Глава 05. Архитектура
В этой главе:
- Архитектура;
- Экземпляр;
- Активность процессов;
- Процессы СУБД в ОС;
- Локальная память процессов;
- Хранение данных;
- Каталог данных кластера БД;
- Этапы выполнения запроса;
- Расширенный протокол;
- Кеш буферов;
- Заголовок буфера;
- Чтение в свободный буфер;
- Вытеснение.
Архитектура
- Работа СУБД Pangolin основана на деятельности отдельных процессов postgres, работающих скоординированно.
- Первым запускается процесс postgres, называемый далее postmaster.
- Он порождает одноименные дочерние процессы (backend), обслуживающие клиентов и выполняющие служебные задачи.
- Процессы взаимодействуют и имеют доступ к общей памяти.
- Команда initdb создает в каталоге данных PGDATA файлы и каталоги, необходимые для работы СУБД и хранения данных.
- СУБД обслуживает несколько БД - кластер баз данных.
- Процессы, файлы и структуры в памяти - экземпляр.
При запуске экземпляра стартует головной процесс postgres, ранее называвшийся postmaster. Для удобства далее можно продолжать называть его именно так. Этот процесс организует необходимые для межпроцессного взаимодействия IPC структуры, например, разделяемую память, и открывает средства сетевого взаимодействия. Далее запускаются копии этого процесса с помощью системного вызова fork(). Дочерние процессы выполняют работу асинхронно и независимо друг от друга, но под общим управлением postmaster.
Процесса экземпляра на равноправных условиях имеют доступ к разделяемым ресурсам кластера баз данных и структурам в файловой системе, созданным с помощью initdb.
Экземпляр PostgreSQL обслуживает сразу несколько баз данных, которые и образуют кластер баз данных. https://www.postgresql.org/docs/15/creating-cluster.html.
Экземпляр
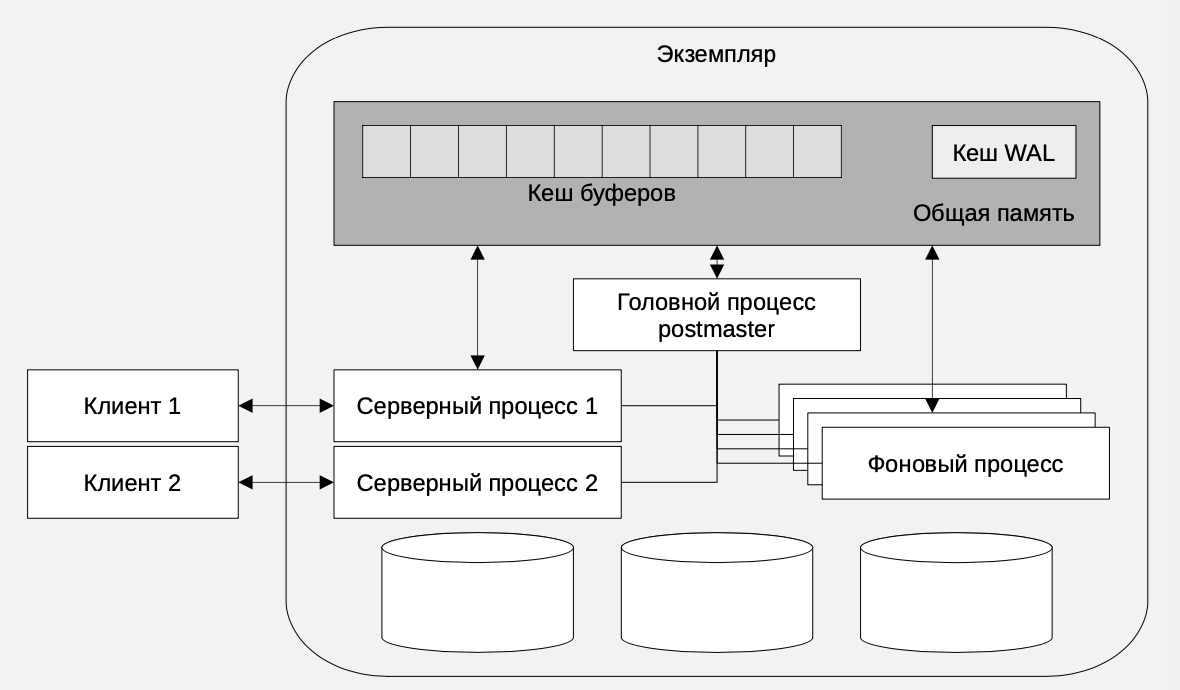
В разделяемой памяти экземпляра, доступной серверным процессам (backend), находится несколько структур данных, главная из которых - буферный кеш. Он предназначен для размещения страниц данных, считанных с диска из файлов данных, и обрабатываемых процессами. При подключении клиента после успешной аутентификации для него создается персональный серверный процесс (client backend). Когда клиент выполняет запрос SQL вначале проверяется какие страницы данных требуются для выполнения запроса. Так например, на этапе планирования запроса уже может быть ясно, что необходимо прочитать все страницы таблицы, так как выполняется полное сканирование таблицы. Далее проверяется, имеются ли требующиеся для этого запроса страницы в буферном кеше. Если они там не находятся, их считывают с диска из файлов данных. Для того чтобы сервер знал, какие файлы надо прочитать, для этого необходимы метаданные (данные о данных), находящиеся в системном каталоге. Считанные таблицы размещаются в буферном кеше. Далее вся работа запроса осуществляется серверным процессов в буферном кеше. Измененные запросами страницы данных должны асинхронно, то есть, в будущем, быть скопированы обратно на их место расположения в файлах данных на жестком диске. Для исключения одновременного изменения данных разными процессами, работающими асинхронно, существует система блокировок.
