Лекция 08. Базы данных
В этой главе:
- Кластер баз данных
- Базы данных
- Объекты баз данных
- Системный каталог
- Расширения
Кластер баз данных
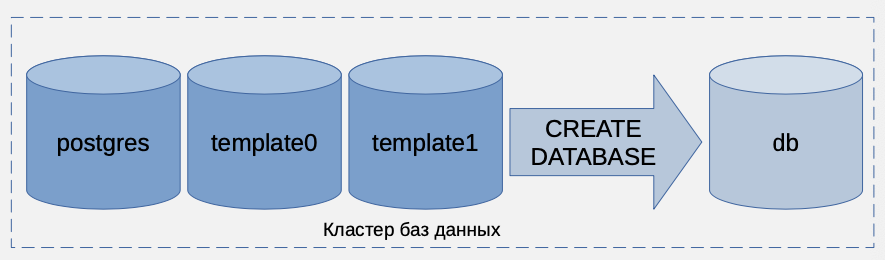
Один экземпляр СУБД обслуживает сразу несколько баз данных. Все базы данных, обслуживаемые экземпляром, называют кластером баз данных.
Кластер создается командой initdb, которая создает сразу три базы данных: template1, template0 и postgres. Процедура создания баз данных определена в Backend Interface (BKI). https://www.postgresql.org/docs/15/bki.html.
Подробно о initdb: https://www.postgresql.org/docs/15/app-initdb.html.
Помимо исходных баз данных initdb создает необходимые для работы СУБД служебные файлы и каталоги, а также файлы конфигурации. Новые базы данных создаются путем копирования существующих.
Три базы данных создаются сразу:
– template1 - основной шаблон для создания новых баз данных; – template0 - шаблон, к которому по умолчанию нельзя подключиться, не предназначен для изменения; – postgres - специальная база данных для подключения суперпользователя postgres.
База данных postgres имеет специальное предназначение для подключения суперпользователя postgres.
База данных template1 используется в качестве шаблона, из которого создаются новые базы данных по умолчанию. К этой базе данных можно подключаться и изменять ее содержимое.
В отличие от предыдущей, база данных template0, хотя также и является шаблоном, но она не предназначена для подключения и ее не следует изменять. Базу данных template0 можно использовать для восстановления template1 при его порче, а также она используется при восстановлении из резервных копий и при необходимости создания новой базы данных с измененной кодировкой по сравнению с кодировкой, использованной при создании кластера баз данных.
Создание кластера БД
$ initdb -k
Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres". От его имени также будет запускаться процесс сервера.
Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8". Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8". Выбрана конфигурация текстового поиска по умолчанию "russian".
Контроль целостности страниц данных включен.
исправление прав для существующего каталога /pgdata/06/data... ок
создание подкаталогов... ок
выбирается реализация динамической разделяемой памяти... posix
Каталог данных определяется либо опцией -D, либо установкой переменной окружения PGDATA.
В примере опция -k включила контроль целостности данных на страницах.
Команда initdb предназначена для создания нового кластера баз данных. Кластер - коллекция баз данных, обслуживаемых одним экземпляром.
Команда initdb не будет работать, если ее запускает суперпользователь ОС root. Непривилегированный пользователь ОС (обычно postgres), запускающий эту команду, указывает путь к каталогу данных с помощью опции -D, на который этот пользователь должден иметь соответствующие права на запись. Если путь не указан, используется значение переменной окружения PGDATA. Пользователь ОС, создающий кластер становится исходным суперпользователем СУБД. Права на каталог данных обычно устанавливают с правами на чтение и запись только для выполнившего initdb пользователя. Например:
[postgres@p620 ~]$ ls -ld $PGDATA
drwx------ 24 postgres postgres 4096 окт 11 08:43 /pgdata/06/data
У initdb имеются опции -g и --allow-group-access, предоставляющими доступ на чтение к каталогу с данными при инициализации кластера. Это бывает необходимо для задач резервного копирования. Опция -k необходима для включения проверки контрольных сумм на страницах данных. Также имеются опции для установки настроек локализации, если необходимо чтобы они отличались от настроек ОС. https://www.postgresql.org/docs/15/app-initdb.html.
Базы данных
Исходные базы данных
[postgres@p620 ~]$ psql
psql (15.5)
Введите "help", чтобы получить справку.
postgres=# \l
Список баз данных
Имя | Владелец | Кодировка | LC_COLLATE | LC_CTYPE | локаль ICU | Провайдер локали | Права доступа
-----------+----------+-----------+------------+-----------+------------+------------------+-----------------------
| postgres | postgres | UTF8 | en_US.UTF8 | en_US.UTF8| | libc |
| template0| postgres | UTF8 | en_US.UTF8 | en_US.UTF8| | libc | =c/postgres postgres=CTc/postgres
| template1| postgres | UTF8 | en_US.UTF8 | en_US.UTF8| | libc | =c/postgres postgres=CTc/postgres
(3 строки)
После создания кластера с настройками по умолчанию к нему можно подключиться суперпользователем postgres.
Метакоманда \l позволяет получить список (list) баз данных.
