Лекция 09. Физическое хранение данных
В этой главе:
- Табличные пространства.
- Хранение информации на носителях
- Размеры объектов
- Работа с табличным пространством
Табличные пространства
- Табличные пространства и базы данных
- Табличные пространства по умолчанию
- Каталоги баз данных в файловой системе
- Создание табличного пространства
- Каталог pg_tblspc
- Создание объекта в табличном пространстве
- Хранение объекта в табличном пространстве
- Создание объекта в ТП по умолчанию
- Перемещение объекта в другое ТП
- Создание БД с указанием ТП
- Информация о ТП для объектов баз данных
- Массовое перемещение
Табличные пространства и базы данных
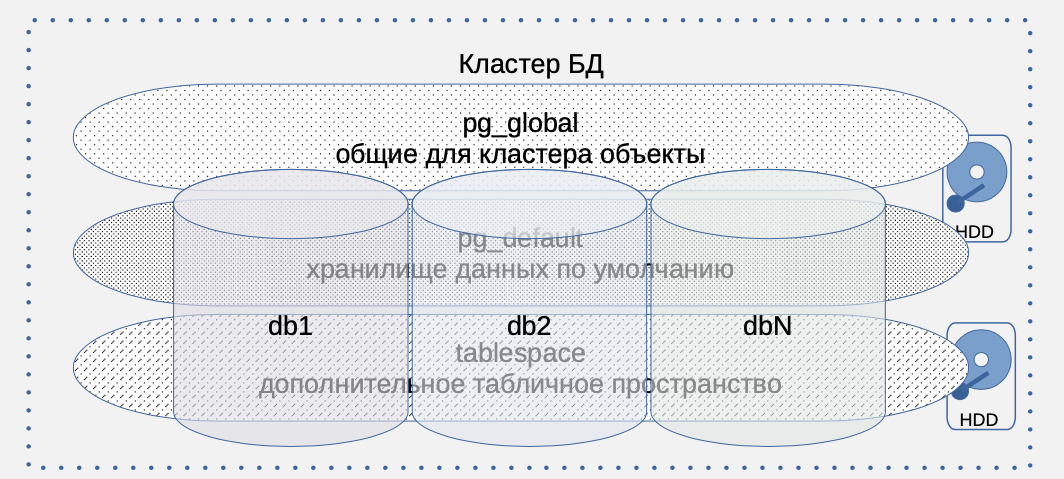
Все данные кластера баз данных должны храниться на носителях, которые не теряют информацию при выключении питания (persistent storage). Например, жестких магнитных дисках, твердотельных носителях или других блочных устройствах.
В PostgreSQL хранение данных организовано с использованием файловых систем - все данные баз хранятся в обычных файлах.
В кластере баз данных имеются глобальные объекты, не принадлежащие конкретным базам в кластере, например, пользователи. Глобальные объекты - общие для кластера и для них имеется табличное пространство pg_global. Оно создается при инициализации кластера командой initdb. При этом также создается табличное пространство по умолчанию pg_default, предназначенное для хранения объектов баз. Если нет других табличных пространств, то все данные различных баз будут находиться в pg_default. Но часто создают и другие табличные пространства. В таком случае можно назначить конкретной базе табличное пространство по умолчанию, отличное от pg_default. Более того, можно назначить отдельное табличное пространство, например, для таблицы или индекса.
Объекты одной базы могут храниться в разных табличных пространствах, и в табличном пространстве хранятся объекты разных баз.
Частые причины создания дополнительных табличных пространств:
- нехватка свободного места в файловой системе;
- хранение архивных данных на медленных носителях, а "горячих" на скоростных;
- отдельное хранение индексов от таблиц.
https://www.postgresql.org/docs/15/storage-file-layout.html.
https://www.postgresql.org/docs/15/manage-ag-tablespaces.html.
Табличные пространства по умолчанию
postgres=# \db
Список табличных пространств
Имя | Владелец | Расположение
------------+----------+--------------
pg_default | postgres |
pg_global | postgres |
(2 строки)
postgres=# \! sudo -u postgres ls -ld $PGDATA/{global,base}
drwx------ 6 postgres postgres 4096 окт 12 18:54 /pgdata/06/data/base
drwx------ 2 postgres postgres 4096 окт 12 18:54 /pgdata/06/data/global
- Метакоманда \db psql выдает список табличных пространств.
- Каталог $PGDATA/global - табличное пространство pg_global.
- Каталог $PGDATA/base - табличное пространство pg_default.
При создании кластера командой initdb автоматически создаются два табличный пространства:
- pg_global - ему соответствует каталог $PGDATA/global
- pg_default - $PGDATA/base
Получить список табличных пространств проще всего метакомандой \db клиента psql. Но можно выполнить и запрос к pg_tablespace:
postgres=# SELECT spcname FROM pg_tablespace;
spcname
------------
pg_default
pg_global
(2 строки)
https://www.postgresql.org/docs/15/storage-file-layout.html.
