Высокая доступность с несколькими центрами обработки данных
Эта страница переведена при помощи нейросети GigaChat.
Высокая доступность кластера PostgreSQL, развернутого в нескольких центрах обработки данных, основана на репликации, которая может быть синхронной или асинхронной.
В обоих случаях важно четко понимать следующие концепции:
- PostgreSQL может работать в качестве основного или резервного лидера только тогда, когда он владеет ведущим ключом и может обновлять ведущий ключ.
- Нужно запускать нечетное количество узлов etcd, ZooKeeper или Consul: 3 или 5!
Синхронная репликация
Чтобы иметь кластер с несколькими ЦОД, который может автоматически выдерживать падение зоны, требуется минимум 3 узла.
Диаграмма архитектуры:
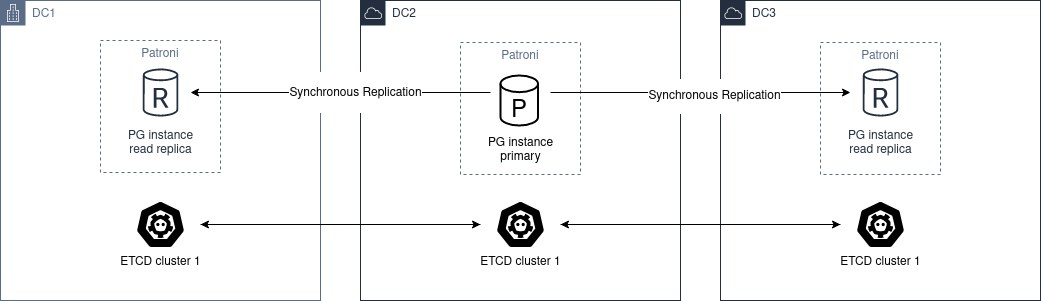
Необходимо развернуть кластер etcd, ZooKeeper или Consul через разные ЦОД с минимальным количеством 3 узлов, по одному в каждой зоне.
Что касается PostgreSQL, то нужно развернуть не менее двух узлов в разных ЦОД. Затем установить synchronous_mode: true в глобальной динамической конфигурации.
Это позволяет выполнять синхронную репликацию, и основной узел выберет один из узлов в качестве синхронного.
Асинхронная репликация
При наличии всего двух центров обработки данных лучше иметь два независимых кластера etcd и запустить резервный кластер Patroni во втором центре обработки данных. Если первый сайт не работает, можно вручную продвинуть standby_cluster.
Диаграмма архитектуры:
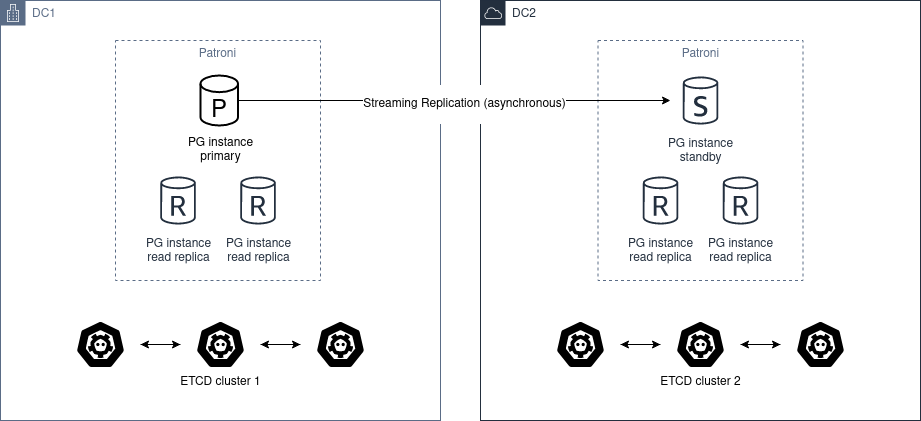
Автоматическое продвижение невозможно, потому что ЦОД2 никогда не сможет определить состояние ЦОД1.
В этом сценарии не следует использовать pg_ctl promote, необходимо «вручную продвинуть» здоровый кластер, удалив секцию standby_cluster из динамической конфигурации.
Внимание!
Если исходный кластер все еще работает, и выполняется продвижение резервного кластер, то создается split-brain.
Если нужно вернуться в «исходное» состояние, есть только два способа решить эту проблему:
- Добавить секцию
standby_clusterобратно, что приведет к запускуpg_rewind, но есть вероятность, чтоpg_rewindне сработает. - Перестроить резервный кластер с нуля.
Прежде чем продвигать резервный кластер, необходимо вручную убедиться, что исходный кластер выключен (STONITH). Когда ЦОД1 восстановит работоспособность, кластеру придется стать резервным кластером.
Прежде чем сделать это, можно вручную проверить базу данных и извлечь все изменения, которые произошли между моментом, когда связь между ЦОД1 и ЦОД2 перестала работать, и моментом, когда вручную был остановлен кластер в ЦОД1.
После извлечения также можно вручную применить эти изменения к кластеру в ЦОД2.