При создании кластера командой initdb создаются три исходные базы данных:
- postgres - эта база данных нужна для подключений суперпользователя postgres, в ней обычно не хранят какие-либо бизнес-данные;
- template1 - шаблонная база данных, необходимая для создания других баз данных, ее содержимое можно изменять;
- template0 - шаблонная база данных, содержимое которой НЕ следует изменять.
https://www.postgresql.org/docs/15/app-initdb.html.
https://www.postgresql.org/docs/15/manage-ag-templatedbs.html.
Получить список баз данных в psql можно метакомандой \l . https://www.postgresql.org/docs/15/app-psql.html.
Создание и удаление базы данных
postgres=# CREATE DATABASE db1;
CREATE DATABASE
postgres=# \l db1
Список баз данных
Имя | Владелец | Кодировка | LC_COLLATE | LC_CTYPE | локаль ICU | Провайдер локали | Права доступа
-----+----------+-----------+------------+------------+------------+------------------+---------------
db1 | postgres | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc |
(1 строка)
postgres=# DROP DATABASE db1;
DROP DATABASE
postgres=# \l db1
Список баз данных
Имя | Владелец | Кодировка | LC_COLLATE | LC_CTYPE | локаль ICU | Провайдер локали | Права доступа
-----+----------+-----------+------------+----------+------------+------------------+---------------
(0 строк)
Команды SQL CREATE DATABASE и DROP DATABASE, соответственно, предназначены для создания и удаления баз данных. При создании базы данных создаются необходимые структуры в файловой системе, а в метаданных записываются сведения о новой базе данных.
Все базы данных создаются с помощью копирования содержимого существующих баз данных.
По умолчанию команда CREATE DATABASE использует шаблон template1 для копирования его содержимого во вновь создаваемую базу данных, однако это может быть изменено. Например, при создании базы данных с кодировкой, отличающейся от кодировки кластера, необходимо будет использовать шаблон template0.
Создавать базы данных имеют право суперпользователи и пользователи, имеющие атрибут CREATEDB. https://www.postgresql.org/docs/current/sql-createdatabase.html.
Удалить базу данных может суперпользователь или ее владелец (исходно - пользователь, который ее создавал). Удалить базу, к которой есть подключения, нельзя. Операция удаления невозвратная, все данные будут удалены. https://www.postgresql.org/docs/15/sql-dropdatabase.html.
Для создания и удаления баз данных можно использовать утилиты командной строки ОС createdb и dropdb. [https://www.postgresql.org/docs/15/app-createdb.html https://www.postgresql.org/docs/15/app-dropdb.html](https://www.postgresql.org/docs/15/app-createdb.html https://www.postgresql.org/docs/15/app-dropdb.html).
Метаданные о базах данных
postgres=# SELECT datname, datistemplate, datallowconn, datconnlimit, datacl FROM pg_database;
datname | datistemplate | datallowconn | datconnlimit | datacl
-----------+---------------+--------------+--------------+-------------------------------------
postgres | f | t | -1 |
template1 | t | t | -1 | {=c/postgres, postgres=CTc/postgres}
template0 | t | f | -1 | {=c/postgres, postgres=CTc/postgres}
(3 строки)
Метаданные хранятся в глобальном каталоге. Информация о базах данных хранится в таблице глобального каталога pg_database. https://www.postgresql.org/docs/15/catalog-pg-database.html.
В примере выше видно, что имеются три исходные базы данных. Является ли база данных исходным шаблоном для копирования в создаваемую базу данных показывает поле datistemplate. На самом деле, в качестве шаблона можно использовать любую существующую базу данных. Истинное значение в поле datistemplate показывает предназначение базы данных в качестве шаблона.
Для шаблона template0 значение поля datallowconn установлено в true для исключения подключения к этой базе данных. Это необходимо для запрета модификации содержимого этой шаблонной базы данных. Если поле datconnlimit содержит -1, значит ограничений по количеству подключений к этой базе данных нет, иначе в поле содержится максимально разрешенное количество соединений.
В поле datacl в виде массива содержатся права доступа к базе данных.
Работа с шаблоном template1
postgres=# \c template1
Вы подключены к базе данных "template1" как пользователь "postgres".
template1=# CREATE EXTENSION pg_hint_plan;
CREATE EXTENSION
template1=# CREATE DATABASE db;
CREATE DATABASE
template1=# \c db
Вы подключены к базе данных "db" как пользователь "postgres".
db=# \dx
Список установленных расширений
Имя | Версия | Схема | Описание
--------------+---------+------------+------------------------------
pg_hint_plan | 1.5 | hint_plan |
plpgsql | 1.1 | pg_catalog | PL/pgSQL procedural language
(2 строки)
На примере выше продемонстрировано подключение к шаблонной базе данных template1, которая используется для создания новых баз данных по умолчанию. Если в этот шаблон добавить какие-либо объекты, то они будут копироваться во вновь создаваемые базы данных. В примере в template1 добавлено расширение pg_hint_plan, позволяющее использовать подсказки (hints) планировщику запросов.