Каталоги баз данных в файловой системе
[postgres@p620 ~]$ oid2name
Oid Database Name Tablespace
----------------------------------
5 postgres pg_default
16409 sch_db pg_default
4 template0 pg_default
1 template1 pg_default
В каталоге файловой системы, соответствующему, табличному пространству, для каждой базы данных, использующей его, создается подкаталог с именем - oid базы данных.
Для получения oid баз данных в командной строке ОС можно использовать утилиту oid2name.
В примере:
- $PGDATA/base - каталог табличного пространства pg_default;
- подкаталоги в $PGDATA/base с именами в виде цифр соответствуют oid БД.
Хранение данных баз в каталоге табличного пространства реализуется по простому принципу: создаются индивидуальные подкаталоги для каждой базы с именами, соответствующими oid (Object ID) баз данных. Получить oid БД можно, например, так:
postgres=# SELECT oid, datname FROM pg_database;
oid | datname
-------+-----------
5 | postgres
1 | template1
4 | template0
16409 | sch_db
(4 строки)
Однако, проще воспользоваться утилитой командной строки oid2name. При вызове ее без каких-либо аргументов она выдает список oid баз данных и их табличные пространства по умолчанию. https://www.postgresql.org/docs/15/oid2name.html.
Создание табличного пространства
[postgres@p620 ~]$ mkdir -p /pgdata/06/newdisk
[postgres@p620 ~]$ psql -q
postgres=# CREATE TABLESPACE newtabspace LOCATION '/pgdata/06/newdisk'; postgres=# \db
Список табличных пространств
Имя | Владелец | Расположение
-------------+----------+--------------------
newtabspace | postgres | /pgdata/06/newdisk
pg_default | postgres |
pg_global | postgres |
(3 строки)
CREATE TABLESPACE создает табличное пространство.
LOCATION указывает каталог, в котором будут размещаться данные для этого табличного пространства.
При создании табличного пространства каталог файловой системы для его размещения должен существовать, им должен владеть пользователь ОС postgres (пользователь, от имени которого работают процессы кластера) и он должен быть доступен для postgres на запись. https://www.postgresql.org/docs/15/sql-createtablespace.html.
Получить список табличных пространств проще всего метакомандой \db.
В Pangolin можно создавать табличные пространства, защищенные шифрованием. Подробнее о них в курсе DBP1.
Каталог pg_tblspc
[postgres@p620 ~]$ ls -l $PGDATA/pg_tblspc/
итого 0
lrwxrwxrwx 1 postgres postgres 18 окт 13 21:47 16440 -> /pgdata/06/newdisk
[postgres@p620 ~]$ psql -c "SELECT oid FROM pg_tablespace WHERE spcname = 'newtabspace'"
oid
-------
16440
(1 строка)
В результате создания табличного пространства в каталоге $PGDATA/pg_tblspc/ создается символическая ссылка с именем, совпадающим с oid созданного табличного пространства.
Ссылка указывает на каталог, который был задан после ключевого слова LOCATION при создании табличного пространства.
Созданное табличное пространство физически оформляется посредством символической ссылки в каталоге $PGDATA/pg_tblspc. Имя файла символической ссылки совпадает с oid табличного пространства, а указывает эта символическая ссылка на каталог файловой системы, в котором будут храниться данные в этом табличном пространстве. Это тот самый каталог, который был указан после ключевого слова LOCATION команды CREATE TABLESPACE. https://www.postgresql.org/docs/15/storage-file-layout.html.
Создание объекта в табличном пространстве
sch_db=# CREATE TABLE tab_in_newts ( id integer, msg text ) TABLESPACE newtabspace; CREATE TABLE
sch_db=# SELECT * FROM pg_tables WHERE tablespace = 'newtabspace' \gx
-[ RECORD 1 ]-------------
schemaname | public
tablename | tab_in_newts
tableowner | postgres
tablespace | newtabspace
hasindexes | f
hasrules | f
hastriggers | f
rowsecurity | f
При создании таблиц, индексов и материализованных представлений можно явно указать, в каком табличном пространстве они должны размещать свои данные.
Для таких объектов баз данных, как таблицы, индексы и материализованные представления можно в явном виде задавать табличное пространство, в котором эти объекты будут хранить данные. Это делается с помощью ключевого слова TABLESPACE. Если его не указать, то при создании объекта будет использовано табличное пространство, которое ДЛЯ ДАННОЙ базы является табличным пространством по умолчанию. https://www.postgresql.org/docs/15/sql-createview.html.
https://www.postgresql.org/docs/15/sql-creatematerializedview.html.
https://www.postgresql.org/docs/15/sql-createindex.html.
Хранение объекта в табличном пространстве
[postgres@p620 ~]$ psql -d sch_db -c "SELECT pg_relation_filepath('tab_in_newts')"
pg_relation_filepath
---------------------------------------------
pg_tblspc/16440/PG_15_202310091/16409/16441
(1 строка)
[postgres@p620 ~]$ ls -l $PGDATA/pg_tblspc/16440/PG_15_202310091/16409/16441
-rw------- 1 postgres postgres 0 окт 14 10:16 /pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16441 [postgres@p620 ~]$ oid2name -d sch_db -f 16441
From database "sch_db":
Filenode Table Name ------------------------
16441 tab_in_newts
[postgres@p620 ~]$ oid2name
All databases:
Oid Database Name Tablespace ----------------------------------
5 postgres pg_default
16409 sch_db pg_default
4 template0 pg_default
1 template1 pg_default
Здесь:
- 16440 - oid табличного пространства;
- 16409 - oid базы данных sch_db;
- 16441 - oid таблицы tab_in_newts.