https://www.postgresql.org/docs/15/tutorial-arch.html.
Активность процессов
В pg_stat_activity информация о процессах экземпляра, порожденных головным (postmaster):
- client backend - серверный процесс, обслуживающий клиента; – checkpointer - процесс контрольной точки; – background writer - записывает измененные страницы из кеша на диск; – walwriter - записывает содержимое кеша WAL в журнал предзаписи; – autovacuum launcher - запускает рабочие процессы автоочистки; – logical replication launcher - запускает рабочие процессы для логической репликации.
Специфичные для Pangolin:
– autounite launcher - для объединения индексов в секционированных таблицах; – integrity check launcher - для проверки целостности.
postgres=# SELECT pid, backend_type FROM pg_stat_activity;
pid | backend_type ------+------------------------------
921 | autovacuum launcher
922 | autounite launcher
924 | logical replication launcher
923 | integrity check launcher
2485 | client backend
907 | background writer
906 | checkpointer
919 | walwriter
(8 rows)
В примере на слайде показан запрос к представлению pg_stat_activity, информирующему о текущей активности в экземпляре. Подробнее об этом будет рассказано в главе "Обслуживание СУБД".
В полученном списке видны процессы экземпляра, среди которых видно несколько служебных фоновых процессов, а также серверный процесс, обслуживающий текущий клиентский сеанс - процесс 2485 client backend.
https://www.postgresql.org/docs/15/monitoring-stats.html#MONITORING-PG-STAT-ACTIVITY-VIEW.
Процессы СУБД в ОС
postgres@arch_db=# \! ps f -C postgres
PID TTY STAT TIME COMMAND
811 ? Ss 0:00 /usr/pangolin-6.2.0/bin/postgres -D /pgdata/06
906 ? Ss 0:00 \_ postgres: checkpointer
907 ? Ss 0:00 \_ postgres: background writer
909 ? Ss 0:00 \_ postgres: idle sessions terminator
919 ? Ss 0:00 \_ postgres: walwriter
920 ? Ss 0:00 \_ postgres: license checker
921 ? Ss 0:00 \_ postgres: autovacuum launcher
922 ? Ss 0:00 \_ postgres: autounite launcher
923 ? Ss 0:00 \_ postgres: integrity check launcher
924 ? Ss 0:00 \_ postgres: logical replication launcher
2485 ? Ss 0:00 \_ postgres: postgres arch_db [local] idle
В примере получен список процессов экземпляра средствами операционной системы. Для этого была использована метакоманда psql !, позволяющая без выхода из интерактивной сессии psql выполнить команду ОС. Для получения списка процессов экземпляра использовалась команда ps с опцией f в BSD стиле - она позволяет получить иерархический список дочерних процессов и их родителя. В списке видно, что головной процесс (бывший postmaster) - это postgres. Другая использованная здесь опция команды ps -C позволяет отфильтровать список процессов по командной строке. См. man ps.
