Реализация
Эта страница переведена при помощи нейросети GigaChat.
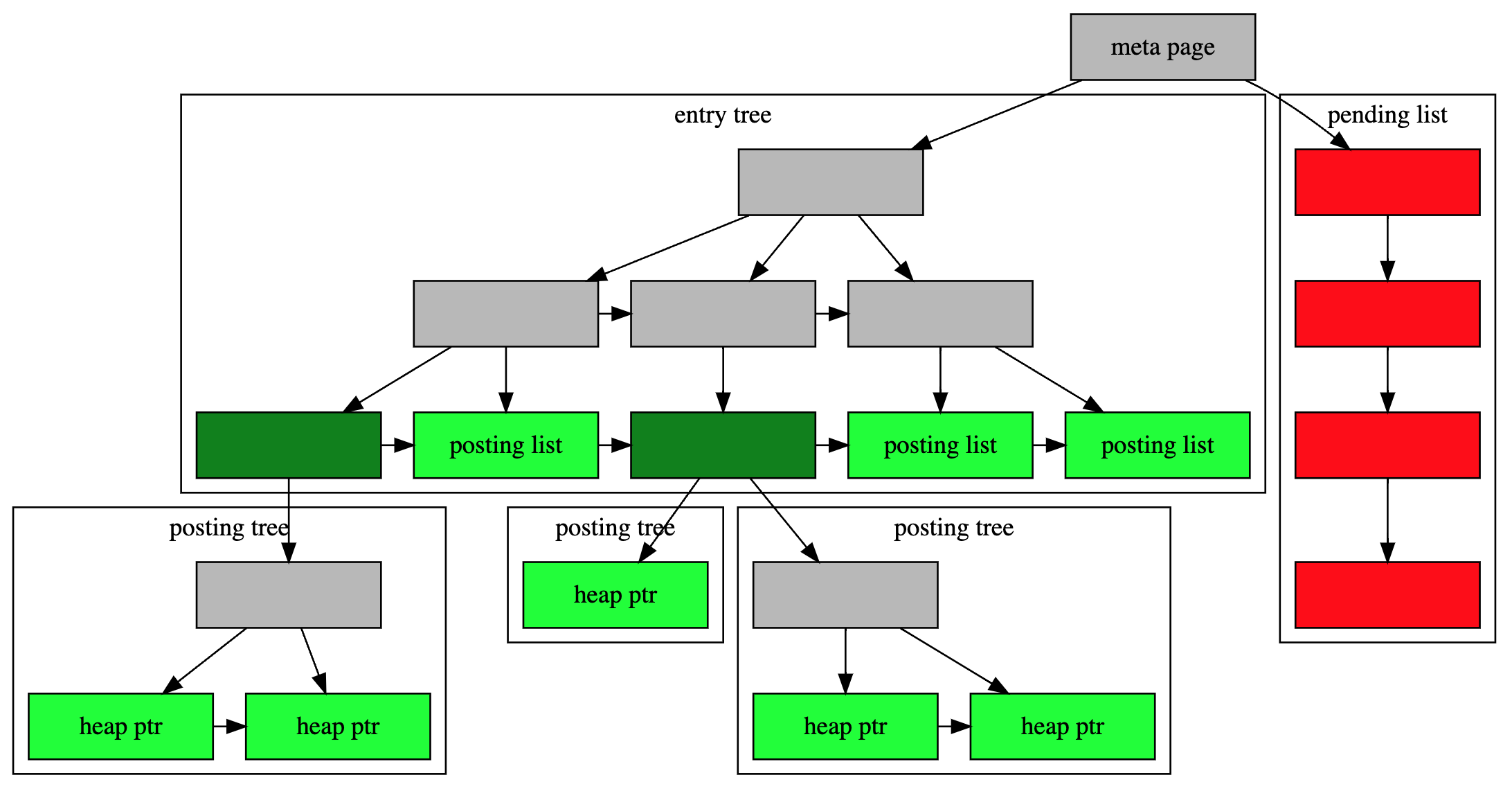
Внутренне индекс GIN содержит B-дерево, построенное по ключам, где каждый ключ - это элемент одного или нескольких индексируемых элементов (например, член массива), и где каждый кортеж в листе страницы содержит либо указатель на B-дерево указателей кучи («дерево постинга»), либо простой список указателей кучи («список размещения»), когда список достаточно мал, чтобы поместиться в один индексный кортеж вместе со значением ключа. На рисунке ниже показаны эти компоненты индекса GIN.
Начиная с версии PostgreSQL 9.1, в индекс можно включать нулевые значения ключей. Кроме того, в индекс включаются нули-заместители для индексируемых элементов, которые являются нулевыми или не содержат ключей в соответствии с extractValue. Это позволяет поиску, который должен найти пустые элементы, сделать это.
Многоколоночные GIN-индексы реализуются путем построения одного B-дерева по составным значениям (номер столбца, ключевое значение). Ключевые значения для разных столбцов могут быть разных типов.
Внутренние элементы GIN:
Техника быстрого обновления GIN
Обновление индекса GIN обычно происходит медленно из-за внутренней природы инвертированных индексов: вставка или обновление одной строки кучи может вызвать множество вставок в индекс (по одной для каждого ключа, извлеченного из индексируемого элемента). GIN способен отложить большую часть этой работы, вставляя новые кортежи во временный, несортированный список ожидающих записей. Когда таблица пылесосится или автоанализируется, или когда вызывается функция gin_clean_pending_list, или если список ожидающих записей становится больше, чем gin_pending_list_limit, записи перемещаются в основную структуру данных GIN с помощью тех же методов массовой вставки, которые использовались при первоначальном создании индекса. Это значительно повышает скорость обновления индекса GIN, даже с учетом дополнительных накладных расходов на вакуум. Более того, эта работа может выполняться фоновым процессом, а не в процессе обработки запросов на переднем плане.
Основным недостатком этого подхода является то, что поиск должен сканировать список ожидающих записей в дополнение к поиску в обычном индексе, поэтому большой список ожидающих записей значительно замедляет поиск. Другой недостаток заключается в том, что, хотя большинство обновлений происходит быстро, обновление, в результате которого список ожидающих записей становится "слишком большим", приведет к немедленному циклу очистки и, следовательно, будет намного медленнее, чем другие обновления. Правильное использование autovacuum может свести к минимуму обе эти проблемы.
Если постоянное время отклика важнее скорости обновления, использование отложенных записей можно отключить, выключив параметр хранения fastupdate для индекса GIN. Подробности см. в разделе CREATE INDEX.
Алгоритм частичного совпадения
GIN может поддерживать запросы с «частичным совпадением», когда запрос не определяет точного совпадения для одного или нескольких ключей, но возможные совпадения находятся в достаточно узком диапазоне значений ключей (в пределах порядка сортировки ключей, определенного методом поддержки сравнения). Метод extractQuery, вместо того чтобы возвращать значение ключа для точного совпадения, возвращает значение ключа, которое является нижней границей диапазона для поиска и устанавливает флаг pmatch в true. Затем диапазон ключей сканируется с помощью метода comparePartial. comparePartial должен возвращать ноль для совпадающего индексного ключа, меньше нуля для несовпадающего, который все еще находится в пределах диапазона поиска, или больше нуля, если индексный ключ находится за пределами диапазона, который может совпасть.