В табличном пространстве newtabspace создана таблица tab_in_newts. Хоть таблица и пустая, но файл для хранения ее данных уже создан, он имеет нулевой размер. Узнать имя файла, сохраняющего данные таблицы, можно функцией pg_relation_filepath().
https://www.postgresql.org/docs/15/disk-usage.html.
https://www.postgresql.org/docs/15/functions-admin.html.
Какой получился путь к данным таблицы в примере?
- $PGDATA/pg_tblspc/16440 - каталог табличного пространства newtabspace;
- $PGDATA/pg_tblspc/16440/PG_15_202310091/16409 - каталог базы данных sch_db для размещения объектов этой базы в табличном пространстве newtabspace;
- $PGDATA/pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16441 - собственно файл для размещения данных таблицы tab_in_newts.
Убедимся, что эта таблица не разместила свои данные в табличном пространстве pg_default, являющемся для БД sch_db ТП по умолчанию:
[postgres@p620 ~]$ oid2name -d sch_db -t tab_in_newts
From database "sch_db":
Filenode Table Name
------------------------
16441 tab_in_newts
[postgres@p620 ~]$ ls -l $PGDATA/base/16409/16441
ls: невозможно получить доступ к '/pgdata/06/data/base/16409/16441': No such file or directory
Создание объекта в ТП по умолчанию
sch_db=# CREATE INDEX ON tab_in_newts(msg);
CREATE INDEX
sch_db=# SELECT * FROM pg_indexes WHERE tablename = 'tab_in_newts' \gx
-[ RECORD 1 ]--------------------------------------------------------------------------
schemaname | public
tablename | tab_in_newts
indexname | tab_in_newts_msg_idx
tablespace |
indexdef | CREATE INDEX tab_in_newts_msg_idx ON public.tab_in_newts USING btree (msg)
sch_db=# SELECT pg_relation_filepath('tab_in_newts_msg_idx');
pg_relation_filepath
----------------------
base/16409/16446
БД sch_db
(1 строка)
oid индекса
sch_db=# \! ls -l $PGDATA/base/16409/16446
-rw------- 1 postgres postgres 8192 окт 14 12:00 /pgdata/06/data/base/16409/16446
Здесь:
- base - ТП pg_default;
- 16409 - БД sch_db;
- 16446 - oid индекса.
Таблица может размещаться в одном табличном пространстве, а индекс для колонки этой таблицы - в другом. В этом примере так и произошло, поскольку команде CREATE INDEX ключевое слово TABLESPACE задано не было.
В отличие от самой таблицы (она пока пустая), размер файла с данными которой нулевой, физический размер файла с данными индекса 8Кб - это ровно одна страница. Так произошло в силу того, что первая страница индекса всегда содержит структуры, необходимые для самого индекса, соответственно, индекс не может быть нулевого размера.
Перемещение объекта в другое ТП
sch_db=# SELECT pg_relation_filepath('tab_in_newts_msg_idx');
pg_relation_filepath
----------------------
base/16409/16446
(1 строка)
sch_db=# ALTER INDEX tab_in_newts_msg_idx SET TABLESPACE newtabspace;
ALTER INDEX
sch_db=# SELECT indexname, tablespace FROM pg_indexes WHERE tablename = 'tab_in_newts';
indexname | tablespace
---------------------+-------------
tab_in_newts_msg_idx | newtabspace
(1 строка)
sch_db=# SELECT pg_relation_filepath('tab_in_newts_msg_idx');
pg_relation_filepath
---------------------------------------------
pg_tblspc/16440/PG_15_202310091/16409/16447 - данные индекса в ТП newtablespace
(1 строка)
Таблицу можно переместить в другое табличное пространство командой ALTER TABLE, индекс - ALTER INDEX и так далее. https://www.postgresql.org/docs/15/sql-altertable.html.
https://www.postgresql.org/docs/15/sql-alterindex.html.
В примере на слайде из табличного пространства pg_default переносится файл данных индекса в табличное пространство newtabspace.
Следует понимать, что перенос выполняется посредством создания нового файла (что видно а примере - изменился oid) и последовательного копирования в него данных из исходного файла. Таким образом, эта процедура создает загрузку на подсистему ввода- вывода и может продолжаться очень длительное время для больших объектов.