В результате этого в template1 будет создана схема hint_plan :
# \dn
Список схем
Имя | Владелец
-----------+-------------------
hint_plan | postgres
public | pg_database_owner
(2 строки)
А также будут доступны объекты из этого расширения:
# \dx+ pg_hint_plan
Объекты в расширении "pg_hint_plan"
Описание объекта
---------------------------------
sequence hint_plan.hints_id_seq
table hint_plan.hints
(2 строки)
В созданной базе данных db в примере на слайде появятся объекты, скопированные из template1 - и объекты расширения pg_hint_plan. Если в новых базах данных эти объекты не нужны, удалите их из template1. В данном случае командами DROP SCHEMA и DROP EXTENSION.
Использование БД в качестве шаблона
db=# CREATE TABLE t_db AS SELECT 'Таблица из db'::text;
SELECT 1
db=# CREATE DATABASE basa TEMPLATE db;
CREATE DATABASE
db=# \c basa
Вы подключены к базе данных "basa" как пользователь "postgres".
basa=# SELECT * FROM t_db ;
text
---------------
Таблица из db
(1 строка)
В примере выше в базе данный db создана таблица t_db. Подключение выполнено с правами суперпользователя, поэтому успешно выполнена команда создания новой базы данных base с помощью копирования всего содержимого из базы db. Подключившись к базе данных base проверено, что таблица t_db в новой базе имеется и данные в ней тоже.
В качестве шаблона можно использовать любую БД. В примере в БД db создана таблица t_db, а из БД db была создана БД basa, содержащая копии всего, что было в БД db, в том числе и таблицу t_db.
Создание БД с измененной локализацией
basa=# CREATE DATABASE db_koi8r ENCODING = 'koi8r' LOCALE = 'ru_RU.koi8r';
ERROR: new encoding (KOI8R) is incompatible with the encoding of the template database (UTF8)
ПОДСКАЗКА: Use the same encoding as in the template database, or use template0 as template.
basa=# CREATE DATABASE db_koi8r ENCODING = 'koi8r' LOCALE = 'ru_RU.koi8r' TEMPLATE = template0; CREATE DATABASE
basa=# \l db*
Список баз данных
Имя | Владелец | Кодировка | LC_COLLATE | LC_CTYPE | локаль ICU | Провайдер локали | Права доступа
----------+----------+-----------+------------+-------------+------------+------------------+---------------
db | postgres | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc |
db_koi8r | postgres | KOI8R | ru_RU.koi8r| ru_RU.koi8r | | libc |
(2 строки)
Кодировка определяет способ представления символов текста в БД, LC_COLLATE - правила сортировки, LC_CTYPE - классификация символов.
- Локализация для БД по умолчанию в определяется при создании кластера утилитой initdb.
- При необходимости создать БД с измененными настройками локали необходимо использовать шаблон template0.
В примере продемонстрировано, что команда создания базы данных с измененными настройками локализации не сработает успешно, если не указан шаблон template0.
Локализация определяет машинное представление символов в базе данных, например, UTF8 или KOI8R, а также устанавливает правила сортировки и классификации символов. Более того, от настроек локализации зависят форматы представления дат, времени, денежных единиц, сообщений сервера и клиента и многое другое.
Локализация определяется с помощью набора специальных переменных, устанавливаемых в ОС, а также настроек СУБД.
О настройках локализации в ОС можно узнать в мануале, вызвав в командной строке ОС команду: man 7 locale.
Настройки СУБД, связанные с локализацией: https://www.postgresql.org/docs/15/locale.html.
Изменение настроек баз данных
basa=# ALTER DATABASE db CONNECTION LIMIT 5;
ALTER DATABASE
basa=# SELECT datname, datconnlimit FROM pg_database WHERE datname = 'db' \gx
-[ RECORD 1 ]+---
datname | db
datconnlimit | 5
Если к БД нет текущих подключений, можно менять ее параметры, а также можно переименовать эту БД. В примере выше установлено ограничение на количество подключений, равное пяти.
При необходимости можно изменять параметры баз данных с помощью команды ALTER DATABASE. Настройки, связанные с локализацией, после создания базы данных уже невозможно. Но, например, ограничить максимальное количество подключений к базе данных вполне можно. Этой же командой можно изменить имя существующей базы данных. https://www.postgresql.org/docs/15/sql-alterdatabase.html.
Определение размера базы данных
basa=# SELECT pg_size_pretty(pg_database_size('db'));
pg_size_pretty
----------------
9655 kB
(1 строка)
basa=# \x \l+ db \x
Расширенный вывод включен.
Список баз данных
-[ RECORD 1 ]------+-----------
Имя | db
Владелец | postgres
Кодировка | UTF8
LC_COLLATE | en_US.UTF8
LC_CTYPE | en_US.UTF8
локаль ICU |
Провайдер локали | libc
Права доступа |
Размер | 9655 kB
Табл. пространство | pg_default
Описание |
- Функция pg_database_size() возвращает размер в байтах заданной аргументом базы данных.
- Для получения размера в удобных единицах измерения используется функция pg_size_pretty().
- При использовании psql можно воспользоваться метакомандой \l+ .
Узнать сколько места занимает база данных в файловой системе позволяет функция pg_database_size(). Эта функция возвращает размер в байтах.
https://www.postgresql.org/docs/15/functions-admin.html#FUNCTIONS-ADMIN-DBOBJECT.
Если необходимо получить размер в более удобных единицах, можно воспользоваться функцией pg_size_pretty().
