Миграция на текущую версию
Внимание!
Перед выполнением обновления рекомендуется сделать резервную копию базы данных, чтобы иметь возможность вернуться к первоначальному состоянию в случае возникновения ошибок.
Чтобы выполнить обновление Pangolin:
-
Скачайте и распакуйте дистрибутив на сервере.
-
Перейдите в каталог с распакованным дистрибутивом, а затем в каталог
installer. -
Перед запуском обновления заполните файл
hosts.ini, в зависимости от установленного решения, добавив информацию о хостах и учетных данных пользователя, которые будет использовать Ansible.Внимание!
Данные должны содержать те же параметры, что и при установке.
-
Заполните настраиваемый конфигурационный файл
custom_file.yml. -
Заполните конфигурационный файл
all.yml. -
Выполните ansible-сценарий. Далее приведены шаблоны ansible-сценариев для обновления различных решений:
-
Обновление standalone решения:
ansible-playbook playbook_updates.yaml \
-i inventories/standalone/hosts.ini \
-t always,standalone \
--ask-vault-pass \
-vv \
-e '{"update_complexity_level": "update_complexity_level_2"}' \
--extra-vars "local_distr_path=${} \
custom_config=${} \
pangolin_license_path=${}" -
Обновление кластерного решения (cluster):
ansible-playbook playbook_updates.yaml \
-i inventories/cluster/hosts.ini \
-t always,cluster \
--ask-vault-pass \
-vv \
-e '{"update_complexity_level": "update_complexity_level_2"}' \
--extra-vars "local_distr_path=${} \
custom_config=${} \
pangolin_license_path=${}"
Описание параметров:
custom_config- абсолютный путь до файла конфигурацииcustom_file.yml;local_distr_path- абсолютный путь до загруженного и распакованного дистрибутива СУБД Pangolin.
Значения используемых в команде запуска Ansible ключей:
-i- путь до inventory-файла;--extra-vars- переменные, которые по приоритету важнее переменных из inventory;-t- теги для запуска;-v- уровень логирования Ansible. Может быть, как пустым, так и -vvvvvv, где запуск без v - минимальное логирование.
После завершения обновления у пользователя
postgresв его корневой директории будет сгенерирован файл с названием.process_work_statuses. В нем будетотображать состояние корректности установленных обновлений.Ниже приведен пример данного файла с конфигурации продукта
standalone-postgresql-pgbouncer:Разведка перед обновлением СУБД Pangolin запущена, текущая конфигурация standalone-postgresql-pgbouncer , тип обновления update_major, режим обновления hardlink
Разведка перед обновлением СУБД Pangolin завершена, текущая конфигурация standalone-postgresql-pgbouncer , тип обновления update_major, режим обновления hardlink
Обновление СУБД Pangolin запущено, текущая конфигурация standalone-postgresql-pgbouncer , с версии 04.003.00 на версию 05.002.00, статус обновления: {u'aggregate': False, u'hosts': {u'replica': False, u'master': False, u'etcd': False}, u'components': {u'haproxy': False, u'pgbouncer': False, u'patroni': False, u'pg': False, u'etcd': False, u'configuration': False}, u'types': {u'etcd': {u'finally': False, u'main': False}, u'pg': {u'major_main_migrate_replica_db': False, u'remove_pgaudit': False, u'major_pre': False, u'major_post': False, u'bootstrap': False, u'role_switched': False, u'major_main_migrate_master_db': False, u'major_main_start_after_migrate_db': False, u'not_started_db': False, u'started_db': False}, u'patroni': {u'finally': False, u'main': False}}}, тип обновления update_major, режим обновления hardlink
Обновление СУБД Pangolin успешно завершено, текущая конфигурация standalone-postgresql-pgbouncer , с версии 04.003.00 на версию 05.002.00, статус обновления: {u'aggregate': False, u'hosts': {u'replica': False, u'master': False, u'etcd': False}, u'components': {u'haproxy': False, u'pgbouncer': False, u'patroni': False, u'pg': False, u'etcd': False, u'configuration': False}, u'types': {u'etcd': {u'finally': False, u'main': False}, u'pg': {u'major_main_migrate_replica_db': False, u'remove_pgaudit': False, u'major_pre': False, u'major_post': False, u'bootstrap': False, u'role_switched': False, u'major_main_migrate_master_db': False, u'major_main_start_after_migrate_db': False, u'not_started_db': False, u'started_db': False}, u'patroni': {u'finally': False, u'main': False}}}, тип обновления update_major, режим обновления hardlink -
Примечание:
Подробное описание процесса обновления Pangolin приведено в разделе «Обновление» документа «Руководство по установке».
Диаграмма процесса миграции с помощью pgloader
В состав дистрибутива включена утилита pgloader. Она находится в каталоге с исполняемыми файлами Pangolin. При возникновении необходимости миграции данных из СУБД MSSQL/MySQL/SQLLite Администратор АС получает УЗ на сервере, готовит файл конфигурации и запускает миграцию.
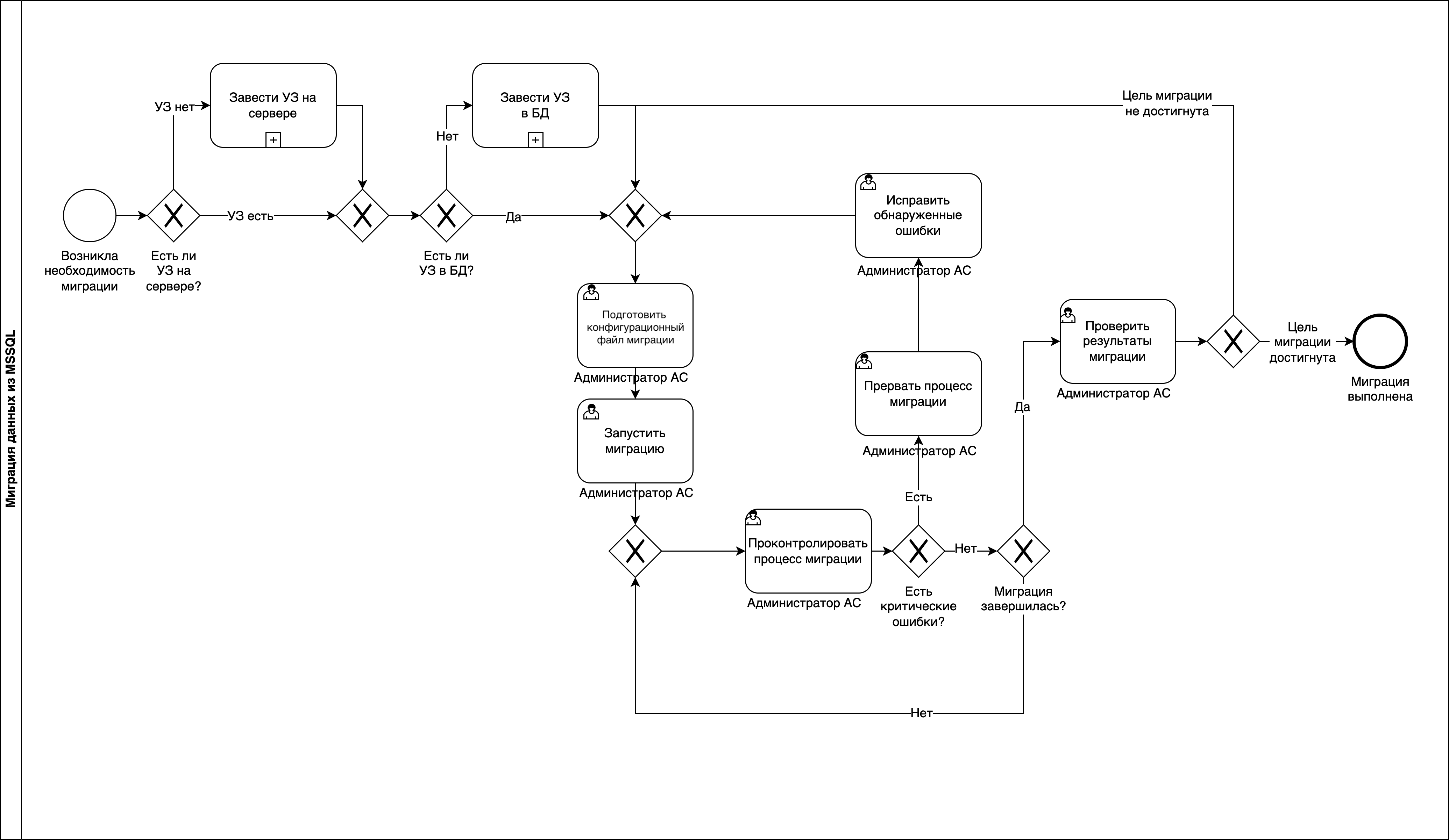
Миграция с MS SQL на Pangolin с помощью pgloader
Подготовка к миграции
pgloader - это программа, которая может загружать данные в базу данных PostgreSQL из различных источников. Она использует PostgreSQL команду + COPY + для копирования данных из исходной базы данных или файла. Для установки pgloader:
sudo yum install freetds sbcl
Скопируйте на хост дистрибутив версии не ниже 4.4.0, распакуйте и скопируйте исполняемый файл migration_tools/pgloader/pgloader (выполнять в папке с распакованным дистрибутивом):
sudo cp ./migration_tools/pgloader/pgloader /usr/local/bin/
Проверьте, что все установлено корректно и версия отображается:
pgloader --version
#Output
pgloader version "3.6.0"
compiled with SBCL 1.4.0-1.el7
Подготовка ролей
Команда pgloader осуществляет копирование в базу PostgreSQL данных из файла или непосредственно БД. Подключаться необходимо в качестве пользователя, имеющего доступ ко всем переносимым объектам, например, db_admin.
