (автообъединение без учета количества потомков) | Максимальное количество субиндексов, при котором автообъединение не выполняется |
autounite_pause_period | string | Формат ЧЧ-ЧЧ, например, 11-13 — период с 11:00 до 12:59:59 По умолчанию '' (период бездействия отсутствует) | Временной интервал, в который автообъединение не выполняется |
Особенности работы команд TRUNCATE/VACUUM FULL/CLUSTER с глобальными индексами
При выполнении команд TRUNCATE/VACUUM FULL/CLUSTER на таблицах или партициях, содержащих глобальные индексы, изменяется структура индекса. Если команды:
- применяются к отдельной партиции, на ней автоматически создается саб-индекс — временный локальный индекс;
- выполняются на родительской таблице, происходит перестроение глобального индекса.
Autovacuum глобальных индексов
autovacuum для партиционированной таблицы, у которой есть хотя бы один глобальный индекс, собирает информацию о количестве записей в партициях, отсоединенных в pg_stat_all_tables.n_dead_tuples. В процесс autovacuum launcher добавлена обработка партиционированных таблиц. Для них запускается очистка, если pg_stat_all_tables.n_dead_tuples >= autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * reltupes, где reltuples - это сумма pg_class.reltuples всех партиций. Очистка – специальный вид постраничной очистки B-Tree, не требующий сканирования таблиц и удаляющий все индексные кортежи, которые относятся к уже отсоединенным партициям. После очистки значение pg_stat_all_tables.n_dead_tuples для партиционированной таблицы обнуляется.
Параметры autovacuum на уровне таблицы:
autovacuum_vacuum_threshold- целое положительное число, свободный коэффициент в неравенствеautovacuum launcher;autovacuum_vacuum_scale_factor- коэффициент, определяющий суммарную долю записей в партициях;autovacuum_enabled- логический параметр, для включения/отключенияautovacuumна уровне таблицы.
Процесс очистки сначала накладывает блокировку на партиционированную таблицу в режиме SHARE UPDATE EXCLUSIVE. Далее устанавливаются блокировки в зависимости от наличия глобальных индексов. Если:
- у партиционированной таблицы существуют глобальные индексы, то на них накладывается блокировка в режиме
ROW EXCLUSIVE; - глобальных индексов нет, блокировка с партиционированной таблицы снимается.
Использование планов сканирования глобального индекса
Выборка данных из таблицы может осуществляться по столбцам, для которых используется глобальный индекс. Также могут быть получены данные только тех столбцов, которые связаны глобальным индексом.
Для настройки планов сканирования могут использоваться параметры:
enable_globalindexonpartition– включает или отключает сканирование по глобальному индексу, при этом, если параметр включен, то при прямых запросах к разделам разбитой таблицы глобальный индекс может использоваться как «локальный» индекс раздела. Если параметр имеет значениеfalse, то применяетсяseqscanи другие;enable_globalindexscan- включает или отключает сканирование по глобальному индексу;enable_globalindexonlyscan- включает или отключает сканирование только по глобальному индексу;enable_globalindex_extensiveplan- разрешает использовать глобальный индекс напрямую при построении плана сканирования партиционированной таблицы. Это ускоряет этап планирования запросов и позволяет получить более точную оценку стоимости выполнения. Данный план строится только для запросов, которые используютWHERE field = ....
Значение по умолчанию каждого из параметров - true (включен), контекст - PGC_USERSET.
Процесс резервного копирования и восстановления глобальных ограничений (pg_dump/pg_restore)
Глобальные ограничения выгружаются без использования параметра ONLY в командах ALTER TABLE ... ADD CONSTRAINT. Это обусловлено тем, что при создании глобального индекса требуется также создание саб-индексов для партиций партиционированной таблицы, а использование ONLY блокирует такое построение.
Во время восстановления логического дампа с параметром --binary-upgrade данный режим временно отключается на этапе построения саб-индексов глобального индекса, связанного с глобальным ограничением. Это связано с тем, что OID, указанный в дампе, относится только к основному глобальному индексу и не может быть применен к создаваемым в процессе саб-индексам. После завершения построения глобального индекса режим --binary-upgrade снова активируется, а временные саб-индексы удаляются. Это предотвращает конфликт с последующим созданием объектов, использующих те же OID, что могли быть задействованы при построении глобального индекса.
Параллелизм при построении и перестраивании глобальных индексов
Реализована возможность выполнять команду с установленными параметрами параллелизма или с использованием настроек по умолчанию. При параллелизации каждый рабочий узел работает со своей партицией. Для явного указания количества рабочих узлов применяется конструкции WITH, где указывается новая опция subindex_parallel_worker, отвечающая за количество запущенных процессов. Их количество не может превышать заданный максимум, указанный в параметре subindex_build_max_workers:
CREATE INDEX idx_name ON table_name (column_name) WITH (subindex_parallel_worker = 3) GLOBAL;
Для перестраивания индекса укажите количество рабочих процессов через замену параметра subindex_parallel_worker:
ALTER INDEX idx_name SET (subindex_parallel_worker = 3);
Возможность параллельного построения распространяется также на оригинальные индексы, если нет субпартиций. Процесс объединения (merge) остается однопоточным.
Добавлено три новых параметра:
| Параметр | Описание | Значение по умолчанию | Контекст |
subindex_build_max_workers | Определяет максимальное количество рабочих процессов, используемых при параллельном построении саб-индексов (локальных индексов партиций) | 3 | postmaster |
partitioned_index_parallel_build | Управляет возможностью параллельного построения обычных (оригинальных) индексов на партиционированных таблицах по умолчанию | false | user |
global_index_parallel_build | Управляет возможностью параллельного построения глобальных индексов по умолчанию | true | user |
Построение и перестраивание глобального индекса также доступно в режиме CONCURRENTLY.