Локальная память процессов
Каждый обслуживающий процесс имеет приватную локальную память.
Локальная память процесса хранит данные сеанса:
- разобранные запросы;
- курсоры;
- кеш системного каталога;
- области сортировки и хеширования.

Каждый процесс имеет собственное адресное пространство памяти. В локальной памяти процессов размещаются:
- кеш результаты разбора запросов;
- курсоры;
- кеш системного каталога;
- память для выполнения операций сортировки;
- память для построения хеш-таблиц.
https://www.postgresql.org/docs/15/runtime-config-resource.html#RUNTIME-CONFIG-RESOURCE-MEMORY.
Хранение данных
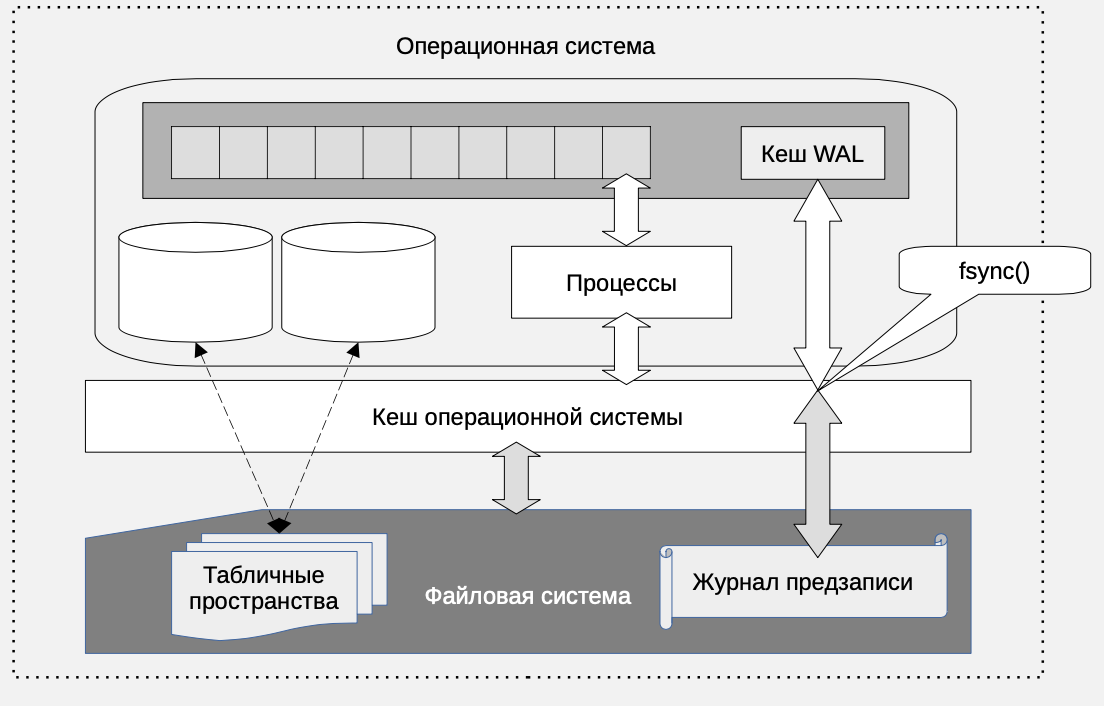
Данные должны храниться на надежных энергонезависимых носителях. В PostgreSQL хранение данных основано на использовании файловых систем. Объекты, содержащие данные, например, таблицы представлены наборами файлов. Эти файлы физически хранятся в табличных пространствах, организованных с помощью специальных каталогов.
Каждая база данных в PostgreSQL имеет табличное пространство по умолчанию, но объекты, принадлежащие этой базе данных могут размещаться в разных табличных пространствах. И наоборот, в одном табличном пространстве могут находиться объекты, принадлежащие разным базам данных.
Подробнее об этом рассказано в главе "Физическое хранение данных". В файловой системе PostgreSQL хранит не только файлы данных, там находятся файлы, сохраняющие состояние транзакций, журнал транзакций WAL и многое другое.
Все структуры данных за исключением физических мест размещения табличных пространств находятся в каталоге данных, определенном с помощью опции -D команды initdb или переменной окружения PGDATA.
https://www.postgresql.org/docs/15/storage.html.