Важно, чтобы пользователь был в группе, у которой есть права на создание объектов (например, as_admin). Сделать это можно с помощью следующего скрипта:
GRANT <группа> TO <user>;
Аналогичным образом настраивается доступ для MS SQL - для подключения необходим пользователь, имеющий доступ ко всем переносимым объектам.
Не забудьте на стороне PostgreSQL в файле /pgdata/<version>/data/pg_hba.conf добавить разрешение на подключение нового пользователя к нужной БД:
host mydb myuser <IP-адрес>/<Порт> md5
Затем в psql выполните команду:
SELECT pg_reload_conf();
Убедитесь, что у БД назначен владелец as_admin:
SELECT d.datname as "Name",
pg_catalog.pg_get_userbyid(d.datdba) as "Owner"
FROM pg_catalog.pg_database d
WHERE d.datname = '<db_name>'
ORDER BY 1;
Если это не так, то выполните команду под суперпользователем:
ALTER DATABASE <db_name> OWNER TO as_admin;
Миграция схемы и данных
Для запуска процедуры миграции необходимо подготовить файл <имя файла>.load следующего содержания (в большинстве случаев это полный и готовый файл конфигурации для переноса MS SQL Server):
load database
from mssql://username:password@URI_MSSQL:PORT_MSSQL/DB_FOR_CONNECTION # для sql like УЗ
from mssql://domain\username:password@URI_MSSQL:PORT_MSSQL/DB_FOR_CONNECTION # для windows like УЗ
into postgresql://username:password@URI_PGSQL:PORT_PGSQL/DB_FOR_CONNECTION
Пример <имя файла>.load:
load database
from mssql://test_role_pgloader:password@tkles-pprb00268.vm.test.ru:1433/TEST
into postgresql://test_role_pgloader:password@tkles-pprb00267.vm.test.ru:5432/test
---переносятся только объекты со схемы dbo (важно, чтобы все схемы в базе принадлежали тому пользователю, под которым осуществляется миграция)
--сюда же при необходимости можно добавить exclusing-исключение и другие including-правила
including only table names like '%' in schema 'dbo'
--задаем опции
with create schemas, include drop, truncate, disable triggers, create tables, create indexes, drop indexes, reset sequences
--настраиваем параметры работы по нагрузке при переносе данных
set work_mem to '16MB', maintenance_work_mem to '512 MB', role to 'as_admin'
--задаем правила преобразования типов
cast type bigint to bigint, type geometry to bytea, type geography to bytea, type smallmoney to money, type tinyint to smallint, type smallint to smallint, type date to date
--если схема dbo есть, то удаляем ее (лучше так не делать и владелец схемы должен быть пользователь, под которым делаем миграцию)
before load do $$ drop schema if exists dbo cascade; $$;
Запуск сформированного файла производится следующим образом:
pgloader <имя файла>.load
Если ранее миграция схемы была произведена (например, через Liquibase), то еще раз схему можно не переносить, в этом случае:
- Вместо
create schemasнужно указатьcreate no schemas. - Вместо
include dropнужно указатьinclude no drop. - Вместо
create tablesнужно указатьcreate no tables. - Указать
data only.
Параметры миграции БД
Опция WITH
Доступны параметры:
create schemas- когда эта опция указана, pgloader создает те же схемы, что и в экземпляре MS SQL. Используется по умолчанию;create no schemas- когда эта опция указана, pgloader воздерживается от создания каких-либо схем, необходимо убедиться, что целевая схема существует;include drop- удаляет в целевой базе данных Pangolin все таблицы, чьи имена присутствуют в базе данных MS SQL;include no drop- никакие таблицы не будут удалены;truncate- перед загрузкой данных будет выполнена команда TRUNCATE для каждой таблицы Pangolin;no truncate- командаTRUNCATEвыполняться не будет;disable triggers- при использовании этой опции будет выполнена командаALTER TABLE … DISABLE TRIGGER ALLперед загрузкой данных иALTER TABLE … ENABLE TRIGGER ALLпосле загрузки данных;create tables- будут созданы таблицы, используя метаданные, найденные в MS SQL, которые должны содержать список полей с их типом данных. Выполнено преобразование типов данных из MS SQL в PostgreSQL;create no tables- никакие таблицы созданы не будут, необходимо создать таблицы заранее до начала миграции;create indexes- будут созданы все индексы, найденные в MS SQL;create no indexes- индексы не будут созданы;drop indexes- удалит все индексы в целевой базе данных перед загрузкой данных и создаст их снова в конце копии данных;reset sequences- при указании этого параметра pgloader после переноса всех данных и создания индексов сбросит все созданные последовательности СУБД Pangolin до текущего максимального значения столбца, к которому они присоединены;reset no sequences- сброс последовательностей будет пропущен;schema only- будет перенесена только схема;data only- будут перенесены только данные.
Опция CAST
Возможно переопределять правила перевода типов данных, заданные по умолчанию.
Числа:
datetimeoffset
type tinyint to smallint
type float to float using float-to-string
type real to real using float-to-string
type double to double precision using float-to-string
type numeric to numeric using float-to-string
type decimal to numeric using float-to-string
type money to numeric using float-to-string
type smallmoney to numeric using float-to-string
Текстовые типы:
type char to text drop typemod
type nchat to text drop typemod
type varchar to text drop typemod
type nvarchar to text drop typemod
type xml to text drop typemod
Бинарные типы:
type binary to bytea using byte-vector-to-bytea
type varbinary to bytea using byte-vector-to-bytea
Даты:
type datetime to timestamptz
type datetime2 to timestamptz
type datetimeoffset to timestamptz
Другое:
type bit to boolean
type hierarchyid to bytea
type geography to bytea
type uniqueidentifier to uuid using sql-server-uniqueidentifier-to-uuid
Частичный перенос данных
Имеется возможность сформировать разделенный запятыми список шаблонов имен таблиц, данные из которых при миграции переносятся частично:
including only table names like 'set' in schema 'dbo'
excluding table names matching 'bank' in schema 'dbo'
Возможно использовать одновременно несколько условий.
Поддержка MS SQL Views
Поддержка MS SQL Views позволяет pgloader переносить представления аналогично базовым таблицам.