Метакоманда \l+ psql также предоставляет информацию о размере баз данных.
Объекты баз данных
Схемы
Кластер состоит из баз данных. База данных - хранилище объектов, например таблиц. У каждого объекта есть имя. Каждый объект обязательно принадлежит той или иной схеме. Полное имя объекта состоит из имени схемы, которой принадлежит объект, и через точку имени объекта. Например: acc.income - полное имя объекта income в схеме acc.
Имя объекта без указания схемы является неполным и в базе данных может иметься несколько абсолютно разных объектов с одинаковыми именами, но они обязательно будут расположены в разных схемах. Схема определяет пространство имен.
Преимущество схем заключается в возможности распределения разных объектов с одинаковыми именами по разным схемам, тематически связанными, например, с различными приложениями или пользователями. Тем не менее, пользователь и схема - разные понятия и их имена вовсе не обязаны совпадать.
Во многих случаях бывает удобно создавать для пользователей их индивидуальные схемы с именами, совпадающими с именами пользователей. Но в общем такого требования нет.
Еще одно преимущество схем состоит в том, что у схем имеются права, которые могут разрешать создание в схемах объектов и использование этих объектов. Пользователи, не имеющие прав на использование объектов в какой-либо схеме, не смогут получить к этим объектам доступ даже при наличие привилегий на сами объекты. [https://www.postgresql.org/docs/15/ddl-schemas.html].
Исходный список схем
postgres=# CREATE DATABASE sch_db;
CREATE DATABASE
postgres=# \c sch_db
Вы подключены к базе данных "sch_db" как пользователь "postgres".
sch_db=# \dn
Список схем
Имя | Владелец
--------+-------------------
public | pg_database_owner
(1 строка)
sch_db=# \dnS
Список схем
Имя | Владелец
--------------------+------------------- information_schema | postgres
pg_catalog | postgres
pg_toast | postgres
public | pg_database_owner
(4 строки)
Стандарт SQL требует наличие схемы public для размещения в ней объектов общего пользования. В ранних версиях PostgreSQL любой пользователь мог создать объект, например, таблицу. Однако сейчас это может сделать исходно лишь владелец базы данных.
Список схем можно получить метакомандой \dn клиента psql. Если необходимо вывести список всех имеющихся схем, включая системные, используйте метакоманду \dnS.
Информация о схемах содержится в таблице pg_namespace системного каталога. Системные схемы:
- pg_catalog - схема для объектов системного каталога, содержащего метаданные о всех имеющихся объектах;
- information_schema - схема с метаданными об имеющихся объектах, соответствующая стандарту SQL;
- pg_toast - схема для специальных таблиц, хранящих значения полей, не помещающихся на обычные страницы данных.
https://www.postgresql.org/docs/15/catalogs.html.
https://www.postgresql.org/docs/15/information-schema.html.
https://www.postgresql.org/docs/15/storage-toast.html.
Создание схемы
sch_db=# CREATE SCHEMA work AUTHORIZATION student;
CREATE SCHEMA
sch_db=# \dn
Список схем
Имя | Владелец
-------+-------------------
public | pg_database_owner
work | student
(2 строки)
Команда CREATE SCHEMA создает новую схему в базе данных. Имя новой схемы должно отличаться от любых существующих в базе схем. Стандарт SQL обязывает чтобы владелец схемы также владел и всеми объектами в ней. Однако, в PostgreSQL в схеме могут быть объекты с владельцами, отличающимися от владельца схемы.
Для создания схемы необходимо иметь право на создание объектов в базе данных. https://www.postgresql.org/docs/15/sql-createschema.html.
Создание объектов в схеме
sch_db=# \c - student
Вы подключены к базе данных "sch_db" как пользователь "student".
sch_db=> CREATE TABLE zp (tabno integer, salary numeric(10,2));
ERROR: permission denied for schema public
СТРОКА 1: CREATE TABLE zp (tabno integer, salary numeric(10,2));
^
sch_db=> CREATE TABLE work.zp (tabno integer, salary numeric(10,2));
CREATE TABLE
Для создания объектов в схеме необходимо обладать соответствующим правом. Исходно лишь владелец схемы и обладающие правами суперпользователя могут создавать объекты в схемах, включая схему public. Если право на создание объектов в схеме имеется, то создать новый объект в ней можно, указав полное имя создаваемого объекта с этой схемой. Если не указывать полное имя объекта, то схема, в которой будет произведена попытка создания объекта определяется автоматически на основе значения параметра настройки search_path. Этот параметр определяет последовательность просмотра схем при доступе к объекту по неполному имени, и он же определяет схему, в которой будет создаваться новый объект. В параметре search_path содержатся перечисленные через запятую имена схем, в которых последовательно слева-направо будут искать требуемый объект при доступе по неполному имени. Первая схема, в которой обнаружится объект с искомым неполным именем, будет использована при доступе к объекту. При создании объекта, имя которого указано без схемы, будет подставлена первая существующая схема. В примере создается таблица zp без указания схемы, поэтому по search_path определяется, что существует схема public. Поэтому производится попытка создать таблицу public.zp. Но пользователь student не имеет прав на создание объектов в ней. Следующая попытка создает таблицу zp в схеме work, которой при ее создании был назначен владельцем student. В результате таблица work.zp успешно создается. https://www.postgresql.org/docs/15/ddl-schemas.html#DDL-SCHEMAS-PATH.