Каталог данных кластера БД
$ sudo -u postgres ls -F /pgdata/06/data
base/ pg_multixact/ pg_snapshots/ pg_xact/
global/ pg_notify/ pg_stat/ postgresql.auto.conf
pg_commit_ts/ pg_perf_insights/ pg_stat_tmp/ postgresql.conf
pg_dynshmem/ pg_commit_ts/ pg_subtrans/ postmaster.opts
pg_hba.conf pg_prep_stats/ pg_subtrans/ postmaster.opts
pg_ident.conf pg_quota.conf pg_twophase/ PRODUCT_VERSION
pg_integrity/ pg_replslot/ PG_VERSION tracing/
pg_logical/ pg_serial/ pg_wal/
- При инициализации кластера БД командой initdb в каталоге данных PGDATA создается набор файлов и каталогов для работы СУБД.
- Права на этот каталог в ОС только для postgres 700 или 750.
- Каталог base - табличное пространство по умолчанию.
На слайде приведен пример содержимого каталога данных. По умолчанию команда initdb устанавливает на этот каталог права доступа 700 (drwx------), то есть, полные права для владельца - postgres. Однако, при инициализации команде initdb можно добавить опцию -g, в результате чего права на каталог данных будут установлены 750 (drwxr-x---), с правами на чтение для членов группы postgres. Такие права могут потребоваться некоторым утилитам резервного копирования.
На слайде выделен каталог base, в котором размещается табличное пространство по умолчанию (оно называется pg_default). Это табличное пространство будет использоваться для размещения данных отношений (таблиц, индексов и т.п.), если для них или для всей их базы данных не указано иное табличное пространство. https://www.postgresql.org/docs/15/app-initdb.html.
Этапы выполнения запроса
Базовый протокол:
- Разбор - построение дерева запроса.
- Переписывание - преобразование запроса в соответствии с правилами.
- Планирование - определение наилучшего способа выполнения запроса.
- Выполнение.
Когда в клиентском приложении вводится SQL запрос, он поступает на сервер и далее выполняется сервером. Получив запрос от клиента, сервер в для обычных случаев использует базовый протокол выполнения, состоящий из следующих стадий:
- происходит разбор (parse) запроса, в результате чего появляется дерево разбора;
- дерево запроса подвергается преобразованию, называющемуся переписыванием (rewriting) - это делается автоматически, но с помощью правил переписывания на этот процесс потенциально можно влиять (не рекомендуется);
- с переписанным деревом запроса начинается работа по планированию выполнения запроса, которая выполняется планировщиком, выбирающим из возможных способов выполнения запроса минимально затратный способ;
- используя выбранный план исполнительный механизм выполняет запрос.
Результаты выполнения или сообщения об ошибках отправляются клиенту.
https://www.postgresql.org/docs/15/protocol-overview.html.
Если используются подготовленные запросы или курсоры, то вместо базового протокола используется расширенный протокол.
Расширенный протокол
Расширенный протокол предоставляет возможность управления этапами выполнения запроса. Используется при подготовке операторов и для работы с курсорами. При подготовке оператора или создании курсора:
- выполняется разбор;
- запрос переписывается;
- результаты запоминаются в локальной памяти процесса.
При получении сервером команды EXECUTE:
- при наличии параметров выполняется их привязка;
- выбирается план исполнения;
- запрос выполняется, причем для курсоров в пошаговом режиме.
Расширенный протокол отличается от базового возможностью непосредственного управления этапами выполнения запроса.
Он используется в случае применения подготовленных запросов и курсоров.
Суть расширенного протокола в том, что фазы подготовки и переписывания запроса отделяются от планирования и выполнения.
Это дает возможность кешировать в локальной памяти процесса результаты разбора и переписывания вместо повторения этих фаз при каждом выполнении запроса. Когда подготовленный запрос, уже прошедший ранее разбор и переписывание, подвергается выполнению посредством команды EXECUTE, тогда при необходимости выполняется привязка (bind) параметров запроса и его выполнение. То есть, экономия заключается в том, что не надо каждый раз выполнять разбор и переписывание подготовленного запроса. https://www.postgresql.org/docs/15/sql-prepare.html.
Для курсоров имеется дополнительная возможность по сравнению с подготовленными запросами, заключающаяся в пошаговом исполнении запроса.
https://www.postgresql.org/docs/15/sql-declare.html.