Преобразование схем MS SQL
Позволяет переименовать схему в процессе миграции, чтобы, например, таблицы, найденные в схеме dbo в исходной базе данных, были перенесены в схему public в Pangolin с помощью этой команды:
excluding table names matching 'bank' in schema 'dbo'
Реализована возможность ввести разделенный запятыми список имен таблиц или регулярных выражений для использования в команде pgloader ALTER TABLE. Доступные действия: SET SCHEMA, RENAME TO и SET:
ALTER TABLE NAMES MATCHING ~/_list$/, 'sales_by_store', ~/sales_by/
IN SCHEMA 'dbo'
SET SCHEMA 'mv'
ALTER TABLE NAMES MATCHING 'film' IN SCHEMA 'dbo' RENAME TO 'films'
ALTER TABLE NAMES MATCHING ~/./ IN SCHEMA 'dbo' SET (fillfactor='40')
ALTER TABLE NAMES MATCHING ~/./ IN SCHEMA 'dbo' SET TABLESPACE 'tlbspc'
Можно использовать столько правил, сколько необходимо. Список таблиц, которые нужно перенести, ищется в памяти pgloader по правилам сопоставления ALTER TABLE, и для каждой команды pgloader останавливается на первом критерии соответствия (регулярное выражение или строка).
Команды ALTER TABLE не отправляется в Pangolin, изменение происходит на уровне представления в памяти pgloader исходной схемы базы данных. В случае изменения имени соответствие сохраняется и повторно используется с поддержкой внешнего ключа и индекса.
Действие SET() работает так же, как WITH для команды CREATE TABLE, которую pgloader запускает, когда ему нужно создать таблицу.
Действие SET TABLESPACE работает так же, как предложение TABLESPACE для команды CREATE TABLE, которую pgloader запустит при создании таблицы.
Сопоставление выполняется в самом pgloader и не зависит от реализации LIKE в MS SQL или от отсутствия поддержки регулярных выражений в компоненте.
Особенности работы pgloader
Изменение порта по умолчанию:
/local-projects/pgloader-3.6.0/src/parsers/command-mssql.lisp:115: (getenv-default "TDSPORT" "1433")
Установите значение переменной окружения TDSPORT на любое другое, проверьте:
echo $TDSPORT
export TDSPORT=1102
При миграции большой БД или при больших размерах tuples может возникать ошибка переполнения heap следующего вида: Heap exhausted during garbage collection: 288 bytes available, 432 requested. Два варианта решения проблемы:
- ограничить количество обрабатываемых строк в памяти за раз (по умолчанию 100000) с помощью конструкции в управляющем файле:
with prefetch rows = 10000; - пересобрать
pgloaderс другим размером heap (по умолчанию 4096 Мб):make DYNSIZE=8192 pgloader- можно начать с половины доступной RAM либо зайти в файлmakefile, который находится в директорииpgloader, и изменить этот параметр там.
Исследование работы pgloader
Режим отладки
При запуске команды pgloader -d <file>.load компонент pgloader выполняет следующие действия:
- читает конфигурационный файл
<file>.loadи выводит его содержимое в терминал; - применяет настройки, указанные в конфигурационном файле;
- проверяет подключения и общие доступы к базам данных, источнику и к принимающей стороне;
- формирует в MS SQL Server запросы на чтение метаданных (по заданному конфигурационному файлу) для выявления, что будет скопировано из источника в приемник.
Запросы в MS SQL Server (источник):
-- params: dbname
-- table-type-name
-- including
-- filter-list-to-where-clause including
-- excluding
-- filter-list-to-where-clause excluding
select c.TABLE_SCHEMA,
c.TABLE_NAME,
c.COLUMN_NAME,
c.DATA_TYPE,
CASE
WHEN c.COLUMN_DEFAULT LIKE '((%' AND c.COLUMN_DEFAULT LIKE '%))' THEN
CASE
WHEN SUBSTRING(c.COLUMN_DEFAULT,3,len(c.COLUMN_DEFAULT)-4) = 'newid()' THEN 'GENERATE_UUID'
WHEN SUBSTRING(c.COLUMN_DEFAULT,3,len(c.COLUMN_DEFAULT)-4) LIKE 'convert(%varchar%,getdate(),%)' THEN 'today'
WHEN SUBSTRING(c.COLUMN_DEFAULT,3,len(c.COLUMN_DEFAULT)-4) = 'getdate()' THEN 'CURRENT_TIMESTAMP'
WHEN SUBSTRING(c.COLUMN_DEFAULT,3,len(c.COLUMN_DEFAULT)-4) LIKE '''%''' THEN SUBSTRING(c.COLUMN_DEFAULT,4,len(c.COLUMN_DEFAULT)-6)
ELSE SUBSTRING(c.COLUMN_DEFAULT,3,len(c.COLUMN_DEFAULT)-4)
END
WHEN c.COLUMN_DEFAULT LIKE '(%' AND c.COLUMN_DEFAULT LIKE '%)' THEN
CASE
WHEN SUBSTRING(c.COLUMN_DEFAULT,2,len(c.COLUMN_DEFAULT)-2) = 'newid()' THEN 'GENERATE_UUID'
WHEN SUBSTRING(c.COLUMN_DEFAULT,2,len(c.COLUMN_DEFAULT)-2) LIKE 'convert(%varchar%,getdate(),%)' THEN 'today'
WHEN SUBSTRING(c.COLUMN_DEFAULT,2,len(c.COLUMN_DEFAULT)-2) = 'getdate()' THEN 'CURRENT_TIMESTAMP'
WHEN SUBSTRING(c.COLUMN_DEFAULT,2,len(c.COLUMN_DEFAULT)-2) LIKE '''%''' THEN SUBSTRING(c.COLUMN_DEFAULT,3,len(c.COLUMN_DEFAULT)-4)
ELSE SUBSTRING(c.COLUMN_DEFAULT,2,len(c.COLUMN_DEFAULT)-2)
END
ELSE c.COLUMN_DEFAULT
END,
c.IS_NULLABLE,
COLUMNPROPERTY(object_id(c.TABLE_NAME), c.COLUMN_NAME, 'IsIdentity'),
c.CHARACTER_MAXIMUM_LENGTH,
c.NUMERIC_PRECISION,
c.NUMERIC_PRECISION_RADIX,
c.NUMERIC_SCALE,
c.DATETIME_PRECISION,
c.CHARACTER_SET_NAME,
c.COLLATION_NAME
from INFORMATION_SCHEMA.COLUMNS c
join INFORMATION_SCHEMA.TABLES t
on c.TABLE_SCHEMA = t.TABLE_SCHEMA
and c.TABLE_NAME = t.TABLE_NAME
where c.TABLE_CATALOG = 'TEST'
and t.TABLE_TYPE = 'BASE TABLE'
and ((c.table_schema = 'dbo' and c.table_name LIKE '%'))
order by c.table_schema, c.table_name, c.ordinal_position;
select schema_name(schema_id) as SchemaName,
o.name as TableName,
REPLACE(i.name, '.', '_') as IndexName,
co.[name] as ColumnName,
i.is_unique,
i.is_primary_key,
i.filter_definition
from sys.indexes i
join sys.objects o on i.object_id = o.object_id
join sys.index_columns ic on ic.object_id = i.object_id
and ic.index_id = i.index_id
join sys.columns co on co.object_id = i.object_id
and co.column_id = ic.column_id
where schema_name(schema_id) not in ('dto', 'sys')
and ((schema_name(schema_id) = 'dbo' and o.name LIKE '%'))
order by SchemaName,
o.[name],
i.[name],
ic.is_included_column,
ic.key_ordinal;
-- params: including
-- filter-list-to-where-clause including
-- excluding
-- filter-list-to-where-clause excluding
SELECT
REPLACE(KCU1.CONSTRAINT_NAME, '.', '_') AS 'CONSTRAINT_NAME'
, KCU1.TABLE_SCHEMA AS 'TABLE_SCHEMA'
, KCU1.TABLE_NAME AS 'TABLE_NAME'
, KCU1.COLUMN_NAME AS 'COLUMN_NAME'
, KCU2.TABLE_SCHEMA AS 'UNIQUE_TABLE_SCHEMA'
, KCU2.TABLE_NAME AS 'UNIQUE_TABLE_NAME'
, KCU2.COLUMN_NAME AS 'UNIQUE_COLUMN_NAME'
, RC.UPDATE_RULE AS 'UPDATE_RULE'
, RC.DELETE_RULE AS 'DELETE_RULE'
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS RC
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE KCU1
ON KCU1.CONSTRAINT_CATALOG = RC.CONSTRAINT_CATALOG
AND KCU1.CONSTRAINT_SCHEMA = RC.CONSTRAINT_SCHEMA
AND KCU1.CONSTRAINT_NAME = RC.CONSTRAINT_NAME
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE KCU2
ON KCU2.CONSTRAINT_CATALOG = RC.UNIQUE_CONSTRAINT_CATALOG
AND KCU2.CONSTRAINT_SCHEMA = RC.UNIQUE_CONSTRAINT_SCHEMA
AND KCU2.CONSTRAINT_NAME = RC.UNIQUE_CONSTRAINT_NAME
WHERE KCU1.ORDINAL_POSITION = KCU2.ORDINAL_POSITION