Путь поиска
sch_db=> SHOW search_path;
search_path
-----------------
"$user", public
(1 строка)
sch_db=> SELECT current_schema();
current_schema
----------------
public
(1 строка)
Настройка параметра search_path по умолчанию: "$user", public. Соответственно, вначале проверяется наличие схемы с именем, совпадающим с именем пользователя в сеансе. Если таковая отсутствует, то происходит обращение к схеме public.
Этот параметр сессионный и может быть установлен в любой сессии:
postgres=# \dconfig+ search_path
Список параметров конфигурации
-[ RECORD 1 ]-+----------------
Параметр | search_path
Значение | "$user", public
Тип | string
Контекст | user
Права доступа |
Узнать, в какой схеме при данных настройках search_path будет создан объект, можно функцией current_schema(). [https://www.postgresql.org/docs/15/ddl-schemas.html#DDL-SCHEMAS-PATH https://www.postgresql.org/docs/15/functions-info.html](https://www.postgresql.org/docs/15/ddl-schemas.html#DDL-SCHEMAS-PATH https://www.postgresql.org/docs/15/functions-info.html).
Реальный путь поиска
sch_db=> \c - postgres
sch_db=# ALTER SCHEMA work RENAME TO student; sch_db=# SELECT current_schema();
current_schema
----------------
public
(1 строка)
sch_db=# \c - student
sch_db=> SELECT current_schema();
current_schema
----------------
student
(1 строка)
sch_db=> SELECT current_schemas(true);
current_schemas
-----------------------------
{pg_catalog,student,public}
(1 строка)
Проведем эксперимент: переименуем схему work, владельцем которой был назначен student, задав ей имя student. В таком случае, при существующей настройке значения search_path, схема с именем пользователя будет просматриваться сначала.
Это подтверждается вызовом функции current_schema() - она показывает имя той схемы, в которой будут создаваться новые объекты, так как это первая существующая схема в пути поиска.
Другая важная функция - current_schemas(). Она выводит реальный набор схем, которые будут просматриваться в поиске объекта, указанного неполным именем. Если параметр этой функции установлен true, то будут показаны и системные схемы. https://www.postgresql.org/docs/15/functions-info.html.
Схемы для временных таблиц
sch_db=> SELECT current_schemas(true);
current_schemas
-----------------------------
{pg_catalog,student,public}
(1 строка)
sch_db=> CREATE TEMP TABLE tmp_tab AS SELECT now() AS timepoint;
sch_db=> \dt tmp_tab
Список отношений
Схема | Имя | Тип | Владелец
-----------+---------+---------+---------- pg_temp_6 | tmp_tab | таблица | student
(1 строка)
sch_db=> SELECT current_schemas(true);
current_schemas
---------------------------------------
{pg_temp_6,pg_catalog,student,public}
(1 строка)
sch_db=> SELECT * FROM pg_temp.tmp_tab;
timepoint
-------------------------------
2024-10-12 18:16:20.861332+03
(1 строка)
Работа с временными таблицами - особый случай. Эти таблицы создаются на срок жизни сессии или транзакции. Потом они автоматически удаляются. Временные таблицы не защищены журналом WAL и не кешируются в буферном кеше. Все это делается для максимальной скорости доступа к временным таблицам. С этой же целью создаются специальные схемы, просматриваемые первыми, для хранения временных таблиц. Когда создается временная таблица, то именно к ней должен осуществляться доступ по неполному имени. Соответственно схема, которой принадлежит временная таблица, должна быть в пути поиска на первом месте.
Имена схем для временных объектов назначаются автоматически и формируются следующим образом: pg_temp_#, где # является автоматически назначенным номером. Так, в примере выше, временная таблица tmp_tab была создана в схеме pg_temp_6.
Для удобства обращения к временным таблицам имеется специальный псевдоним pg_temp. https://www.postgresql.org/docs/15/runtime-config-client.html.
Удаление схем
sch_db=> \dn
Список схем
Имя | Владелец
---------+-------------------
public | pg_database_owner
student | student
(2 строки)
sch_db=> DROP SCHEMA student;
ERROR: cannot drop schema student because other objects depend on it
ПОДРОБНОСТИ: table zp depends on schema student
ПОДСКАЗКА: Use DROP ... CASCADE to drop the dependent objects too.
sch_db=> DROP SCHEMA student CASCADE; NOTICE: drop cascades to table zp DROP SCHEMA
Суперпользователь или владелец схемы может ее удалить. Если в схеме имеются объекты, то простой команды DROP SCHEMA недостаточно и необходимо добавить ключевое слово CASCADE. При этом и схема и объекты в ней будут безвозвратно удалены. https://www.postgresql.org/docs/15/sql-dropschema.html.
Системный каталог
Содержимое системного каталога
В документации PostgreSQL таблицы, содержащие данные об объектах баз данных кластера (метаданные), называются системными каталогами. Например, pg_class - это системный каталог, содержащий свойства отношений (таблиц, индексов и т.п.), а pg_attribute - системный каталог с данными о столбцах всех отношений.