Кеш буферов
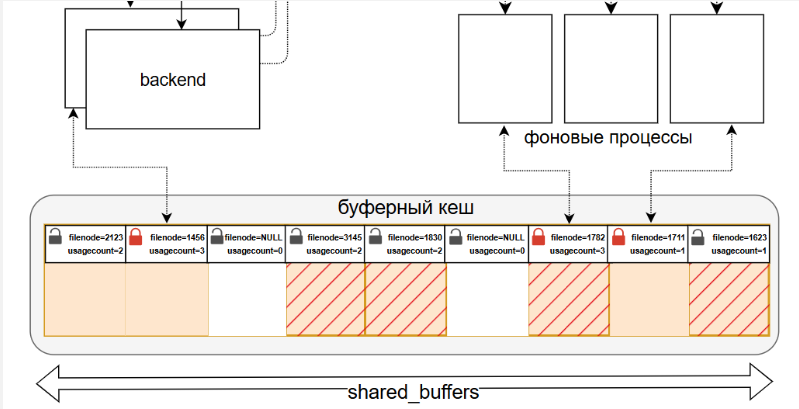
Работа с данными происходят в кеше буферов, куда из файлов данных считываются страницы с версиями строк при обращении. Когда процессу требуется строка, он выполняет поиск соответствующей страницы в буферном кеше. Если ее там нет, страница считывается в буфер из файла данных.
Кеш буферов избавляет от необходимости постоянного чтения-записи на диски при работе с данными. Файлы данных, хранящие строки таблиц и других отношений, состоят из страниц фиксированного размера - по умолчанию 8Кб. То есть, строки размещаются на страницах. При добавлении новых строк страница заполняется и выделяется новая страница. Когда любому процессу экземпляра необходима информация (строка или строки) из какого-либо отношения, используются метаданные в системном каталоге, с помощью которых определяется в каком файле находятся искомые страницы. Чтение и запись в файлы данных осуществляется с помощью страниц. То есть, для того чтобы прочитать строку, необходимо прочитать страницу, содержащую эту строку.
Страницы читаются в буфер, расположенный в кеше буферов разделяемой памяти экземпляра. Все процессы имеют к буферам кеша равноправный доступ. Все чтения и изменения данных происходят в кеше буферов, а не в файлах. Однако, если на странице что-то поменялась, такая страница называется "грязной" и чтобы не потерять результаты изменений, она должна быть записана на свое место в файле данных. Эта запись осуществляется не в тот момент, когда страница стала грязной, а в будущем. Например, при выполнении контрольной точки или при вытеснении страницы из кеша буферов при недостатке в нем места. Поэтому кеш должен быть защищен от сбоя, что и обеспечивает журнал предзаписи WAL.
Заголовок буфера
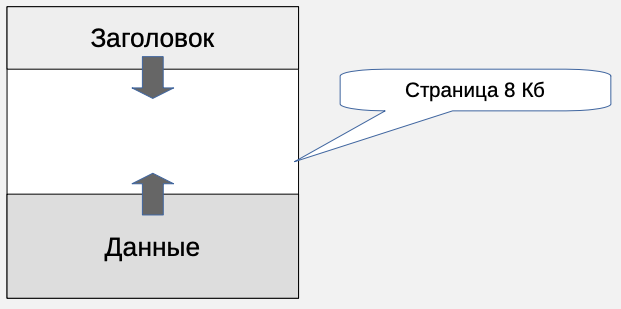
У каждого буфера в кеше имеется заголовок. В этом заголовке находятся сведения о состоянии страницы в этом буфере:
- buffer_id - идентификатор буфера;
- buffer pin_lock - признак закрепление буфера;
- usage count - счетчик количества обращений;
- filenode+blocknumber - название сегмента и номер страницы;
- isdirty - признак наличия изменений (буфер грязный).