AND KCU1.TABLE_CATALOG = 'TEST'
AND KCU1.CONSTRAINT_CATALOG = 'TEST'
AND KCU1.CONSTRAINT_SCHEMA NOT IN ('dto', 'sys')
AND KCU1.TABLE_SCHEMA NOT IN ('dto', 'sys')
AND KCU2.TABLE_SCHEMA NOT IN ('dto', 'sys')
and ((kcu1.table_schema = 'dbo' and kcu1.table_name LIKE '%'))
ORDER BY KCU1.CONSTRAINT_NAME, KCU1.ORDINAL_POSITION;
-- params: dbname
-- including
-- filter-list-to-where-clause including
-- excluding
-- filter-list-to-where-clause excluding
SELECT
REPLACE(KCU1.CONSTRAINT_NAME, '.', '_') AS 'CONSTRAINT_NAME'
, KCU1.TABLE_SCHEMA AS 'TABLE_SCHEMA'
, KCU1.TABLE_NAME AS 'TABLE_NAME'
, KCU1.COLUMN_NAME AS 'COLUMN_NAME'
, KCU2.TABLE_SCHEMA AS 'UNIQUE_TABLE_SCHEMA'
, KCU2.TABLE_NAME AS 'UNIQUE_TABLE_NAME'
, KCU2.COLUMN_NAME AS 'UNIQUE_COLUMN_NAME'
, RC.UPDATE_RULE AS 'UPDATE_RULE'
, RC.DELETE_RULE AS 'DELETE_RULE'
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS RC
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE KCU1
ON KCU1.CONSTRAINT_CATALOG = RC.CONSTRAINT_CATALOG
AND KCU1.CONSTRAINT_SCHEMA = RC.CONSTRAINT_SCHEMA
AND KCU1.CONSTRAINT_NAME = RC.CONSTRAINT_NAME
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE KCU2
ON KCU2.CONSTRAINT_CATALOG = RC.UNIQUE_CONSTRAINT_CATALOG
AND KCU2.CONSTRAINT_SCHEMA = RC.UNIQUE_CONSTRAINT_SCHEMA
AND KCU2.CONSTRAINT_NAME = RC.UNIQUE_CONSTRAINT_NAME
WHERE KCU1.ORDINAL_POSITION = KCU2.ORDINAL_POSITION
AND KCU1.TABLE_CATALOG = 'TEST'
AND KCU1.CONSTRAINT_CATALOG = 'TEST'
AND KCU1.CONSTRAINT_SCHEMA NOT IN ('dto', 'sys')
AND KCU1.TABLE_SCHEMA NOT IN ('dto', 'sys')
AND KCU2.TABLE_SCHEMA NOT IN ('dto', 'sys')
and ((kcu1.table_schema = 'dbo' and kcu1.table_name LIKE '%'))
ORDER BY KCU1.CONSTRAINT_NAME, KCU1.ORDINAL_POSITION;
По запросу видно, что основные системные схемы и системные объекты отсекаются по умолчанию (их не нужно фильтровать), после чего:
- На основе полученных данных формируются DDL-скрипты создания схемы и кусками передаются на выполнение в PostgreSQL (принимающую сторону).
- Кусками передаются данные из источника в приемник с применением параметров, указанных в конфигурационном файле.
- Выводится итоговая таблица работы миграции с детализацией о проделанных как успешных, так и неуспешных операциях с основными характеристиками в виде количества чтений, записей и времени выполнения.
Наблюдения
Перевод типов по умолчанию
| MS SQL | Pangolin | Корректность |
|---|---|---|
| xml | xml | Корректно |
| varchar(max) | text | Корректно |
| varchar(n) | text | Корректно |
| varbinary(max) | bytea | Корректно |
| varbinary(n) | bytea | Корректно |
| uniqueidentifier | uuid | Корректно |
| tinyint | int2 (smallint) | Корректно |
| timestamp | timestamp(6) | Не всегда может перевести корректно значения – необходимо подбирать дополнительно |
| time | time(6) | Корректно |
| text | text | Корректно |
| smallmoney | numeric | Некорректный перевод – происходит потеря точности младшего разряда (123456,1234 превращается в 123456,125). Если поменять тип на money, округление все равно происходит, но уже до сотых |
| smallint | int2 (smallint) | Корректно |
| smalldatetime | timestamptz(6) | Корректно |
| real | float4 (real) | Корректно |
| nvarchar(max) | text | Корректно |
| nvarchar(n) | text | Корректно |
| numeric | numeric | Корректно |
| ntext | text | Корректно |
| nchar | text | Корректно |
| money | numeric | Корректно |
| int | int4 | Корректно |
| image | bytea | Проверить |
| fieldhierarchyid | bytea | Проверить |
| float | float8 (double precision) | Корректно |
| decimal | numeric | Корректно |
| datetime2 | timestamptz(6) | Автоматический перевод невозможен, необходимо явно задать TIMESTAMP |
| datetime | timestamptz(6) | Корректно |
| date | date(0) | Корректно |
| char | text | Корректно |
| bit | bool | Корректно |
| binary | bytea | Корректно |
| bigint | int8 (bigint) | Корректно |
| geometry | По умолчанию не конвертируется, необходимо выставить тип bytea, в противном случае вероятны проблемы при переводе значений | |
| geography | По умолчанию не конвертируется, необходимо выставить тип bytea, в противном случае вероятны проблемы при переводе значений | |
| datetimeoffset | timestamptz | Корректно |
| sql_variant | По умолчанию не конвертируется, точного соответствия нет. Лучше указать точный тип в источнике (например, строка или др.) |
В правилах нельзя задать преобразования в следующие типы (при обработке файла высвечивается предупреждение об ошибке правил синтаксиса):
timestamptz- не может передать со скобками – только без скобок, что нормально, так как значение по умолчанию равно 6;timestamp- не может передать со скобками — только без скобок, так как значение по умолчанию равно 6;timestamp with time zone- можно черезtimestamptz(то же самое);double precision;real(особенно если встречается уточнение по размеру в скобках).
Также замечено, что даже если указать явно перевод в тип smallint, а не в int2 (к примеру), то все равно будет сделан перевод в синоним типа smallint, а именно — в int2.
Перенос отношений
Pgloader корректно переносит отношения следующих видов:
| Тип отношения (? - необязательная связь) | Схема | Данные | Схема с каскадным удалением и обновлением, включая выставление значения в NULL | Данные с каскадным удалением и обновлением, включая выставление значения в NULL |
|---|---|---|---|---|
| 1:1 | Корректно | Корректно | Корректно | Корректно |
| 1:?1 | Корректно | Корректно | Корректно | Корректно |
| 1:?неск | Корректно | Корректно | Корректно | Корректно |
| 1:неск | Корректно | Корректно | Корректно | Корректно |
| неск:1 | Корректно | Корректно | Корректно | Корректно |
| неск:?1 | Корректно | Корректно | Корректно | Корректно |
| неск:неск | Корректно | Корректно | Корректно | Корректно |
Перенос индексов
Строковый индекс
-
Строковый кластерный индекс:
-
Тип индекса простой:
-
Простой:
Индекс MS SQL:
CREATE CLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле>)Таким образом, простой кластерный индекс переносится как простой не кластерный индекс, что в рамках определения PostgreSQL верно, но не является идентичным решением.
-
Композитный:
Индекс MS SQL:
CREATE CLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле_01] ASC,
...
[поле_N] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ..., <поле_N>)Таким образом, композитный кластерный индекс переносится как композитный не кластерный индекс, что в рамках определения PostgreSQL верно, но не является идентичным решением.
-
Уникальный:
Индекс MS SQL:
CREATE UNIQUE CLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE UNIQUE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле>)Таким образом, уникальный кластерный индекс переносится как уникальный не кластерный индекс, что в рамках определения PostgreSQL верно, но не является идентичным решением.