Для упрощения будем далее именовать системным каталогом схему pg_catalog, которой принадлежат все таблицы и представления с метаданными.
Когда приложению требуется получить информацию о каком-либо объекте базы данных, это делается с помощью обычного SELECT выражения. Но изменять метаданные командами DML (Data Manipulation Language - Язык манипулирования данными) нельзя. Вместо этого используются команды DDL (Data Definition Language - язык определения данных). Это CREATE, ALTER DROP и т.п.
Схема pg_catalog содержит исчерпывающие метаданные кластера баз данных PostgreSQL, но стандарт SQL предписывает иметь специальную схему information_schema для метаданных, а также описывает наименования и структуру объектов в ней.
PostgreSQL поддерживает information_schema. Большинство объектов в pg_catalog описывают объекты текущей базы данных, но в pg_catalog есть описатели и глобальных объектов, например, метаданные ролей и самих баз данных кластера. https://www.postgresql.org/docs/15/catalogs-overview.html.
https://www.postgresql.org/docs/15/information-schema.html.
Структура таблиц системного каталога
student@student=> \d pg_namespace
Таблица "pg_catalog.pg_namespace"
Столбец | Тип | Правило сортировки | Допустимость NULL | По умолчанию
----------+-----------+--------------------+-------------------+--------------
oid |oid | | not null |
nspname | name | | not null |
nspowner | oid | | not null |
nspacl | aclitem[] |
Индексы:
"pg_namespace_oid_index" PRIMARY KEY, btree (oid)
"pg_namespace_nspname_index" UNIQUE CONSTRAINT, btree (nspname)
- Традиционно первые три символа в именах столбцов обычно являются аббревиатурой имени таблицы системного каталога.
- Таблица pg_namespace содержит информацию о схемах, nsp - аббревиатура слова namespace.
- Это соглашение не распространяется на все имена столбцов, например, oid.
В PostgreSQL большинство колонок в таблицах системного каталога именуется с помощью аббревиатуры, построенной из имени таблицы. Например, метаданные баз данных - таблица pg_database:
student@student=> \d pg_database
Таблица "pg_catalog.pg_database"
Столбец | Тип | Правило сортировки | Допустимость NULL |
----------------+-----------+--------------------+-------------------+-
oid | oid | | not null |
datname | name | | not null |
datdba | oid | | not null |
encoding | integer | | not null |
datlocprovider | "char" | | not null |
datistemplate | boolean | | not null |
datallowconn | boolean | | not null |
datconnlimit | integer | | not null |
datfrozenxid | xid | | not null |
datminmxid | xid | | not null |
dattablespace | oid | | not null |
datcollate | text | C | not null |
datctype | text | C | not null |
daticulocale | text | C | |
datcollversion | text | C | |
datacl | aclitem[] | | |
Индексы:
"pg_database_oid_index" PRIMARY KEY, btree (oid), табл. пространство "pg_global"
"pg_database_datname_index" UNIQUE CONSTRAINT, btree (datname), табл.
пространство "pg_global"
Табличное пространство: "pg_global"
Большинство столбцов именуются, начиная с dat - аббревиатура имени таблицы. Обратите внимание на табличное пространство pg_global - таблица pg_database описывает глобальные объекты.
Тип OID и reg типы
student@student=> \dT reg*
Список типов данных
Схема | Имя | Описание
------------+---------------+--------------------------------------
pg_catalog | regclass | registered class
pg_catalog | regcollation | registered collation
pg_catalog | regconfig | registered text search configuration
pg_catalog | regdictionary | registered text search dictionary
pg_catalog | regnamespace | registered namespace
pg_catalog | regoper | registered operator
pg_catalog | regoperator | registered operator (with args)
pg_catalog | regproc | registered procedure
pg_catalog | regprocedure | registered procedure (with args)
pg_catalog | regrole | registered role
pg_catalog | regtype | registered type
(11 строк)
- Таблицы системного каталога проиндексированы по полю OID (Object identifiers), таблицы часто связывают в запросах по этому полю.
- Для некоторых таблиц системного каталога можно преобразовывать OID в имя объекта и наоборот с помощью специальных reg типов.
Пусть необходимо получить список столбцов таблицы. Например:
=> CREATE TABLE tablo(n int);
=> SELECT attrelid, attname, atttypid FROM pg_attribute WHERE attrelid = (SELECT oid FROM pg_class WHERE relname = 'tablo') AND attnum > 0;
attrelid | attname | atttypid
----------+---------+----------
24596 | n | 23
(1 строка)
Поле attrelid таблицы pg_attribute (таблица с метаданными столбцов всех таблиц БД) содержит OID таблицы, в строках которой есть эти столбцы. Без reg преобразования пришлось выполнить подзапрос для определения OID таблицы, а для удобного вывода типа столбца необходим еще один подзапрос или соединение.
Используя reg типы:
=> SELECT attrelid::regclass, attname, atttypid::regtype FROM pg_attribute WHERE attrelid = 'tablo'::regclass AND attnum > 0;
attrelid | attname | atttypid
----------+---------+----------
tablo | n | integer
(1 строка)
PostgreSQL использует reg тип таким образом: отбрасывается приставка reg, например, regclass -> class, и добавляется префикс pg_, class -> pg_class. Таким образом, для приведения типа OID attrelid к имени таблицы attrelid::regclass была использована таблица pg_class, а для приведения из OID типа atttypid::regtype таблица pg_type. https://www.postgresql.org/docs/15/datatype-oid.html.