Чтение в свободный буфер
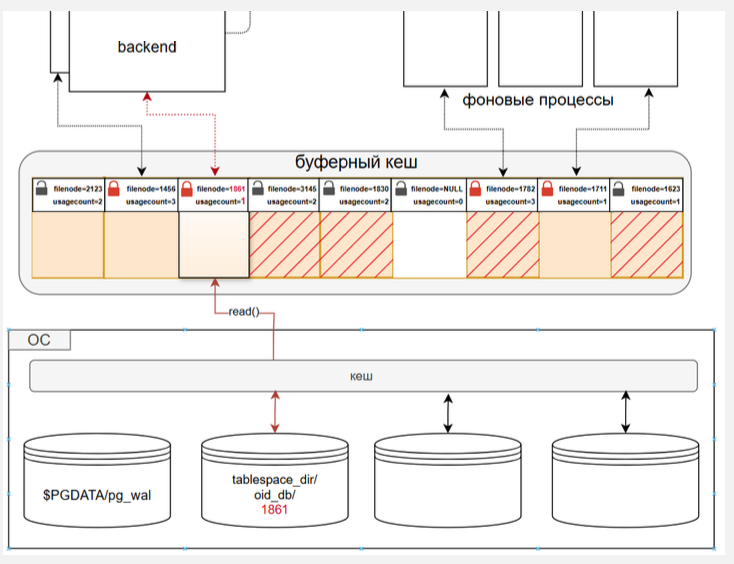
Если в кеше есть свободные буферы и какому-либо процессу понадобилась страница, то она просто считывается из соответствующего файла в свободный буфер. Но чаще всего буферы заняты и необходимо произвести вытеснение страницы, освободив таким образом буфер.
Вытеснение
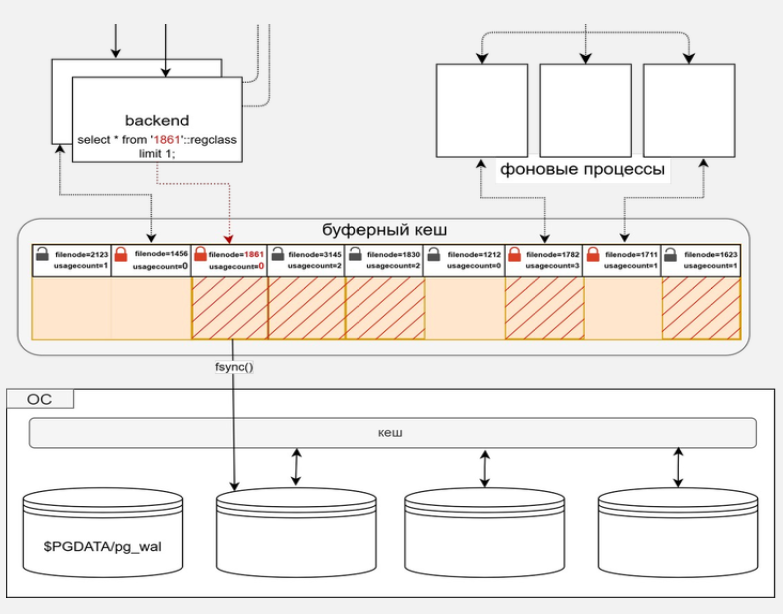
Для определения, какую страницу из кеша буферов можно вытеснить используются счетчик прикреплений Pin count и счетчик использований Usage count. Счетсик Usage count увеличивается вплоть до значения 5 при обращении любого процесса к этому буферу. Однако по алгоритму LRU регулярно происходит происходит обход всех буферов в кеше, на каждом круге (clock sweep) которого происходит уменьшение счетчика Usage count на единицу.
Счетчик Pin count имеет ненулевое значение для тех буферов, которые требуются некоторым процессам в кеше буферов, то есть, буфер прикреплен для выполнения некоторой операции.
Имеется специальный "указатель на следующую жертву" (next victim) - на страницу, у которой Usage count = 0 и Pin count = 0. Это редко используемая страница и ее можно вытеснить. Если страница грязная, то ее следует записать на ее место в файле данных.
Итоги
- Экземпляр представлен скоординированно работающими процессами, общей памятью и каталогом данных.
- Кластер баз данных состоит из нескольких баз данных, обслуживаемых экземпляром.
- Процессы обслуживают клиентов и отвечают за выполнение служебных действий в СУБД.
- Каждый процесс обладает собственной локальной памятью.
- Клиентские запросы разбираются, переписываются, планируются и выполняются сервером СУБД.
- Данные в виде строк размещаются на страницах в файлах данных.
- Работа со страницами производится через кеш буферов.
- При отсутствии в кеше буферов места для размещения страницы происходит вытеснение давно неиспользуемой незакрепленной страницы.