-
-
Тип индекса композитный:
-
Простой:
Индекс MS SQL:
CREATE CLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле_01] ASC,
...
[поле_N] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ..., <поле_N>)
Таким образом, композитный кластерный индекс переносится как композитный не кластерный индекс, что в рамках определения PostgreSQL верно, но не является идентичным решением.
-
Композитный:
Нет.
-
Уникальный:
Индекс MS SQL:
CREATE UNIQUE CLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле_01] ASC,
...
[поле_N] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE UNIQUE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ..., <поле_N>)
Таким образом, уникальный композитный кластерный индекс переносится как уникальный композитный не кластерный индекс, что в рамках определения PostgreSQL верно, но не является идентичным решением.
-
-
Тип индекса уникальный:
-
Простой:
Индекс MS SQL:
CREATE UNIQUE CLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE UNIQUE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле>)Таким образом, уникальный кластерный индекс переносится как уникальный не кластерный индекс, что в рамках определения PostgreSQL верно, но не является идентичным решением.
-
Композитный:
Индекс MS SQL:
CREATE UNIQUE CLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле_01] ASC,
...
[поле_N] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE UNIQUE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ..., <поле_N>)Таким образом, уникальный композитный кластерный индекс переносится как уникальный композитный не кластерный индекс, что в рамках определения PostgreSQL верно, но не является идентичным решением.
-
Уникальный:
Нет.
-
Ограничение первичного ключа PK переносится как уникальный не кластерный индекс, что верно, но не является полным идентичным решением.
Индекс MS SQL:
ALTER TABLE [схема].[таблица] ADD CONSTRAINT [ограничение] PRIMARY KEY CLUSTERED
(
...Переносит как (Pangolin):
CREATE UNIQUE INDEX <ограничение> ON <схема>.<таблица> USING btree ... -
-
Строковый не кластерный индекс:
-
Тип индекса простой:
-
Простой:
Индекс MS SQL:
CREATE NONCLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле>)Таким образом, простой не кластерный индекс переносится как простой не кластерный индекс, что верно.
-
Композитный:
Индекс MS SQL:
CREATE NONCLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле_01] ASC,
...
[поле_N] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ..., <поле_N>)Таким образом, простой не кластерный индекс переносится как простой не кластерный индекс, что верно.
-
С включением:
Индекс MS SQL:
CREATE NONCLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле] ASC
)
INCLUDE([поле_вкл_01], ..., [поле_вкл_N]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле>, <поле_вкл_01>, ..., <поле_вкл_N>)Таким образом, не кластерный индекс с включением переносится как композитный не кластерный индекс, в котором сначала идут по порядку ключевые поля, а затем включенные поля, что допустимо в целом, но не является идентичным решением.
-
-
Тип индекса композитный:
-
Простой:
Индекс MS SQL:
CREATE NONCLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле_01] ASC,
...
[поле_N] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ..., <поле_N>)Таким образом, простой не кластерный индекс переносится как простой не кластерный индекс, что верно.
-
Композитный:
Нет.
-
С включением:
Индекс MS SQL:
CREATE NONCLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле_01] ASC,
...
[поле_N] ASC
)
INCLUDE([поле_вкл_01], ..., [поле_вкл_N]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ... <поле_N>, <поле_вкл_01>, ..., <поле_вкл_N>)Таким образом, композитный не кластерный индекс с включением переносится как композитный не кластерный индекс, в котором сначала идут по порядку ключевые поля, а затем включенные поля, что допустимо в целом, но не является идентичным решением.
-
-
Тип индекса с включением:
-
Простой:
Индекс MS SQL:
CREATE NONCLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле] ASC
)
INCLUDE([поле_вкл_01], ..., [поле_вкл_N]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле>, <поле_вкл_01>, ..., <поле_вкл_N>)Таким образом, не кластерный индекс с включением переносится как композитный не кластерный индекс, в котором сначала идут по порядку ключевые поля, а затем включенные поля, что допустимо в целом, но не является идентичным решением.
-
Композитный:
Индекс MS SQL:
CREATE NONCLUSTERED INDEX [индекс] ON [схема].[таблица]
(
[поле_01] ASC,
...
[поле_N] ASC
)
INCLUDE([поле_вкл_01], ..., [поле_вкл_N]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ... <поле_N>, <поле_вкл_01>, ..., <поле_вкл_N>)Таким образом, композитный не кластерный индекс с включением переносится как композитный не кластерный индекс, в котором сначала идут по порядку ключевые поля, а затем включенные поля, что допустимо в целом, но не является идентичным решением.
-
С включением:
Нет.
-
-
С признаком уникальности:
Индекс MS SQL:
CREATE UNIQUE NONCLUSTERED INDEX [индекс] ON [схема].[таблица]
...
Переносит как (Pangolin):
CREATE UNIQUE INDEX <индекс> ON <схема>.<таблица> USING btree ...
Таким образом, уникальный не кластерный индекс переносится как уникальный не кластерный индекс, что верно.
Ограничение уникальности переносится как уникальный не кластерный индекс, что верно, но не является полным идентичным решением:
Индекс MS SQL:
ALTER TABLE [схема].[таблица] ADD CONSTRAINT [ограничение] UNIQUE NONCLUSTERED
(
...
Переносит как (Pangolin):
CREATE UNIQUE INDEX <ограничение> ON <схема>.<таблица> USING btree ...
Фильтруемый индекс
Фильтруемый индекс передается корректно.
Например, следующий индекс из MS SQL:
CREATE NONCLUSTERED INDEX [indEmployee] ON [dbo].[Employee]
(
[DT] ASC,
[TelNumber] ASC
)
INCLUDE([LastName],[FirstName],[MiddleName])
WHERE ((DT is not null) and (TelNumber is not null))
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON);
Переводит в Pangolin в следующем виде:
CREATE INDEX idx_28244_indemployee ON dbo.employee USING btree (dt, telnumber, lastname, firstname, middlename) WHERE ((dt IS NOT NULL) AND (telnumber IS NOT NULL));
Колоночный индекс
-
Тип индекса не кластерный:
-
Простой:
Индекс MS SQL:
CREATE NONCLUSTERED COLUMNSTORE INDEX [индекс] ON [схема].[таблица]
(
[поле]
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле>)То есть простой колоночный не кластерный индекс переносится как просто простой не кластерный индекс, что неверно.
-
Композитный:
Индекс MS SQL:
CREATE NONCLUSTERED COLUMNSTORE INDEX [индекс] ON [схема].[таблица]
(
[поле_01],
...
[поле_N]
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ..., <поле_N>)То есть композитный колоночный не кластерный индекс переносится как просто композитный не кластерный индекс, что неверно.
-
-
Тип индекса кластерный:
-
Простой и композитный:
Индекс MS SQL:
CREATE CLUSTERED COLUMNSTORE INDEX [индекс] ON [схема].[таблица] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]Переносит как (Pangolin):
CREATE INDEX <индекс> ON <схема>.<таблица> USING btree (<поле_01>, ..., <поле_N>)То есть колоночный кластерный индекс переносится как просто не кластерный индекс, состоящий из всех полей таблицы, что неверно.
-
Специальные индексы
| Тип индекса | Простой | Составной |
|---|---|---|
| XML | нет | нет |
| Пространственный | нет | нет |
Выводы по индексам
Результаты переноса индексов:
- корректно переносятся простые и композитные не кластерные индексы как уникальные, так и неуникальные с учетом фильтрации и без;
- не переносится порядок сортировки (ASC - по возрастанию, DESC - по убыванию);
- не переносится fillfactor и другие опции;
- включенные столбцы переносятся как ключевые в конец списка ключевых полей индекса;
- кластерные индексы переносятся как не кластерные индексы;
- ограничения уникальности и первичного ключа PK переводит в виде соответствующих уникальных не кластерных индексов;
- колоночные индексы переводятся как просто не кластерные индексы, что неверно;
- специальные индексы (XML, пространственные) не переносятся.
Перенос последовательностей
Последовательности (identity) не переносятся.
Выявленные проблемы
Список выявленных проблем:
-
Не переносятся программируемые объекты, в том числе ограничения, значения по умолчанию и представления (их можно перенести только как таблицы, что в большинстве случаев не нужно);
-
В правилах нельзя задать преобразования в следующие типы (будет выведена синтаксическая ошибка обработки файла):
- double precision;
- real (особенно если встречается уточнение по размеру в скобках);
Замечено, что даже если указать явно перевод в тип smallint, а не в int2 (к примеру), то все равно будет произведен перевод в синоним типа smallint, а именно — в int2.