Создание БД с указанием ТП
sch_db=# CREATE DATABASE nts_db TABLESPACE newtabspace;
sch_db=# \x \l+ ???_db \x
-[ RECORD 1 ]------+------------
Имя | nts_db
Владелец | postgres
Кодировка | UTF8
LC_COLLATE | en_US.UTF8
LC_CTYPE | en_US.UTF8
локаль ICU |
Провайдер локали | libc
Права доступа |
Размер | 9607 kB
Табл. пространство | newtablespace
Описание |
-[ RECORD 2 ]------+------------
Имя | sch_db
Владелец | postgres
Кодировка | UTF8
LC_COLLATE | en_US.UTF8
LC_CTYPE | en_US.UTF8
локаль ICU |
Провайдер локали | libc
Права доступа |
Размер | 9687 kB
Табл. пространство | pg_default
Описание |
У каждой базы данных есть табличное пространство, в котором по умолчанию будут размещаться данные объектов в этой базе. В таблице системного каталога pg_catalog.pg_database в поле dattablespace для каждой базы данных запомнен oid ее табличного пространства по умолчанию.
https://www.postgresql.org/docs/15/catalogs.html.
https://www.postgresql.org/docs/15/catalog-pg-database.html.
В строках представлений, информирующих об объектах базы данных, хранящих данные на диске, есть столбец, показывающий табличное пространство для хранения данных конкретного объекта.
Например, в представлении pg_tables есть столбец tablespace. Это поле не будет пустым у тех таблиц, которые хранят данные в иных табличных пространствах, не назначенных по умолчанию для данной базы. https://www.postgresql.org/docs/15/view-pg-tables.html.
Информация о ТП для объектов баз данных
nts_db=# CREATE TABLE t_def_ts (dtme timestamp DEFAULT now());
CREATE TABLE
nts_db=# CREATE TABLE t_new_ts (dtme timestamp DEFAULT now()) TABLESPACE pg_default; CREATE TABLE
nts_db=# SELECT tablename, tablespace FROM pg_tables WHERE tablename ~ '^t';
tablename | tablespace
-----------+------------
t_def_ts |
t_new_ts | pg_default
(2 строки)
В базе nts_db создана таблица t_def_ts в табличном пространстве по умолчанию для этой базы - newtabspace.
Таблица t_new_ts, напротив, табличном пространстве, не являющемся для базы nts_db пространством по умолчанию - pg_default.
В выводе из представления pg_tables видно, что столбец tablespace пуст, что свидетельствует о расположении данных для этой таблицы в табличном пространстве по умолчанию для БД nts_db - newtabspace.
Если при создании базы данных было указано табличное пространство, отличное от pg_default, то именно явно указанное пространство и будет для этой базы данных табличным пространством по умолчанию.
Имя табличного пространства pg_default выводится в строке pg_tables для таблицы t_new_ts, поскольку оно явно было указано для этой таблицы.
Наоборот, для таблицы t_def_ts не выведено имя табличного пространства в столбце tablespace по причине того, что при создании этой таблицы было использовано табличное пространство, установленное для этой базы по умолчанию - newtabspace.
Массовое перемещение
nts_db=# ALTER TABLE ALL IN TABLESPACE pg_default SET TABLESPACE newtabspace;
ALTER TABLE
nts_db=# SELECT tablename, tablespace FROM pg_tables WHERE tablename ~ '^t';
tablename | tablespace
----------+------------
t_new_ts |
t_def_ts |
(2 строки)
Для перемещения всех таблиц в другое табличное пространство имеется команда ALTER TABLE ALL IN TABLESPACE.
Для индексов, аналогично - ALTER INDEX ALL IN TABLESPACE.
Вместо массового перемещения индексов можно использовать REINDEX.
При обоснованной необходимости можно массово перенести объекты базы данных в другое табличное пространство. Это может быть достаточно длительная процедура, причем при копировании данных посредством подсистемы ввода-вывода, доступ к данным будет заблокирован. Перемещение индексов можно заменить переиндексированием перенесенных в другое табличное пространство таблиц.https://www.postgresql.org/docs/15/sql-reindex.html.
Хранение информации на носителях
Сегманты
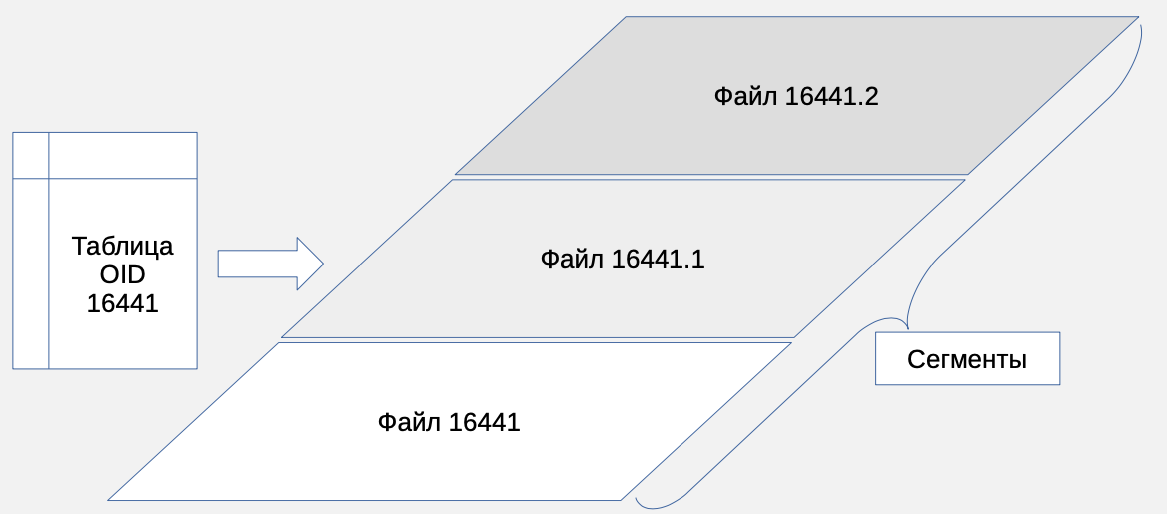
Создание таблицы порождает пустой файл для хранения данных с именем - oid таблицы, называемый сегментом.