Работа скрытых запросов в psql
student@student=> \set ECHO_HIDDEN on
student@student=> \db
********* ЗАПРОС *********
SELECT spcname AS "Name",
pg_catalog.pg_get_userbyid(spcowner) AS "Owner",
pg_catalog.pg_tablespace_location(oid) AS "Location" FROM pg_catalog.pg_tablespace
ORDER BY 1;
**************************
Список табличных пространств
Имя | Владелец | Расположение
------------+----------+--------------
pg_default | postgres |
pg_global | postgres |
(2 строки)
student@student=> \set ECHO_HIDDEN off
Клиент psql предоставляет удобную возможность увидеть скрытые запросы к объектам системного каталога, выполняемые метакомандами. Для вывода запросов, выполняемых psql, установите значение встроенной переменной psql ECHO_HIDDEN в значение ON. Когда режим вывода запросов не будет далее необходим, переключите переменную в OFF или просто сбросьте ее метакомандой \unset. https://www.postgresql.org/docs/15/app-psql.html.
Расширения
Расширяемость
Удобной особенностью PostgreSQL является его расширяемость, достигаемая за счет гибкости системного каталога. Поскольку системный каталог представлен таблицами и представлениями, его содержимое можно модифицировать. Именно это позволяет пользователям создавать:
- собственные функции;
- добавлять языки программирования для кода на стороне сервера;
- новые специализированные типы данных;
- способы доступа к данным;
- новые типы данных, операторы и соответствующие типы индексов;
- способы подключения к внешним источникам данных. https://www.postgresql.org/docs/15/extend.html.
Обычно работа, связанная с расширением возможностей PostgreSQL, выражается в конечном итоге в появление расширения (extension). Расширение включает в себя группу логически связанных объектов (таблиц, функций, представлений, типов и т.п.), упакованных в единое целое.
Наиболее важные расширения поставляются вместе с исходным кодом PostgreSQL в каталоге contrib.
Доступные расширения
postgres=# SELECT count(*) FROM pg_available_extensions;
count
-------
85
(1 строка)
postgres=# SELECT name, comment FROM pg_available_extensions WHERE name ~ 'ora';
name | comment
------------+-----------------------------------------------------------------------------------------------
orafce | Functions and operators that emulate a subset of functions and packages from the Oracle RDBMS
oracle_fdw | foreign data wrapper for Oracle access
(2 строки)
Представление pg_catalog.pg_available_extensions содержит список доступных к установке расширений.
- СУБД Pangolin 6.2.0 поставляется с 85-ю расширениями.
- Например, имеется расширение для подключения к Oracle RDBMS oracle_fdw (FDW - Foreign Data Wrapper) и расширение orafce с популярными функциями из Oracle RDBMS.
Множество востребованных расширений поставляются непосредственно в установочном пакете Pangolin. Каталог, в который файлы расширений установлены и доступны для СУБД, можно узнать следующим образом:
[postgres@p620 ~]$ pg_config --sharedir
/usr/pangolin-6.2.0/share
Физически файлы расширений находятся в подкаталоге extension этого каталога. Список расширений, доступных к установке (то есть, к подключению к текущей базе данных), можно в представлении pg_available_extensions. В нем можно получить информацию о версии расширения по умолчанию и о текущей установленной версии. https://www.postgresql.org/docs/15/view-pg-available-extensions.html.
Доступные версии расширений
postgres=# SELECT name, default_version FROM pg_available_extensions WHERE name ~ 'hint';
name | default_version
--------------+-----------------
pg_hint_plan | 1.5
(1 строка)
postgres=# SELECT name, version, requires FROM pg_available_extension_versions WHERE name ~ 'hint';
name | version | requires
--------------+---------+----------
pg_hint_plan | 1.3.0 |
pg_hint_plan | 1.3.1 |
pg_hint_plan | 1.3.2 |
pg_hint_plan | 1.3.6 |
pg_hint_plan | 1.3.7 |
pg_hint_plan | 1.4.1 |
pg_hint_plan | 1.5 |
pg_hint_plan | 1.3.3 |
pg_hint_plan | 1.3.5 |
pg_hint_plan | 1.3.4 |
pg_hint_plan | 1.3.8 |
pg_hint_plan | 1.4 |
(12 строк)
Версию по умолчанию показывает поле default_version представления pg_available_extensions.
Все доступные к установке версии выдает представление pg_available_extension_versions.
Некоторые расширения бывают доступны сразу в нескольких версиях. Например, в Pangolin 6.2.0 поставляется расширение pg_hint_plan сразу в нескольких версиях. У каждого расширения обязательно имеется управляющий файл с расширением control. Версия по умолчанию указана в нем:
[postgres@p620 ~]$ cat
/usr/pangolin-6.2.0/share/extension/pg_hint_plan.control
# pg_hint_plan extension
comment = ''
default_version = '1.5'
relocatable = false
schema = hint_plan
Версии расширения, доступные для установки, можно увидеть в представлении pg_available_extension_versions. https://www.postgresql.org/docs/15/view-pg-available-extension-versions.html.