-
Следующие типы либо не могут быть преобразованы, либо преобразуются некорректно:
- geometry;
- geography;
- datetime2;
- timestamp;
- money и smallmoney (потеря точности в младших битах);
- sql_variant (в строку или бинарную последовательность не может, а другие типы не подойдут);
-
Специальные индексы (XML, пространственные), а также их настройки (fillfactor, порядок сортировки и т д) не могут быть перенесены. Колоночные индексы переводится как простые не кластерные индексы, что неверно;
-
Последовательности (identity) не переносятся.
Варианты решения проблем
Перенос программируемых объектов
Решение: только вручную.
Ошибки преобразования типов
Ниже приведен список ошибок преобразования типов и способы их решения:
-
В правилах нельзя задать преобразования в следующие типы (при обработке файла возникает предупреждение об ошибке в синтаксисе):
-
double precision - можно задать тип float8.
-
real (особенно если встречается уточнение по размеру в скобках) - можно задать тип float.
Решение: настройками изменить невозможно, только править непосредственно сам код.
-
Перевод типа MS SQL всегда осуществляется в специфичный тип для PostgreSQL в сокращенном формате (int2, int4, int8, float4, float8 и т. д.). Например, даже если указать явно перевод в тип smallint, а не в int2 (к примеру), то перевод все равно будет произведен в синоним типа smallint, а именно — в int2.
Решение: настройками изменить невозможно, только править непосредственно код.
-
Следующие типы либо не могут быть преобразованы, либо преобразуются некорректно:
-
geometry – невозможен автоматический перевод. Следует добавить правило в коде либо перевести в двоичный вид на источнике, а потом перенести и перевести в соответствующий вид в PostgreSQL.
-
geography – невозможен автоматический перевод. Следует добавить правило в коде либо перевести в двоичный вид на источнике, а потом перенести и перевести в соответствующий вид в PostgreSQL.
-
datetimeoffset – следует в коде добавить правило переноса его в тип timestamptz.
-
datetime2 – на стороне источника перевести по возможности в тип datetime (убедиться, что потери точности не будет). При необходимости отдельно перевести наносекунды в тип int, так как datetime2=datetime+наносекунды.
--получаем текущую дату и время с точностью до наносекунды
declare @dt2 datetime2=SYSDATETIME();
--переменная для сохранения наносекунд из типа datetime2
declare @dt2_nanosecond int;
--сохраняем datetime из типа datetime2 (сохраняем дату и время с точностью до секунды включительно)
declare @dt datetime=DATETIMEFROMPARTS(YEAR(@dt2), MONTH(@dt2), DAY(@dt2), DatePart(hour, @dt2), DatePart(minute, @dt2), DatePart(second, @dt2), 0);
--сохраняем наносекунды из типа datetime2
set @dt2_nanosecond=DatePart(nanosecond, @dt2);
--выводим datetime и наносекунды
select @dt as DT, @dt2_nanosecond as NanoSec;
--пытаемся воссоздать значение типа datetime2
declare @dt2_2 datetime2;
--из ранее сохраненной части datetime
set @dt2_2=@dt;
--и кол-ва наносекунд
set @dt2_2=DateAdd(nanosecond, @dt2_nanosecond, @dt2_2);
--выводим результат (Diff должен быть равен 0)
select @dt2, @dt2_2, DateDiff(nanosecond, @dt2, @dt2_2) as Diff;После переноса на принимающей стороне наносекунды должны быть добавлены в получившееся значение. Либо только микросекунды стандартным способом: dt+((dt2_nanosecond/1000) * interval '1 microsecond'), либо все наносекунды через расширение (поставить и проверить).
-
-
timestamp – аналога нет, так как в MS SQL Server это метка времени, а в PostgreSQL это дата и время (в общем виде не переводится никак).
-
money и smallmoney (потеря точности в младших битах) - на стороне источника необходимо осуществить перевод в тип int или bigint, так как даже money округляет последний младший разряд (123456,1234→123456,125).
Рекомендация: все типы с плавающей точкой лучше перевести в целочисленные типы и их уже переносить, а на принимающей стороне затем вновь перевести в нужный тип (для минимизации вероятности потери точности).
-
sql_variant - на стороне источника перевести в тип NVARCHAR(max).
Перенос специализированных индексов
Не может перенести специальные индексы (XML, пространственные), а также настройки (fillfactor, порядок сортировки и т. д.) индексов. Колоночные индексы переводит как просто не кластерные индексы, что неверно.
Решение: только вручную или внеся необходимые изменения непосредственно в сам код.
Перенос последовательностей
Последовательности (identity) не переносятся.
Решение: выполнить запрос на MS SQL Server и выполнить результаты в PostgreSQL.
Генерация кода identity-последовательностей:
select 'do $$
declare start_with_val bigint;
declare sql_statement varchar;
begin
start_with_val := coalesce((select max('+c.name+') from '+s.name+'.'+o.name +'),0)+1;
sql_statement := ''alter table '+s.name+'.'+o.name +'
alter '+c.name+' add generated by default as identity (start with ''
||cast(start_with_val as varchar)||'');'';
execute sql_statement;
end;
$$;' as plsql_statement
--select distinct s.name
from sys.all_columns as c
inner join sys.all_objects as o
on o.object_id = c.object_id
inner join sys.schemas as s
on s.schema_id = o.schema_id
where is_identity<>0
and schema_name(o.schema_id)<>'sys'
and o.type='U';
Пример:
do $$
declare start_with_val bigint;
declare sql_statement varchar;
begin
start_with_val := coalesce((select max(err_friend_retail_motivation_id) from err.friend_retail_motivation),0)+1;
sql_statement := 'alter table err.friend_retail_motivation alter err_friend_retail_motivation_id add generated by default as identity (start with '||cast(start_with_val as varchar)||');';
execute sql_statement;
end;
$$
Миграция с оригинального PostgreSQL на Pangolin
В качестве инструмента для миграции с оригинального PostgreSQL на Pangolin используется доработанная утилита pg_upgrade. Подробнее об оригинальной утилите pg_upgrade и ее параметрах читайте здесь.
Миграция с оригинального PostgreSQL на Pangolin существующими утилитами невозможна из-за увеличенной до 128 бит длины идентификаторов в Pangolin, а также из-за отсутствия системных каталогов парольных политик и защиты данных от привилегированных пользователей, что считается критической ошибкой для инструментов миграции. Это послужило поводом для доработок в части проверки совместимости кластеров, исходного и целевого, а также в части создания образа системных каталогов.
Внимание!
Концепция LOB, реализованная в PostgreSQL начиная с ядра 9.0, подразумевает, что каждый LOB-объект рассматривается отдельно со своим набором привилегий.
Большое количество LOB-объектов может привести к серьезным проблемам при администрировании сервера СУБД. Так обработка большого количества LOB-объектов, каждого со своими привилегиями, сказывается на требованиях оперативной памяти при работе утилиты
pg_dump, а такжеpg_upgrade. Если в системе недостаточно ресурсов для работы этих утилит, автоматическое обновление может быть невозможно. Заранее рассчитать требования памятиpg_dumpзатруднительно, так как они могут зависеть не только от количества объектов и привилегий, но и от длины полей (в названиях, комментариях и т.п). Оценку лучше проводить практическими тестами. При этом также следует оценивать время выполнения утилитыpg_dumpи последующего восстановления данных (в случае необходимости).При выборе архитектуры приложения следует оценить реальную необходимость использования LOB-объектов, так как в большинстве случаев можно выбрать TOAST. При использовании TOAST привилегии выдаются на таблицу целиком, а не на каждый LOB-объект в отдельности. Размер TOAST ограничивается 1 Гб. Более подробную информацию о LOB-объектах смотрите в документации PostgeSQL.