По мере вставки строк сегмент дискретно увеличивается с шагом, определенным размером страниц - 8Кб по умолчанию.
Когда размер сегмента достигает 1Гб, выделяется новый сегмент, имя которого также формируется из oid таблицы, но с добавлением порядкового номера, начиная с единицы.
[postgres@p620 ~]$ psql -d sch_db -q
sch_db=# \t
sch_db=# SELECT pg_relation_filepath('tab_in_newts');
pg_tblspc/16440/PG_15_202310091/16409/16441
sch_db=# \! ls -l $PGDATA/pg_tblspc/16440/PG_15_202310091/16409/16441*
-rw------- 1 postgres postgres 0 окт 14 10:16
/pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16441
sch_db=# INSERT INTO tab_in_newts(id) VALUES (1);
sch_db=# \! ls -l $PGDATA/pg_tblspc/16440/PG_15_202310091/16409/16441*
-rw------- 1 postgres postgres 8192 окт 14 20:20
/pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16441
Данные таблиц хранятся в сегментах - файлах на диске. Имена файлов сегментов соответствуют oid таблицы. В примере - 16441. Сегменты содержат 8Кб (по умолчанию) страницы со строками данных.
Первая вставка приводит к выделению первой страницы и размер сегмента становится 8Кб. Если заполняется первая страница, выделяется вторая и так далее до тех пор, пока суммарный размер сегмента не достигнет 1Гб (историческое ограничение). Таблицы в PostgreSQL при размере страниц 8Кб могут достигать размера 32Тб. При увеличении таблицы выделяются новые сегменты: когда полностью заполняется первый сегмент 1Гб данных, выделяется второй, третий и так далее. Например, первый сегмент в примере 16441. Когда он достигнет 1Гб, будет выделен второй, который будет называться 16411.1, далее - третий с именем 16411.2 и так далее. https://www.postgresql.org/docs/15/storage-file-layout.html.
https://www.postgresql.org/docs/15/limits.html.
Слои
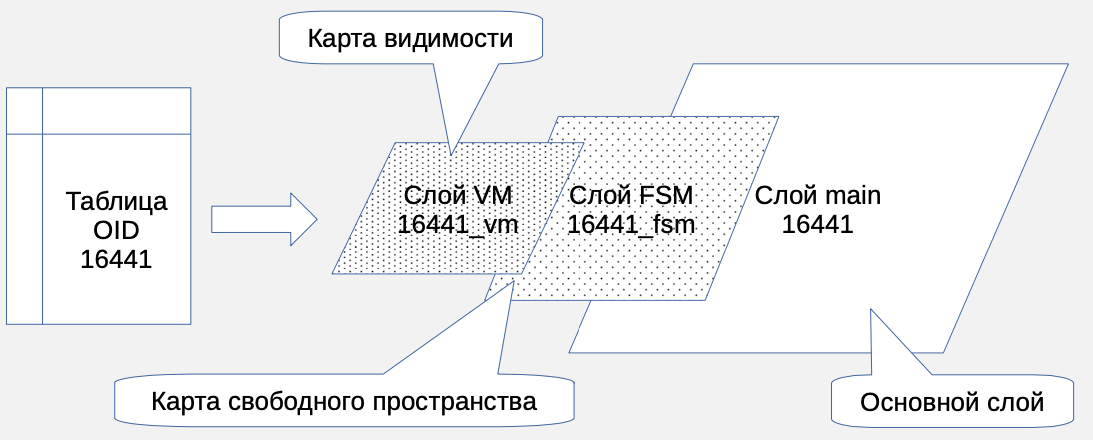
Хранение данных организовано с помощью слоев (fork). Данные хранятся в файлах основного слоя (main), их имена формируются из oid таблицы. При достижении 1Гб файла основного слоя, создается новый файл (сегмент) к имени которого добавляется порядковый номер, начиная с единицы: 16441.1, затем 16441.2 и так далее. Основной слой при добавлении данных занимает основное пространство. У индексов также имеется основной слой.