При установке расширения можно указать требуемую версию. Также, если доступна к установке более свежая версия, то установленную старую версию можно обновить.
Установка расширения
postgres=# \c student
Вы подключены к базе данных "student" как пользователь "postgres". student=# \dx
Список установленных расширений
Имя | Версия | Схема | Описание
---------+--------+------------+------------------------------
plpgsql | 1.1 | pg_catalog | PL/pgSQL procedural language
(1 строка)
student=# CREATE EXTENSION orafce;
CREATE EXTENSION
student=# \dx
Список установленных расширений
Имя | Версия | Схема | Описание
---------+--------+------------+-----------------------------------------------------------------------------------------------
orafce | 4.4 | public | Functions and operators that emulate a subset of functions and packages from the Oracle RDBMS
plpgsql | 1.1 | pg_catalog | PL/pgSQL procedural language
(2 строки)
Установка расширения осуществляется командой CREATE EXTENSION, в результате которой объекты, упакованные в расширение, становятся доступными в текущей базе данных. Без явного указания требуемой версии расширения устанавливается версия по умолчанию.
В примере на слайде суперпользователь postgres подключается к БД student и проверяет метакомандой \dx, какие расширения подключены. В списке изначально имеется расширение plpgsql - это язык PL/pgSQL, которое подключается автоматически. После установки расширения его видно в списке, выводимом \dx.
Для получения списка объектов, установленных из расширения, удобно использовать \dx+ (показана часть списка, так как из этого расширения установлено 682 объекта).
https://www.postgresql.org/docs/15/sql-createextension.html.
student=# \dx+ orafce
...
view oracle.user_cons_columns
view oracle.user_constraints
view oracle.user_ind_columns
view oracle.user_objects
view oracle.user_procedures
view oracle.user_source
view oracle.user_tab_columns
view oracle.user_tables
view oracle.user_views
(682 строки)
Использование объектов расширения
student=# SELECT * FROM oracle.user_tables LIMIT 10;
table_name
-----------------------
tablo
pg_statistic_ext_data
pg_type
pg_attribute
utl_file_dir
pg_user_mapping
psql_grace_authid
pg_authid
pg_statistic
pg_proc
(10 строк)
Объекты, установленные из расширения, используются обычными способами.
Из расширения могут быть установлены схемы.
В примере из расширения установлена схема oracle, один из объектов в которой - представление user_tables.
Из расширений часто устанавливаются схемы, которым будут принадлежать другие объекты, установленные из расширения. Так, например, из расширения orafce были установлены следующие схемы:
student=# \dn
Список схем
Имя | Владелец
--------------+-------------------
dbms_alert | postgres
dbms_assert | postgres
dbms_output | postgres
dbms_pipe | postgres
dbms_random | postgres
dbms_sql | postgres
dbms_utility | postgres
oracle | postgres
plunit | postgres
plvchr | postgres
plvdate | postgres
plvlex | postgres
plvstr | postgres
plvsubst | postgres
public | pg_database_owner
utl_file | postgres
(16 строк)
Удаление расширений
student=# DROP VIEW oracle.user_tables;
ERROR: cannot drop view oracle.user_tables because extension orafce requires it
ПОДСКАЗКА: You can drop extension orafce instead.
student=# DROP EXTENSION orafce;
DROP EXTENSION
student=# \dx
Список установленных расширений
Имя | Версия | Схема | Описание
---------+--------+------------+------------------------------
plpgsql | 1.1 | pg_catalog | PL/pgSQL procedural language
(1 строка)
Установка расширения подключает его к текущей базе и все объекты, упакованные в расширение, становятся доступными в каких-либо схемах этой базы.
Удалить командой DROP объект, упакованный в расширение, нельзя, так как с помощью механизма зависимостей выяснится, что расширение зависит от этого объекта. Это и продемонстрировано в примере на слайде.
Объекты расширения будут удалены из текущей базы данных лишь тогда, когда будет удалено само расширение командой DROP EXTENSION.
При этом, однако, возможна ситуация, когда в базе после установки расширения были созданы новые объекты, использующие объекты расширения. Например, в подключенном расширении имеется некоторый тип данных и этот тип использован для столбцов некоторых таблиц. Тогда команда DROP EXTENSION не выполнится успешно и будет получено сообщение о нарушении зависимости.
Можно использовать DROP EXTENSION ... CASCADE, но при этом из базы данных будут удалены зависимые от этого расширения объекты. https://www.postgresql.org/docs/15/sql-dropextension.html.
Итоги
- Базы данных, обслуживаемые одним экземпляром СУБД, называются кластером.
- В кластере исходно три базы данных: template1, template0 и postgres.
- Все базы данных создаются копированием существующих.
- В базах данных хранятся объекты, каждый из которых принадлежит некоторой схеме.
- Имя схемы и имя объекта дают полное имя объекта.
- Имеются специальные схемы для хранения метаданных.
- Для временных таблиц создаются специальные схемы.
- Системный каталог содержит метаданные.
- PostgreSQL расширяем.