Описание
При расхождении длины идентификаторов исходного и целевого кластеров осуществляется дополнительная проверка использования этого параметра в исходном кластере. Тип данных name, использующий длину идентификаторов, не должен использоваться для пользовательских отношений, поэтому была добавлена дополнительная проверка отношений пользователей на наличие использования этого типа. Если такие отношения обнаружены, миграция невозможна по причине того, что в файлах пользовательских данных при записи была использована длина идентификаторов меньшего размера, и, следовательно, эти файлы не могут быть декодированы. В системных каталогах наличие этого типа не критично, так как каталоги создаются заново при инициализации целевого кластера и заполняются скриптом-образом заново, то есть при заполнении будет использоваться уже новое значение параметра длины идентификаторов.
Необходимым условием для запуска миграции с оригинального PostgreSQL на Pangolin является указание нового параметра запуска утилиты pg_upgrade --old-original. Этот параметр явно задает что исходный кластер должен относиться к оригинальному PostgreSQL. В случае, если в сочетании с ключом в качестве исходного кластера выступает продукт Pangolin, или исходный кластер (оригинальный PostgreSQL), но ключ --old-original не указан, миграция будет завершена с ошибкой.
При создании образа системных каталогов утилитой миграции pg_upgrade используется утилита pg_dumpall, которая копирует все глобальные объекты, кроме системных объектов, относящихся к защите данных от привилегированного пользователя. Критичность наличия системных каталогов парольных политик и защиты данных определяется типом продукта исходного кластера. Для определения типа продукта используется наличие GUC-параметра server_se_version. Параметр был добавлен в версии Pangolin 4.1.0, вместе с изменением наполнения системных каталогов.
Примечание:
Подробнее об утилите
pg_dumpallможно прочитать здесь.
Утилита pg_dumpall проверяет лишь наличие этого конфигурационного параметра, который является внутренним и не может быть изменен через файл конфигурации postgresql.conf, и на основе его наличия в настройках работающего кластера делает вывод о принадлежности кластера к продукту Pangolin. Для оригинального PostgreSQL пропускается шаг дампа каталогов парольных политик.
Утилита pg_upgrade так же использует параметр конфигурации server_se_version, но дополнительно осуществляет синтаксический анализ полученного значения, для определения версии продукта. Несмотря на изменения формата содержания переменной server_se_version, в зависимости от версии Pangolin, во всех вариантах неизменным является вывод непосредственно версии <major>.<minor>.<patch>. По наличию номера версии делается вывод о принадлежности исходного кластера к продукту Pangolin и в этом случае утилитой pg_upgrade осуществляется копирование системных каталогов защиты данных от привилегированных пользователей.
Диаграммы процессов
Схема миграции с оригинального PostgreSQL на Pangolin:
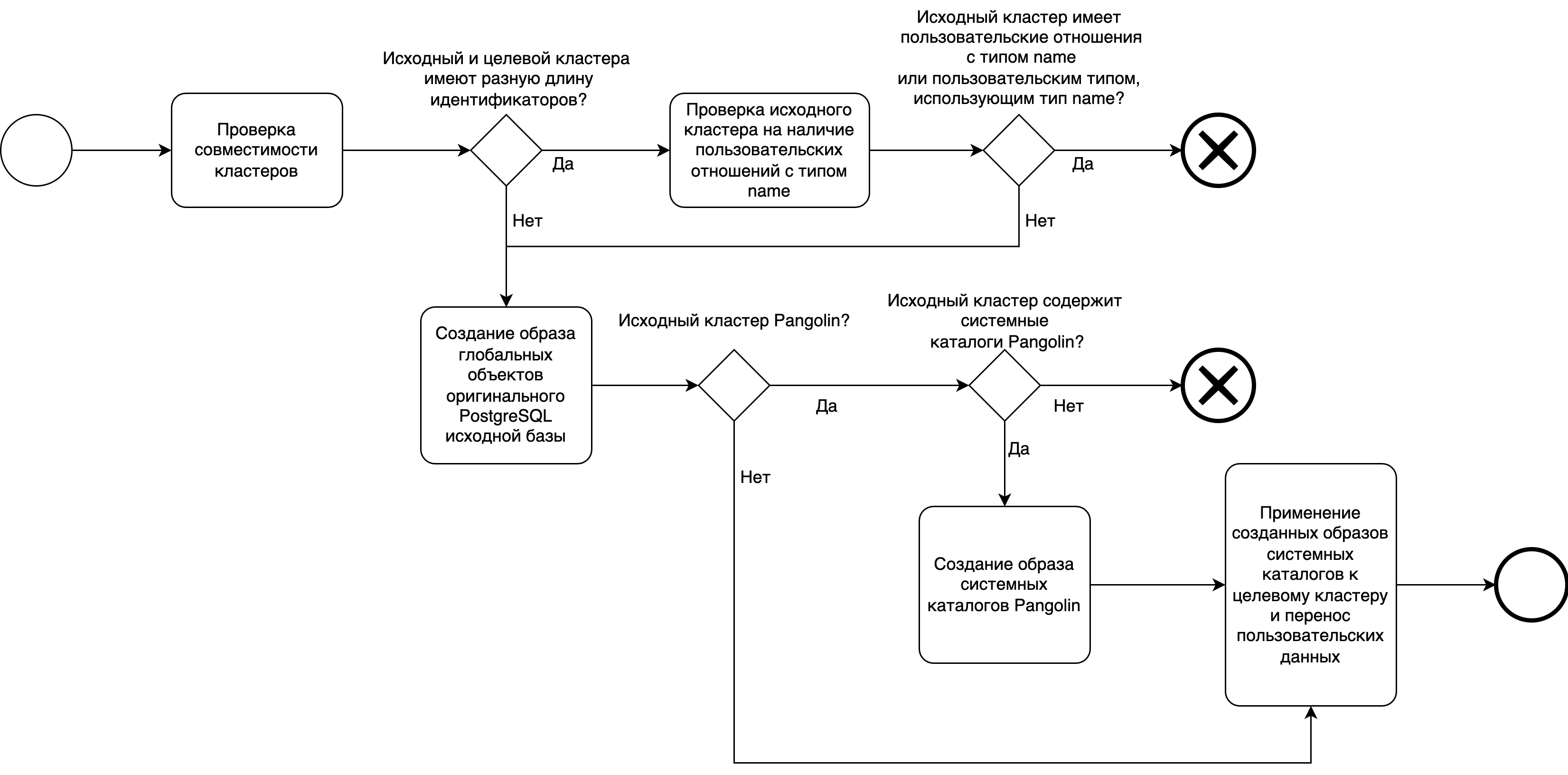
| Наименование шага | Входной документ | Описание | Исполнитель | Характер изменений | Продолжительность | Выходной документ | ИТ-система | Переход к шагу |
|---|---|---|---|---|---|---|---|---|
| 01 Проверка совместимости кластеров | Проверка совместимости параметров исходного и целевого кластеров. В случае расхождения длины идентификаторов устанавливается флаг необходимости дополнительной проверки пользовательских отношений на наличие использования типа данных name | pg_upgrade | Pangolin | 02 | ||||
| 02 Необходимость проверки исходного кластера на наличие пользовательских отношений с типом name и/или с пользовательским типом, использующим тип name | В зависимости от флага, выставленного на предыдущем шаге, переход к проверке пользовательских отношений на возможность миграции | pg_upgrade | Pangolin | 03 - нужна дополнительная проверка пользовательских отношений 04 - переход к началу миграции | ||||
| 03 Проверка исходного кластера на наличие пользовательских отношений с типом name и/или с пользовательским типом, использующим тип name | Проверка исходного кластера на наличие пользовательских отношений с типом name и/или с пользовательским типом, использующим тип name | pg_upgrade | Pangolin | 04 - в исходном кластере нет пользовательских отношений с типом name отказ в миграции при наличии использования типа name в пользовательских отношениях | ||||