Карта свободного пространства (free space map - fsm) необходима для ускорения поиска свободного места на страницах данных при операциях вставки и обновления. Файлы слоя свободного пространства имеют суффикс _fsm, а при достижении 1Гб с ними происходит та же процедура, что и с файлами основного слоя - создается новый файл, к имени которого добавляется порядковый номер, начиная с единицы. Этот слой существует у таблиц и индексов.
Слой карты видимости (visibility map - vm) существует только для таблиц и в нем отмечаются те страницы, на которых все версии строк актуальны. Такие страницы команда VACUUM при следующем запуске пропускает, так как на них нет "мертвых" (dead) версий строк, подлежащих чистке. https://www.postgresql.org/docs/15/storage-file-layout.html.
https://www.postgresql.org/docs/15/storage-fsm.html.
https://www.postgresql.org/docs/15/storage-vm.html.
Слои нежурналируемых таблиц
sch_db=# CREATE UNLOGGED TABLE unl_tab (id integer, datum timestamp DEFAULT now()) TABLESPACE newtabspace;
CREATE TABLE
sch_db=# SELECT pg_relation_filepath('unl_tab');
pg_relation_filepath
---------------------------------------------
pg_tblspc/16440/PG_15_202310091/16409/16484
(1 строка)
sch_db=# \! ls -l $PGDATA/pg_tblspc/16440/PG_15_202310091/16409/16484*
-rw------- 1 postgres postgres 0 окт 16 21:11 /pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16484
-rw------- 1 postgres postgres 0 окт 16 21:11 /pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16484_init
Нежурналируемые таблицы не защищают журналом транзакций WAL. Следовательно, изменения в них производятся быстрее, так при этом не надо ничего писать в WAL. В результате сбоя информация в них теряется, так как они восстанавливаются из специального слоя init, который есть только у нежурналируемых таблиц. Слой init представляет собой пустую таблицу с такой же структурой, которая была определена для нежурналируемой таблицы. https://www.postgresql.org/docs/15/storage-init.html.
Слои временных таблиц
sch_db=# CREATE TEMP TABLE tmp_tab (id text, dt timestamp DEFAULT now()) TABLESPACE newtabspace ;
CREATE TABLE
sch_db=# SELECT pg_relation_filepath('tmp_tab');
pg_relation_filepath
------------------------------------------------
pg_tblspc/16440/PG_15_202310091/16409/t6_16492
(1 строка)
sch_db=# INSERT INTO tmp_tab (id) VALUES ('Запись.');
INSERT 0 1
sch_db=# VACUUM tmp_tab;
VACUUM
sch_db=# \! ls -l $PGDATA/pg_tblspc/16440/PG_15_202310091/16409/t6_16492*
-rw------- 1 postgres postgres 8192 окт 17 14:17 /pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/t6_16492
-rw------- 1 postgres postgres 24576 окт 17 14:17 /pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/t6_16492_fsm
-rw------- 1 postgres postgres 8192 окт 17 14:17 /pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/t6_16492_vm
Временные таблицы, хотя и живут лишь в течении сессии или даже транзакции, должны сохранять в течении своей жизни данные на диске. При этом используются те же слои, что и для обычных таблиц:
- основной (main);
- карта свободного пространства (fsm);
- карта видимости (vm).
Для того чтобы отличить файлы временных таблиц от обычных, к именам файлов добавлен префикс t (temp).
После этого префикса идет номер временной схемы, которой принадлежит временная таблица.
В примере полное имя временной таблицы pg_temp_6.tmp_tab. https://www.postgresql.org/docs/15/storage-file-layout.html.
Хранение больших атрибутов TOAST
Любая строка таблицы должна полностью помещаться на страницу. Если в поле строки записывается достаточно большое значение, оно может значительно превышать размер страницы. Так, например, тип данных VARCHAR позволяет хранить строки длиной 10485760 символов, а максимальный размер строки типа TEXT почти 1Гб. https://www.postgresql.org/docs/current/datatype-character.html. Сохранять в таблицах PostgreSQL такие большие значения позволяет технология TOAST (The Oversized Attributes Storage Technique). Она позволяет следующее:
- сжимать поля с длинными значениями, добиваясь помещения сжатой стройки в пространство страницы;
- помещать в специальную toast таблицу нарезанные на проиндексированные фрагменты исходные поля строк;
- помещать в таблицу toast фрагменты строк, дополнительно сжимая их. Во всех трех вариантах цель - добиться размещения преобразованной строки на одной странице.
В метаданных таблиц есть специальное поле (reltoastrelid в таблице pg_class), идентифицирующее toast таблицу, в которой будут храниться фрагменты "длинных" полей. Таблицы toast находятся в специальной схеме pg_toast.
Технология TOAST работает прозрачно для приложений, вся работа по сжатию, фрагментации и обратной сборке выполняется незаметно. https://www.postgresql.org/docs/15/storage-toast.html.
Размеры объектов
Определение размеров слоев таблиц
sch_db=# SELECT pg_relation_size('tab_in_newts','main') AS "MAIN",
sch_db-# pg_relation_size('tab_in_newts','fsm') AS "FSM",
sch_db-# pg_relation_size('tab_in_newts','vm') AS "VM";
MAIN | FSM | VM
------+-------+------
8192 | 24576 | 8192
(1 строка)
sch_db=# INSERT INTO tab_in_newts SELECT i,'Nr '||i::text FROM generate_series(1,100000) AS g(i);
INSERT 0 100000
sch_db=# SELECT pg_relation_size('tab_in_newts','main') AS "MAIN",
pg_relation_size('tab_in_newts','fsm') AS "FSM",
pg_relation_size('tab_in_newts','vm') AS "VM";
MAIN | FSM | VM
---------+-------+------
4431872 | 24576 | 8192
(1 строка)
В примере выше была использована функция pg_relation_size(), выводящая размер слоя в байтах. Первое измерение производилось, когда в таблице была единственная запись (см. слайд 16) и в слое main хранилась одна страница 8Кб с единственной строкой.
После вставки ста тысяч строк в таблицу ее размер увеличился: в слой main теперь занимает в файловой системе 4431872 байт.
Проверим сведения функции pg_relation_size() непосредственным измерением размеров файлов:
sch_db=# \! ls -l
$PGDATA/pg_tblspc/16440/PG_15_202310091/16409/16441*
-rw------- 1 postgres postgres 4431872 окт 17 15:07
/pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16441
-rw------- 1 postgres postgres 24576 окт 17 15:07
/pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16441_fsm
-rw------- 1 postgres postgres 8192 окт 17 15:07
/pgdata/06/data/pg_tblspc/16440/PG_15_202310091/16409/16441_vm
https://www.postgresql.org/docs/current/functions-admin.html#FUNCTIONS-ADMIN-DBOBJECT.
Определение размеров индексов
sch_db=# \d tab_in_newts
Таблица "public.tab_in_newts"
Столбец | Тип | Правило сортировки | Допустимость NULL | По умолчанию
---------+---------+--------------------+-------------------+--------------
id | integer | | |
msg | text | | |
Индексы:
"tab_in_newts_msg_idx" btree (msg), табл. пространство "newtabspace"
Табличное пространство: "newtabspace"
sch_db=# SELECT pg_relation_size('tab_in_newts_msg_idx','main') AS "MAIN", pg_relation_size('tab_in_newts_msg_idx','fsm') AS "FSM";
MAIN | FSM
---------+-----
5275648 | 0
(1 строка)
sch_db=# SELECT pg_indexes_size('tab_in_newts');
pg_indexes_size
-----------------
5275648
(1 строка)
Функция pg_indexes_size() возвращает суммарный размер всех индексов таблицы.
Функция pg_relation_size() возвращает размер любого отношения (relation), например, индекса.
Также имеется удобная функция pg_indexes_size(), принимающая в качестве аргумента имя таблицы и возвращающая суммарный размер всех индексов таблицы. https://www.postgresql.org/docs/current/functions-admin.html.
Размер таблицы с TOAST
sch_db=# CREATE TABLE bigfield(tme timestamp DEFAULT now() PRIMARY KEY, big text);
CREATE TABLE
sch_db=# ALTER TABLE bigfield ALTER COLUMN big SET STORAGE external;
sch_db=# INSERT INTO bigfield(big) VALUES(repeat('ABCD',1000000));
INSERT 0 1 ~4Мб
sch_db=# SELECT pg_relation_size('bigfield','main');
pg_relation_size
------------------
8192
(1 строка)
sch_db=# SELECT pg_table_size('bigfield');
pg_table_size
---------------
4218880
(1 строка)
Функция pg_table_size() возвращает размер таблицы с учетом TOAST.
Определить размер таблицы с учетом хранения длинных значений полей в toast таблице позволяет функция pg_table_size(). В примере для поля big таблицы bigfield установлен тип хранения в toast таблице без сжатия. В поле big записано значение размером порядка 4Мб, но размер основного слоя таблицы bigfield всего 8Кб, так как данные находятся в toast таблице.
В поле reltoastrelid таблицы pg_class содержится oid toast таблицы. Определив oid этой таблицы можно узнать объем данных, хранящийся в слое main таблицы toast.
sch_db=# SELECT pg_relation_size((SELECT reltoastrelid FROM
pg_class WHERE relname = 'bigfield')::regclass);
pg_relation_size
------------------
4112384
(1 строка)
https://www.postgresql.org/docs/15/functions-admin.html.
Размер таблицы с индексами и TOAST
sch_db=# SELECT pg_total_relation_size('bigfield'); pg_total_relation_size
------------------------
4235264
(1 строка)
Дисковое пространство, занимаемое таблицей, ее индексами и toast таблицей, возвращает функция pg_total_relation_size(). Возвращаемый ей результат равен сумме значений, возвращаемый функциями pg_table_size() и pg_indexes_size(). https://www.postgresql.org/docs/15/functions-admin.html.