| 04 Создание образа глобальных объектов оригинального PostgreSQL исходной базы | Создание образа глобальных объектов присущих оригинальному PostgreSQL | pg_dumpall | Pangolin | 05 | ||||
| 05 Проверка является ли исходный кластер продуктом Pangolin | На основе версии продукта определяется является ли исходный кластер продуктом Pangolin или оригинальным PostgreSQL | pg_upgrade, pg_dumpall | Pangolin | 06 - исходный кластер является продуктом Pangolin 08 - исходный кластер является оригинальным PostgreSQL | ||||
| 06 Проверка наличия системных каталогов присущих продукту Pangolin | Проверка наличия системных каталогов парольных политик и защиты данных от привилегированных пользователей в исходном кластере | pg_upgrade, pg_dumpall | Pangolin | 07 - системные каталоги Pangolin присутствуют в исходном кластере отказ в миграции | ||||
| 07 Создание образа системных каталогов Pangolin | Создание образа системных каталогов Pangolin | pg_upgrade, pg_dumpall | Pangolin | 08 | ||||
| 08 Применение созданных образов системных каталогов к целевому кластеру и перенос пользовательских данных | В завершении миграции к целевому кластеру применяются созданные образы системных каталогов и осуществляется миграция пользовательских данных |
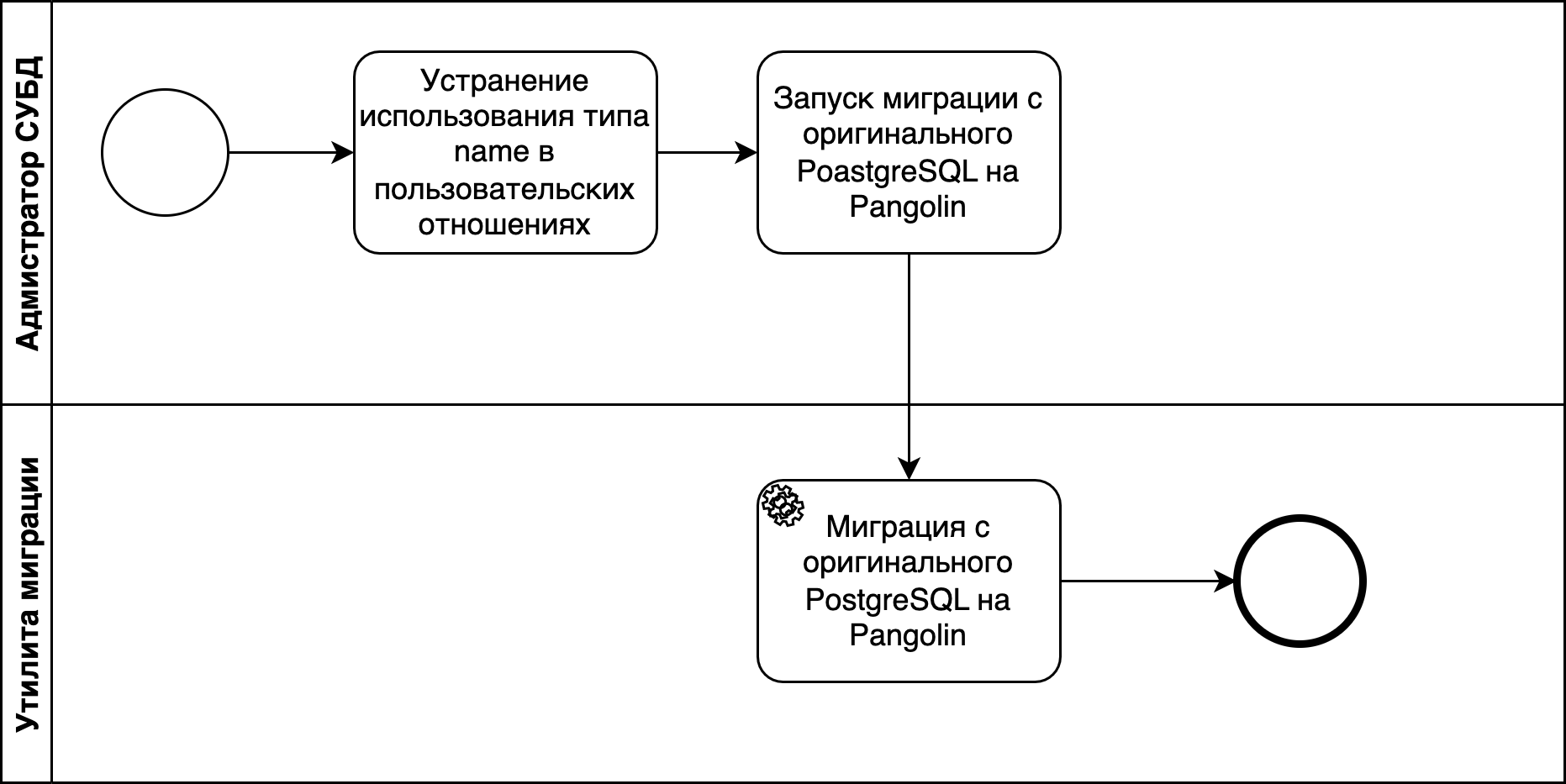
Схема миграции с оригинального PostgreSQL на Pangolin при наличии пользовательских данных с типом name:
| Наименование шага | Входной документ | Описание | Исполнитель | Характер изменений | Продолжительность | Выходной документ | ИТ-система | Переход к шагу |
|---|---|---|---|---|---|---|---|---|
| 01 Устранение использования типа name в пользовательских отношениях | Тип name не предназначен для использования пользователем, поэтому отношения могут быть модифицированы с использованием подходящего типа данных | Администратор СУБД | PostgreSQL | 02 | ||||
| 02 Запуск миграции с оригинального PostgreSQL на Pangolin | Запуск процесса миграции | Администратор СУБД | Pangolin | 03 | ||||
| 03 Миграция с оригинального PostgreSQL на Pangolin | Осуществление миграции утилитами входящими в состав Pangolin | pg_upgrade | Pangolin |
Пример миграции с оригинального PostgreSQL на Pangolin
Внимание!
После переноса dbms в клиентскую часть в Pangolin
{{version}}, некоторые утилиты, необходимые для корректной миграции с оригинального PostgreSQL, находятся в клиентской части. Для их корректного использования утилитойpg_upgradeтребуется создать ссылки на файлы утилит:ln -s /usr/pangolin-dbms-client/bin/pg_dump /usr/pangolin-06/bin/pg_dump
ln -s /usr/pangolin-dbms-client/bin/pg_dumpall /usr/pangolin-06/bin/pg_dumpall
ln -s /usr/pangolin-dbms-client/bin/pg_restore /usr/pangolin-06/bin/pg_restore
ln -s /usr/pangolin-dbms-client/bin/psql /usr/pangolin-06/bin/psql
ln -s /usr/pangolin-dbms-client/bin/vacuumdb /usr/pangolin-06/bin/vacuumdb
В качестве исходной СУБД в примере использован оригинальный PostgreSQL 11.21, целевой – Pangolin 5.5.0. Для миграции выполните шаги:
-
Выполните преобразование пользовательских объектов использующих тип name.
-
Создайте образ пользовательских данных для проверки миграции:
${исходная_СУБД}/bin/pg_dump -Fp -f original_dump.sql -
Остановите кластер:
${исходная_СУБД}/bin/pg_ctl -D ${PGDATA_OLD} stop -
Создайте целевой кластер Pangolin:
-
Установите СУБД в
${целевая_СУБД}. -
Выполните инициализацию:
${целевая_СУБД}/bin/initdb -D ${PGDATA_NEW}
-
-
Запустите миграцию:
${целевая_СУБД}/bin/pg_upgrade --old-bindir ${исходная_СУБД}/bin --old-datadir ${PGDATA_OLD} --new-bindir ${целевая_СУБД}/bin --new-datadir ${PGDATA_NEW} --old-originalПараметры:
--old-bindir– каталог с исполняемыми файлами исходной версии PostgreSQL (${исходная_СУБД}/bin);--old-datadir– каталог данных исходного кластера (${PGDATA_OLD});--old-original– параметр явно задает, что исходный кластер должен относиться к оригинальному PostgreSQL;--new-bindir– каталог с исполняемыми файлами целевой версии Pangolin (${целевая_СУБД}/bin);--new-datadir– каталог данных целевого кластера (${PGDATA_NEW}).
Версии PostgreSQL, подходящие для миграции
Возможно обновление только на версию с ядром СУБД не ниже исходной:
| Исходная версия ядра PostgreSQL | Исходная версия PostgreSQL | Целевая версия Pangolin |
|---|---|---|
| 10 | 10.23 | 5.5.0, 6.1.0 |
| 11 | 11.21 | 5.5.0, 6.1.0 |
| 12 | 12.16 | 5.5.0, 6.1.0 |
| 13 | 13.12 | 5.5.0, 6.1.0 |
| 15 | 15.4 | 6.1.0 |