Размер базы данных
sch_db=# SELECT pg_size_pretty(pg_database_size(current_database()));
pg_size_pretty
----------------
23 MB
(1 строка)
sch_db=# SELECT pg_size_pretty(pg_database_size('nts_db'));
pg_size_pretty
----------------
9607 kB
(1 строка)
Суммарный объем дискового пространства, занимаемый всеми объектами базы данных можно получить, используя функцию pg_database_size(). В примере использованы удобная функция current_database(), возвращающая имя базы данных текущего сеанса, а также функция pg_size_pretty() для представления размера файлов в удобных для восприятия единицах. https://www.postgresql.org/docs/15/functions-admin.html.
https://www.postgresql.org/docs/15/functions-info.html.
Работа с табличным пространством
Объекты БД в табличном пространстве
postgres=# \c postgres
Вы подключены к базе данных "postgres" как пользователь "postgres". postgres=# SELECT datname FROM pg_database WHERE oid IN (
SELECT pg_tablespace_databases(
(SELECT oid FROM pg_tablespace WHERE spcname = 'newtabspace')));
datname
---------
sch_db
nts_db
(2 строки)
Удалить базе данных командой DROP DATABASE или схему командой DROP SCHEMA ... CASCADE можно со всеми данными, которые в них находились. Однако при попытке удалить табличное пространство, в котором размещаются объекты баз данных, возникнет ошибка.
То есть, до того, как удалять табличное пространство, необходимо либо перенести все объекты из него в остающиеся табличные пространства, либо удалить эти объекты каким-либо способом.
Например, перед удалением табличного пространства вначале удалить все базы данных, если это допустимо. Получить список имен баз данных, содержащих объекты в заданном табличном пространстве, можно функцией pg_tablespace_databases(). Она возвращает набор строк с единственным полем - oid баз данных.
Преобразовать oid в имя базы несложно с помощью системного каталога pg_tablespace. https://www.postgresql.org/docs/15/functions-info.html.
Перенос таблиц в табличное пространство
postgres=# SELECT db.datname, ts.spcname FROM pg_database db JOIN pg_tablespace ts ON (db.dattablespace = ts.oid)
WHERE datname ~ 'db$';
datname | spcname
---------+-------------
sch_db | pg_default
nts_db | newtablespace
(2 строки)
Вы подключены к базе данных "nts_db" как пользователь "postgres".
nts_db=# SELECT tablename, tablespace FROM pg_tables WHERE schemaname = 'public';
tablename | tablespace
-----------+------------
t_new_ts |
t_def_ts |
(2 строки)
nts_db=# ALTER TABLE ALL IN TABLESPACE newtabspace SET TABLESPACE pg_default;
ALTER TABLE
nts_db=# SELECT tablename, tablespace FROM pg_tables WHERE schemaname = 'public';
tablename | tablespace
-----------+------------
t_new_ts | pg_default
t_def_ts | pg_default
(2 строки)
В примере выше вначале определены табличные пространства по умолчанию для баз данных, имена которых заканчиваются на db. Затем выполнено подключение к базе nts_db, для которой табличное пространство newtabspace задано по умолчанию. В таблице pg_tables, которая информирует о таблицах в этой базе данных, в поле tablespace отсутствует имя табличного пространства, если таблица размещается в табличном пространстве по умолчанию для этой базы данных.
Далее с помощью ALTER TABLE можно задать для таблиц размещение в требуемом табличном пространстве для каждой таблицы в отдельности.
В примере показан иной подход: командой ALTER TABLE ALL IN TABLESPACE выполнено массовое перемещение таблиц в заданное табличное пространство.
Индексы можно также перенести командой ALTER INDEX ALL IN TABLESPACE, но разумно рассмотреть альтернативный путь с помощью переиндексирования REINDEX с опцией TABLESPACE. Любые операции по перемещению данных нагружают подсистему ввода-вывода, блокируют таблицы и приводят к значительным затратам по времени.
https://www.postgresql.org/docs/15/sql-altertable.html.
https://www.postgresql.org/docs/15/sql-alterindex.html.
https://www.postgresql.org/docs/15/sql-reindex.html.
Удаление табличного пространства
nts_db=# \c postgres
postgres=# DROP DATABASE nts_db;
postgres=# DROP DATABASE sch_db;
postgres=# DROP TABLESPACE newtabspace;
postgres=# \db
Список табличных пространств
Имя | Владелец | Расположение
------------+----------+-------------
pg_default | postgres |
pg_global | postgres |
(2 строки)
Если в табличном пространстве нет объектов каких-либо баз данных, оно может быть удалено.
Команда DROP TABLESPACE удалит табличное пространство, если оно пустое. https://www.postgresql.org/docs/15/sql-droptablespace.html.
Итоги
- Табличные пространства - каталоги в файловой системе, содержащие файлы для хранения данных.
- По умолчанию два ТП: pg_global и pg_default, другие можно создавать и удалять, если в них нет данных.
- При создании нового ТП указывают каталог в файловой системе, а в каталоге pg_tblspc создается символическая ссылка на него.
- Отношения хранятся в сегментах - файлах, размер которых не превышает 1Гб.
- Объекты используют слои, слой main хранит данные и есть всегда, остальные слои: fsm, vm, init - зависят от типа объекта.
- Технология TOAST позволяет хранить значения, на помещающиеся на одну страницу.